How to improve your Custom Vision model
In this guide, you'll learn how to improve the quality of your Custom Vision model. The quality of your classifier or object detector depends on the amount, quality, and variety of labeled data you provide and how balanced the overall dataset is. A good model has a balanced training dataset that is representative of what will be submitted to it. The process of building such a model is iterative; it's common to take a few rounds of training to reach expected results.
The following is a general pattern to help you train a more accurate model:
- First-round training
- Add more images and balance data; retrain
- Add images with varying background, lighting, object size, camera angle, and style; retrain
- Use new image(s) to test prediction
- Modify existing training data according to prediction results
Prevent overfitting
Sometimes a model will learn to make predictions based on arbitrary characteristics that your images have in common. For example, if you're creating a classifier for apples vs. citrus, and you've used images of apples in hands and of citrus on white plates, the classifier may give undue importance to hands vs. plates, rather than apples vs. citrus.
To correct this problem, provide images with different angles, backgrounds, object size, groups, and other variations. The following sections expand upon these concepts.
Data quantity
The number of training images is the most important factor for your dataset. We recommend using at least 50 images per label as a starting point. With fewer images, there's a higher risk of overfitting, and while your performance numbers may suggest good quality, your model may struggle with real-world data.
Data balance
It's also important to consider the relative quantities of your training data. For instance, using 500 images for one label and 50 images for another label makes for an imbalanced training dataset. This will cause the model to be more accurate in predicting one label than another. You're likely to see better results if you maintain at least a 1:2 ratio between the label with the fewest images and the label with the most images. For example, if the label with the most images has 500 images, the label with the least images should have at least 250 images for training.
Data variety
Be sure to use images that are representative of what will be submitted to the classifier during normal use. Otherwise, your model could learn to make predictions based on arbitrary characteristics that your images have in common. For example, if you're creating a classifier for apples vs. citrus, and you've used images of apples in hands and of citrus on white plates, the classifier may give undue importance to hands vs. plates, rather than apples vs. citrus.

To correct this problem, include a variety of images to ensure that your model can generalize well. Below are some ways you can make your training set more diverse:
Background: Provide images of your object in front of different backgrounds. Photos in natural contexts are better than photos in front of neutral backgrounds as they provide more information for the classifier.

Lighting: Provide images with varied lighting (that is, taken with flash, high exposure, and so on), especially if the images used for prediction have different lighting. It's also helpful to use images with varying saturation, hue, and brightness.

Object Size: Provide images in which the objects vary in size and number (for example, a photo of bunches of bananas and a closeup of a single banana). Different sizing helps the classifier generalize better.

Camera Angle: Provide images taken with different camera angles. Alternatively, if all of your photos must be taken with fixed cameras (such as surveillance cameras), be sure to assign a different label to every regularly occurring object to avoid overfitting—interpreting unrelated objects (such as lampposts) as the key feature.

Style: Provide images of different styles of the same class (for example, different varieties of the same fruit). However, if you have objects of drastically different styles (such as Mickey Mouse vs. a real-life mouse), we recommend you label them as separate classes to better represent their distinct features.

Negative images (classifiers only)
If you're using an image classifier, you may need to add negative samples to help make your classifier more accurate. Negative samples are images that don't match any of the other tags. When you upload these images, apply the special Negative label to them.
Object detectors handle negative samples automatically, because any image areas outside of the drawn bounding boxes are considered negative.
Note
The Custom Vision service supports some automatic negative image handling. For example, if you are building a grape vs. banana classifier and submit an image of a shoe for prediction, the classifier should score that image as close to 0% for both grape and banana.
On the other hand, in cases where the negative images are just a variation of the images used in training, it is likely that the model will classify the negative images as a labeled class due to the great similarities. For example, if you have an orange vs. grapefruit classifier, and you feed in an image of a clementine, it may score the clementine as an orange because many features of the clementine resemble those of oranges. If your negative images are of this nature, we recommend you create one or more additional tags (such as Other) and label the negative images with this tag during training to allow the model to better differentiate between these classes.
Occlusion and truncation (object detectors only)
If you want your object detector to detect truncated objects (objects that are partially cut out of the image) or occluded objects (objects that are partially blocked by other objects in the image), you'll need to include training images that cover those cases.
Note
The issue of objects being occluded by other objects is not to be confused with Overlap Threshold, a parameter for rating model performance. The Overlap Threshold slider on the Custom Vision website deals with how much a predicted bounding box must overlap with the true bounding box to be considered correct.
Use prediction images for further training
When you use or test the model by submitting images to the prediction endpoint, the Custom Vision service stores those images. You can then use them to improve the model.
To view images submitted to the model, open the Custom Vision web page, go to your project, and select the Predictions tab. The default view shows images from the current iteration. You can use the Iteration drop down menu to view images submitted during previous iterations.
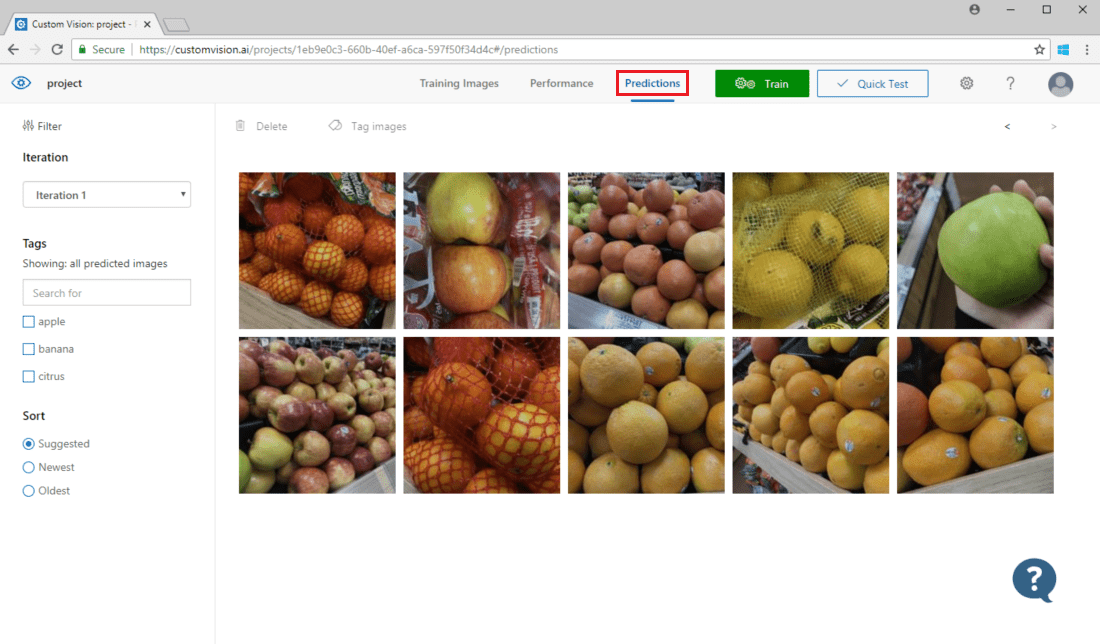
Hover over an image to see the tags that were predicted by the model. Images are sorted so that the ones that can bring the most improvements to the model are listed the top. To use a different sorting method, make a selection in the Sort section.
To add an image to your existing training data, select the image, set the correct tag(s), and select Save and close. The image will be removed from Predictions and added to the set of training images. You can view it by selecting the Training Images tab.
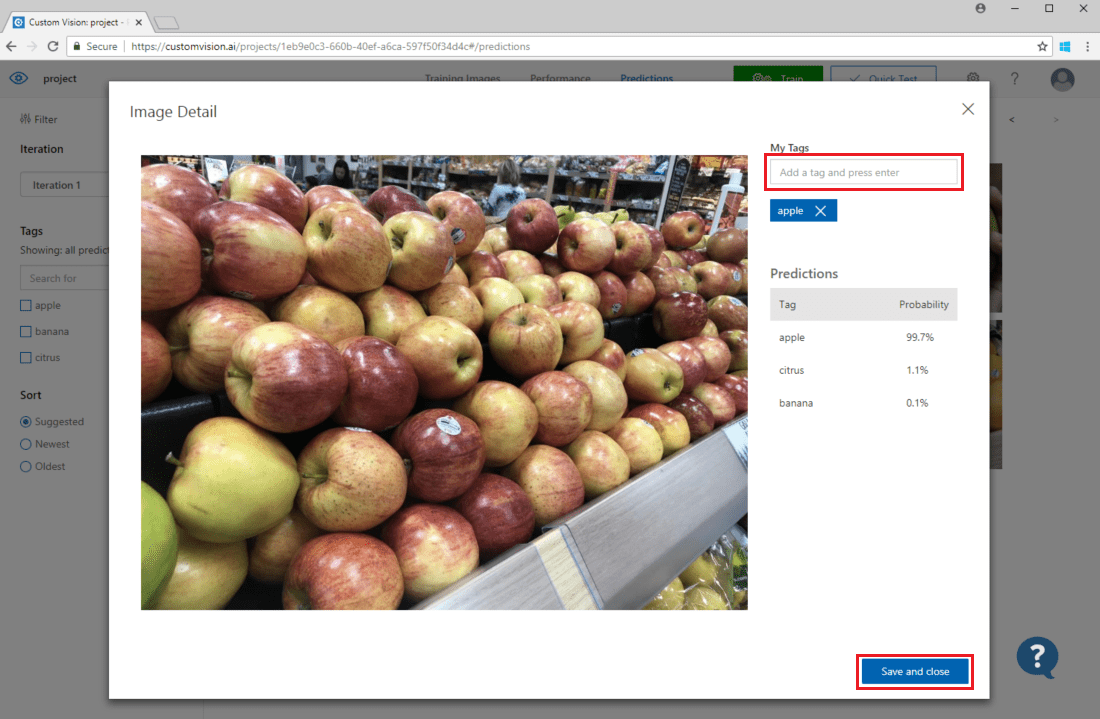
Then use the Train button to retrain the model.
Visually inspect predictions
To inspect image predictions, go to the Training Images tab, select your previous training iteration in the Iteration drop-down menu, and check one or more tags under the Tags section. The view should now display a red box around each of the images for which the model failed to correctly predict the given tag.
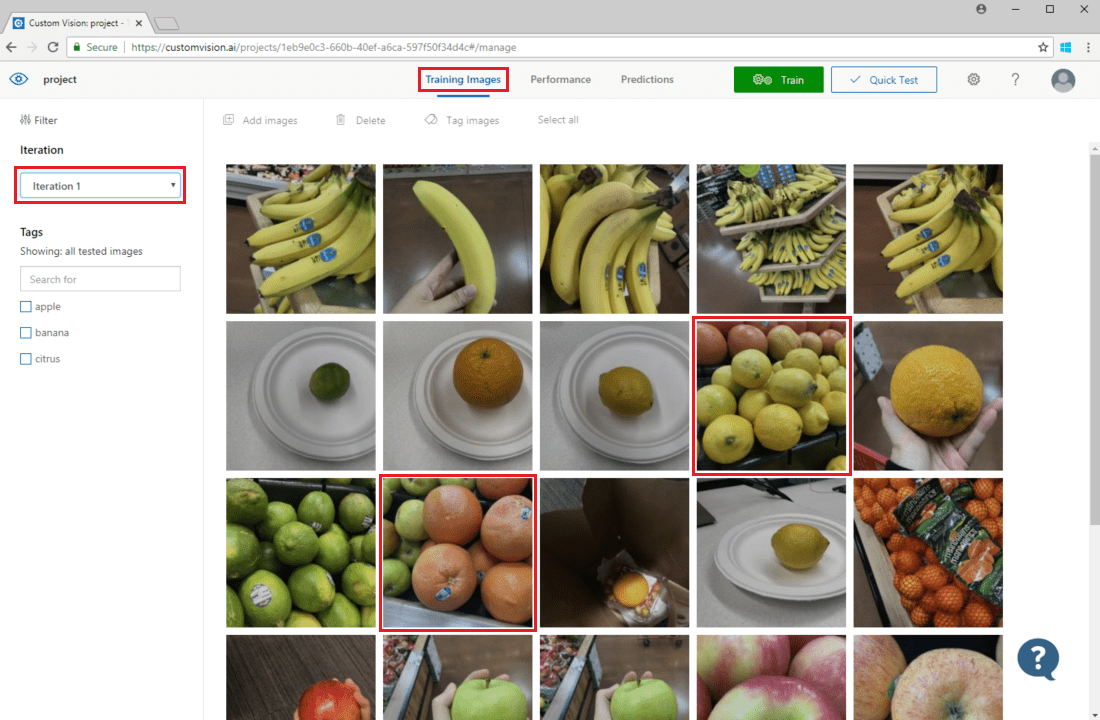
Sometimes a visual inspection can identify patterns that you can then correct by adding more training data or modifying existing training data. For example, a classifier for apples vs. limes may incorrectly label all green apples as limes. You can then correct this problem by adding and providing training data that contains tagged images of green apples.
Next steps
In this guide, you learned several techniques to make your custom image classification model or object detector model more accurate. Next, learn how to test images programmatically by submitting them to the Prediction API.