This reference architecture shows a serverless, event-driven architecture that ingests a stream of data, processes the data, and writes the results to a back-end database.
Architecture
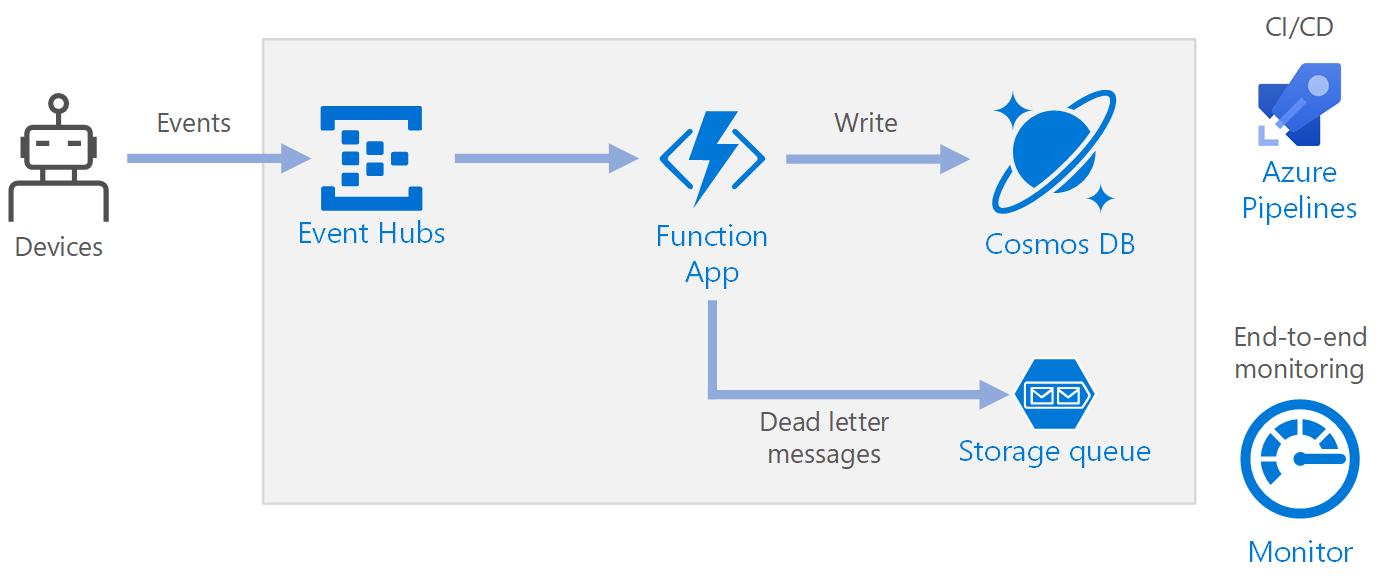
Workflow
- Events arrive at Azure Event Hubs.
- A Function App is triggered to handle the event.
- The event is stored in an Azure Cosmos DB database.
- If the Function App fails to store the event successfully, the event is saved to a Storage queue to be processed later.
Components
Event Hubs ingests the data stream. Event Hubs is designed for high-throughput data streaming scenarios.
Note
For Internet of Things (IoT) scenarios, we recommend Azure IoT Hub. IoT Hub has a built-in endpoint that's compatible with the Azure Event Hubs API, so you can use either service in this architecture with no major changes in the back-end processing. For more information, see Connecting IoT Devices to Azure: IoT Hub and Event Hubs.
Function App. Azure Functions is a serverless compute option. It uses an event-driven model, where a piece of code (a function) is invoked by a trigger. In this architecture, when events arrive at Event Hubs, they trigger a function that processes the events and writes the results to storage.
Function Apps are suitable for processing individual records from Event Hubs. For more complex stream processing scenarios, consider Apache Spark using Azure Databricks, or Azure Stream Analytics.
Azure Cosmos DB. Azure Cosmos DB is a multi-model database service that is available in a serverless, consumption-based mode. For this scenario, the event-processing function stores JSON records, using Azure Cosmos DB for NoSQL.
Queue Storage. Queue Storage is used for dead-letter messages. If an error occurs while processing an event, the function stores the event data in a dead-letter queue for later processing. For more information, see the Resiliency section later in this article.
Azure Monitor. Monitor collects performance metrics about the Azure services deployed in the solution. By visualizing these in a dashboard, you can get visibility into the health of the solution.
Azure Pipelines. Pipelines is a continuous integration (CI) and continuous delivery (CD) service that builds, tests, and deploys the application.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that can be used to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Availability
The deployment shown here resides in a single Azure region. For a more resilient approach to disaster-recovery, take advantage of geo-distribution features in the various services:
- Event Hubs. Create two Event Hubs namespaces, a primary (active) namespace and a secondary (passive) namespace. Messages are automatically routed to the active namespace unless you fail over to the secondary namespace. For more information, see Azure Event Hubs Geo-disaster recovery.
- Function App. Deploy a second function app that is waiting to read from the secondary Event Hubs namespace. This function writes to a secondary storage account for a dead-letter queue.
- Azure Cosmos DB. Azure Cosmos DB supports multiple write regions, which enables writes to any region that you add to your Azure Cosmos DB account. If you don't enable multi-write, you can still fail over the primary write region. The Azure Cosmos DB client SDKs and the Azure Function bindings automatically handle the failover, so you don't need to update any application configuration settings.
- Azure Storage. Use RA-GRS storage for the dead-letter queue. This creates a read-only replica in another region. If the primary region becomes unavailable, you can read the items currently in the queue. In addition, provision another storage account in the secondary region that the function can write to after a fail-over.
Scalability
Event Hubs
The throughput capacity of Event Hubs is measured in throughput units. You can autoscale an event hub by enabling auto-inflate, which automatically scales the throughput units based on traffic, up to a configured maximum.
The Event Hubs trigger in the function app scales according to the number of partitions in the event hub. Each partition is assigned one function instance at a time. To maximize throughput, receive the events in a batch, instead of one at a time.
Azure Cosmos DB
Azure Cosmos DB is available in two different capacity modes:
- Serverless, for workloads with intermittent or unpredictable traffic and low average-to-peak traffic ratio.
- Provisioned throughput, for workloads with sustained traffic requiring predictable performance.
To make sure your workload is scalable, it is important to choose an appropriate partition key when you create your Azure Cosmos DB containers. Here are some characteristics of a good partition key:
- The key value space is large.
- There will be an even distribution of reads/writes per key value, avoiding hot keys.
- The maximum data stored for any single key value won't exceed the maximum physical partition size (20 GB).
- The partition key for a document won't change. You can't update the partition key on an existing document.
In the scenario for this reference architecture, the function stores exactly one document per device that is sending data. The function continually updates the documents with the latest device status using an upsert operation. Device ID is a good partition key for this scenario because writes will be evenly distributed across the keys, and the size of each partition will be strictly bounded because there is a single document for each key value. For more information about partition keys, see Partition and scale in Azure Cosmos DB.
Resiliency
When using the Event Hubs trigger with Functions, catch exceptions within your processing loop. If an unhandled exception occurs, the Functions runtime doesn't retry the messages. If a message can't be processed, put the message into a dead-letter queue. Use an out-of-band process to examine the messages and determine corrective action.
The following code shows how the ingestion function catches exceptions and puts unprocessed messages onto a dead-letter queue.
[Function(nameof(RawTelemetryFunction))]
public async Task RunAsync([EventHubTrigger("%EventHubName%", Connection = "EventHubConnection")] EventData[] messages,
FunctionContext context)
{
_telemetryClient.GetMetric("EventHubMessageBatchSize").TrackValue(messages.Length);
DeviceState? deviceState = null;
// Create a new CosmosClient
var cosmosClient = new CosmosClient(Environment.GetEnvironmentVariable("COSMOSDB_CONNECTION_STRING"));
// Get a reference to the database and the container
var database = cosmosClient.GetDatabase(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_NAME"));
var container = database.GetContainer(Environment.GetEnvironmentVariable("COSMOSDB_DATABASE_COL"));
// Create a new QueueClient
var queueClient = new QueueClient(Environment.GetEnvironmentVariable("DeadLetterStorage"), "deadletterqueue");
await queueClient.CreateIfNotExistsAsync();
foreach (var message in messages)
{
try
{
deviceState = _telemetryProcessor.Deserialize(message.Body.ToArray(), _logger);
try
{
// Add the device state to Cosmos DB
await container.UpsertItemAsync(deviceState, new PartitionKey(deviceState.DeviceId));
}
catch (Exception ex)
{
_logger.LogError(ex, "Error saving on database", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
catch (Exception ex)
{
_logger.LogError(ex, "Error deserializing message", message.PartitionKey, message.SequenceNumber);
var deadLetterMessage = new DeadLetterMessage { Issue = ex.Message, MessageBody = message.Body.ToArray(), DeviceState = deviceState };
// Convert the dead letter message to a string
var deadLetterMessageString = JsonConvert.SerializeObject(deadLetterMessage);
// Send the message to the queue
await queueClient.SendMessageAsync(deadLetterMessageString);
}
}
}
The code shown also logs exceptions to Application Insights. You can use the partition key and sequence number to correlate dead-letter messages with the exceptions in the logs.
Messages in the dead-letter queue should have enough information so that you can understand the context of the error. In this example, the DeadLetterMessage class contains the exception message, the original event body data, and the deserialized event message (if available).
public class DeadLetterMessage
{
public string? Issue { get; set; }
public byte[]? MessageBody { get; set; }
public DeviceState? DeviceState { get; set; }
}
Use Azure Monitor to monitor the event hub. If you see there is input but no output, it means that messages aren't being processed. In that case, go into Log Analytics and look for exceptions or other errors.
DevOps
Use infrastructure as code (IaC) when possible. IaC manages the infrastructure, application, and storage resources with a declarative approach like Azure Resource Manager. That will help in automating deployment using DevOps as a continuous integration and continuous delivery (CI/CD) solution. Templates should be versioned and included as part of the release pipeline.
When creating templates, group resources as a way to organize and isolate them per workload. A common way to think about workload is a single serverless application or a virtual network. The goal of workload isolation is to associate the resources to a team, so that the DevOps team can independently manage all aspects of those resources and perform CI/CD.
As you deploy your services you will need to monitor them. Consider using Application Insights to enable the developers to monitor performance and detect issues.
Disaster recovery
The deployment shown here resides in a single Azure region. For a more resilient approach to disaster-recovery, take advantage of geo-distribution features in the various services:
Event Hubs. Create two Event Hubs namespaces, a primary (active) namespace and a secondary (passive) namespace. Messages are automatically routed to the active namespace unless you fail over to the secondary namespace. For more information, see Azure Event Hubs Geo-disaster recovery.
Function App. Deploy a second function app that is waiting to read from the secondary Event Hubs namespace. This function writes to a secondary storage account for dead-letter queue.
Azure Cosmos DB. Azure Cosmos DB supports multiple write regions, which enables writes to any region that you add to your Azure Cosmos DB account. If you don't enable multi-write, you can still fail over the primary write region. The Azure Cosmos DB client SDKs and the Azure Function bindings automatically handle the failover, so you don't need to update any application configuration settings.
Azure Storage. Use RA-GRS storage for the dead-letter queue. This creates a read-only replica in another region. If the primary region becomes unavailable, you can read the items currently in the queue. In addition, provision another storage account in the secondary region that the function can write to after a fail-over.
Cost optimization
Cost optimization is about looking at ways to reduce unnecessary expenses and improve operational efficiencies. For more information, see Overview of the cost optimization pillar.
Use the Azure Pricing calculator to estimates costs. Here are some other considerations for Azure Functions and Azure Cosmos DB.
Azure Functions
Azure Functions supports two hosting models:
- Consumption plan. Compute power is automatically allocated when your code is running.
- App Service plan. A set of virtual machines (VMs) are allocated for your code. The App Service plan defines the number of VMs and the VM size.
In this architecture, each event that arrives on Event Hubs triggers a function that processes that event. From a cost perspective, the recommendation is to use the consumption plan because you pay only for the compute resources you use.
Azure Cosmos DB
With Azure Cosmos DB, you pay for the operations you perform against the database and for the storage consumed by your data.
- Database operations. The way you get charged for your database operations depends on the type of Azure Cosmos DB account you're using.
- In serverless mode, you don't have to provision any throughput when creating resources in your Azure Cosmos DB account. At the end of your billing period, you get billed for the amount of Request Units consumed by your database operations.
- In provisioned throughput mode, you specify the throughput that you need in Request Units per second (RU/s), and get billed hourly for the maximum provisioned throughput for a given hour. Note: Because the provisioned throughput model dedicates resources to your container or database, you'll be charged for the throughput you've provisioned even if you don't run any workloads.
- Storage. You're billed a flat rate for the total amount of storage (in GBs) consumed by your data and indexes for a given hour.
In this reference architecture, the function stores exactly one document per device that is sending data. The function continually updates the documents with latest device status, using an upsert operation, which is cost effective in terms of consumed storage. For more information, see Azure Cosmos DB pricing model.
Use the Azure Cosmos DB capacity calculator to get a quick estimate of the workload cost.
Deploy this scenario
 A reference implementation for this architecture is available on GitHub.
A reference implementation for this architecture is available on GitHub.
Next steps
- Introduction to Azure Functions
- Welcome to Azure Cosmos DB
- What is Azure Queue Storage?
- Azure Monitor overview
- Azure Pipelines documentation