Flapping in Autoscale
This article describes flapping in autoscale and how to avoid it.
Flapping refers to a loop condition that causes a series of opposing scale events. Flapping happens when a scale event triggers the opposite scale event.
Autoscale evaluates a pending scale-in action to see if it would cause flapping. In cases where flapping could occur, autoscale may skip the scale action and reevaluate at the next run, or autoscale may scale by less than the specified number of resource instances. The autoscale evaluation process occurs each time the autoscale engine runs, which is every 30 to 60 seconds, depending on the resource type.
To ensure adequate resources, checking for potential flapping doesn't occur for scale-out events. Autoscale will only defer a scale-in event to avoid flapping.
For example, let's assume the following rules:
- Scale out increasing by 1 instance when average CPU usage is above 50%.
- Scale in decreasing the instance count by 1 instance when average CPU usage is lower than 30%.
In the table below at T0, when usage is at 56%, a scale-out action is triggered and results in 56% CPU usage across 2 instances. That gives an average of 28% for the scale set. As 28% is less than the scale-in threshold, autoscale should scale back in. Scaling in would return the scale set to 56% CPU usage, which triggers a scale-out action.
| Time | Instance count | CPU% | CPU% per instance | Scale event | Resulting instance count |
|---|---|---|---|---|---|
| T0 | 1 | 56% | 56% | Scale out | 2 |
| T1 | 2 | 56% | 28% | Scale in | 1 |
| T2 | 1 | 56% | 56% | Scale out | 2 |
| T3 | 2 | 56% | 28% | Scale in | 1 |
If left uncontrolled, there would be an ongoing series of scale events. However, in this situation, the autoscale engine will defer the scale-in event at T1 and reevaluate during the next autoscale run. The scale-in will only happen once the average CPU usage is below 30%.
Flapping is often caused by:
- Small or no margins between thresholds
- Scaling by more than one instance
- Scaling in and out using different metrics
Small or no margins between thresholds
To avoid flapping, keep adequate margins between scaling thresholds.
For example, the following rules where there's no margin between thresholds, cause flapping.
- Scale out when thread count >=600
- Scale in when thread count < 600
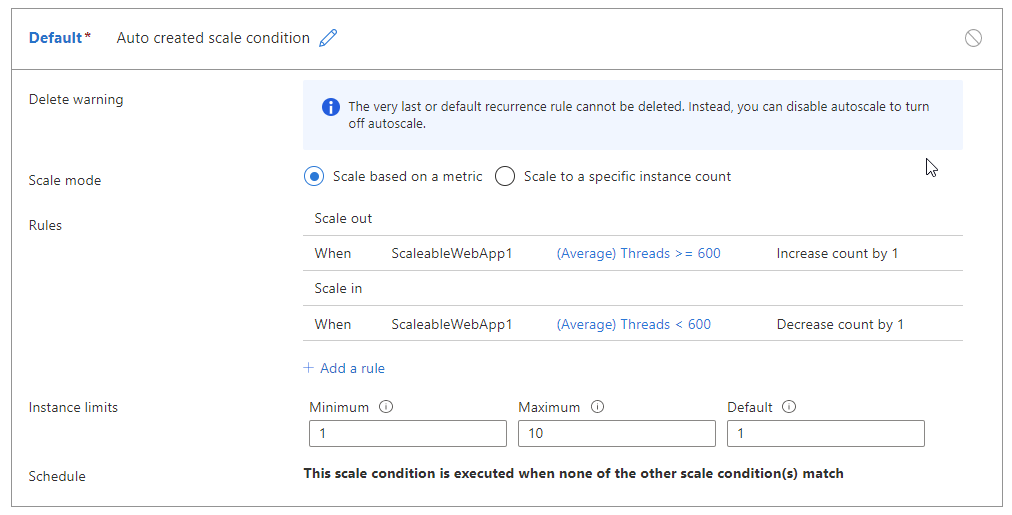
The table below shows a potential outcome of these autoscale rules:
| Time | Instance count | Thread count | Thread count per instance | Scale event | Resulting instance count |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Scale out | 3 |
| T1 | 3 | 1250 | 417 | Scale in | 2 |
- At time T0, there are two instances handling 1250 threads, or 625 treads per instance. Autoscale scales out to three instances.
- Following the scale-out, at T1, we have the same 1250 threads, but with three instances, only 417 threads per instance. A scale-in event is triggered.
- Before scaling-in, autoscale evaluates what would happen if the scale-in event occurs. In this example, 1250 / 2 = 625, that is, 625 threads per instance. Autoscale would have to immediately scale out again after it scaled in. If it scaled out again, the process would repeat, leading to flapping loop.
- To avoid this situation, autoscale doesn't scale in. Autoscale skips the current scale event and reevaluates the rule in the next execution cycle.
In this case, it looks like autoscale isn't working since no scale event takes place. Check the Run history tab on the autoscale setting page to see if there's any flapping.

Setting an adequate margin between thresholds avoids the above scenario. For example,
- Scale out when thread count >=600
- Scale in when thread count < 400

If the scale-in thread count is 400, the total thread count would have to drop to below 1200 before a scale event would take place. See the table below.
| Time | Instance count | Thread count | Thread count per instance | Scale event | Resulting instance count |
|---|---|---|---|---|---|
| T0 | 2 | 1250 | 625 | Scale out | 3 |
| T1 | 3 | 1250 | 417 | no scale event | 3 |
| T2 | 3 | 1180 | 394 | scale in | 2 |
| T3 | 3 | 1180 | 590 | no scale event | 2 |
Scaling by more than one instance
To avoid flapping when scaling in or out by more than one instance, autoscale may scale by less than the number of instances specified in the rule.
For example, the following rules can cause flapping:
- Scale out by 20 when the request count >=200 per instance.
- OR when CPU > 70% per instance.
- Scale in by 10 when the request count <=50 per instance.
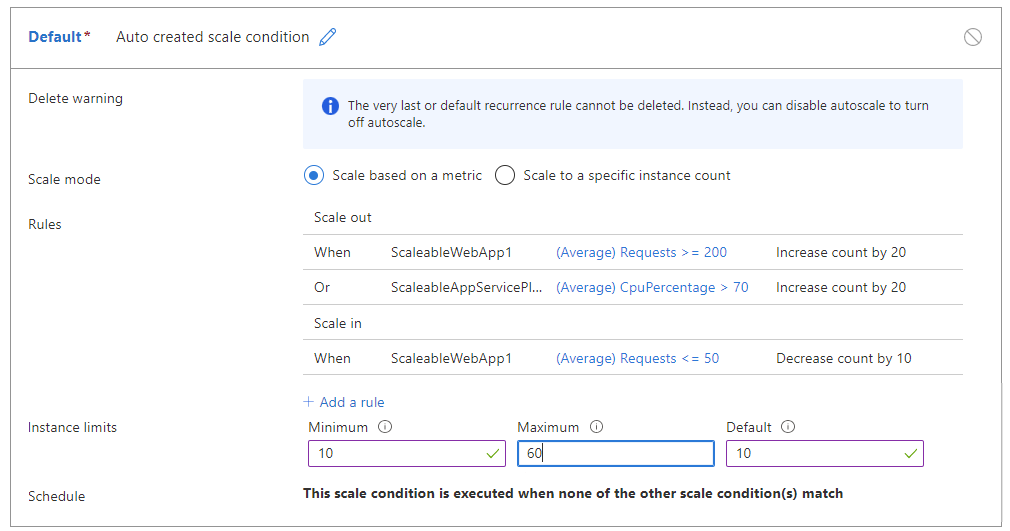
The table below shows a potential outcome of these autoscale rules:
| Time | Number of instances | CPU | Request count | Scale event | Resulting instances | Comments |
|---|---|---|---|---|---|---|
| T0 | 30 | 65% | 3000, or 100 per instance. | No scale event | 30 | |
| T1 | 30 | 65 | 1500 | Scale in by 3 instances | 27 | Scaling-in by 10 would cause an estimated CPU rise above 70%, leading to a scale-out event. |
At time T0, the app is running with 30 instances, a total request count of 3000, and a CPU usage of 65% per instance.
At T1, when the request count drops to 1500 requests, or 50 requests per instance, autoscale will try to scale in by 10 instances to 20. However, autoscale estimates that the CPU load for 20 instances will be above 70%, causing a scale-out event.
To avoid flapping, the autoscale engine estimates the CPU usage for instance counts above 20 until it finds an instance count where all metrics are with in the defined thresholds:
- Keep the CPU below 70%.
- Keep the number of requests per instance is above 50.
- Reduce the number of instances below 30.
In this situation, autoscale may scale in by 3, from 30 to 27 instances in order to satisfy the rules, even though the rule specifies a decrease of 10. A log message is written to the activity log with a description that includes Scale down will occur with updated instance count to avoid flapping
If autoscale can't find a suitable number of instances, it will skip the scale in event and reevaluate during the next cycle.
Note
If the autoscale engine detects that flapping could occur as a result of scaling to the target number of instances, it will also try to scale to a lower number of instances between the current count and the target count. If flapping does not occur within this range, autoscale will continue the scale operation with the new target.
Log files
Find flapping in the activity log with the following query:
// Activity log, CategoryValue: Autoscale
// Lists latest Autoscale operations from the activity log, with OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action
AzureActivity
|where CategoryValue =="Autoscale" and OperationNameValue =="Microsoft.Insights/AutoscaleSettings/Flapping/Action"
|sort by TimeGenerated desc
Below is an example of an activity log record for flapping:

{
"eventCategory": "Autoscale",
"eventName": "FlappingOccurred",
"operationId": "1111bbbb-22cc-dddd-ee33-ffffff444444",
"eventProperties":
"{"Description":"Scale down will occur with updated instance count to avoid flapping.
Resource: '/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/ed-rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan'.
Current instance count: '6',
Intended new instance count: '1'.
Actual new instance count: '4'",
"ResourceName":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourcegroups/rg-001/providers/Microsoft.Web/serverFarms/ScaleableAppServicePlan",
"OldInstancesCount":6,
"NewInstancesCount":4,
"ActiveAutoscaleProfile":{"Name":"Auto created scale condition",
"Capacity":{"Minimum":"1","Maximum":"30","Default":"1"},
"Rules":[{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Average","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"GreaterThanOrEqual","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Increase","Type":"ChangeCount","Value":"10","Cooldown":"PT1M"}},{"MetricTrigger":{"Name":"Requests","Namespace":"microsoft.web/sites","Resource":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","ResourceLocation":"West Central US","TimeGrain":"PT1M","Statistic":"Max","TimeWindow":"PT1M","TimeAggregation":"Maximum","Operator":"LessThan","Threshold":3.0,"Source":"/subscriptions/aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e/resourceGroups/ed-rg-001/providers/Microsoft.Web/sites/ScaleableWebApp1","MetricType":"MDM","Dimensions":[],"DividePerInstance":true},"ScaleAction":{"Direction":"Decrease","Type":"ChangeCount","Value":"5","Cooldown":"PT1M"}}]}}",
"eventDataId": "dddd3333-ee44-5555-66ff-777777aaaaaa",
"eventSubmissionTimestamp": "2022-09-13T07:20:41.1589076Z",
"resource": "scaleableappserviceplan",
"resourceGroup": "RG-001",
"resourceProviderValue": "MICROSOFT.WEB",
"subscriptionId": "aaaa0a0a-bb1b-cc2c-dd3d-eeeeee4e4e4e",
"activityStatusValue": "Succeeded"
}
Next steps
To learn more about autoscale, see the following resources: