Publish machine learning pipelines
APPLIES TO:  Python SDK azureml v1
Python SDK azureml v1
This article will show you how to share a machine learning pipeline with your colleagues or customers.
Machine learning pipelines are reusable workflows for machine learning tasks. One benefit of pipelines is increased collaboration. You can also version pipelines, allowing customers to use the current model while you're working on a new version.
Prerequisites
Create an Azure Machine Learning workspace to hold all your pipeline resources
Configure your development environment to install the Azure Machine Learning SDK, or use an Azure Machine Learning compute instance with the SDK already installed
Create and run a machine learning pipeline, such as by following Tutorial: Build an Azure Machine Learning pipeline for batch scoring. For other options, see Create and run machine learning pipelines with Azure Machine Learning SDK
Publish a pipeline
Once you have a pipeline up and running, you can publish a pipeline so that it runs with different inputs. For the REST endpoint of an already published pipeline to accept parameters, you must configure your pipeline to use PipelineParameter objects for the arguments that will vary.
To create a pipeline parameter, use a PipelineParameter object with a default value.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Add this
PipelineParameterobject as a parameter to any of the steps in the pipeline as follows:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Publish this pipeline that will accept a parameter when invoked.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")After you publish your pipeline, you can check it in the UI. Pipeline ID is the unique identified of the published pipeline.
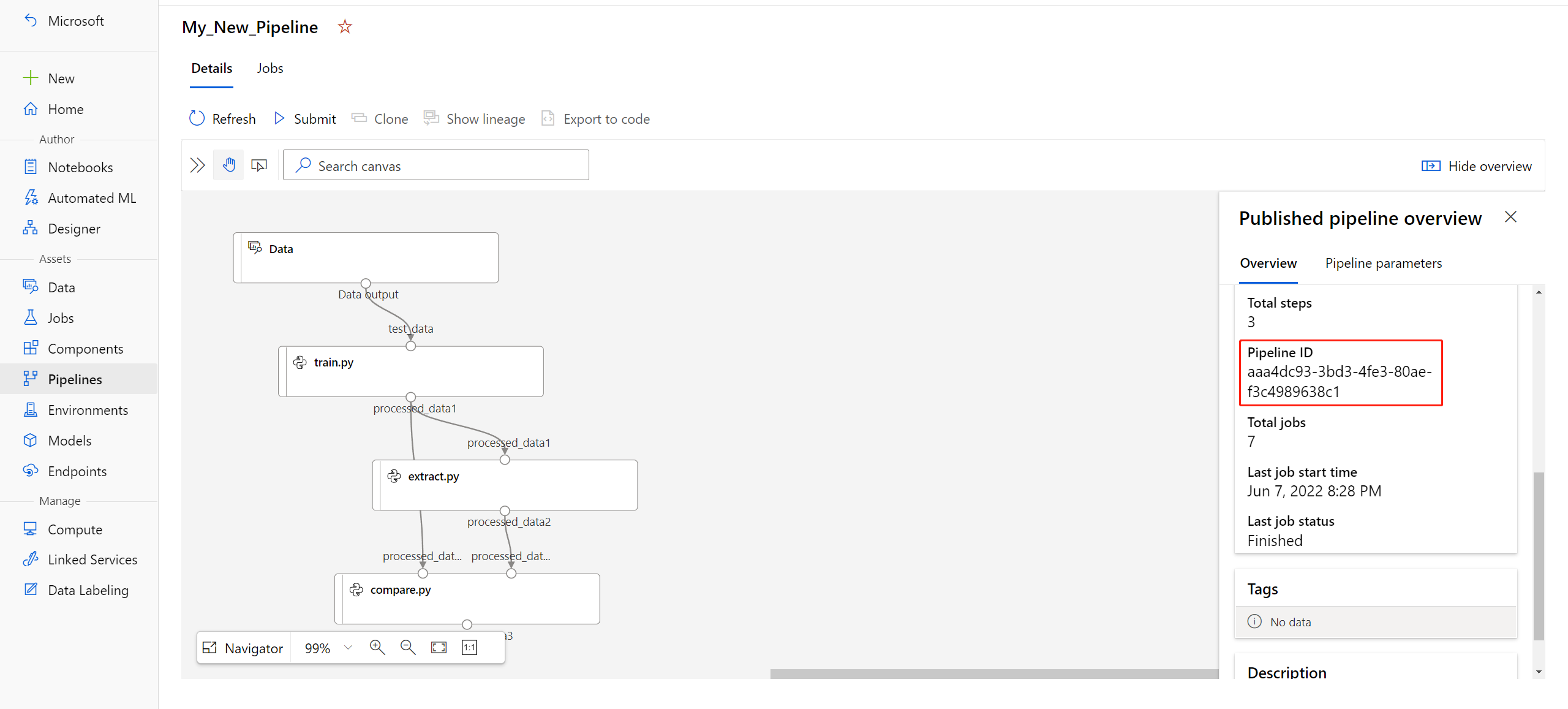

Run a published pipeline
All published pipelines have a REST endpoint. With the pipeline endpoint, you can trigger a run of the pipeline from any external systems, including non-Python clients. This endpoint enables "managed repeatability" in batch scoring and retraining scenarios.
Important
If you are using Azure role-based access control (Azure RBAC) to manage access to your pipeline, set the permissions for your pipeline scenario (training or scoring).
To invoke the run of the preceding pipeline, you need a Microsoft Entra authentication header token. Getting such a token is described in the AzureCliAuthentication class reference and in the Authentication in Azure Machine Learning notebook.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
The json argument to the POST request must contain, for the ParameterAssignments key, a dictionary containing the pipeline parameters and their values. In addition, the json argument may contain the following keys:
| Key | Description |
|---|---|
ExperimentName |
The name of the experiment associated with this endpoint |
Description |
Freeform text describing the endpoint |
Tags |
Freeform key-value pairs that can be used to label and annotate requests |
DataSetDefinitionValueAssignments |
Dictionary used for changing datasets without retraining (see discussion below) |
DataPathAssignments |
Dictionary used for changing datapaths without retraining (see discussion below) |
Run a published pipeline using C#
The following code shows how to call a pipeline asynchronously from C#. The partial code snippet just shows the call structure and isn't part of a Microsoft sample. It doesn't show complete classes or error handling.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Run a published pipeline using Java
The following code shows a call to a pipeline that requires authentication (see Set up authentication for Azure Machine Learning resources and workflows). If your pipeline is deployed publicly, you don't need the calls that produce authKey. The partial code snippet doesn't show Java class and exception-handling boilerplate. The code uses Optional.flatMap for chaining together functions that may return an empty Optional. The use of flatMap shortens and clarifies the code, but note that getRequestBody() swallows exceptions.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Changing datasets and datapaths without retraining
You may want to train and inference on different datasets and datapaths. For instance, you may wish to train on a smaller dataset but inference on the complete dataset. You switch datasets with the DataSetDefinitionValueAssignments key in the request's json argument. You switch datapaths with DataPathAssignments. The technique for both is similar:
In your pipeline definition script, create a
PipelineParameterfor the dataset. Create aDatasetConsumptionConfigorDataPathfrom thePipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)In your ML script, access the dynamically specified dataset using
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...Notice that the ML script accesses the value specified for the
DatasetConsumptionConfig(tabular_dataset) and not the value of thePipelineParameter(tabular_ds_param).In your pipeline definition script, set the
DatasetConsumptionConfigas a parameter to thePipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])To switch datasets dynamically in your inferencing REST call, use
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
The notebooks Showcasing Dataset and PipelineParameter and Showcasing DataPath and PipelineParameter have complete examples of this technique.
Create a versioned pipeline endpoint
You can create a Pipeline Endpoint with multiple published pipelines behind it. This technique gives you a fixed REST endpoint as you iterate on and update your ML pipelines.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Submit a job to a pipeline endpoint
You can submit a job to the default version of a pipeline endpoint:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
You can also submit a job to a specific version:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
The same can be accomplished using the REST API:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Use published pipelines in the studio
You can also run a published pipeline from the studio:
Sign in to Azure Machine Learning studio.
On the left, select Endpoints.
On the top, select Pipeline endpoints.
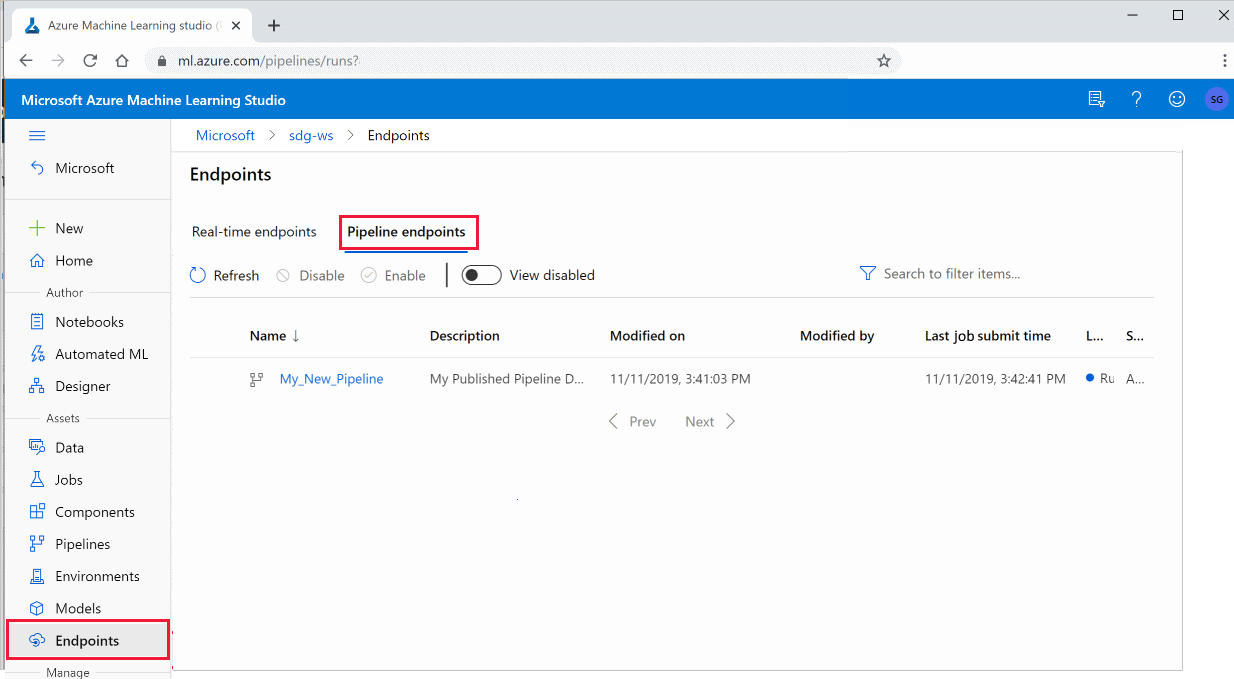
Select a specific pipeline to run, consume, or review results of previous runs of the pipeline endpoint.
Disable a published pipeline
To hide a pipeline from your list of published pipelines, you disable it, either in the studio or from the SDK:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
You can enable it again with p.enable(). For more information, see PublishedPipeline class reference.
Next steps
- Use these Jupyter notebooks on GitHub to explore machine learning pipelines further.
- See the SDK reference help for the azureml-pipelines-core package and the azureml-pipelines-steps package.
- See the how-to for tips on debugging and troubleshooting pipelines.