Reliability in Azure HDInsight
This article describes reliability support in Azure HDInsight, and covers availability zones and cross-region recovery and business continuity. For a more detailed overview of reliability in Azure, see Azure reliability.
Availability zone support
Azure availability zones are at least three physically separate groups of datacenters within each Azure region. Datacenters within each zone are equipped with independent power, cooling, and networking infrastructure. In the case of a local zone failure, availability zones are designed so that if the one zone is affected, regional services, capacity, and high availability are supported by the remaining two zones.
Failures can range from software and hardware failures to events such as earthquakes, floods, and fires. Tolerance to failures is achieved with redundancy and logical isolation of Azure services. For more detailed information on availability zones in Azure, see Regions and availability zones.
Azure availability zones-enabled services are designed to provide the right level of reliability and flexibility. They can be configured in two ways. They can be either zone redundant, with automatic replication across zones, or zonal, with instances pinned to a specific zone. You can also combine these approaches. For more information on zonal vs. zone-redundant architecture, see Recommendations for using availability zones and regions.
Azure HDInsight supports a zonal deployment configuration. Azure HDInsight cluster nodes are placed in a single zone that you select in the selected region. A zonal HDInsight cluster is isolated from any outages that occur in other zones. However, if an outage impacts the specific zone chosen for the HDInsight cluster, the cluster won't be available. This deployment model provides inexpensive, low latency network connectivity within the cluster. Replicating this deployment model into multiple availability zones can provide a higher level of availability to protect against hardware failure.
Important
For deployments where users don't specify a specific zone, node types are not zone resilient and can experience downtime during an outage in any zone in that region.
Prerequisites
Availability zones are only supported for clusters created after June 15, 2023. Availability zone settings can't be updated after the cluster is created. You also can't update an existing, non-availability zone cluster to use availability zones.
Clusters must be created under a custom VNet.
You need to bring your own SQL DB for Ambari DB and external metastore, such as Hive metastore, so that you can config these DBs in the same availability zone.
Your HDInsight clusters must be created with the availability zone option in one of the following regions:
- Australia East
- Brazil South
- Canada Central
- Central US
- East US
- East US 2
- France Central
- Germany West Central
- Japan East
- Korea Central
- North Europe
- Qatar Central
- Southeast Asia
- South Central US
- UK South
- US Gov Virginia
- West Europe
- West US 2
Create an HDInsight cluster using availability zone
You can use Azure Resource Manager (ARM) template to launch an HDInsight cluster into a specified availability zone.
In the resources section, you need to add a section of ‘zones’ and provide which availability zone you want this cluster to be deployed into.
"resources": [
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('cluster name')]",
"location": "East US 2",
"zones": [
"1"
],
}
]
Verify nodes within one availability Zone across zones
When the HDInsight cluster is ready, you can check the location to see which availability zone they're deployed in.

Get API response:
[
{
"location": "East US 2",
"zones": [
"1"
],
}
]
Scale up the cluster
You can scale up an HDInsight cluster with more worker nodes. The newly added worker nodes will be placed in the same availability zone of this cluster.
Availability zone migration
Azure HDInsight clusters currently doesn't support in-place migration of existing cluster instances to availability zone support. However, you can choose to recreate your cluster, and choose a different availability zone or region during the cluster creation. A secondary standby cluster in a different region and a different availability zone can be used in disaster recovery scenarios.
Zone down experience
When an availability zone goes down:
- You can't ssh to this cluster.
- You can't delete or scale up or scale down this cluster.
- You can't submit jobs or see job history.
- You still can submit new cluster creation request in a different region.
Cross-region disaster recovery and business continuity
Disaster recovery (DR) is about recovering from high-impact events, such as natural disasters or failed deployments that result in downtime and data loss. Regardless of the cause, the best remedy for a disaster is a well-defined and tested DR plan and an application design that actively supports DR. Before you begin to think about creating your disaster recovery plan, see Recommendations for designing a disaster recovery strategy.
When it comes to DR, Microsoft uses the shared responsibility model. In a shared responsibility model, Microsoft ensures that the baseline infrastructure and platform services are available. At the same time, many Azure services don't automatically replicate data or fall back from a failed region to cross-replicate to another enabled region. For those services, you are responsible for setting up a disaster recovery plan that works for your workload. Most services that run on Azure platform as a service (PaaS) offerings provide features and guidance to support DR and you can use service-specific features to support fast recovery to help develop your DR plan.
Azure HDInsight clusters depend on many Azure services like storage, databases, Active Directory, Active Directory Domain Services, networking, and Key Vault. A well-designed, highly available, and fault-tolerant analytics application should be designed with enough redundancy to withstand regional or local disruptions in one or more of these services. This section gives an overview of best practices, single and multi region availability, and optimization options for business continuity planning.
Disaster recovery in multi-region geography
Improving business continuity using cross region high availability disaster recovery requires architectural designs of higher complexity and higher cost. The following tables detail some technical areas that may increase total cost of ownership.
Cost optimizations
| Area | Cause of cost escalation | Optimization strategies |
|---|---|---|
| Data Storage | Duplicating primary data/tables in a secondary region | Replicate only curated data |
| Data Egress | Outbound cross region data transfers come at a price. Review Bandwidth pricing guidelines | Replicate only curated data to reduce the region egress footprint |
| Cluster Compute | Additional HDInsight cluster/s in secondary region | Use automated scripts to deploy secondary compute after primary failure. Use Autoscaling to keep secondary cluster size to a minimum. Use cheaper VM SKUs. Create secondaries in regions where VM SKUs may be discounted. |
| Authentication | Multiuser scenarios in the secondary region incurs extra Microsoft Entra Domain Services setups | Avoid multiuser setups in secondary region. |
Complexity optimizations
| Area | Cause of complexity escalation | Optimization strategies |
|---|---|---|
| Read Write patterns | Requiring both primary and secondary to be Read and Write enabled | Design the secondary to be read only |
| Zero RPO & RTO | Requiring zero data loss (RPO=0) and zero downtime (RTO=0) | Design RPO and RTO in ways to reduce the number of components that need to fail over. For more information on RTO and RPO, see Recovery objectives. |
| Business functionality | Requiring full business functionality of primary in secondary | Evaluate if you can run with bare minimum critical subset of the business functionality in secondary. |
| Connectivity | Requiring all upstream and downstream systems from primary to connect to the secondary as well | Limit the secondary connectivity to a bare minimum critical subset. |
When you create your multi region disaster recovery plan, consider the following recommendations:
Determine the minimal business functionality you need if there is a disaster and why. For example, evaluate if you need failover capabilities for the data transformation layer (shown in yellow) and the data serving layer (shown in blue), or if you only need failover for the data service layer.
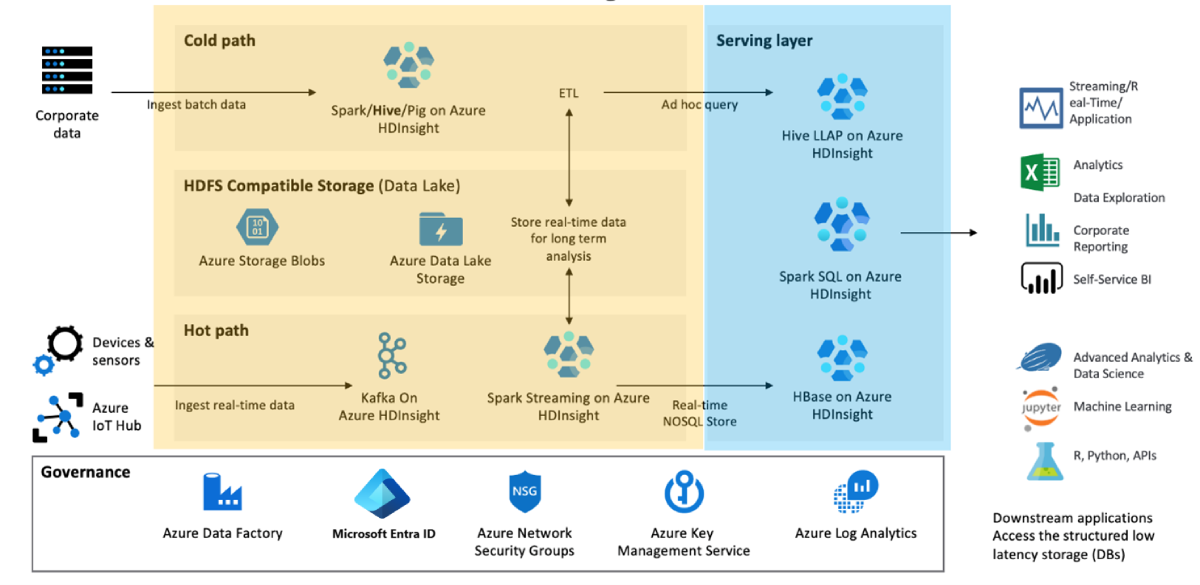
Segment your clusters based on workload, development lifecycle, and departments. Having more clusters reduces the chances of a single large failure affecting multiple different business processes.
Make your secondary regions read-only. Failover regions with both read and write capabilities can lead to complex architectures.
Transient clusters are easier to manage when there is a disaster. Design your workloads in a way that clusters can be cycled and no state is maintained in clusters.
Often workloads are left unfinished if there is a disaster and need to restart in the new region. Design your workloads to be idempotent in nature.
Use automation during cluster deployments and ensure cluster configuration settings are scripted as far as possible to ensure rapid and fully automated deployment if there is a disaster.
Outage detection, notification, and management
Use Azure monitoring tools on HDInsight to detect abnormal behavior in the cluster and set corresponding alert notifications. You can deploy the pre-configured HDInsight cluster-specific management solutions that collect important performance metrics of the specific cluster type. For more information, see Azure Monitoring for HDInsight.
Subscribe to Azure health alerts to be notified about service issues, planned maintenance, health and security advisories for a subscription, service, or region. Health notifications that include the issue cause and resolute ETA help you to better execute failover and failbacks. For more information, see Azure Service Health documentation.
Disaster recovery in single-region geography
Each component in a basic HDInsight system has its own single region fault tolerance mechanisms. Keep in mind that doesn't always take a catastrophic event to impact business functionality. Service incidents in one or more of the following services in a single region can also lead to loss of expected business functionality.
Compute (virtual machines): Azure HDInsight cluster. HDInsight offers an availability SLA of 99.9%. To provide high availability in a single deployment, HDInsight is accompanied by many services that are in high availability mode by default. Fault tolerance mechanisms in HDInsight are provided by both Microsoft and Apache OSS ecosystem high availability services.
The following infrastructure components are designed to be highly available:
- Active and Standby Headnodes
- Multiple Gateway Nodes
- Three Zookeeper Quorum nodes
- Worker Nodes distributed by fault and update domains
The following services are also designed to be highly available:
- Apache Ambari Server
- Application timeline severs for YARN
- Job History Server for Hadoop MapReduce
- Apache Livy
- HDFS
- YARN Resource Manager
- HBase Master
To learn more, see high availability services supported by Azure HDInsight.
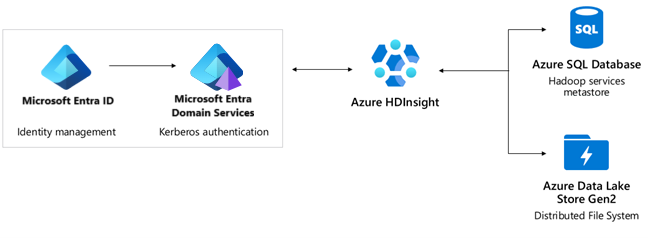
Metastore(s): Azure SQL Database. HDInsight uses Azure SQL Database as a metastore, which provides an SLA of 99.99%. Three replicas of data persist within a data center with synchronous replication. If there is a replica loss, an alternate replica is served seamlessly. Active geo-replication is supported out of the box with a maximum of four data centers. When there is a failover, either manual or data center, the first replica in the hierarchy automatically becomes read-write capable. For more information, see Azure SQL Database business continuity.
Storage: Azure Data Lake Gen2 or Blob storage. HDInsight recommends Azure Data Lake Storage Gen2 as the underlying storage layer. Azure Storage, including Azure Data Lake Storage Gen2, provides an SLA of 99.9%. HDInsight uses the LRS service in which three replicas of data persist within a data center, and replication is synchronous. When there is a replica loss, a replica is served seamlessly.
Authentication: Microsoft Entra ID, Microsoft Entra Domain Services, Enterprise Security Package.
- Microsoft Entra ID provides an SLA of 99.9%. Active Directory is a global service with multiple levels of internal redundancy and automatic recoverability. For more information, see how Microsoft in continually improving the reliability of Microsoft Entra ID.
- Microsoft Entra Domain Services provides an SLA of 99.9%. Microsoft Entra Domain Services is a highly available service hosted in globally distributed data centers. Replica sets are a preview feature in Microsoft Entra Domain Services that enables geographic disaster recovery if an Azure region goes offline. For more information, see replica sets concepts and features for Microsoft Entra Domain Services to learn more.
- Azure DNS provides an SLA of 100%. HDInsight uses Azure DNS in various places for domain name resolution.
Optional services, such as Azure Key Vault and Azure Data Factory.