Nóta
Aðgangur að þessari síðu krefst heimildar. Þú getur prófað aðskrá þig inn eða breyta skráasöfnum.
Aðgangur að þessari síðu krefst heimildar. Þú getur prófað að breyta skráasöfnum.
Azure Synapse Analytics offers various analytics engines to help you ingest, transform, model, analyze, and serve your data. Apache Spark pool offers open-source big data compute capabilities. After you create an Apache Spark pool in your Synapse workspace, data can be loaded, modeled, processed, and served to obtain insights.
This quickstart describes the steps to create an Apache Spark pool in a Synapse workspace by using Synapse Studio.
Important
Billing for Spark instances is prorated per minute, whether you are using them or not. Be sure to shutdown your Spark instance after you have finished using it, or set a short timeout. For more information, see the Clean up resources section of this article.
Note
Synapse Studio will continue to support terraform or bicep-based configuration files.
If you don't have an Azure subscription, create a free account before you begin.
Prerequisites
- You'll need an Azure subscription. If needed, create a free Azure account
- You'll be using the Synapse workspace.
Sign in to the Azure portal
Sign in to the Azure portal
Navigate to the Synapse workspace
Navigate to the Synapse workspace where the Apache Spark pool will be created by typing the service name (or resource name directly) into the search bar.
From the list of workspaces, type the name (or part of the name) of the workspace to open. For this example, we use a workspace named contosoanalytics.



Launch Synapse Studio
From the workspace overview, select the Workspace web URL to open Synapse Studio.

Create the Apache Spark pool in Synapse Studio
Important
Azure Synapse Runtime for Apache Spark 2.4 has been deprecated and officially not supported since September 2023. Given Spark 3.1 and Spark 3.2 are also End of Support announced, we recommend customers migrate to Spark 3.3.
On the Synapse Studio home page, navigate to the Management Hub in the left navigation by selecting the Manage icon.

Once in the Management Hub, navigate to the Apache Spark pools section to see the current list of Apache Spark pools that are available in the workspace.

Select + New and the new Apache Spark pool create wizard will appear.
Enter the following details in the Basics tab:
Setting Suggested value Description Apache Spark pool name A valid pool name, like contososparkThis is the name that the Apache Spark pool will have. Node size Small (4 vCPU / 32 GB) Set this to the smallest size to reduce costs for this quickstart Autoscale Disabled We won't need autoscale in this quickstart Number of nodes 8 Use a small size to limit costs in this quickstart Dynamically allocate executors Disabled This setting maps to the dynamic allocation property in Spark configuration for Spark Application executors allocation. We won't need autoscale in this quickstart. 
Important
There are specific limitations for the names that Apache Spark pools can use. Names must contain letters or numbers only, must be 15 or less characters, must start with a letter, not contain reserved words, and be unique in the workspace.
In the next tab, Additional settings, leave all settings as defaults.
Select Tags. Consider using Azure tags. For example, the "Owner" or "CreatedBy" tag to identify who created the resource, and the "Environment" tag to identify whether this resource is in Production, Development, etc. For more information, see Develop your naming and tagging strategy for Azure resources. When ready, select Review + create.
In the Review + create tab, make sure that the details look correct based on what was previously entered, and press Create.
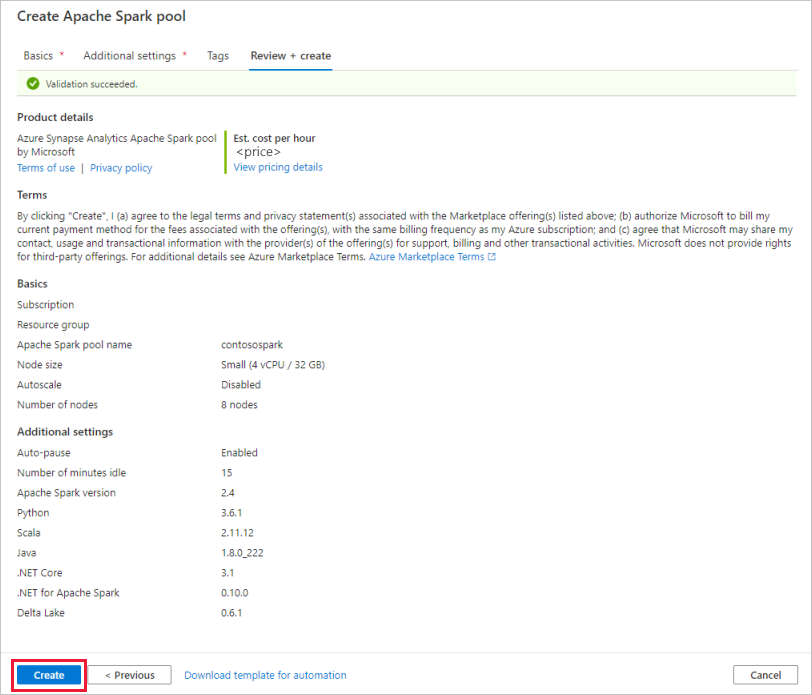
The Apache Spark pool will start the provisioning process.
Once the provisioning is complete, the new Apache Spark pool will appear in the list.






Clean up Apache Spark pool resources using Synapse Studio
The following steps delete the Apache Spark pool from the workspace using Synapse Studio.
Warning
Deleting a Spark pool will remove the analytics engine from the workspace. It will no longer be possible to connect to the pool, and all queries, pipelines, and notebooks that use this Spark pool will no longer work.
If you want to delete the Apache Spark pool, do the following steps:
Navigate to the Apache Spark pools in the Management Hub in Synapse Studio.
Select the ellipsis next to the Apache pool to be deleted (in this case, contosospark) to show the commands for the Apache Spark pool.

Select Delete.
Confirm the deletion, and press Delete button.
When the process completes successfully, the Apache Spark pool will no longer be listed in the workspace resources.
