Per verificare che le applicazioni e i servizi funzionino correttamente, è possibile usare il modello di monitoraggio degli endpoint di integrità. Questo modello specifica l'uso di controlli funzionali in un'applicazione. Gli strumenti esterni possono accedere a questi controlli a intervalli regolari tramite endpoint esposti.
Contesto e problema
È consigliabile monitorare le applicazioni Web e i servizi back-end. Il monitoraggio garantisce che le applicazioni e i servizi siano disponibili e funzionino correttamente. I requisiti aziendali includono spesso il monitoraggio.
A volte è più difficile monitorare i servizi cloud rispetto ai servizi locali. Un motivo è che non si ha il controllo completo dell'ambiente di hosting. Un altro è che i servizi dipendono in genere da altri servizi forniti dai fornitori di piattaforme e da altri.
Molti fattori influiscono sulle applicazioni ospitate nel cloud. Ad esempio, la latenza di rete, le prestazioni e la disponibilità dei sistemi di calcolo e archiviazione sottostanti e la larghezza di banda di rete tra di esse. Un servizio può non riuscire completamente o parzialmente a causa di uno di questi fattori. Per garantire un livello di disponibilità necessario, è necessario verificare a intervalli regolari che il servizio funzioni correttamente. Il contratto di servizio potrebbe specificare il livello che è necessario soddisfare.
Soluzione
Implementare il monitoraggio dell'integrità inviando richieste a un endpoint nell'applicazione. L'applicazione deve eseguire i controlli necessari e quindi restituire un'indicazione del relativo stato.
Un controllo di monitoraggio dell'integrità combina in genere due fattori:
- Verifica (se presente) che l'applicazione o il servizio esegua in risposta alla richiesta all'endpoint di verifica dell'integrità
- L'analisi dei risultati dallo strumento o dal framework che esegue il controllo di verifica dell'integrità
Il codice di risposta indica lo stato dell'applicazione. Facoltativamente, il codice di risposta fornisce anche lo stato dei componenti e dei servizi usati dall'app. Lo strumento di monitoraggio o il framework esegue il controllo della latenza o del tempo di risposta.
La figura seguente offre una panoramica del modello.
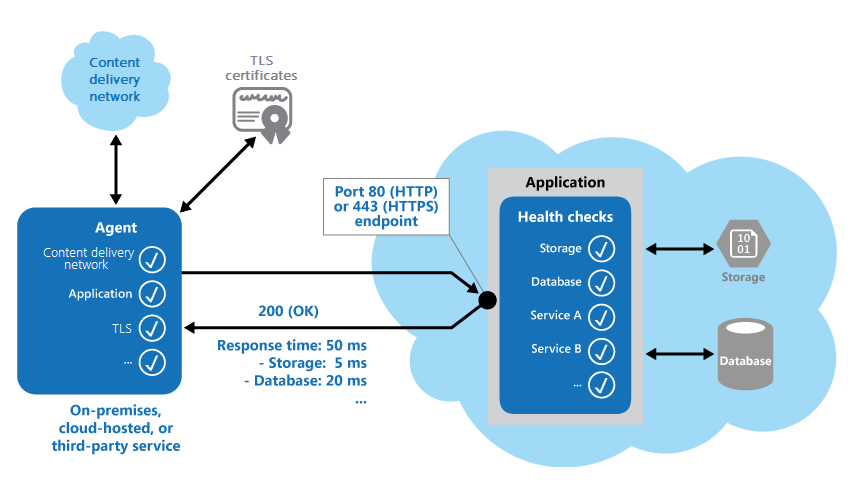
Il codice di monitoraggio dell'integrità nell'applicazione potrebbe anche eseguire altri controlli per determinare:
- Disponibilità e tempo di risposta dell'archiviazione cloud o di un database.
- Stato di altre risorse o servizi usati dall'applicazione. Queste risorse e servizi potrebbero trovarsi nell'applicazione o all'esterno.
Sono disponibili servizi e strumenti che monitorano le applicazioni Web inviando una richiesta a un set configurabile di endpoint. Questi servizi e strumenti valutano quindi i risultati rispetto a un set di regole configurabili. È relativamente semplice creare un endpoint di servizio allo scopo esclusivo di eseguire alcuni test funzionali in un sistema.
I controlli tipici eseguiti da strumenti di monitoraggio includono:
- Convalida del codice di risposta. Ad esempio, una risposta HTTP di 200 (OK) indica che l'applicazione ha risposto senza errori. Il sistema di monitoraggio potrebbe anche controllare altri codici di risposta per offrire risultati più completi.
- Controllo del contenuto della risposta per rilevare gli errori, anche quando il codice di stato è 200 (OK). Controllando il contenuto, è possibile rilevare errori che interessano solo una sezione della pagina Web o della risposta del servizio restituita. Ad esempio, è possibile controllare il titolo di una pagina o cercare una frase specifica che indica che l'app ha restituito la pagina corretta.
- Misurazione del tempo di risposta. Il valore include la latenza di rete e il tempo impiegato dall'applicazione per emettere la richiesta. Un valore di incremento può indicare un problema emergente con l'applicazione o la rete.
- Controllo delle risorse o dei servizi che si trovano all'esterno dell'applicazione. Un esempio è una rete per la distribuzione di contenuti usata dall'applicazione per distribuire contenuto da cache globali.
- Verifica della scadenza dei certificati TLS.
- Misurazione del tempo di risposta di una ricerca DNS per l'URL dell'applicazione. Questo controllo misura gli errori DNS e la latenza DNS.
- Convalida dell'URL restituito da una ricerca DNS. Convalidando, è possibile assicurarsi che le voci siano corrette. È anche possibile evitare il reindirizzamento di richieste dannose che potrebbero causare un attacco al server DNS.
Laddove possibile, è anche utile eseguire questi controlli da posizioni locali o ospitate diverse e quindi confrontare i tempi di risposta. Idealmente, è consigliabile monitorare le applicazioni da posizioni vicine ai clienti. Si ottiene quindi una visualizzazione accurata delle prestazioni da ogni posizione. Questa pratica fornisce un meccanismo di controllo più affidabile. I risultati possono anche aiutare a prendere le decisioni seguenti:
- Dove distribuire l'applicazione
- Indica se distribuirlo in più data center
Per assicurarsi che l'applicazione funzioni correttamente per tutti i clienti, eseguire test su tutte le istanze del servizio usate dai clienti. Ad esempio, se l'archiviazione dei clienti viene distribuita in più account di archiviazione, il processo di monitoraggio deve controllare ogni account.
Considerazioni e problemi
Quando si decide come implementare questo modello, tenere presente quanto segue:
Si pensi a come convalidare la risposta. Ad esempio, determinare se un codice di stato 200 (OK) è sufficiente per verificare che l'applicazione funzioni correttamente. Controllare il codice di stato è l'implementazione minima di questo modello. Un codice di stato fornisce una misura di base della disponibilità dell'applicazione. Tuttavia, un codice fornisce poche informazioni sulle operazioni, le tendenze e i possibili problemi imminenti nell'applicazione.
Determinare il numero di endpoint da esporre per un'applicazione. Un approccio consiste nell'esporre almeno un endpoint per i servizi di base usati dall'applicazione e un altro per i servizi con priorità inferiore. Con questo approccio, è possibile assegnare livelli di importanza diversi a ogni risultato di monitoraggio. Valutare anche la possibilità di esporre endpoint aggiuntivi. È possibile esporre uno per ogni servizio principale per aumentare la granularità del monitoraggio. Ad esempio, un controllo di verifica dell'integrità potrebbe controllare il database, l'archiviazione e un servizio di geocodifica esterno usato da un'applicazione. Ognuno potrebbe richiedere un livello diverso di tempo di attività e tempo di risposta. Il servizio di geocodifica o altre attività in background potrebbero non essere disponibili per alcuni minuti. Ma l'applicazione potrebbe essere ancora integra.
Decidere se usare lo stesso endpoint per il monitoraggio e per l'accesso generale. È possibile usare lo stesso endpoint per entrambi, ma progettare un percorso specifico per i controlli di verifica dell'integrità. Ad esempio, è possibile usare /health nell'endpoint di accesso generale. Con questo approccio, gli strumenti di monitoraggio possono eseguire alcuni test funzionali nell'applicazione. Gli esempi includono la registrazione di un nuovo utente, l'accesso e l'inserimento di un ordine di test. Allo stesso tempo, è anche possibile verificare che l'endpoint di accesso generale sia disponibile.
Determinare il tipo di informazioni da raccogliere nel servizio in risposta alle richieste di monitoraggio. È anche necessario determinare come restituire queste informazioni. La maggior parte degli strumenti e dei framework esistenti verificano solo il codice di stato HTTP restituito dall'endpoint. Per restituire e convalidare informazioni aggiuntive, potrebbe essere necessario creare un servizio o un'utilità di monitoraggio personalizzata.
Determinare la quantità di informazioni da raccogliere. L'esecuzione di un'elaborazione eccessiva durante il controllo può sovraccaricare l'applicazione e influire sugli altri utenti. Il tempo di elaborazione potrebbe anche superare il timeout del sistema di monitoraggio. Di conseguenza, il sistema potrebbe contrassegnare l'applicazione come non disponibile. La maggior parte delle applicazioni include strumentazione, ad esempio gestori di errori e contatori delle prestazioni. Questi strumenti possono registrare le prestazioni e informazioni dettagliate sugli errori, che potrebbero essere sufficienti. Prendere in considerazione l'uso di questi dati invece di restituire informazioni aggiuntive da un controllo di verifica dell'integrità.
Prendere in considerazione la memorizzazione nella cache dello stato dell'endpoint. L'esecuzione frequente del controllo integrità potrebbe risultare costosa. Ad esempio, se lo stato di integrità viene segnalato tramite un dashboard, non si vuole che ogni richiesta al dashboard attivi un controllo integrità. Controllare periodicamente l'integrità del sistema e memorizzare nella cache lo stato. Esporre un endpoint che restituisca lo stato memorizzato nella cache.
Pianificare la configurazione della sicurezza per gli endpoint di monitoraggio. Configurando la sicurezza, è possibile proteggere gli endpoint dall'accesso pubblico, che potrebbe:
- Esporre l'applicazione a attacchi dannosi.
- Rischia l'esposizione di informazioni riservate.
- Attirare gli attacchi Denial of Service (DoS).
In genere, la sicurezza viene configurata nella configurazione dell'applicazione. È quindi possibile aggiornare facilmente le impostazioni senza riavviare l'applicazione. Considerare l'uso di una o più tecniche riportate di seguito:
Proteggere l'endpoint richiedendo l'autenticazione. Se il servizio di monitoraggio o lo strumento supporta l'autenticazione, è possibile usare una chiave di sicurezza di autenticazione nell'intestazione della richiesta. È anche possibile passare le credenziali con la richiesta. Quando si usa l'autenticazione, considerare come accedere agli endpoint del controllo integrità. Ad esempio, app Azure Servizio dispone di un controllo integrità predefinito che si integra con le funzionalità di autenticazione e autorizzazione servizio app.
Usare un endpoint oscuro o nascosto. Ad esempio, esporre l'endpoint in un indirizzo IP diverso da quello usato dall'URL dell'applicazione predefinito. Configurare l'endpoint su una porta HTTP non standard. Prendere in considerazione anche l'uso di un percorso complesso per la pagina di test. In genere è possibile specificare indirizzi e porte endpoint aggiuntivi nella configurazione dell'applicazione. Se necessario, è possibile aggiungere voci per questi endpoint al server DNS. Evitare quindi di dover specificare direttamente l'indirizzo IP.
Esporre un metodo su un endpoint che accetta un parametro, ad esempio un valore di chiave o di modalità di operazione. Quando arriva una richiesta, il codice può eseguire test specifici che dipendono dal valore del parametro . Il codice può restituire un errore 404 (Non trovato) se non riconosce il valore del parametro. È possibile definire i valori dei parametri nella configurazione dell'applicazione.
Usare un endpoint separato che esegue test funzionali di base senza compromettere il funzionamento dell'applicazione. Con questo approccio, è possibile ridurre l'impatto di un attacco DoS. Evitare se possibile di usare un test che possa esporre informazioni riservate. In alcuni casi è necessario restituire informazioni utili per un utente malintenzionato. In questo caso, considerare come proteggere l'endpoint e i dati da accessi non autorizzati. Affidarsi all'oscurità non è sufficiente. Prendere in considerazione anche l'uso di una connessione HTTPS e la crittografia dei dati sensibili, anche se questo approccio aumenta il carico sul server.
Decidere come assicurarsi che l'agente di monitoraggio funzioni correttamente. Un approccio consiste nell'esporre un endpoint che restituisce un valore dalla configurazione dell'applicazione o un valore casuale che è possibile usare per testare l'agente. Assicurarsi anche che il sistema di monitoraggio esegua controlli su se stesso. È possibile usare un test automatico o predefinito per impedire al sistema di monitoraggio di emettere risultati falsi positivi.
Quando usare questo modello
Questo modello è utile per:
- Monitorare applicazioni e siti Web per verificare la disponibilità.
- Monitorare applicazioni e siti Web per confermare il corretto funzionamento.
- Monitoraggio di servizi di livello intermedio o condivisi per rilevare e isolare gli errori che possono interrompere altre applicazioni.
- Integrare la strumentazione esistente nell'applicazione, ad esempio con contatori delle prestazioni e gestori degli errori. Il controllo di verifica dell'integrità non sostituisce i requisiti dell'applicazione per la registrazione e il controllo. La strumentazione offre informazioni utili per un framework esistente che monitora contatori e log degli errori per rilevare altri problemi. Tuttavia, la strumentazione non può fornire informazioni se un'applicazione non è disponibile.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello di monitoraggio degli endpoint di integrità può essere usato nella progettazione del carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Ad esempio:
| Concetto fondamentale | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| Le decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resilienti a malfunzionamenti e di assicurarsi che venga ripristinato in uno stato completamente funzionante dopo che si verifica un errore. | Questi endpoint supportano gli avvisi di affidabilità e le attività di dashboarding di un carico di lavoro. Possono anche essere usati come segnale per la correzione automatica. - RE:07 Auto-guarigione e auto-conservazione - STRATEGIA di monitoraggio e avviso RE:10 |
| L'eccellenza operativa consente di offrire la qualità del carico di lavoro attraverso processi standardizzati e coesione del team. | La standardizzazione degli endpoint di integrità da esporre e il livello di dettaglio nei risultati consentirà di valutare i problemi. - Sistema di monitoraggio OE:07 |
| L'efficienza delle prestazioni consente al carico di lavoro di soddisfare in modo efficiente le richieste tramite ottimizzazioni in termini di scalabilità, dati, codice. | Gli endpoint di integrità migliorano la logica di bilanciamento del carico instradando il traffico solo ai nodi verificati come integri. Con una configurazione aggiuntiva, è anche possibile ottenere metriche sulla capacità del nodo disponibile. - PE:05 Ridimensionamento e partizionamento |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Esempio
È possibile usare il middleware e le librerie dei controlli di integrità ASP.NET per segnalare l'integrità dei componenti dell'infrastruttura delle app. Questo framework consente di segnalare i controlli di integrità in modo coerente. Implementa molte delle procedure descritte in questo articolo. Ad esempio, i controlli di integrità ASP.NET includono controlli esterni, ad esempio connettività del database e concetti specifici, ad esempio probe di attività e conformità.
In GitHub sono disponibili diverse implementazioni di esempio che usano ASP.NET controlli di integrità.
Monitorare gli endpoint nelle applicazioni ospitate in Azure
Le opzioni per il monitoraggio degli endpoint nelle applicazioni di Azure includono:
- Usare le funzionalità di monitoraggio predefinite di Azure, ad esempio Monitoraggio di Azure.
- Usare un servizio di terze parti o un framework come Microsoft System Center Operations Manager.
- Creare un'utilità personalizzata o un servizio in esecuzione nel proprio server o in un server ospitato.
Anche se Azure offre opzioni di monitoraggio complete, è possibile usare servizi e strumenti aggiuntivi per fornire informazioni aggiuntive. Application Insights, una funzionalità di Monitoraggio, è progettata per i team di sviluppo. Questa funzionalità consente di comprendere le prestazioni dell'app e il modo in cui viene usata. Application Insights monitora i tassi di richiesta, i tempi di risposta, le percentuali di errore e le percentuali di dipendenza. Può essere utile per determinare se i servizi esterni rallentano l'utente.
Le condizioni che è possibile monitorare dipendono dal meccanismo di hosting scelto per l'applicazione. Tutte le opzioni in questa sezione supportano le regole di avviso. Una regola di avviso usa un endpoint Web specificato nelle impostazioni per il servizio. L'endpoint risponde in modo tempestivo, in modo che il sistema di avvisi possa rilevare il corretto funzionamento dell'applicazione. Per altre informazioni, vedere Creare una nuova regola di avviso.
Se si verifica un'interruzione importante, il traffico client deve essere instradabile a una distribuzione di applicazioni disponibile in altre aree o zone. Questa situazione è un buon caso per la connettività cross-premise e il bilanciamento del carico globale. La scelta dipende dal fatto che l'applicazione sia interna o esterna. Servizi come Frontdoor di Azure, Gestione traffico di Azure o reti per la distribuzione di contenuti possono instradare il traffico tra aree in base ai dati forniti dai probe di integrità.
Gestione traffico è un servizio di routing e bilanciamento del carico. Può usare un'ampia gamma di regole e impostazioni per distribuire le richieste a istanze specifiche dell'applicazione. Oltre al routing delle richieste, Gestione traffico può effettuare regolarmente il ping di un URL, una porta e un percorso relativo. Specificare le destinazioni ping con l'obiettivo di determinare quali istanze dell'applicazione sono attive e rispondono alle richieste. Se Gestione traffico rileva un codice di stato 200 (OK), contrassegna l'applicazione come disponibile. Con qualsiasi altro codice di stato, Gestione traffico contrassegna l'applicazione come offline. La console Gestione traffico visualizza lo stato di ogni applicazione. È possibile configurare ogni regola per reindirizzare le richieste ad altre istanze dell'applicazione che rispondono.
Gestione traffico attende un determinato periodo di tempo per ricevere una risposta dall'URL di monitoraggio. Assicurarsi che il codice di verifica dell'integrità venga eseguito in questa fase. Consentire la latenza di rete per il round trip da Gestione traffico all'applicazione e di nuovo.
Passaggi successivi
Le indicazioni seguenti sono utili per implementare questo modello:
- Linee guida sul monitoraggio dell'integrità nelle applicazioni basate su microservizi
- Monitoraggio dell'integrità delle applicazioni per l'affidabilità, parte di Azure Well-Architected Framework
- Creare una nuova regola di avviso