Suggerimenti sulle prestazioni per Azure Cosmos DB Sync Java SDK v2
SI APPLICA A: ![]() NoSQL
NoSQL
Importante
Questa non corrisponde alla versione più recente di Java SDK per Azure Cosmos DB. È consigliabile aggiornare il progetto a Java SDK v4 per Azure Cosmos DB e quindi leggere la guida dei suggerimenti relativi alle prestazioni di Java SDK v4 per Azure Cosmos DB. Seguire le istruzioni della guida alla migrazione a Java SDK v4 per Azure Cosmos DB e la guida relativa al confronto tra Reactor e RxJava.
Questi suggerimenti sulle prestazioni sono relativi solo ad Azure Cosmos DB Sync Java SDK v2. Per altre informazioni, vedere il repository Maven.
Importante
Il 29 febbraio 2024 Azure Cosmos DB Sync Java SDK v2.x verrà ritirato; l'SDK e tutte le applicazioni che usano l'SDK continueranno a funzionare; Azure Cosmos DB smetterà semplicemente di fornire manutenzione e supporto per questo SDK. È consigliabile seguire le istruzioni sopra riportate per eseguire la migrazione ad Azure Cosmos DB Java SDK v4.
Azure Cosmos DB è un database distribuito veloce e flessibile, facilmente scalabile e con latenza e velocità effettiva garantite. Non è necessario apportare modifiche significative all'architettura o scrivere codice complesso per ridimensionare il database con Azure Cosmos DB. Aumentare o ridurre le prestazioni è semplice come eseguire una singola chiamata API. Per altre informazioni, vedere Effettuare il provisioning della velocità effettiva per un contenitore oppure Effettuare il provisioning della velocità effettiva per un database. Tuttavia, dato che si accede ad Azure Cosmos DB tramite chiamate di rete, è possibile introdurre ottimizzazioni sul lato client per ottenere massime prestazioni durante l'uso di Azure Cosmos DB Sync Java SDK v2.
Se si vogliono migliorare le prestazioni del database, valutare le opzioni seguenti:
Rete
Modalità di connessione: usare DirectHttps
La modalità di connessione di un client ad Azure Cosmos DB influisce significativamente sulle prestazioni, in particolare in termini di latenza lato client osservata. È disponibile un'impostazione di configurazione chiave per la configurazione del parametro ConnectionPolicy lato client, ovvero ConnectionMode. Per ConnectionMode sono disponibili le due modalità seguenti:
-
La modalità Gateway è supportata in tutte le piattaforme SDK ed è l'impostazione predefinita configurata. Se l'applicazione è in esecuzione in una rete aziendale con limitazioni rigide del firewall, la modalità Gateway è la scelta migliore perché usa la porta HTTPS standard e un singolo endpoint. A livello di prestazioni, tuttavia, la modalità Gateway prevede un hop di rete aggiuntivo ogni volta che i dati vengono letti o scritti in Azure Cosmos DB. La modalità DirectHttps offre quindi prestazioni migliori grazie al numero minore di hop di rete.
Azure Cosmos DB Sync Java SDK v2 usa HTTPS come protocollo di trasporto. Il protocollo HTTPS usa TLS per l'autenticazione iniziale e la crittografia del traffico. Quando si usa Azure Cosmos DB Sync Java SDK v2, è necessario aprire solo la porta HTTPS 443.
L'impostazione ConnectionMode viene configurata durante la creazione dell'istanza di DocumentClient con il parametro ConnectionPolicy.
Sync Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
public ConnectionPolicy getConnectionPolicy() { ConnectionPolicy policy = new ConnectionPolicy(); policy.setConnectionMode(ConnectionMode.DirectHttps); policy.setMaxPoolSize(1000); return policy; } ConnectionPolicy connectionPolicy = new ConnectionPolicy(); DocumentClient client = new DocumentClient(HOST, MASTER_KEY, connectionPolicy, null);
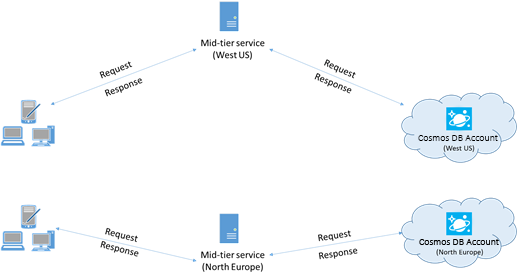
Collocare i client nella stessa area di Azure per ottenere prestazioni migliori
Quando possibile, posizionare eventuali applicazioni che chiamano Azure Cosmos DB nella stessa area del database Azure Cosmos DB. Per un confronto approssimativo, le chiamate ad Azure Cosmos DB eseguite nella stessa area vengono completate entro 1-2 millisecondi, mentre la latenza tra la costa occidentale e quella orientale degli Stati Uniti è >50 millisecondi. Questa latenza può variare da richiesta a richiesta, in base alla route seguita dalla richiesta durante il passaggio dal client al limite del data center di Azure. È possibile ottenere la latenza più bassa possibile assicurandosi che l'applicazione chiamante si trovi nella stessa area di Azure in cui si trova l'endpoint di Azure Cosmos DB con provisioning. Per un elenco delle aree disponibili, vedere Aree di Azure.
Uso dell'SDK
Installare l'SDK più recente
Agli SDK di Azure Cosmos DB vengono apportati continui miglioramenti per offrire prestazioni ottimali. Per determinare i miglioramenti più recenti dell'SDK , visitare Azure Cosmos DB SDK.
Usare un client Azure Cosmos DB singleton per la durata dell'applicazione
Ogni istanza di DocumentClient è thread-safe ed esegue la gestione efficiente delle connessioni e la memorizzazione nella cache degli indirizzi quando viene usata la modalità diretta. Per consentire una gestione efficiente delle connessioni e prestazioni migliori da parte di DocumentClient, è consigliabile usare una singola istanza di DocumentClient per ogni AppDomain per la durata dell'applicazione.
Aumentare MaxPoolSize per host quando si usa la modalità Gateway
Quando si usa la modalità Gateway, le richieste di Azure Cosmos DB vengono eseguite su HTTPS/REST e sono soggette ai limiti di connessione predefiniti per ogni nome host o indirizzo IP. Può essere necessario impostare MaxPoolSize su un valore più alto (200-1000) in modo che la libreria client possa usare più connessioni simultanee ad Azure Cosmos DB. In Azure Cosmos DB Sync Java SDK v2 il valore predefinito per ConnectionPolicy.getMaxPoolSize è 100. Usare setMaxPoolSize per modificare il valore.
Ottimizzazione delle query parallele per le raccolte partizionate
Azure Cosmos DB Sync Java SDK versione 1.9.0 e versioni successive supportano le query parallele, che consentono di eseguire una query in una raccolta partizionata in parallelo. Per altre informazioni, vedere esempi di codice correlati all'utilizzo con gli SDK. Le query parallele sono state concepite per migliorare la velocità e la latenza delle query sulle loro controparti seriali.
(a) Ottimizzazione di setMaxDegreeOfParallelism: le query parallele funzionano eseguendo query su più partizioni in parallelo. I dati di una singola raccolta partizionata vengono recuperati in modo seriale per quanto riguarda la query. Usare pertanto setMaxDegreeOfParallelism per impostare il numero di partizioni con la massima probabilità di ottenere la query più efficiente, se tutte le altre condizioni del sistema rimangono invariate. Se non si conosce il numero di partizioni, è possibile impostare il valore di setMaxDegreeOfParallelism su un numero elevato. Il sistema sceglie il numero minimo (numero di partizioni, input specificato dall'utente) come livello di parallelismo massimo.
È importante notare che le query parallele producono i vantaggi migliori se i dati sono distribuiti uniformemente tra tutte le partizioni per quanto riguarda la query. Se la raccolta partizionata viene partizionata in modo che tutti o la maggior parte dei dati restituiti da una query venga concentrata in poche partizioni (una partizione nel peggiore dei casi), le prestazioni della query verrebbero colli di bottiglia da tali partizioni.
(b) Tuning setMaxBufferedItemCount: la query parallela è progettata per prelettura dei risultati mentre il batch corrente di risultati viene elaborato dal client. Il prelettura consente di migliorare complessivamente la latenza di una query. setMaxBufferedItemCount limita il numero di risultati prelettura. Impostando setMaxBufferedItemCount sul numero previsto di risultati restituiti (o un numero superiore), questa operazione consente alla query di ricevere il massimo vantaggio dalla prelettura.
La prelettura funziona allo stesso modo indipendentemente da MaxDegreeOfParallelism e esiste un singolo buffer per i dati di tutte le partizioni.
Implementare il backoff in base agli intervalli definiti dal parametro getRetryAfterInMilliseconds
Durante il test delle prestazioni, è necessario aumentare il carico fino a limitare un numero ridotto di richieste. Se limitata, l'applicazione client deve eseguire il backoff sulla limitazione per l'intervallo tra tentativi specificato dal server. Rispettando il backoff si garantiscono tempi di attesa minimi tra i tentativi. Il supporto dei criteri di ripetizione è incluso nella versione 1.8.0 e versioni successive di Azure Cosmos DB Sync Java SDK. Per altre informazioni, vedere getRetryAfterInMilliseconds.
Aumentare il carico di lavoro client
Se si sta eseguendo il test a livelli di velocità effettiva elevati (>50.000 UR/sec), l'applicazione client può diventare un collo di bottiglia a causa della limitazione di uso della CPU o della rete. In questo caso, è possibile continuare a effettuare il push dell'account Azure Cosmos DB aumentando il numero di istanze delle applicazioni client in più server.
Usare l'indirizzamento basato sul nome
Usare l'indirizzamento basato sul nome, in cui il formato dei collegamenti è
dbs/MyDatabaseId/colls/MyCollectionId/docs/MyDocumentId, invece dei selflink (_self), il cui formato èdbs/<database_rid>/colls/<collection_rid>/docs/<document_rid>, per evitare di recuperare l'ID di tutte le risorse usate per costruire il collegamento. Inoltre, poiché queste risorse vengono ricreate (possibilmente con stesso nome), la relativa memorizzazione nella cache potrebbe essere controproducente.Modificare le dimensioni di pagina per le query o i feed di lettura per ottenere prestazioni migliori
Quando si esegue una lettura in blocco di documenti usando la funzionalità dei feed di lettura, ad esempio readDocuments, oppure quando si esegue una query SQL, i risultati vengono restituiti in modo segmentato se il set di risultati è troppo grande. Per impostazione predefinita, i risultati vengono restituiti in blocchi di 100 elementi o 1 MB, a seconda del limite che viene raggiunto prima.
Per ridurre il numero di round trip di rete necessari per recuperare tutti i risultati applicabili, è possibile aumentare le dimensioni di pagina usando l'intestazione di richiesta x-ms-max-item-count fino a 1000. Nei casi in cui è necessario visualizzare solo alcuni risultati, ad esempio se l'interfaccia utente o l'API dell'applicazione restituisce solo 10 risultati alla volta, è anche possibile ridurre le dimensioni di pagina a 10 in modo da ridurre la velocità effettiva usata per le letture e le query.
È anche possibile impostare le dimensioni di pagina usando il metodo setPageSize.
Criterio di indicizzazione
Escludere i percorsi non usati dall'indicizzazione per scritture più veloci
I criteri di indicizzazione di Azure Cosmos DB consentono di specificare i percorsi dei documenti da includere o escludere dall'indicizzazione usando i percorsi di indicizzazione (setIncludedPaths e setExcludedPaths). L'uso dei percorsi di indicizzazione può consentire di ottenere prestazioni migliori e di ridurre le risorse di archiviazione dell'indice per gli scenari in cui i modelli di query sono noti in anticipo, poiché i costi dell'indicizzazione sono correlati direttamente al numero di percorsi univoci indicizzati. Il codice seguente, ad esempio, mostra come escludere dall'indicizzazione un'intera sezione dei documenti (sottoalbero) usando il carattere jolly "*".
Sync Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
Index numberIndex = Index.Range(DataType.Number); numberIndex.set("precision", -1); indexes.add(numberIndex); includedPath.setIndexes(indexes); includedPaths.add(includedPath); indexingPolicy.setIncludedPaths(includedPaths); collectionDefinition.setIndexingPolicy(indexingPolicy);Per altre informazioni, vedere l'articolo relativo ai criteri di indicizzazione di Azure Cosmos DB.
Velocità effettiva
Misurare e ottimizzare per ottenere un utilizzo minore di unità richiesta al secondo
Azure Cosmos DB offre un'ampia gamma di operazioni di database, incluse le query relazionali e gerarchiche con funzioni definite dall'utente, stored procedure e trigger, operative nei documenti in una raccolta di database. Il costo associato a ognuna di queste operazioni dipende da CPU, I/O e memoria necessari per il completamento dell'operazione. Invece di occuparsi della pianificazione e della gestione delle risorse hardware, sarà possibile usare un'unità di richiesta come misura singola per le risorse necessarie per eseguire diverse operazioni di database e rispondere a una richiesta dell'applicazione.
Viene eseguito il provisioning della velocità effettiva in base al numero di unità richiesta impostato per ogni contenitore. Il consumo delle unità di richiesta è valutato in base alla frequenza al secondo. Le applicazioni che superano la frequenza di unità richiesta con provisioning previsto per il contenitore sono limitate fino al ritorno della frequenza sotto il valore riservato per il contenitore. Se l'applicazione necessita di un livello superiore di velocità effettiva, sarà possibile aumentare la velocità effettiva eseguendo il provisioning di unità di richiesta aggiuntive.
La complessità di una query influisce sulla quantità di unità richiesta usate per un'operazione. Il numero di predicati, la natura dei predicati, il numero di funzioni definite dall'utente e le dimensioni del set di dati di origine sono tutti fattori che incidono sul costo delle operazioni di query.
Per misurare il sovraccarico di qualunque operazione (creazione, aggiornamento o eliminazione), esaminare l'intestazione x-ms-request-charge (o la proprietà RequestCharge equivalente in ResourceResponse<T> or FeedResponse<T> per determinare il numero di unità richiesta usate da queste operazioni.
Sync Java SDK V2 (Maven com.microsoft.azure::azure-documentdb)
ResourceResponse<Document> response = client.createDocument(collectionLink, documentDefinition, null, false); response.getRequestCharge();L'addebito richiesta restituito in questa intestazione è una frazione della velocità effettiva con provisioning. Ad esempio, se è stato effettuato il provisioning di 2000 UR/sec e se la query precedente restituisce 1.000 documenti da 1 KB, il costo dell'operazione è 1000. Entro un secondo, il server rispetterà quindi solo due richieste di questo tipo prima di limitare la velocità delle richieste successive. Per altre informazioni, vedere Unità richiesta e il calcolatore di unità richiesta.
Gestire la limitazione della frequenza o una frequenza di richieste troppo elevata
Quando un client prova a superare la velocità effettiva riservata per un account, non si verifica alcun calo delle prestazioni del server e l'uso della capacità della velocità effettiva non supera il livello riservato. Il server termina preventivamente la richiesta con RequestRateTooLarge (codice di stato HTTP 429) e restituisce l'intestazione x-ms-retry-after-ms, che indica la quantità di tempo, in millisecondi, che l'utente deve attendere prima di eseguire di nuovo la richiesta.
HTTP Status 429, Status Line: RequestRateTooLarge x-ms-retry-after-ms :100Tutti gli SDK intercettano implicitamente questa risposta, rispettano l'intestazione retry-after specificata dal server e ripetono la richiesta. A meno che all'account non accedano contemporaneamente più client, il tentativo successivo riuscirà.
Se più client operano cumulativamente in modo costante al di sopra della frequenza delle richieste, il numero di ripetizioni dei tentativi predefinito attualmente impostato su 9 internamente dal client potrebbe non essere sufficiente. In questo caso, il client genererà un'eccezione DocumentClientException con codice di stato 429 per l'applicazione. Il numero di ripetizioni dei tentativi predefinito può essere modificato impostando setRetryOptions nell'istanza di ConnectionPolicy. Per impostazione predefinita, l'eccezione DocumentClientException con codice di stato 429 viene restituita dopo un tempo di attesa cumulativo di 30 secondi, se la richiesta continua a funzionare al di sopra della frequenza delle richieste. Ciò si verifica anche quando il numero di ripetizioni dei tentativi corrente è inferiore al numero massimo di tentativi, indipendentemente dal fatto che si tratti del valore predefinito 9 o di un valore definito dall'utente.
Benché il comportamento automatizzato per la ripetizione dei tentativi consenta di migliorare la resilienza e l'usabilità per la maggior parte delle applicazioni, è possibile che provochi conflitti durante l'esecuzione dei benchmark delle prestazioni, in particolare durante la misurazione della latenza. La latenza osservata dal client presenterà dei picchi se l'esperimento raggiunge il limite del server e fa in modo che l'SDK client ripeta automaticamente i tentativi. Per evitare i picchi di latenza durante gli esperimenti relativi alle prestazioni, misurare l'addebito restituito da ogni operazione e assicurarsi che le richieste operino al di sotto della frequenza delle richieste riservata. Per altre informazioni, vedere Unità richiesta.
Progettare documenti di dimensioni minori per ottenere una velocità effettiva maggiore
L'addebito per le richieste, ovvero il costo di elaborazione delle richieste, per un'operazione specifica è correlato direttamente alle dimensioni del documento. Le operazioni sui documenti di grandi dimensioni sono più costose rispetto alle operazioni per i documenti di piccole dimensioni.
Passaggi successivi
Per altre informazioni sulla progettazione dell'applicazione per scalabilità e prestazioni elevate, vedere l'articolo relativo a partizionamento e ridimensionamento in Azure Cosmos DB.