Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:✅SQL database in Microsoft Fabric
In questa esercitazione si apprenderà come usare il database SQL in Fabric usando il controllo del codice sorgente di integrazione Git di Fabric.
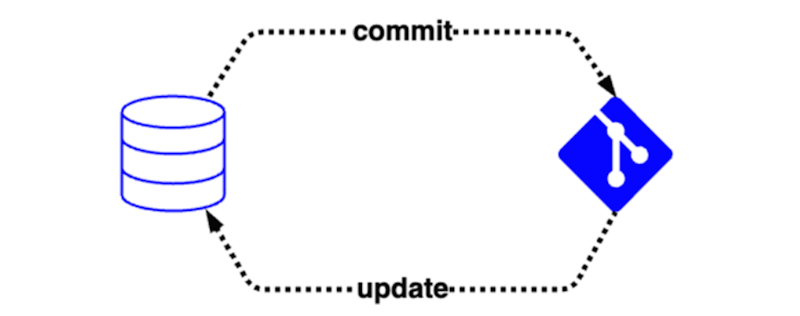
Un database SQL in Microsoft Fabric include l'integrazione del controllo del codice sorgente o "integrazione git", in modo che gli utenti possano tenere traccia delle definizioni degli oggetti di database nel tempo. Questa integrazione consente a un team di:
- Eseguire il commit del database nel controllo del codice sorgente, che converte automaticamente il database attivo nel codice nel repository di controllo del codice sorgente configurato, ad esempio Azure DevOps.
- Aggiornare gli oggetti di database dal contenuto del controllo del codice sorgente, che convalida il codice nel repository del controllo del codice sorgente prima di applicare una modifica differenziale al database.
Se non si ha familiarità con Git, ecco alcune risorse consigliate:
- Che cos'è Git?
- Modulo di training: Introduzione a Git
- Esercitazione: gestione del ciclo di vita in Fabric
Questo articolo presenta una serie di scenari utili che è possibile usare singolarmente o in combinazione per gestire il processo di sviluppo con il database SQL in Fabric:
- Convertire il database SQL dell'infrastruttura in codice nel controllo del codice sorgente
- Aggiornare il database SQL Fabric dal controllo del codice sorgente
- Creare un'area di lavoro del ramo
- Unire le modifiche da un ramo a un altro
- Gestire i dati statici con uno script di post-distribuzione
Gli scenari in questo articolo sono trattati in un episodio di Data Exposed. Guardare il video per una panoramica dell'integrazione del controllo del codice sorgente in Fabric:
Nota
Le impostazioni a livello di database, ad esempio le regole di confronto e il livello di compatibilità, non sono incluse nel controllo del codice sorgente e nell'integrazione delle pipeline di distribuzione. Per le impostazioni del database che è possibile impostare usando T-SQL dopo la creazione del database, è possibile modificare il database con script dopo la distribuzione.
Prerequisiti
- Tutto ciò che serve è una capacità di Fabric. Se non lo fai, avvia una versione di prova di Fabric.
- Assicurarsi di abilitare le impostazioni del tenant di integrazione Git.
- Crea una nuova area di lavoro o utilizza un'area di lavoro Fabric esistente.
- Creare o usare un database SQL esistente in Fabric. Se non ne è già disponibile uno, creare un nuovo database SQL in Fabric.
- Facoltativo: installare Visual Studio Code, l'estensione MSSQL e i progetti SQL per VS Code.
Configurazione
Questa connessione al repository si applica a livello di area di lavoro, in modo che un singolo ramo nel repository sia associato a tale area di lavoro. Il repository può avere più rami, ma solo il codice nel ramo selezionato nelle impostazioni dell'area di lavoro influisce direttamente sull'area di lavoro.
Per la procedura per connettere l'area di lavoro a un repository di controllo del codice sorgente, vedere Introduzione all'integrazione con Git. L'area di lavoro può essere connessa a un Azure DevOps o a un repository remoto GitHub.
Aggiungere il database SQL di Fabric al controllo del codice sorgente
In questo scenario, si eseguono operazioni di commit degli oggetti del database nel sistema di controllo delle versioni. È possibile sviluppare un'applicazione in cui si creano oggetti direttamente in un database di test e tenere traccia del database nel controllo del codice sorgente esattamente come il codice dell'applicazione. Di conseguenza, si ha accesso alla cronologia delle definizioni degli oggetti di database e si possono usare concetti Git come la diramazione e l'unione per personalizzare il processo di sviluppo.
- Connetti al tuo database SQL nell'editor SQL di Fabric SQL Server Management Studio, l'estensione MSSQL per Visual Studio Code o altri strumenti esterni.
- Creare una nuova tabella, una stored procedure o un altro oggetto nel database.
- Selezionare il pulsante Controllo del codice sorgente per aprire il pannello di controllo del codice sorgente.
- Selezionare la casella di controllo accanto al database desiderato. Selezionare Commit. Il servizio Fabric legge le definizioni degli oggetti dal database e le scrive nel repository remoto.
- È ora possibile visualizzare la cronologia degli oggetti di database nella vista origine del repository del codice.
Quando si continua a modificare il database, inclusa la modifica di oggetti esistenti, eseguire il commit di tali modifiche nel controllo del codice sorgente seguendo i passaggi precedenti.
File di progetto SQL
Il file di progetto SQL nel repository del controllo del codice sorgente contiene i metadati relativi al database. L'integrazione del controllo del codice sorgente di Fabric utilizza questo file per aggiungere funzionalità aggiuntive nei pipeline di controllo del codice sorgente e distribuzione. L'integrazione del controllo del codice sorgente di Fabric genera e aggiorna automaticamente il file di progetto. Evitare modifiche manuali al file di progetto perché le modifiche apportate al file di progetto vengono sovrascritte dall'integrazione del controllo del codice sorgente di Fabric nel commit successivo da Fabric. Tuttavia, se si vuole compilare un progetto SQL in locale usando strumenti SQL come SQL Server Management Studio o l'estensione di progetti SQL per Visual Studio Code, è possibile aggiungere un riferimento al master.dacpac file nel file di progetto.
L'integrazione dell'infrastruttura con i progetti SQL aggiunge queste proprietà di metadati al file di progetto:
- Esclude la
.sharedQueriescartella dalla compilazione del progetto di database. Questa esclusione consente di tenere traccia degli script nel controllo del codice sorgente senza influire sulla convalida del modello di database. - Script di pre-distribuzione e post-distribuzione dalla cartella .sharedQueries
- Riferimenti dell'oggetto di sistema come riferimenti di pacchetto al file master.dacpac
La funzionalità dei riferimenti agli oggetti di sistema viene configurata automaticamente senza alcuna azione necessaria. L'editor di query fabric fornisce script di pre-distribuzione e post-distribuzione nella cartella Query condivise .
Aggiornare il database SQL Fabric dal controllo del codice sorgente
In questo scenario si creano oggetti di database come codice nell'estensione progetti SQL in Visual Studio Code, quindi si esegue il commit dei file nel controllo del codice sorgente prima di aggiornare il database SQL di Fabric dall'integrazione del controllo del codice sorgente. Questo scenario è destinato agli sviluppatori che preferiscono lavorare in Visual Studio Code, hanno applicazioni esistenti che usano progetti SQL o hanno requisiti più avanzati per la pipeline CI/CD.
- Assicurarsi di installare la versione più recente di Visual Studio Code e le estensioni per progetti MSSQL e SQL per Visual Studio Code.
- Creare un nuovo database SQL nell'area di lavoro ed eseguirne il commit nel controllo del codice sorgente senza aggiungere oggetti. Questo passaggio aggiunge i metadati vuoti del progetto SQL e dell'elemento del database SQL al repository.
- Clonare il repository di controllo del codice sul computer locale.
- Se si usa Azure DevOps, selezionare il menu di scelta rapida
...per il progetto di controllo del codice sorgente. Selezionare Clone per copiare il repository Azure DevOps nel computer locale. Se non si ha familiarità con Azure DevOps, vedere la guida Code con git per Azure DevOps. - Se si usa GitHub, selezionare il pulsante Code nel repository e copiare l'URL per clonare il repository nel computer locale. Se sei nuovo su GitHub, consulta la guida clonazione di un repository.
- Se si usa Azure DevOps, selezionare il menu di scelta rapida
- Aprire la cartella clonata in Visual Studio Code. Il ramo associato all'area di lavoro potrebbe non essere l'impostazione predefinita. Dopo aver cambiato il ramo, verrà visualizzata una cartella denominata
<yourdatabase>.SQLDatabasein Visual Studio Code. - Creare un
.sqlfile per almeno una tabella che si desidera creare nel database all'interno della struttura di cartelle per il database. Il file deve contenere l'istruzioneCREATE TABLEper la tabella. Ad esempio, creare un file denominatoMyTable.sqlnella cartelladbo/Tablescon il contenuto seguente:CREATE TABLE dbo.MyTable ( Id INT PRIMARY KEY, ExampleColumn NVARCHAR(50) ); - Per assicurarsi che la sintassi sia valida, convalidare il modello di database con il progetto SQL. Dopo aver aggiunto i file, usare la visualizzazione Progetti di database in Visual Studio Code per compilare il progetto.
- Dopo aver completato la build, eseguire il commit dei file nel controllo del codice sorgente usando la visualizzazione del controllo del codice sorgente in Visual Studio Code o la tua interfaccia Git locale preferita.
- Eseguire il push/sincronizzazione del commit nel repository remoto. Verificare che i nuovi file vengano visualizzati in Azure DevOps o GitHub.
- Tornare all'interfaccia Web fabric e aprire il pannello di controllo Del codice sorgente nell'area di lavoro. Potresti già avere un avviso che "hai modifiche in sospeso da Git". Selezionare il pulsante Aggiorna (Aggiorna tutto) per applicare il codice dal progetto SQL al database.
- Il database potrebbe indicare immediatamente che è "Non eseguito il commit" dopo l'aggiornamento. Questo stato si verifica perché la funzionalità integrazione Git esegue un confronto diretto di tutto il contenuto del file generato per una definizione di elemento e alcune differenze involontarie sono possibili. Un esempio è costituito da attributi inline sulle colonne. In questi casi, è necessario effettuare il commit nel sistema di controllo del codice sorgente nell'interfaccia Web di Fabric per sincronizzare la definizione con ciò che è generato come parte dell'operazione di commit.
- Al termine dell'aggiornamento, usare uno strumento di propria scelta per connettersi al database. Gli oggetti aggiunti al progetto SQL sono visibili nel database.
Nota
Quando si apportano modifiche al progetto SQL locale, se si verifica un errore di sintassi o l'uso di funzionalità non supportate in Fabric, l'aggiornamento del database ha esito negativo. È necessario ripristinare manualmente la modifica nel controllo del codice sorgente prima di poter continuare.
L'aggiornamento di un database SQL in Fabric dal controllo del codice sorgente combina una compilazione di progetto SQL e un'operazione di pubblicazione sqlPackage. La compilazione del progetto SQL convalida la sintassi dei file SQL e genera un file .dacpac. L'operazione di pubblicazione di SqlPackage determina le modifiche necessarie per aggiornare il database in modo che corrisponda al .dacpac file. A causa della natura semplificata dell'interfaccia fabric, le opzioni seguenti vengono applicate all'operazione di pubblicazione di SqlPackage:
/p:ScriptDatabaseOptions = false/p:DoNotAlterReplicatedObjects = false/p:IncludeTransactionalScripts = true/p:GenerateSmartDefaults = true
È anche possibile clonare il progetto SQL controllato dal codice sorgente nel computer locale per la modifica in Visual Studio Code, SQL Server Management Studio o altri strumenti di progetto SQL. Compilare il progetto SQL in locale per convalidare le modifiche prima di eseguirne il commit nel controllo del codice sorgente.
Creare un'area di lavoro del ramo
In questo scenario, si configura un nuovo ambiente di sviluppo in Fabric, facendo in modo che Fabric crei un set duplicato di risorse in base alla definizione del controllo del codice sorgente. Il database duplicato include gli oggetti di database inseriti nel controllo del codice sorgente. Questo scenario è destinato agli sviluppatori che continuano il ciclo di vita di sviluppo delle applicazioni in Fabric e usano l'integrazione del controllo del codice sorgente da Fabric.
- Completare lo scenario convertire il database SQL Fabric in codice sotto controllo del codice sorgente.
- È necessario disporre di un ramo in un repository di controllo del codice sorgente con sia un progetto SQL che i metadati dell'oggetto Fabric.
- Nell'area di lavoro Fabric, aprire il pannello di controllo versione. Nella scheda Rami del menu Controllo del codice sorgente, selezionare Diramare in un nuovo spazio di lavoro.
- Specificare i nomi del ramo e dell'area di lavoro da creare. Il ramo viene creato nel repository del controllo del codice sorgente e viene popolato con il contenuto di cui è stato eseguito il commit del ramo associato all'area di lavoro da cui si esegue la diramazione. L'area di lavoro viene creata in Fabric.
- Passare alla nuova area di lavoro appena creata in Fabric. Al termine della creazione del database, il database appena creato contiene gli oggetti specificati nel repository di codice. Se si apre l'editor di query di Fabric e si passa a Esplora oggetti, il database include nuove tabelle (vuote) e altri oggetti.
Unire le modifiche da un ramo a un altro
In questo scenario si usa il repository del controllo del codice sorgente per esaminare le modifiche del database prima che siano disponibili per la distribuzione. Questo scenario è destinato agli sviluppatori che lavorano in un ambiente del team e usano il controllo del codice sorgente per gestire le modifiche del database.
Creare due aree di lavoro con rami associati nello stesso repository, come descritto nello scenario precedente.
- Con il database nel ramo secondario, apportare modifiche agli oggetti di database.
- Ad esempio, modificare una stored procedure esistente o creare una nuova tabella.
- Controllare queste modifiche al controllo del codice sorgente usando il pulsante Commit nel pannello di controllo del codice sorgente in Fabric.
- In Azure DevOps o GitHub creare una richiesta pull dal ramo secondario al ramo primario.
- Nella richiesta pull è possibile visualizzare le modifiche nel codice del database tra l'area di lavoro primaria e l'area di lavoro secondaria.
- Dopo aver completato la richiesta pull, il controllo del codice sorgente viene aggiornato, ma il database in Fabric nell'area di lavoro primaria non viene modificato. Per modificare il database primario, aggiornare l'area di lavoro primaria dal controllo del codice sorgente usando il pulsante Aggiorna nel pannello di controllo del codice sorgente in Fabric.
Gestire i dati statici con uno script di post-distribuzione
In questo scenario si controllano le righe di una tabella di ricerca nel database con il controllo del codice sorgente. La funzionalità che abilita questa funzionalità, la pre-distribuzione e gli script post-distribuzione, si applica anche alle pipeline di distribuzione, in modo da poter usare gli stessi script per gestire i dati statici in entrambi gli scenari.
Da un database SQL in Fabric connesso al controllo del codice sorgente, identificare o creare una tabella per cui si desidera gestire i dati statici. Ad esempio, potrebbe essere disponibile una
dbo.Colorstabella usata dall'applicazione e un set noto di valori che non cambiano di frequente.Creare una nuova query nell'editor di database SQL in Fabric. Nell'editor di query aggiungere un'istruzione
MERGEper gestire il contenuto dellaColorstabella. Per esempio:MERGE dbo.Colors AS target USING (VALUES (1, 'Red'), (2, 'Green'), (3, 'Blue') ) AS source (Id, Name) ON target.Id = source.Id WHEN MATCHED THEN UPDATE SET Name = source.Name WHEN NOT MATCHED BY TARGET THEN INSERT (Id, Name) VALUES (source.Id, source.Name) WHEN NOT MATCHED BY SOURCE THEN DELETE;Rinominare la query
Post-Deployment-StaticData.sqlin e spostarla in Query condivise.Una volta in Query Condivise, selezionare il menu ... per la query e selezionare Imposta come script post-distribuzione.
Questa query viene eseguita automaticamente come parte di qualsiasi aggiornamento dal controllo del codice sorgente o dalla pipeline di distribuzione, in modo da poter gestire i dati statici nella tabella utilizzando il controllo del codice sorgente. È possibile modificare la query nell'editor di query di Fabric ed eseguire il commit delle modifiche al controllo del codice sorgente per gestire le modifiche ai dati statici nel tempo. Inoltre, poiché nel progetto SQL sono inclusi script di pre-distribuzione e post-distribuzione, è anche possibile modificare la query dal computer locale usando Visual Studio Code o altri strumenti di progetto SQL, quindi eseguire il commit di tali modifiche nel controllo del codice sorgente. Altre informazioni sulla pre-distribuzione e sugli script post-distribuzione sono disponibili nella documentazione dei progetti SQL.