Linee guida per i modelli compositi in Power BI Desktop
Questo articolo è destinato agli sviluppatori di modelli compositi per Power BI. Vengono descritti i casi d'uso dei modelli compositi e vengono offerte linee guida di progettazione. In particolare, le linee guida aiutano a determinare se un modello composito è appropriato per la soluzione. In caso affermativo, questo articolo consente anche di progettare modelli e report compositi ottimali.
Nota
Un'introduzione ai modelli compositi non è descritta in questo articolo. Se non si ha familiarità con i modelli compositi, è consigliabile leggere prima l'articolo Usare modelli compositi in Power BI Desktop.
Poiché i modelli compositi sono costituiti da almeno un'origine DirectQuery, è anche importante avere una conoscenza approfondita delle relazioni dei modelli, dei modelli DirectQuery e delle linee guida per la progettazione di modelli DirectQuery.
Casi d'uso di modelli compositi
Per definizione, un modello composito combina più gruppi di origine. Un gruppo di origine può rappresentare dati importati o una connessione a un'origine DirectQuery. Un'origine DirectQuery può essere un database relazionale o un altro modello tabulare, che può essere un modello semantico di Power BI o un modello tabulare di Analysis Services. Quando un modello tabulare si connette a un altro modello tabulare, è noto come concatenamento. Per altre informazioni, vedere Uso di DirectQuery per i modelli semantici di Power BI e Analysis Services.
Nota
Quando un modello si connette a un modello tabulare ma non lo estende con dati aggiuntivi, non è un modello composito. In questo caso, si tratta di un modello DirectQuery che si connette a un modello remoto, quindi comprende solo il gruppo di origine. È possibile creare questo tipo di modello per modificare le proprietà dell'oggetto modello di origine, ad esempio un nome di tabella, un ordinamento di colonna o una stringa di formato.
La connessione a modelli tabulari è particolarmente rilevante quando si estende un modello semantico aziendale (quando si tratta di un modello semantico di Power BI o di Analysis Services). Un modello semantico aziendale è fondamentale per lo sviluppo e il funzionamento di un data warehouse. Fornisce un livello di astrazione sui dati nel data warehouse per presentare definizioni aziendali e terminologia. Viene comunemente usato come collegamento tra i modelli di dati fisici e gli strumenti di creazione di report, ad esempio Power BI. Nella maggior parte delle organizzazioni, è gestito da un team centrale ed è per questo che viene descritto come aziendale. Per altre informazioni, vedere lo scenario di utilizzo di business intelligence aziendale.
Nelle situazioni seguenti è possibile prendere in considerazione lo sviluppo di un modello composito.
- Il modello potrebbe essere un modello DirectQuery e migliorare le prestazioni. In un modello composito è possibile migliorare le prestazioni configurando l'archiviazione appropriata per ogni tabella. È anche possibile aggiungere aggregazioni definite dall'utente. Entrambe queste ottimizzazioni sono descritte più avanti in questo articolo.
- Si vuole combinare un modello DirectQuery con più dati, che devono essere importati nel modello. È possibile caricare dati importati da un'origine dati diversa o da tabelle calcolate.
- Si vogliono combinare due o più origini dati DirectQuery in un unico modello. Queste origini possono essere database relazionali o altri modelli tabulari.
Nota
I modelli compositi non possono includere connessioni a determinati database analitici esterni. Questi database includono SAP Business Warehouse e SAP HANA quando si considera SAP HANA come origine multidimensionale.
Valutare altre opzioni di progettazione del modello
Anche se i modelli compositi di Power BI possono risolvere particolari sfide di progettazione, possono contribuire a rallentare le prestazioni. Inoltre, in alcune situazioni, possono verificarsi risultati di calcolo imprevisti (descritti più avanti in questo articolo). Per questi motivi, valutare altre opzioni di progettazione del modello quando esistono.
Quando possibile, è preferibile sviluppare un modello in modalità di importazione. Questa modalità offre una flessibilità di progettazione elevata e prestazioni ottimizzate.
Tuttavia, le sfide correlate a volumi di dati di grandi dimensioni o alla creazione di report su dati quasi in tempo reale non possono essere sempre risolte dai modelli di importazione. In questi casi è possibile prendere in considerazione un modello DirectQuery, a condizione che i dati siano archiviati in una singola origine dati supportata dalla modalità DirectQuery. Per altre informazioni, vedere Modelli DirectQuery in Power BI Desktop.
Suggerimento
Se l'obiettivo è estendere un modello tabulare esistente con più dati, quando possibile, aggiungere tali dati all'origine dati esistente.
Modalità archiviazione tabella
In un modello composito è possibile impostare la modalità di archiviazione per ogni tabella, ad eccezione delle tabelle calcolate.
- DirectQuery: è consigliabile impostare questa modalità per le tabelle che rappresentano volumi di dati di grandi dimensioni o che devono fornire risultati quasi in tempo reale. I dati non verranno mai importati nelle tabelle. In genere, queste tabelle saranno di tipo fact, ovvero tabelle riepilogate.
- Importazione: è consigliabile impostare questa modalità per le tabelle che non vengono usate per filtrare e raggruppare le tabelle dei fatti in modalità DirectQuery o ibrida. È anche l'unica opzione per le tabelle basate su origini non supportate dalla modalità DirectQuery. Le tabelle calcolate sono sempre di tipo importazione.
- Dual: si consiglia di impostare questa modalità per le tabelle di tipo dimensione, quando esiste la possibilità che queste tabelle vengano sottoposte a query insieme con le tabelle di tipo fact DirectQuery dalla stessa origine.
- Ibrido: è consigliabile impostare questa modalità aggiungendo partizioni di importazione e una partizione DirectQuery a una tabella dei fatti quando si desidera includere le modifiche dei dati più recenti in tempo reale o quando si vuole fornire accesso rapido ai dati usati più di frequente tramite partizioni di importazione, lasciando al contempo la maggior parte dei dati usati più raramente nel data warehouse.
Esistono diversi scenari in cui Power BI esegue una query su un modello composito.
- Esegue query solo su tabelle di importazione o dual: Power BI recupera tutti i dati dalla cache dei modelli. ottimizzando la velocità delle prestazioni. Questo scenario è comune per le tabelle di tipo dimensione sottoposte a query da filtri o oggetti visivi di tipo filtro dei dati.
- Esegue query su tabelle dual o tabelle DirectQuery dalla stessa origine: Power BI recupera tutti i dati inviando una o più query native all'origine DirectQuery. Offre buone prestazioni, soprattutto quando esistono indici appropriati nelle tabelle di origine. Questo scenario è comune per le query correlate alle tabelle di tipo dimensione doppie e alle tabelle di tipo fact DirectQuery. Queste query vengono eseguite all'interno del gruppo di origine, quindi tutte le relazioni uno-a-uno o uno-a-molti vengono valutate come relazioni regolari.
- Esegue query su tabelle dual o tabelle ibride dalla stessa origine: questo scenario è una combinazione dei due scenari precedenti. Power BI recupera i dati dalla cache del modello quando è disponibile nelle partizioni di importazione; in caso contrario, invia una o più query native all'origine DirectQuery. Offre le prestazioni più veloci possibili perché viene eseguita una query solo su una sezione dei dati nel data warehouse, soprattutto quando sono presenti indici appropriati nelle tabelle di origine. Per quanto riguarda le tabelle con tipo di dimensione doppia e le tabelle di tipo fatto DirectQuery, queste query sono all'interno del gruppo di origine e quindi tutte le relazioni uno-a-uno o uno-a-molti vengono valutate come relazioni regolari.
- Tutte le altre query: queste query comportano relazioni tra gruppi di origine. Questo perché una tabella di importazione è correlata a una tabella DirectQuery o una tabella doppia è correlata a una tabella DirectQuery da un'origine diversa, nel qual caso si comporta come una tabella di importazione. Tutte le relazioni vengono valutate come relazioni limitate. Significa anche che i raggruppamenti applicati alle tabelle non DirectQuery devono essere inviati all'origine DirectQuery come sottoquery materializzate (tabelle virtuali). In questo caso la query nativa può risultare inefficiente, soprattutto per set di raggruppamenti di grandi dimensioni.
Riepilogando, è consigliabile:
- Considerare attentamente che un modello composito è la soluzione giusta, mentre consente l'integrazione a livello di modello di origini dati diverse, presenta anche complessità di progettazione con possibili conseguenze (descritte più avanti in questo articolo).
- Impostare la modalità di archiviazione su DirectQuery quando una tabella è una tabella di tipo fact che archivia volumi di dati di grandi dimensioni o deve produrre risultati quasi in tempo reale.
- È consigliabile usare la modalità ibrida definendo criteri di aggiornamento incrementale e dati in tempo reale oppure partizionando la tabella dei fatti usando TOM, TMSL o uno strumento di terze parti. Per altre informazioni, vedere Aggiornamento incrementale e dati in tempo reale per i modelli semantici e lo scenario di utilizzo Gestione dei modelli di dati avanzata.
- Impostare la modalità di archiviazione su Dual quando una tabella è una tabella di tipo dimensione e verrà eseguita una query insieme a DirectQuery o a tabelle di tipo fatto ibrido che si trovano nello stesso gruppo di origine.
- Impostare le frequenze di aggiornamento appropriate per mantenere la cache dei modelli per le tabelle dual e ibride (e le tabelle calcolate dipendenti) sincronizzate con i database di origine.
- Cercare di garantire l'integrità dei dati tra gruppi di origine (inclusa la cache del modello), perché le relazioni limitate elimineranno le righe nei risultati della query quando i valori delle colonne correlate non corrispondono.
- Quando possibile, ottimizzare le origini dati DirectQuery con indici appropriati per join, filtri e raggruppamenti efficienti.
Aggregazioni definite dall'utente
È possibile aggiungere aggregazioni definite dall'utente alle tabelle DirectQuery. Il loro scopo è quello di migliorare le prestazioni per le query a granularità più elevata.
Quando le aggregazioni vengono memorizzate nella cache del modello, si comportano come tabelle di importazione, sebbene non possano essere usate come una tabella del modello. L'aggiunta di aggregazioni di importazione a un modello DirectQuery comporterà un modello composito.
Nota
Le tabelle ibride non supportano le aggregazioni perché alcune delle partizioni operano in modalità di importazione. Non è possibile aggiungere aggregazioni a livello di una singola partizione DirectQuery.
È consigliabile che un'aggregazione segua una regola di base: il conteggio delle righe deve essere almeno un fattore inferiore a 10 rispetto alla tabella sottostante. Se, ad esempio, la tabella sottostante archivia 1 miliardo di righe, la tabella di aggregazioni non deve superare i 100 milioni di righe. Questa regola garantisce un miglioramento delle prestazioni adeguato rispetto al costo della creazione e della gestione dell'aggregazione.
Relazioni tra gruppi tra origini
Quando una relazione di modello si estende su gruppi di origine, è nota come relazione tra gruppi di origine. Anche le relazioni tra gruppi di origine sono relazioni limitate perché non esiste "un" lato garantito. Per altre informazioni, vedere Valutazione della relazione.
Nota
In alcune situazioni, è possibile evitare di creare una relazione tra gruppi di origine. Vedere l'argomento Usare i filtri dei dati di sincronizzazione più avanti in questo articolo.
Quando si definiscono le relazioni tra gruppi di origine, prendere in considerazione le raccomandazioni seguenti.
- Usare colonne di relazione di cardinalità bassa: per ottenere prestazioni ottimali, è consigliabile che le colonne della relazione siano di cardinalità bassa, ovvero devono archiviare meno di 50.000 valori univoci. Questo consiglio è particolarmente vero quando si combinano modelli tabulari e per colonne non di testo.
- Evitare di usare colonne di relazione di testo di grandi dimensioni: se è necessario usare colonne di testo in una relazione, calcolare la lunghezza del testo prevista per il filtro moltiplicando la cardinalità per la lunghezza media della colonna di testo. La lunghezza del testo possibile non deve superare 1.000.000 di caratteri.
- Aumentare la granularità della relazione: se possibile, creare relazioni a un livello di granularità superiore. Ad esempio, invece di correlare una tabella "data" nella chiave "data", usare invece la chiave "mese". Questo approccio di progettazione richiede che la tabella correlata includa una colonna chiave "mese" e che i report non siano in grado di visualizzare i fatti giornalieri.
- Cercare di ottenere una progettazione semplice delle relazioni: creare una relazione tra gruppi di origine solo quando è necessaria e provare a limitare il numero di tabelle nel percorso della relazione. Questo approccio di progettazione consente di migliorare le prestazioni ed evitare percorsi di relazione ambigui.
Avviso
Poiché Power BI Desktop non convalida accuratamente le relazioni tra gruppi di origine, è possibile creare relazioni ambigue.
Scenario di relazione tra gruppi di origine 1
Si consideri uno scenario di progettazione di relazioni complesse e come potrebbe produrre risultati diversi, ma validi.
In questo scenario, la tabella Region nel gruppo di origine A ha una relazione con la tabella Data e la tabella Vendite nel gruppo di origine B. La relazione tra la tabella Area e la tabella Data è attiva, mentre la relazione tra la tabella Area e la tabella Vendite è inattiva. Esiste anche una relazione attiva tra la tabella Area e la tabella Vendite, entrambe incluse nel gruppo di origine B. La tabella Vendite include una misura denominata TotalSales e la tabella Area include due misure denominate RegionalSales e RegionalSalesDirect.
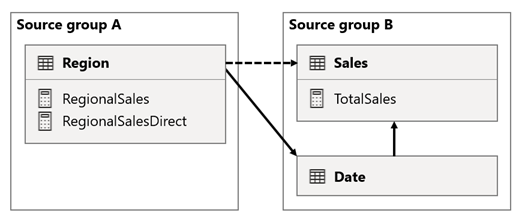
Ecco le definizioni delle misure.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Si noti che la misura RegionalSales fa riferimento alla misura TotalSales, a differenza della misura RegionalSalesDirect. La misura RegionalSalesDirect usa invece l'espressione SUM(Sales[Sales]), ovvero l'espressione della misura TotalSales.
La differenza nel risultato è sottile. Quando Power BI valuta la misura RegionalSales, applica il filtro dalla tabella Area sia alla tabella Vendite che alla tabella Data. Pertanto, il filtro viene propagato anche dalla tabella Data alla tabella Vendite. Al contrario, quando Power BI valuta la misura RegionalSalesDirect, propaga solo il filtro dalla tabella Area alla tabella Vendite. I risultati restituiti dalla misura RegionalSales e la misura RegionalSalesDirect potrebbero differire, anche se le espressioni sono semanticamente equivalenti.
Importante
Ogni volta che si usa la funzione CALCULATE con un'espressione che è una misura in un gruppo di origine remoto, testare accuratamente i risultati del calcolo.
Scenario di relazione tra gruppi di origine 2
Si consideri uno scenario in cui una relazione tra gruppi di origine ha colonne di relazione di cardinalità elevata.
In questo scenario, la tabella Data è correlata alla tabella Vendite nelle colonne DateKey. Il tipo di dati delle colonne DateKey è integer, archiviando numeri interi che usano il formato aaaammgg. Le tabelle appartengono a gruppi di origine diversi. Inoltre, si tratta di una relazione di cardinalità elevata perché la prima data nella tabella Data è il 1° gennaio 1900 e la data più recente è il 31 dicembre 2100, quindi nella tabella è presente un totale di 73.414 righe (una riga per ogni data nell'intervallo di tempo 1900-2100).
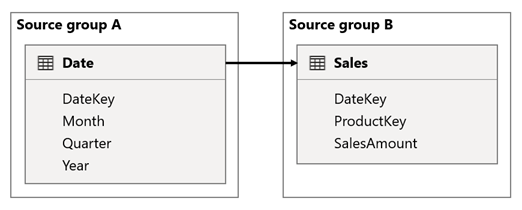
Ci sono due casi di dubbio.
In primo luogo, quando si usano le colonne della tabella Data come filtri, la propagazione dei filtri filtra la colonna DateKey della tabella Vendite per valutare le misure. Quando si filtra in base a un singolo anno, ad esempio 2022, la query DAX includerà un'espressione di filtro come Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Le dimensioni del testo della query possono diventare estremamente grandi quando il numero di valori nell'espressione di filtro è elevato o quando i valori del filtro sono stringhe lunghe. È costoso che Power BI generi la query lunga e che l'origine dati esegua la query.
In secondo luogo, quando si usano colonne della tabella Data, ad esempio Anno, Trimestre o Mese, come colonne di raggruppamento, vengono restituiti filtri che includono tutte le combinazioni univoche di anno, trimestre o mese e dei valori della colonna DateKey. Le dimensioni della stringa della query, che contiene filtri per le colonne di raggruppamento e la colonna della relazione, possono diventare estremamente grandi. Ciò vale soprattutto quando il numero di colonne di raggruppamento e/o la cardinalità della colonna join (la colonna DateKey ) è grande.
Per risolvere eventuali problemi di prestazioni, è possibile:
- Aggiungere la tabella Data all'origine dati, generando un singolo modello di gruppo di origine (ovvero non è più un modello composito).
- Aumentare la granularità della relazione. Ad esempio, è possibile aggiungere una colonna MonthKey a entrambe le tabelle e creare la relazione su tali colonne. Tuttavia, aumentando la granularità della relazione, si perde la possibilità di creare report sull'attività di vendita giornaliera, a meno che non si usi la colonna DateKey dalla tabella Vendite.
Scenario di relazione tra gruppi di origine 3
Si consideri uno scenario in cui non sono presenti valori corrispondenti tra tabelle in una relazione tra gruppi di origine.
In questo scenario, la tabella Data nel gruppo di origine B ha una relazione con la tabella Vendite in tale gruppo di origine e anche con la tabella Destinazione nel gruppo di origine A. Tutte le relazioni sono uno-a-molti dalla tabella Data relativa alle colonne Anno. La tabella Vendite include una colonna SalesAmount che archivia gli importi delle vendite, mentre la tabella Target include una colonna TargetAmount che archivia gli importi di destinazione.

La tabella Data archivia gli anni 2021 e 2022. La tabella Vendite archivia gli importi delle vendite per gli anni 2021 (100) e 2022 (200), mentre la tabella Destinazione archivia gli importi di destinazione per il 2021 (100), 2022 (200) e 2023 (300), un anno futuro.
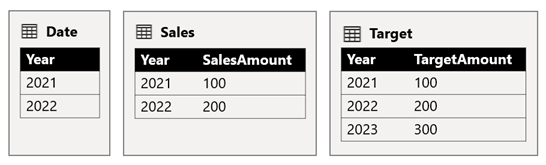
Quando un oggetto visivo tabella di Power BI esegue una query sul modello composito raggruppando la colonna Anno dalla tabella Data e sommando le colonne SalesAmount e TargetAmount, non mostrerà un importo di destinazione per il 2023. Ciò è dovuto al fatto che la relazione tra gruppi di origine è una relazione limitata e quindi usa la semantica INNER JOIN, eliminando le righe in cui non esiste alcun valore corrispondente su entrambi i lati. Produrrà tuttavia un totale di destinazione corretto (600), perché un filtro di tabella Data non si applica alla valutazione.
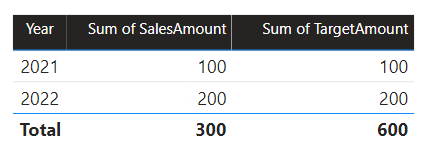
Se la relazione tra la tabella Data e la tabella Destinazione è una relazione tra gruppi di origine (presupponendo che la tabella Destinazione appartenga al gruppo di origine B), l'oggetto visivo includerà un anno (Vuoto) per visualizzare l'importo di destinazione 2023 (e qualsiasi altro anno non corrispondente).
Importante
Per evitare errori di report, assicurarsi che siano presenti valori corrispondenti nelle colonne delle relazioni quando le tabelle delle dimensioni e dei fatti si trovano in gruppi di origine diversi.
Per altre informazioni sulle relazioni limitate, vedere Valutazione delle relazioni.
Calcoli
È consigliabile considerare limitazioni specifiche quando si aggiungono colonne calcolate e gruppi di calcolo a un modello composito.
Colonne calcolate
Le colonne calcolate aggiunte a una tabella DirectQuery che generano i dati da un database relazionale, ad esempio Microsoft SQL Server, sono limitate alle espressioni che operano su una singola riga alla volta. Queste espressioni non possono usare funzioni iteratore DAX, ad esempio SUMX, o funzioni di modifica del contesto di filtro, ad esempio CALCULATE.
Nota
Non è possibile aggiungere colonne calcolate o tabelle calcolate che dipendono da modelli tabulari concatenati.
Un'espressione di colonna calcolata in una tabella DirectQuery remota è limitata solo alla valutazione all'interno di righe. Tuttavia, è possibile creare un'espressione di questo tipo, ma genererà un errore quando viene usato in un oggetto visivo. Ad esempio, se si aggiunge una colonna calcolata a una tabella DirectQuery remota denominata DimProduct usando l'espressione [Product Sales] / SUM (DimProduct[ProductSales]), sarà possibile salvare correttamente l'espressione nel modello. Tuttavia, genererà un errore quando viene usato in un oggetto visivo perché viola la restrizione di valutazione all'interno della riga.
Al contrario, le colonne calcolate aggiunte a una tabella DirectQuery remota che è un modello tabulare, ovvero un modello semantico di Power BI o un modello di Analysis Services, sono più flessibili. In questo caso, tutte le funzioni DAX sono consentite perché l'espressione verrà valutata all'interno del modello tabulare di origine.
Molte espressioni richiedono Power BI per materializzare la colonna calcolata prima di usarla come gruppo o filtro o aggregarla. Quando una colonna calcolata viene materializzata su una tabella di grandi dimensioni, può essere costosa in termini di CPU e memoria, a seconda della cardinalità delle colonne da cui dipende la colonna calcolata. In questo caso, è consigliabile aggiungere tali colonne calcolate al modello di origine.
Nota
Quando si aggiungono colonne calcolate a un modello composito, assicurarsi di testare tutti i calcoli del modello. I calcoli upstream potrebbero non funzionare correttamente perché non hanno considerato la loro influenza sul contesto di filtro.
Gruppi di calcolo
Se esistono gruppi di calcolo in un gruppo di origine che si connette a un modello semantico di Power BI o a un modello di Analysis Services, Power BI potrebbe restituire risultati imprevisti. Per altre informazioni, vedere Gruppi di calcolo, query e valutazione delle misure.
Progettazione del modello
È consigliabile ottimizzare sempre un modello di Power BI adottando una progettazione dello schema a stella.
Suggerimento
Per altre informazioni, vedere Informazioni su uno schema star e sull'importanza di questo schema per Power BI.
Assicurarsi di creare tabelle delle dimensioni separate dalle tabelle dei fatti in modo che Power BI possa interpretare correttamente i join e produrre piani di query efficienti. Anche se queste linee guida sono vere per qualsiasi modello di Power BI, lo sono particolarmente per i modelli che diventeranno un gruppo di origine di un modello composito. Questo consente un'integrazione più semplice e più efficiente di altre tabelle nei modelli downstream.
Quando possibile, evitare di disporre di tabelle delle dimensioni in un gruppo di origine correlato a una tabella dei fatti in un gruppo di origine diverso. Ciò è dovuto al fatto che è preferibile avere relazioni tra gruppi all'interno del gruppo di origine rispetto alle relazioni tra gruppi di origine, soprattutto per le colonne di relazione di cardinalità elevata. Come descritto in precedenza, le relazioni tra gruppi di origine si basano sulla presenza di valori corrispondenti nelle colonne delle relazioni, altrimenti potrebbero essere visualizzati risultati imprevisti negli oggetti visivi del report.
Sicurezza a livello di riga
Se il modello include aggregazioni definite dall'utente, colonne calcolate nelle tabelle di importazione o tabelle calcolate, assicurarsi che qualsiasi sicurezza a livello di riga sia configurata correttamente e testata.
Se il modello composito si connette ad altri modelli tabulari, le regole della sicurezza a livello di riga vengono applicate solo al gruppo di origine (modello locale) in cui sono definite. Non verranno applicate ad altri gruppi di origine (modelli remoti). Inoltre, non è possibile definire regole di sicurezza a livello di riga in una tabella da un altro gruppo di origine né definire regole di sicurezza a livello di riga in una tabella locale con una relazione con un altro gruppo di origine.
Progettazione del report
In alcune situazioni, è possibile migliorare le prestazioni di un modello composito progettando un layout di report ottimizzato.
Oggetti visivi del gruppo di origine singolo
Quando possibile, creare oggetti visivi che usano campi da un singolo gruppo di origine. Ciò è dovuto al fatto che le query generate dagli oggetti visivi offrono prestazioni migliori quando il risultato viene recuperato da un singolo gruppo di origine. Valutare la possibilità di creare due oggetti visivi posizionati affiancati per recuperare i dati da due gruppi di origine diversi.
Usare i filtri dei dati di sincronizzazione
In alcune situazioni, è possibile configurare filtri dei dati di sincronizzazione per evitare di creare una relazione tra gruppi di origine nel modello. Consente di combinare visivamente i gruppi di origine che possono offrire prestazioni migliori.
Si consideri uno scenario in cui il modello ha due gruppi di origine. Ogni gruppo di origine ha una tabella delle dimensioni del prodotto usata per filtrare le vendite di rivenditori e Internet.
In questo scenario, il gruppo di origine A contiene la tabella Product correlata alla tabella ResellerSales. Il gruppo di origine B contiene la tabella Product2 correlata alla tabella InternetSales. Non sono presenti relazioni tra gruppi di origine.
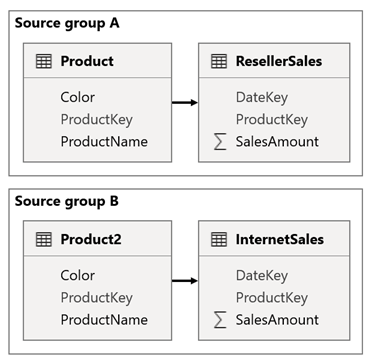
Nel report si aggiunge un filtro dei dati che filtra la pagina usando la colonna Color della tabella Product. Per impostazione predefinita, il filtro dei dati filtra la tabella ResellerSales, ma non la tabella InternetSales. Si aggiunge quindi un filtro dei dati nascosto usando la colonna Color della tabella Product2. Impostando un nome di gruppo identico (disponibile nelle Opzioni avanzate dei filtri dei dati di sincronizzazione), i filtri applicati al filtro dei dati visibile vengono propagati automaticamente al filtro dei dati nascosto.
Nota
Anche se l'uso di filtri dei dati di sincronizzazione può evitare la necessità di creare una relazione tra gruppi di origine, aumenta la complessità della progettazione del modello. Assicurarsi di informare altri utenti sul motivo per cui è stato progettato il modello con tabelle di dimensioni duplicate. Evitare confusione nascondendo le tabelle delle dimensioni che non si desidera che altri utenti usino. È anche possibile aggiungere testo di descrizione alle tabelle nascoste per documentare lo scopo.
Per altre informazioni, vedere Sincronizzare filtri dei dati separati.
Altro materiale sussidiario
Ecco altro materiale sussidiario che consente di progettare e gestire modelli compositi.
- Prestazioni e scalabilità: se i report sono stati precedentemente connessi a un modello semantico di Power BI o a un modello di Analysis Services, il servizio Power BI potrebbe riutilizzare le cache visive tra i report. Dopo aver convertito la connessione dinamica per creare un modello DirectQuery locale, i report non trarranno più vantaggio da tali cache. Di conseguenza, è possibile che si verifichino errori di aggiornamento o prestazioni più lente. Inoltre, il carico di lavoro per il servizio Power BI aumenterà, il che potrebbe richiedere l'aumento della capacità o la distribuzione del carico di lavoro tra altre capacità. Per altre informazioni sull'aggiornamento e la memorizzazione nella cache dei dati, vedere Aggiornamento dei dati in Power BI.
- Ridenominazione: non è consigliabile rinominare i modelli semantici usati dai modelli compositi o rinominare le aree di lavoro. Ciò è dovuto al fatto che i modelli compositi si connettono ai modelli semantici di Power BI usando i nomi dell'area di lavoro e dei modelli semantici (e non i relativi identificatori univoci interni). La ridenominazione di un modello semantico o di un'area di lavoro potrebbe interrompere le connessioni usate dal modello composito.
- Governance: non è consigliabile che la singola versione del modello di verità sia un modello composito. Ciò è dovuto al fatto che dipende da altre origini dati o modelli, che, se aggiornati, potrebbero causare un'interruzione del modello composito. È invece consigliabile pubblicare un modello semantico aziendale come singola versione di verità. Prendere in considerazione questo modello come base affidabile. Altri modelli di dati possono quindi creare modelli compositi che estendono il modello di base per creare modelli specializzati.
- Derivazione dei dati: usare le funzionalità di derivazione dei dati e analisi dell'impatto del modello semantico prima di pubblicare modifiche al modello composito. Queste funzionalità sono disponibili nel servizio Power BI e consentono di comprendere in che modo i modelli semantici sono correlati e usati. È importante comprendere che non è possibile eseguire l'analisi dell'impatto sui modelli semantici esterni visualizzati nella visualizzazione di derivazione, ma che si trovano in un'altra area di lavoro. Per eseguire l'analisi di impatto su un modello semantico esterno, è necessario passare all'area di lavoro di origine.
- Aggiornamenti dello schema: è necessario aggiornare il modello composito in Power BI Desktop quando vengono apportate modifiche dello schema alle origini dati upstream. Sarà quindi necessario ripubblicare il modello nel servizio Power BI. Assicurarsi di testare accuratamente i calcoli e i report dipendenti.
Contenuto correlato
Per altre informazioni correlate a questo articolo, vedere le risorse seguenti.
- Usare i modelli compositi in Power BI Desktop
- Relazioni nei modelli in Power BI Desktop
- Modelli DirectQuery in Power BI Desktop
- Usare DirectQuery in Power BI Desktop
- Uso di DirectQuery per modelli semantici di Power BI e Analysis Services
- Modalità di archiviazione in Power BI Desktop
- Aggregazioni definite dall'utente
- Domande? Contattare la community di Power BI
- inviare suggerimenti, Contribuire con idee per migliorare Power BI