Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
È possibile creare carichi di lavoro di flussi di dati nella sottoscrizione di Power BI Premium. In Power BI il concetto di carichi di lavoro si riferisce ai contenuti Premium. I carichi di lavoro includono set di dati, report impaginati, flussi di dati e intelligenza artificiale. Il carico di lavoro Flussi di dati consente di usare la preparazione dei dati self-service con flussi di dati per inserire, trasformare, integrare e arricchire i dati. I flussi di dati di Power BI Premium vengono gestiti nel portale di amministrazione.
Le sezioni seguenti descrivono come abilitare i flussi di dati nell'organizzazione e come perfezionare le impostazioni nella capacità Premium e forniscono le linee guida per il comune utilizzo.
Abilitazione dei flussi di dati in Power BI Premium
Il primo requisito per usare i flussi di dati nella sottoscrizione di Power BI Premium consiste nell'abilitare la creazione e l'uso dei flussi di dati per l'organizzazione. Nel portale di amministrazione selezionare Impostazioni tenant e spostare il dispositivo di scorrimento sotto Impostazioni del flusso di dati su Abilitato, come illustrato nell'immagine seguente.
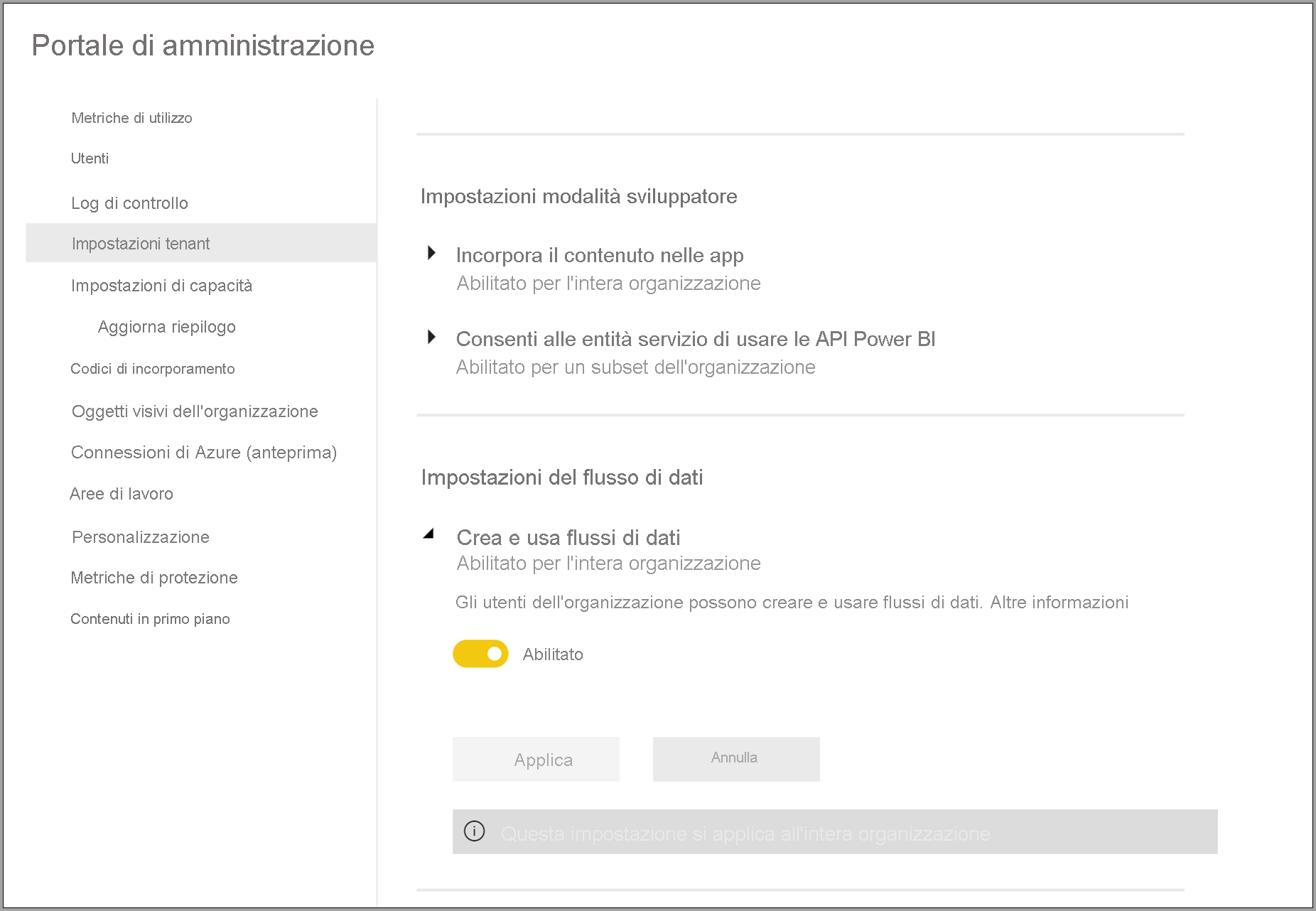
Dopo aver abilitato il carico di lavoro dei flussi di dati, viene configurato con le impostazioni predefinite. Potrebbe essere necessario modificare queste impostazioni in base alle esigenze. Successivamente, viene descritto il punto in cui queste impostazioni sono attive, descritte ognuna e consentono di comprendere quando è possibile modificare i valori per ottimizzare le prestazioni del flusso di dati.
Ridefinire le impostazioni del flusso di dati in Premium
Una volta abilitati i flussi di lavoro, è possibile usare il portale di amministrazione per modificare o ridefinire come i flussi di dati vengono creati e come usano le risorse nella sottoscrizione di Power BI Premium. Power BI Premium non richiede la modifica delle impostazioni di memoria. La memoria in Power BI Premium gestisce automaticamente il sistema sottostante. I passaggi seguenti illustrano come modificare le impostazioni del flusso di dati.
Nel portale di amministrazione selezionare Impostazioni tenant per elencare tutte le capacità create. Selezionare una capacità per gestirne le impostazioni.
La capacità Power BI Premium riflette le risorse disponibili per i flussi di dati. È possibile modificare le dimensioni della capacità selezionando il pulsante Modifica dimensioni, come illustrato nell'immagine seguente.
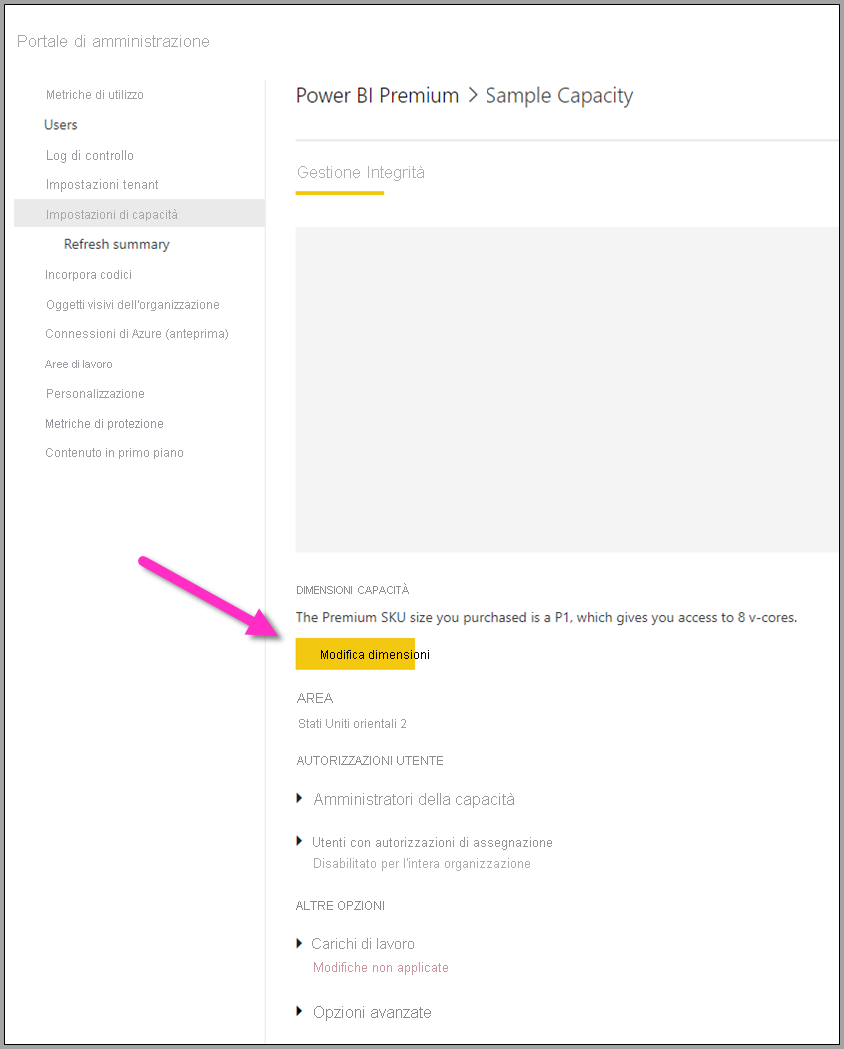
SKU della capacità Premium - aumentare le prestazioni dell'hardware
I carichi di lavoro di Power BI Premium usano v-core per gestire query veloci nei vari tipi di carico di lavoro. Capacità e SKU include un grafico che illustra le specifiche correnti in ognuna delle offerte di carico di lavoro disponibili. Le capacità A3 e superiori possono sfruttare il motore di calcolo, quindi per usare il motore di calcolo avanzato, iniziare da qui.
Motore di calcolo avanzato - opportunità di migliorare le prestazioni
Il motore di calcolo avanzato è un motore in grado di accelerare le query. Power BI usa un motore di calcolo per elaborare le query e le operazioni di aggiornamento. Il motore di calcolo avanzato è un miglioramento rispetto al motore standard e funziona caricando i dati in una cache SQL e usa SQL per accelerare la trasformazione della tabella, le operazioni di aggiornamento e abilita la connettività DirectQuery. Se impostato su Sì o su Ottimizzato per le entità calcolate, se la logica di business lo consente, Power BI usa SQL per migliorare le prestazioni. Il motore attivo fornisce anche la connettività DirectQuery. Assicurarsi che l'utilizzo del flusso di dati usi correttamente il motore di calcolo avanzato. Gli utenti possono configurare il motore di calcolo avanzato in modo che sia attivato, ottimizzato o disattivato per ogni flusso di dati.
Nota
Il motore di calcolo avanzato non è ancora disponibile in tutte le aree.
Linee guida per scenari comuni
Questa sezione fornisce linee guida per gli scenari più comuni quando si usano i carichi di lavoro Flussi di dati con Power BI Premium.
Tempi di aggiornamento lenti
La lentezza dei tempi di aggiornamento in genere è un problema di parallelismo. È consigliabile esaminare le opzioni seguenti, nell'ordine indicato:
Un concetto chiave per i tempi di aggiornamento lenti è legato alla natura della preparazione dei dati. Ogni volta che è possibile ottimizzare i tempi di aggiornamento lenti sfruttando l'origine dati ed eseguendo effettivamente la preparazione e la logica di query in anticipo, è opportuno farlo. In particolare, quando si usa come origine un database relazionale come SQL, verificare se la query iniziale può essere eseguita sull'origine e usare tale query di origine per il flusso di dati di estrazione iniziale per l'origine dati. Se non è possibile usare una query nativa nel sistema di origine, eseguire operazioni che il motore dei flussi di dati può piegare all'origine dati.
Valutare la distribuzione dei tempi di aggiornamento sulla stessa capacità. Le operazioni di aggiornamento sono un processo che richiede un'intensa attività di calcolo. In base all'analogia del ristorante, distribuire i tempi di aggiornamento equivale a limitare il numero degli ospiti nel ristorante. Proprio come i ristoranti pianificano gli ospiti e pianificano la capacità, è anche consigliabile prendere in considerazione le operazioni di aggiornamento durante i periodi in cui l'utilizzo non è al massimo massimo. Ciò può contribuire ad attenuare la pressione sulla capacità.
Se i passaggi illustrati in questa sezione non offrono il grado di parallelismo desiderato, valutare la possibilità di aggiornare la capacità a uno SKU superiore. Seguire quindi di nuovo i passaggi precedenti in questa sequenza.
Uso del motore di calcolo per migliorare le prestazioni
Seguire questa procedura per consentire ai carichi di lavoro di attivare il motore di calcolo e migliorare sempre le prestazioni:
Per le entità calcolate e collegate nella stessa area di lavoro:
Per l'inserimento fare in modo di immettere i dati nella risorsa di archiviazione il più rapidamente possibile, usando i filtri solo se riducono le dimensioni complessive del set di dati. È consigliabile tenere la logica di trasformazione separata da questo passaggio e consentire al motore di concentrarsi sulla raccolta iniziale degli ingredienti. Separare quindi la logica di trasformazione e di business in un flusso di dati distinto nella stessa area di lavoro, usando le entità collegate o calcolate. Questa operazione consente al motore di attivare e accelerare i calcoli. La logica deve essere preparata separatamente prima che possa sfruttare il motore di calcolo.
Assicurarsi di eseguire le operazioni di riduzione, ad esempio merge, join, conversione e altre.
Creare i flussi di dati rispettando le linee guida e le limitazioni pubblicate.
È anche possibile usare DirectQuery.
Il motore di calcolo è attivo ma le prestazioni sono lente
Seguire questa procedura quando si analizzano gli scenari in cui il motore di calcolo è attivo, ma si osserva un rallentamento delle prestazioni:
Limitare le entità calcolate e collegate esistenti in più aree di lavoro.
Quando si esegue l'aggiornamento iniziale con il motore di calcolo attivato, i dati vengono scritti nel lake e nella cache. Questa doppia scrittura indica che gli aggiornamenti sono più lenti.
Se si ha un flusso di dati collegato a più flussi di dati, assicurarsi di pianificare gli aggiornamenti dei flussi di dati di origine in modo che non vengano aggiornati tutti contemporaneamente.
Contenuto correlato
Gli articoli seguenti contengono altre informazioni sui flussi di dati e su Power BI:
- Introduzione ai flussi di dati e alla preparazione dei dati self-service
- Creazione di un flusso di dati
- Configurazione e uso di un flusso di dati
- Configurazione dello spazio di archiviazione del flusso di dati per usare Azure Data Lake Gen 2
- Pianificazione dell'implementazione di Power BI - Integrazione con altri servizi
- Considerazioni e limitazioni per i flussi di dati