Usare la visualizzazione Hive di Apache Ambari con Apache Hadoop in HDInsight
Informazioni su come eseguire query Hive usando la vista Hive di Apache Ambari. Le viste di Hive consentono di creare, ottimizzare ed eseguire query Hive dal Web browser.
Prerequisiti
Un cluster Hadoop in HDInsight. Vedere Guida introduttiva: Introduzione ad Apache Hadoop e Apache Hive in Azure HDInsight usando il modello di Resource Manager.
Eseguire una query Hive
Selezionare il proprio cluster nel portale di Azure. Per istruzioni, vedere Elencare e visualizzare i cluster. Il cluster viene aperto in una nuova visualizzazione del portale.
In Dashboard cluster selezionare Visualizzazioni Ambari. Quando viene richiesta l'autenticazione, usare il nome e la password dell'account di accesso al cluster (per impostazione predefinita,
admin) specificati durante la creazione del cluster. È anche possibile passare ahttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsnel browser in cuiCLUSTERNAMEè il nome del cluster.Nell'elenco di viste selezionare vista Hive.
La pagina Vista Hive è simile all'immagine seguente:
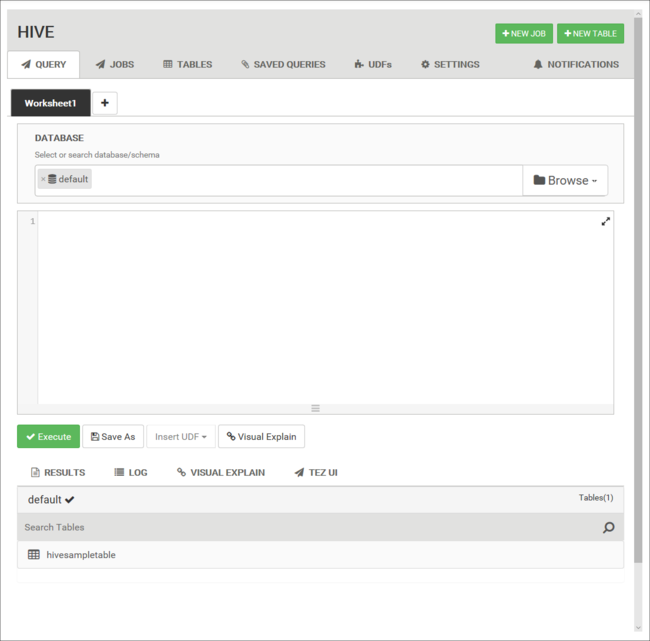
Dalla scheda Query incollare le istruzioni HiveQL seguenti nel foglio di lavoro:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Queste istruzioni eseguono le azioni seguenti:
Istruzione Descrizione DROP TABLE elimina la tabella e il file di dati, qualora la tabella esista già. CREATE EXTERNAL TABLE crea una nuova tabella "esterna" in Hive. Le tabelle esterne archiviano solo la definizione della tabella in Hive. I dati rimangono nel percorso originale. FORMATO RIGA indica il modo in cui sono formattati i dati. In questo caso, i campi in ogni log sono separati da uno spazio. STORED AS TEXTFILE LOCATION indica dove sono archiviati i dati e che sono archiviati come testo. SELECT seleziona un conteggio di tutte le righe in cui la colonna t4 include il valore [ERROR]. Importante
Mantenere la selezione di Databasepredefinita. Gli esempi di questo documento usano il database predefinito incluso in HDInsight.
Per avviare la query, selezionare Esegui sotto il foglio di lavoro. Il pulsante diventa arancione e il testo cambia in Interrompi.
Al termine dell'elaborazione della query, nella scheda Risultati vengono visualizzati i risultati dell'operazione. Il testo seguente è il risultato della query:
loglevel count [ERROR] 3È possibile usare la scheda LOG per visualizzare le informazioni di registrazione create dal processo.
Suggerimento
Scaricare o salvare i risultati dalla finestra di dialogo a discesa Azioni nella scheda Risultati .
Visual Explain
Per aprire una visualizzazione del piano di query, selezionare la scheda Visual Explain (Spiegazione visiva) sotto il foglio di lavoro.
La vista Visual Explain (Spiegazione visiva) della query può essere utile per conoscere il flusso delle query complesse.
Interfaccia utente di Tez
Per visualizzare l'interfaccia utente di Tez per la query, selezionare la scheda Interfaccia utente tez sotto il foglio di lavoro.
Importante
Tez non viene usato per risolvere tutte le query. Molte query possono essere risolte senza usare Tez.
Visualizzazione cronologia processo
La scheda Jobs (Processi) visualizza una cronologia delle query Hive.
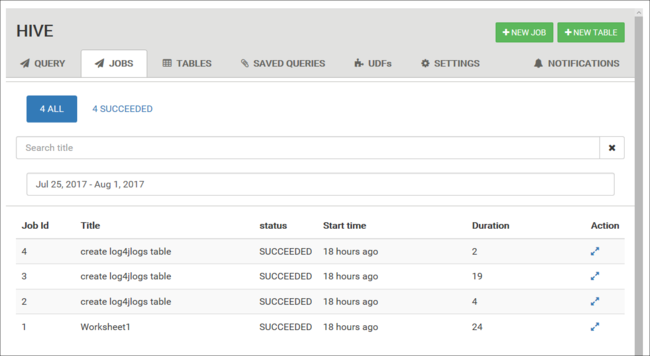
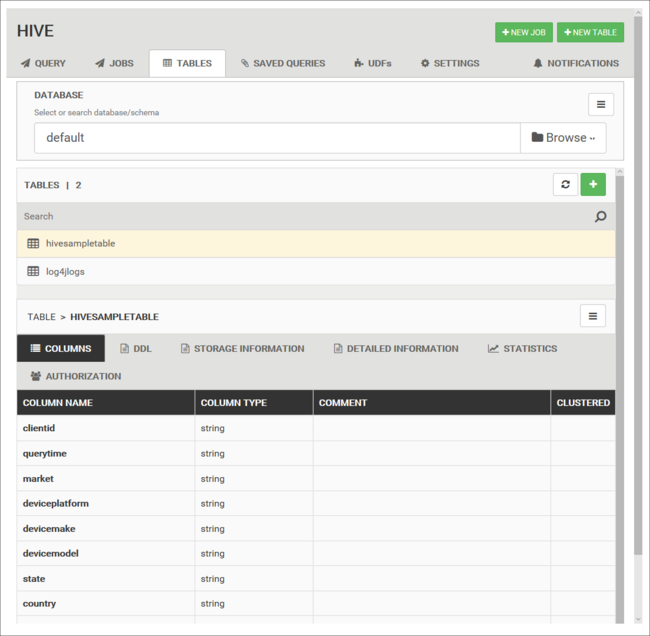
Tabelle di database
È possibile usare la scheda Tables (Tabelle) per utilizzare le tabelle in un database Hive.
Query salvate
Dalla scheda Query è facoltativamente possibile salvare le query. Dopo aver salvato una query, è possibile riusarla dalla scheda Query salvate.
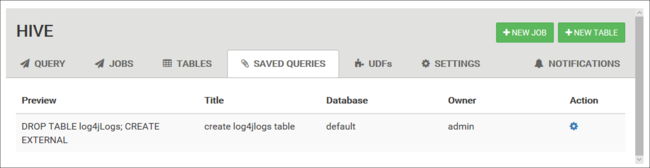
Suggerimento
Le query salvate vengono archiviate nell'archiviazione cluster predefinita. Le query salvate sono disponibili nel percorso /user/<username>/hive/scripts. Vengono archiviate come file .hql in testo normale.
Se si elimina il cluster, ma si conserva l'archiviazione, è possibile usare un'utilità come Azure Storage Explorer o Data Lake Storage Explorer dal portale di Azure per recuperare le query.
Funzioni definite dall'utente
Hive può essere esteso tramite funzioni definite dall'utente (UDF), che consentono di implementare funzionalità o logiche non facilmente modellate in HiveQL.
La scheda della funzione definita dall'utente nella parte superiore della vista Hive consente di dichiarare e salvare un set di funzioni definite dall'utente, che è possibile usare con Query Editor.
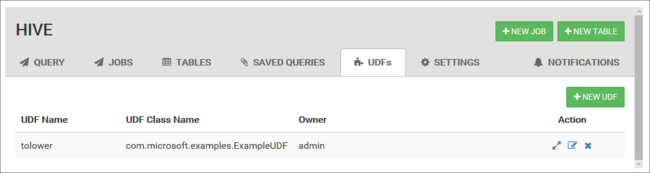
Nella parte inferiore della Editor di query viene visualizzato un pulsante Inserisci funzioni definite dall'utente. Questa voce visualizza un elenco a discesa delle funzioni definite dall'utente definite nella visualizzazione Hive. La selezione di una funzione definita dall'utente aggiungerà istruzioni HiveQL alla query per abilitare la funzione definita dall'utente.
Ad esempio, se è stata definita una funzione definita dall'utente con le proprietà seguenti:
Nome della risorsa: myudfs
Percorso della risorsa: /myudfs.jar
Nome della funzione definita dall'utente: myawesomeudf
Nome della classe per la funzione definita dall'utente: com.myudfs.Awesome
Se si usa il pulsante Insert udfs (Inserisci funzioni definite dall'utente), verrà visualizzata una voce denominata myudfs, con un altro elenco a discesa per ogni funzione definita dall'utente specificata per tale risorsa. In questo caso, myawesomeudf. Se si seleziona questa voce, verrà aggiunto quanto segue all'inizio della query:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
Si potrà quindi usare la funzione definita dall'utente nella query, Ad esempio: SELECT myawesomeudf(name) FROM people;.
Per altre informazioni sull'uso di funzioni definite dall'utente con Hive in HDInsight, vedere gli articoli seguenti:
- Usare le funzioni definite dall'utente di Python con Apache Hive e Apache Pig in HDInsight
- Usare una funzione definita dall'utente Java con Apache Hive in HDInsight
Settings di Hive
È possibile modificare diverse impostazioni di Hive, ad esempio il motore di esecuzione per Hive da Tez (impostazione predefinita), in MapReduce.
Passaggi successivi
Per informazioni generali su Hive in HDInsight:
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per