Ottimizzare Apache Hive con Apache Ambari in Azure HDInsight
Apache Ambari è un'interfaccia Web per gestire e monitorare i cluster HDInsight. Per un'introduzione all'interfaccia utente Web di Ambari, vedere Gestire i cluster HDInsight usando l'interfaccia utente Web di Apache Ambari.
Le sezioni seguenti descrivono le opzioni di configurazione per ottimizzare le prestazioni generali di Apache Hive.
- Per modificare i parametri di configurazione di Hive, selezionare Hive dalla barra laterale Services (Servizi).
- Passare alla scheda Configs (Configurazioni).
Impostare il motore di esecuzione di Hive
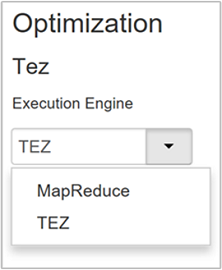
Hive fornisce due motori di esecuzione: Apache Hadoop MapReduce e Apache TEZ. Tez è più veloce di MapReduce. I cluster Linux in HDInsight usano Tez come motore di esecuzione predefinito. Per cambiare il motore di esecuzione:
Nella scheda Configs (Configurazioni) di Hive digitare execution engine nella casella di filtro.
Il valore predefinito della proprietà Optimization (Ottimizzazione) è Tez.
Ottimizzare i mapper
Hadoop prova a dividere (eseguire il mapping) di un singolo file in più file e a elaborare i file risultanti in parallelo. Il numero di mapper dipende dal numero di suddivisioni. I due parametri di configurazione seguenti determinano il numero di suddivisioni per il motore di esecuzione:
tez.grouping.min-size: limite minimo delle dimensioni di una suddivisione raggruppata, con un valore predefinito di 16 MB (16.777.216 byte).tez.grouping.max-size: limite massimo delle dimensioni di una suddivisione raggruppata, con un valore predefinito di 1 GB (1.073.741.824 byte).
Come linea guida sulle prestazioni, ridurre entrambi questi parametri per migliorare la latenza, aumentare la velocità effettiva.
Ad esempio, per impostare quattro attività di mapper per dimensioni dei dati pari a 128 MB, impostare entrambi i parametri su 32 MB ognuno (33.554.432 byte).
Per modificare i parametri limite, passare alla scheda Configs (Configurazioni) del servizio Tez. Espandere il pannello General (Generale) e individuare i parametri
tez.grouping.max-sizeetez.grouping.min-size.Impostare entrambi i parametri su 33.554.432 byte (32 MB).

Queste modifiche interessano tutti i processi Tez nel server. Per ottenere un risultato ottimale, scegliere valori appropriati per i parametri.
Ottimizzare i riduttori
Apache ORC e Snappy offrono entrambi prestazioni elevate. Hive potrebbe tuttavia avere un numero troppo basso di riduttori per impostazione predefinita e causare quindi colli di bottiglia.
Si supponga, ad esempio, di avere dati di input di dimensioni pari a 50 GB. Tali dati nel formato ORC con la compressione Snappy sono pari a 1 GB. Hive stima il numero di riduttori necessari nel modo seguente: (numero di byte di input per i mapper / hive.exec.reducers.bytes.per.reducer).
Con le impostazioni predefinite, questo esempio è costituito da quattro riduttori.
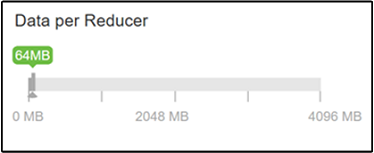
Il parametro hive.exec.reducers.bytes.per.reducer specifica il numero di byte elaborati per riduttore. Il valore predefinito è 64 MB. Se si diminuisce questo valore, il parallelismo aumenta e le prestazioni possono migliorare. Se lo si diminuisce troppo, potrebbero anche essere generati troppi riduttori, che possono influire negativamente sulle prestazioni. Questo parametro è basato sugli specifici requisiti per i dati, sulle impostazioni di compressione e su altri fattori ambientali.
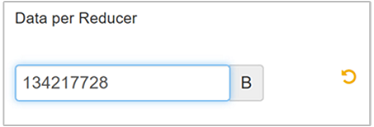
Per modificare il parametro, passare alla scheda Configs (Configurazioni) di Hive e trovare il parametro Data per Reducer (Dati per riduttore) nella pagina Settings (Impostazioni).
Selezionare Edit (Modifica) per impostare il valore su 128 MB (134.217.728 byte) e quindi premere INVIO per salvare.
Data una dimensione di input di 1.024 MB, con 128 MB di dati per riduttore, sono presenti otto riduttori (1024/128).
Un valore non corretto per il parametro Data per Reducer (Dati per riduttore) può restituire un numero elevato di riduttori, che influisce negativamente sulle prestazioni della query. Per limitare il numero massimo di riduttori, impostare
hive.exec.reducers.maxsu un valore appropriato. Il valore predefinito è 1009.
Abilitare l'esecuzione parallela
Una query Hive viene eseguita in una o più fasi. Se le fasi indipendenti possono essere eseguite in parallelo, le prestazioni della query miglioreranno.
Per abilitare l'esecuzione della query parallela, passare alla scheda Config (Configurazioni) di Hive e cercare la proprietà
hive.exec.parallel. Il valore predefinito è false. Impostare il valore su true e quindi premere INVIO per salvare il valore.Per limitare il numero di processi da eseguire in parallelo, modificare la
hive.exec.parallel.thread.numberproprietà . Il valore predefinito è 8.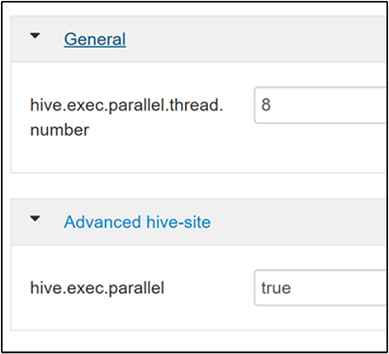
Abilitare la vettorializzazione
Hive elabora i dati una riga alla volta. Con la vettorializzazione Hive elabora i dati in blocchi di 1.024 righe invece che una riga alla volta. La vettorializzazione è applicabile solo al formato di file ORC.
Per abilitare un'esecuzione di query vettorializzata, passare alla scheda Configs (Configurazioni) di Hive e cercare il parametro
hive.vectorized.execution.enabled. Il valore predefinito è true per Hive 0.13.0 o versione successiva.Per abilitare l'esecuzione vettorializzata per il lato reduce della query, impostare il parametro
hive.vectorized.execution.reduce.enabledsu true. Il valore predefinito è false.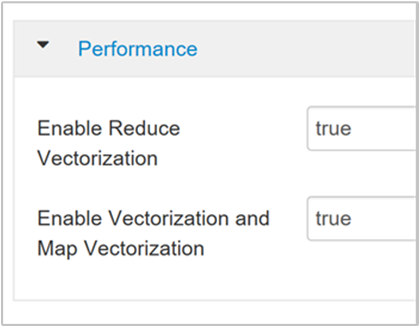
Abilitare l'ottimizzazione basata sui costi
Per impostazione predefinita, Hive segue un set di regole per trovare un piano di esecuzione della query ottimale. L'ottimizzazione basata sui costi valuta più piani per eseguire una query. Assegna un costo a ogni piano, quindi determina il piano più economico per eseguire una query.
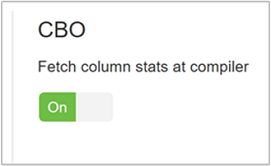
Per abilitare l'oggetto CBO, passare a Configurazioni> Hive>Impostazioni e trovare Abilita Ottimizzazione basata sui costi, quindi impostare il pulsante Attiva/Disattiva.

I parametri di configurazione aggiuntivi seguenti migliorano le prestazioni della query Hive quando l'ottimizzazione basata sui costi è abilitata:
hive.compute.query.using.statsSe impostato su true, Hive usa le statistiche archiviate nel metastore per rispondere a query semplici, ad esempio
count(*).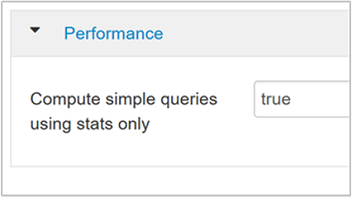
hive.stats.fetch.column.statsQuando l'ottimizzazione basata sui costi è abilitata, vengono create statistiche di colonna. Hive usa le statistiche di colonna, archiviate nel metastore, per ottimizzare le query. Recuperare le statistiche per ogni colonna richiede più tempo quando il numero di colonne è elevato. Se impostata su false, questa impostazione disabilita il recupero delle statistiche di colonna dal metastore.
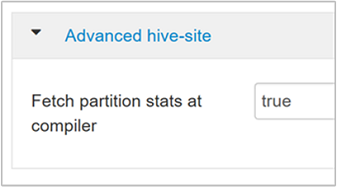
hive.stats.fetch.partition.statsLe statistiche della partizione di base, ad esempio numero di righe, dimensioni dei dati e dimensioni dei file, vengono archiviate nel metastore. Se impostato su true, le statistiche della partizione vengono recuperate dal metastore. Se false, le dimensioni del file vengono recuperate dal file system. E il numero di righe viene recuperato dallo schema di riga.
Per altre informazioni, vedere il post di blog sull'ottimizzazione basata sui costi hive in Analytics on Azure Blog (Analisi su Azure)
Abilitare la compressione intermedia
Le attività mappe creano file intermedi che vengono usati dalle attività riduttori. La compressione intermedia riduce le dimensioni dei file intermedi.
I processi Hadoop presentano in genere colli di bottiglia a causa dell'I/O. La compressione dei dati può velocizzare l'I/O e il trasferimento di rete complessivo.
I tipi di compressione disponibili sono:
| Formato | Strumento | Algoritmo | Estensione file | Divisibile |
|---|---|---|---|---|
| Gzip | Gzip | DEFLATE | .gz |
No |
| Bzip2 | Bzip2 | Bzip2 | .bz2 |
Sì |
| LZO | Lzop |
LZO | .lzo |
Sì, se indicizzato |
| Snappy | N/D | Snappy | Snappy | No |
Come regola generale, la suddivisione del metodo di compressione è importante. In caso contrario, verranno creati pochi mapper. Se i dati di input sono costituiti da testo, bzip2 è l'opzione migliore. Per il formato ORC, Snappy è l'opzione di compressione più rapida.
Per abilitare la compressione intermedia, passare alla scheda Configs (Configurazioni) di Hive e quindi impostare il parametro
hive.exec.compress.intermediatesu true. Il valore predefinito è false.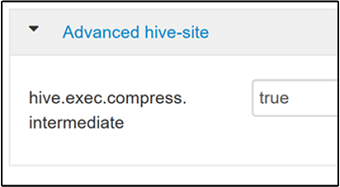
Nota
Per comprimere i file intermedi, scegliere un codec di compressione con costi di CPU più bassi, anche se il codec non ha un output di compressione elevato.
Per impostare il codec di compressione intermedia, aggiungere la proprietà personalizzata
mapred.map.output.compression.codecal filehive-site.xmlomapred-site.xml.Per aggiungere un'impostazione personalizzata:
a. Passare a Hive Configs Advanced Custom hive-site (Configurazioni>hive>avanzate).>
b. Selezionare Aggiungi proprietà nella parte inferiore del riquadro Sito hive personalizzato.
c. Nella finestra Add Property (Aggiungi proprietà) immettere
mapred.map.output.compression.codeccome chiave eorg.apache.hadoop.io.compress.SnappyCodeccome valore.d. Selezionare Aggiungi.
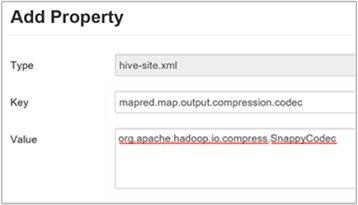
Questa impostazione comprime il file intermedio usando la compressione Snappy. Dopo che la proprietà è stata aggiunta, viene visualizzata nel riquadro Custom hive-site (hive-site personalizzato).
Nota
Questa procedura modifica il file
$HADOOP_HOME/conf/hive-site.xml.
Comprimere l'output finale
Anche l'output di Hive finale può essere compresso.
Per comprimere l'output di Hive finale, passare alla scheda Configs (Configurazioni) di Hive e quindi impostare il parametro
hive.exec.compress.outputsu true. Il valore predefinito è false.Per scegliere il codec di compressione dell'output, aggiungere la proprietà personalizzata
mapred.output.compression.codecal riquadro Custom hive-site (hive-site personalizzato), come descritto nel passaggio 3 della sezione precedente.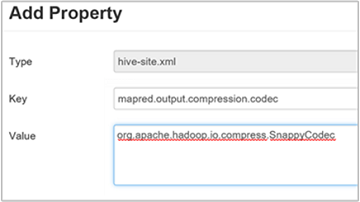
Abilitare l'esecuzione speculativa
L'esecuzione speculativa avvia un determinato numero di attività duplicate per rilevare e negare l'elenco di attività a esecuzione lenta. Durante il miglioramento dell'esecuzione complessiva del processo ottimizzando i risultati delle singole attività.
È consigliabile non attivare l'esecuzione speculativa per le attività MapReduce a esecuzione prolungata con grandi quantità di input.
Per abilitare l'esecuzione speculativa, passare alla scheda Configs (Configurazioni) di Hive e quindi impostare il parametro
hive.mapred.reduce.tasks.speculative.executionsu true. Il valore predefinito è false.
Ottimizzare le partizioni dinamiche
Hive consente di creare partizioni dinamiche durante l'inserimento di record in una tabella, senza predefinito ogni partizione. Questa capacità è una funzionalità potente. Anche se può comportare la creazione di un numero elevato di partizioni. E un numero elevato di file per ogni partizione.
Per creare partizioni dinamiche in Hive, il parametro
hive.exec.dynamic.partitiondeve essere impostato su (impostazione predefinita).Impostare la modalità di partizione dinamica su strict. Nella modalità strict almeno una partizione deve essere statica Questa impostazione impedisce le query senza il filtro di partizione nella clausola WHERE, ovvero strict impedisce le query che analizzano tutte le partizioni. Passare alla scheda Configs (Configurazioni) di Hive e quindi impostare
hive.exec.dynamic.partition.modesu strict. Il valore predefinito è nonstrict.Per limitare il numero di partizioni dinamiche da creare, modificare il parametro
hive.exec.max.dynamic.partitions. Il valore predefinito è 5000.Per limitare il numero totale di partizioni dinamiche per nodo, modificare
hive.exec.max.dynamic.partitions.pernode. Il valore predefinito è 2000.
Abilitare la modalità locale
La modalità locale consente a Hive di eseguire tutte le attività di un processo in un singolo computer. O a volte in un singolo processo. Questa impostazione migliora le prestazioni delle query se i dati di input sono di piccole dimensioni. E il sovraccarico dell'avvio di attività per le query utilizza una percentuale significativa dell'esecuzione complessiva delle query.
Per abilitare la modalità locale, aggiungere il parametro hive.exec.mode.local.auto al pannello Custom hive-site (hive-site personalizzato), come illustrato nel passaggio 3 della sezione Abilitare la compressione intermedia.
Impostare una singola query MultiGROUP BY per MapReduce
Quando questa proprietà è impostata su true, una query MultiGROUP BY con chiavi group-by comuni genera un singolo processo MapReduce.
Per abilitare questo comportamento, aggiungere il parametro hive.multigroupby.singlereducer al riquadro Custom hive-site (hive-site personalizzato), come illustrato nel passaggio 3 della sezione Abilitare la compressione intermedia.
Ottimizzazioni di Hive aggiuntive
Le sezioni seguenti descrivono altre ottimizzazioni relative a Hive che è possibile impostare.
Ottimizzazioni del join
Il tipo di join predefinito in Hive è un join casuale. In Hive speciali mapper leggono l'input e generano una coppia chiave/valore di join per un file intermedio. Hadoop ordina e unisce queste coppie in una fase casuale. Questa fase casuale è costosa. La scelta del join appropriato in base ai dati può migliorare considerevolmente le prestazioni.
| Tipo di join | Se | Come | Settings di Hive | Commenti |
|---|---|---|---|---|
| Join casuale |
|
|
Non sono necessarie impostazioni di Hive significative | Funziona sempre |
| Map Join |
|
|
hive.auto.confvert.join=true |
Veloce, ma limitato |
| Sort Merge Bucket | Se entrambe le tabelle sono:
|
Ogni processo:
|
hive.auto.convert.sortmerge.join=true |
Efficienza |
Ottimizzazioni del motore di esecuzione
Raccomandazioni aggiuntive per ottimizzare il motore di esecuzione Hive:
| Impostazione | Consigliato | Impostazione predefinita di HDInsight |
|---|---|---|
hive.mapjoin.hybridgrace.hashtable |
True = più sicuro, più lento; false = più veloce | false |
tez.am.resource.memory.mb |
Limite superiore di 4 GB nella maggior parte dei casi | Ottimizzazione automatica |
tez.session.am.dag.submit.timeout.secs |
300+ | 300 |
tez.am.container.idle.release-timeout-min.millis |
20000+ | 10000 |
tez.am.container.idle.release-timeout-max.millis |
40000+ | 20000 |
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per