Personalizzazione del modello (anteprima versione 4.0)
Importante
Questa funzionalità è ora deprecata. Il 10 gennaio 2025, l'API di anteprima Analisi immagini di Intelligenza artificiale di Azure 4.0, Rilevamento oggetti personalizzati e Riconoscimento del prodotto verrà ritirata. Dopo questa data, le chiamate API a questi servizi avranno esito negativo.
Per mantenere il funzionamento dei modelli, passare a Visione personalizzata di Azure AI, ora disponibile a livello generale. Visione personalizzata offre funzionalità simili a quelle in fase di ritiro.
La personalizzazione del modello consente di eseguire il training di un modello di analisi delle immagini specializzato per il proprio caso d'uso. I modelli personalizzati possono eseguire la classificazione delle immagini (i tag si applicano all'intera immagine) o il rilevamento degli oggetti (i tag si applicano a aree specifiche dell'immagine). Dopo aver creato e sottoposto a training il modello personalizzato, questo appartiene alla risorsa Visione ed è possibile chiamarlo usando l'API Analizza immagine.
Implementare la personalizzazione del modello in modo rapido e semplice seguendo una guida introduttiva:
Importante
È possibile eseguire il training di un modello personalizzato usando il servizio Visione personalizzata o il servizio Analisi immagini 4.0 con la personalizzazione del modello. Nella tabella seguente vengono confrontati i due servizi.
| Aree | Servizio Visione personalizzata | Servizio Analisi immagini 4.0 | ||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Attività | Classificazione immagini Rilevamento oggetti |
Classificazione immagini Rilevamento oggetti |
||||||||||||||||||||||||||||||||||||
| Modello di base | CNN | Modello trasformatore | ||||||||||||||||||||||||||||||||||||
| Etichettatura | Customvision.ai | AML Studio | ||||||||||||||||||||||||||||||||||||
| Portale Web | Customvision.ai | Vision Studio | ||||||||||||||||||||||||||||||||||||
| Librerie | REST, SDK | REST, esempio in Python | ||||||||||||||||||||||||||||||||||||
| Dati di training minimi necessari | 15 immagini per categoria | 2-5 immagini per categoria | ||||||||||||||||||||||||||||||||||||
| Archiviazione dei dati di training | Caricata nel servizio | Account di archiviazione BLOB del cliente | ||||||||||||||||||||||||||||||||||||
| Hosting di modelli | Cloud ed edge | Solo hosting su cloud, l'hosting in contenitori edge disponibile in futuro | ||||||||||||||||||||||||||||||||||||
| Qualità dell'intelligenza artificiale |
|
|
||||||||||||||||||||||||||||||||||||
| Prezzi | Prezzi della Visione personalizzata | Prezzi di Analisi immagini |
Componenti di uno scenario
I componenti principali di un sistema di personalizzazione del modello sono le immagini di training, il file COCO, l'oggetto set di dati e l'oggetto modello.
Immagini di training
Il set di immagini di training deve includere diversi esempi di ognuna delle etichette da rilevare. È anche opportuno raccogliere alcune immagini aggiuntive con cui testare il modello dopo il training. Le immagini devono essere archiviate in un contenitore di Archiviazione di Azure per poter essere accessibili al modello.
Per eseguire il training del modello in modo efficace, usare le immagini con diversi oggetti visivi. Selezionare immagini diverse per:
- angolazione
- illuminazione
- background
- stile visivo
- soggetti singoli/raggruppati
- size
- type
Assicurarsi anche che tutte le immagini di training soddisfino i criteri seguenti:
- L'immagine deve essere presentata in formato JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF o MPO.
- Le dimensioni del file dell'immagine devono essere minori di 20 megabyte (MB).
- Le dimensioni dell'immagine devono essere superiori a 50 x 50 pixel e inferiori a 16.000 x 16.000 pixel.
File COCO
Il file COCO fa riferimento a tutte le immagini di training e le associa alle informazioni di etichettatura. Nel caso del rilevamento degli oggetti, ha specificato le coordinate del rettangolo delimitatore di ogni tag in ogni immagine. Questo file deve essere nel formato COCO, ovvero un tipo specifico di file JSON. Il file COCO deve essere archiviato nello stesso contenitore di Archiviazione di Azure delle immagini di training.
Suggerimento
Informazioni sui file COCO
I file COCO sono file JSON con campi obbligatori specifici: "images", "annotations" e "categories". Un file COCO di esempio ha un aspetto simile al seguente:
{
"images": [
{
"id": 1,
"width": 500,
"height": 828,
"file_name": "0.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/0.jpg"
},
{
"id": 2,
"width": 754,
"height": 832,
"file_name": "1.jpg",
"absolute_url": "https://blobstorage1.blob.core.windows.net/cpgcontainer/1.jpg"
},
...
],
"annotations": [
{
"id": 1,
"category_id": 7,
"image_id": 1,
"area": 0.407,
"bbox": [
0.02663142641129032,
0.40691584277841153,
0.9524163571731749,
0.42766634515266866
]
},
{
"id": 2,
"category_id": 9,
"image_id": 2,
"area": 0.27,
"bbox": [
0.11803319477782331,
0.41586723392402375,
0.7765206955096307,
0.3483334397217212
]
},
...
],
"categories": [
{
"id": 1,
"name": "vegall original mixed vegetables"
},
{
"id": 2,
"name": "Amy's organic soups lentil vegetable"
},
{
"id": 3,
"name": "Arrowhead 8oz"
},
...
]
}
Informazioni di riferimento sui campi del file COCO
Se si genera un file COCO partendo da zero, assicurarsi che tutti i campi obbligatori siano stati compilati con i dati corretti. Le tabelle seguenti descrivono tutti i campi presenti in un file COCO:
"immagini"
| Chiave | Type | Description | Obbligatorio? |
|---|---|---|---|
id |
integer | ID immagine univoco, a partire da 1 | Sì |
width |
integer | Larghezza dell'immagine in pixel | Sì |
height |
integer | Altezza dell'immagine in pixel | Sì |
file_name |
string | Nome univoco dell’immagine | Sì |
absolute_url oppure coco_url |
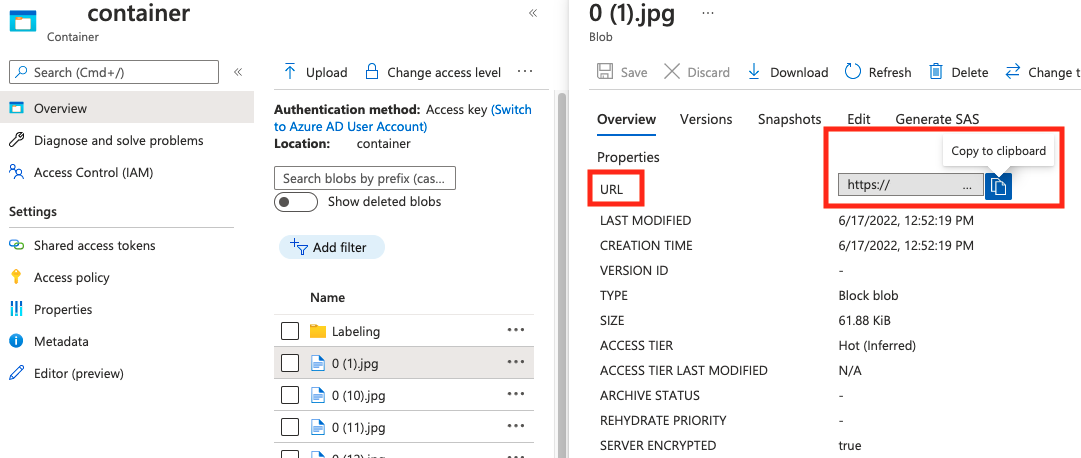
string | Percorso dell’immagine come URI assoluto in un BLOB in un contenitore BLOB. La risorsa Visione deve avere l'autorizzazione a leggere i file di annotazione e tutti i file di immagine cui si fa riferimento. | Sì |
Il valore di absolute_url è reperibile nelle proprietà del contenitore BLOB:
"annotazioni"
| Chiave | Type | Description | Obbligatorio? |
|---|---|---|---|
id |
integer | ID dell’annotazione | Sì |
category_id |
integer | ID della categoria definita nella sezione categories |
Sì |
image_id |
integer | ID dell’immagine | Sì |
area |
integer | Valore di 'Width' x 'Height' (terzo e quarto valore di bbox) |
No |
bbox |
list[float] | Coordinate relative del rettangolo delimitatore (da 0 a 1), nell'ordine 'Left', 'Top', 'Width', 'Height' | Sì |
"categorie"
| Chiave | Type | Description | Obbligatorio? |
|---|---|---|---|
id |
integer | ID univoco per ogni categoria (classe di etichetta). Devono essere presenti nella sezione annotations. |
Sì |
name |
string | Nome della categoria (classe etichetta) | Sì |
Verifica del file COCO
È possibile utilizzare il codice di esempio Python per controllare il formato di un file COCO.
Oggetto Dataset
L'oggetto Set di dati è una struttura di dati archiviata dal servizio Analisi immagini che fa riferimento al file di associazione. È necessario creare un oggetto Dataset prima di poter creare ed eseguire il training di un modello.
Oggetto modello
L'oggetto Modello è una struttura di dati archiviata dal servizio Analisi immagini che rappresenta un modello personalizzato. Deve essere associato a un set di dati per eseguire il training iniziale. Dopo aver eseguito il training, è possibile eseguire query sul modello immettendone il nome nel parametro di query model-name della chiamata API Analizza immagine.
Limiti di quota
Nella tabella seguente vengono descritti i limiti sulla scala dei progetti di modello personalizzati.
| Categoria | Classificatore di immagini generiche | Rilevatore di oggetti generici |
|---|---|---|
| Max # ore di training | 288 (12 giorni) | 288 (12 giorni) |
| Max # immagini di training | 1\.000.000 | 200.000 |
| Max # immagini di valutazione | 100,000 | 100,000 |
| Min # immagini di training per categoria | 2 | 2 |
| Max # tag per immagine | 1 | N/D |
| Max # aree per immagine | N/D | 1.000 |
| Max # categorie | 2500 | 1.000 |
| Min # categorie | 2 | 1 |
| Dimensioni max immagine (training) | 20 MB | 20 MB |
| Dimensioni max immagine (stima) | Sincronizzazione: 6 MB, Batch: 20 MB | Sincronizzazione: 6 MB, Batch: 20 MB |
| Larghezza/altezza max immagine (training) | 10.240 | 10.240 |
| Larghezza/altezza min immagine (stima) | 50 | 50 |
| Aree disponibili | Stati Uniti occidentali 2, Stati Uniti orientali, Europa occidentale | Stati Uniti occidentali 2, Stati Uniti orientali, Europa occidentale |
| Tipi di immagine accettati | jpg, png, bmp, gif, jpeg | jpg, png, bmp, gif, jpeg |
Domande frequenti
Perché l'importazione del file COCO non riesce durante l'importazione dall'archivio BLOB?
Attualmente, Microsoft sta risolvendo un problema che causa l'esito negativo dell'importazione di file COCO con set di dati di grandi dimensioni quando viene avviato in Vision Studio. Per eseguire il training con un set di dati di grandi dimensioni, è consigliabile, in alternativa, utilizzare l'API REST.
Perché il training richiede più tempo/meno tempo del budget specificato?
Il budget di training specificato è il tempo di calcolo calibrato, non l'orario. Ecco alcuni motivi comuni per cui la differenza è elencata:
Più tempo del budget specificato:
- L'analisi delle immagini presenta un traffico di training elevato e le risorse GPU possono essere limitate. Il processo potrebbe attendere in coda o essere messo in attesa durante il training.
- Il processo di training back-end si è verificato in errori imprevisti, causando la logica di ripetizione dei tentativi. Le esecuzioni non riuscite non consumano il budget, ma questo può portare a tempi di training più lunghi in generale.
- I dati vengono archiviati in un'area diversa rispetto alla risorsa Visione, con un tempo di trasmissione dei dati più lungo.
Più breve del budget specificato: i fattori seguenti accelerano l'allenamento a costo di usare più budget in un determinato orario di tempo.
- Analisi immagini a volte esegue il training con più GPU a seconda dei dati.
- Analisi immagini a volte esegue il training di più prove di esplorazione su più GPU contemporaneamente.
- Analisi immagini a volte usa SKU GPU premier (più veloci) per eseguire il training.
Perché il training ha esito negativo e cosa devo fare?
Di seguito sono riportati alcuni motivi comuni per cui si è verificato un errore di training:
diverged: il training non può apprendere elementi significativi dai dati. Alcune cause comuni:- I dati non sono sufficienti: fornire più dati dovrebbe essere utile.
- I dati sono di scarsa qualità: controllare se le immagini sono a bassa risoluzione, proporzioni estreme o se le annotazioni sono errate.
notEnoughBudget: il budget specificato non è sufficiente per le dimensioni del set di dati e del tipo di modello di cui si sta eseguendo il training. Specificare un budget maggiore.datasetCorrupt: in genere ciò significa che le immagini fornite non sono accessibili o il file di annotazione è nel formato errato.datasetNotFound: impossibile trovare il set di datiunknown: potrebbe trattarsi di un problema back-end. Contattare il supporto per l'indagine.
Quali metriche vengono usate per valutare i modelli?
Vengono usate le metriche seguenti:
- Classificazione immagini: precisione media, Accuratezza Top 1, Accuratezza Top 5
- Rilevamento oggetti: precisione media media @ 30, precisione media media @ 50, precisione media media @ 75
Perché la registrazione del set di dati ha esito negativo?
Le risposte API devono essere abbastanza informative. Sono:
DatasetAlreadyExists: esiste già un set di dati con lo stesso nomeDatasetInvalidAnnotationUri: "È stato fornito un URI non valido tra gli URI di annotazione in fase di registrazione del set di dati.
Quante immagini sono necessarie per una qualità ragionevole/buona/migliore del modello?
Sebbene i modelli di Firenze abbiano una grande capacità di esecuzione ridotta (ottenendo prestazioni ottimali del modello con disponibilità limitata dei dati), in generale più dati rendono il modello sottoposto a training migliore e più affidabile. Alcuni scenari richiedono poco dati (come la classificazione di una mela contro una banana), ma altri richiedono più (come il rilevamento di 200 tipi di insetti in una foresta pluviale). Ciò rende difficile fornire una singola raccomandazione.
Se il budget per l'etichettatura dei dati è vincolato, il flusso di lavoro consigliato consiste nel ripetere i passaggi seguenti:
Raccogliere immagini
Nper classe, in cui immaginiNsono facili da raccogliere (ad esempio,N=3)Eseguire il training di un modello e testarlo nel set di valutazione.
Se le prestazioni del modello sono:
- Sufficientemente efficaci (le prestazioni sono migliori delle aspettative o delle prestazioni vicine all'esperimento precedente con meno dati raccolti): arrestare qui e usare questo modello.
- Non buone (le prestazioni sono ancora al di sotto delle aspettative o migliori rispetto all'esperimento precedente con meno dati raccolti a un margine ragionevole):
- Raccogliere più immagini per ogni classe, un numero facile da raccogliere e tornare al passaggio 2.
- Se si nota che le prestazioni non migliorano più dopo alcune iterazioni, il problema potrebbe essere dovuto al fatto che:
- questo problema non è ben definito o è troppo difficile. Contattaci per l'analisi caso per caso.
- i dati di training potrebbero essere di bassa qualità: controllare se sono presenti annotazioni errate o immagini molto basse.
Quanto budget di formazione è necessario specificare?
È necessario specificare il limite massimo di budget che si è disposti a utilizzare. Analisi immagini usa un sistema AutoML nel back-end per provare modelli diversi e ricette di training per trovare il modello migliore per il caso d'uso. Maggiore è il budget dato, maggiore è la possibilità di trovare un modello migliore.
Il sistema AutoML si arresta automaticamente anche se conclude che non è necessario provare più, anche se è ancora presente un budget rimanente. Quindi, non esaurisce sempre il budget specificato. Non è garantito che venga addebitato il budget specificato.
È possibile controllare gli iperparametri o usare i propri modelli nel training?
No, il servizio di personalizzazione del modello di analisi delle immagini usa un sistema di training AutoML a basso codice che gestisce la ricerca dell’iperparametro e la selezione del modello di base nel back-end.
È possibile esportare il modello dopo il training?
L'API di stima è supportata solo tramite il servizio cloud.
Perché la valutazione non riesce per il modello di rilevamento oggetti?
Ecco i possibili motivi:
internalServerError: si è verificato un errore sconosciuto. Riprova più tardi.modelNotFound: il modello specificato non è stato trovato.datasetNotFound: il set di dati specificato non è stato trovato.datasetAnnotationsInvalid: si è verificato un errore durante il tentativo di scaricare o analizzare le annotazioni di verità di base associate al set di dati di test.datasetEmpty: il set di dati di test non contiene annotazioni "verità di base".
Qual è la latenza prevista per le stime con modelli personalizzati?
Non è consigliabile utilizzare modelli personalizzati per ambienti business critical a causa della latenza potenzialmente elevata. Quando i clienti eseguono il training di modelli personalizzati in Vision Studio, tali modelli appartengono alla risorsa Visione di Azure AI con la quale sono stati sottoposti a training, quindi il cliente è in grado di effettuare chiamate a questi modelli tramite l'API Analizza immagine. Quando si effettuano queste chiamate, il modello personalizzato viene caricato in memoria e l’infrastruttura di previsione viene inizializzata. Quando ciò accade, i clienti potrebbero riscontrare una latenza più lunga del previsto prima di ricevere i risultati della previsione.
Privacy e sicurezza dei dati
Come per tutti i Servizi di Azure AI, gli sviluppatori che usano la personalizzazione del modello di analisi delle immagini devono essere consapevoli dei criteri di Microsoft sui dati dei clienti. Per altre informazioni, vedere la pagina sui Servizi di Azure AI nel Centro protezione di Microsoft.