L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Creare un modello di Image Analysis personalizzato
Articolo
16/10/2024
Importante
Questa funzionalità è ora deprecata. Il 31 marzo 2025, l'API di anteprima Analisi immagini di Intelligenza artificiale di Azure 4.0 personalizzata, rilevamento oggetti personalizzati e api di anteprima del riconoscimento del prodotto verrà ritirata. Dopo questa data, le chiamate API a questi servizi avranno esito negativo.
Per mantenere il funzionamento dei modelli, passare a Visione personalizzata di Azure AI, ora disponibile a livello generale. Visione personalizzata offre funzionalità simili a quelle in fase di ritiro.
Image Analysis 4.0 consente di eseguire il training di un modello personalizzato con immagini di training personalizzate. Assegnando manualmente delle etichette alle immagini, è possibile eseguire il training di un modello per applicare tag personalizzati alle immagini (classificazione immagini), oppure per rilevare oggetti personalizzati (rilevamento oggetti). I modelli di analisi delle immagini 4.0 sono particolarmente efficaci durante l'apprendimento con pochi scatti , quindi è possibile ottenere modelli accurati con meno dati di training.
Nella presente guida si illustra come creare ed eseguire il training di un modello di classificazione immagini personalizzato. Sono indicate alcune differenze tra il training di un modello di classificazione immagini e il modello di rilevamento oggetti.
Nota
La personalizzazione del modello è disponibile tramite l'API REST e Vision Studio, ma non tramite gli SDK del linguaggio client.
Dopo aver creato la sottoscrizione di Azure, creare una risorsa di Visione nel portale di Azure per ottenere la chiave e l'endpoint. Se si seguono le istruzioni della presente guida utilizzando Vision Studio, è necessario creare la risorsa nell'area Stati Uniti orientali. Al termine della distribuzione, fare clic su Vai alla risorsa. Copiare la chiave e l'endpoint in un percorso temporaneo per un uso successivo.
Una risorsa di Archiviazione di Azure. Creare una risorsa di archiviazione.
Un set di immagini con cui eseguire il training del modello di classificazione. È possibile usare il set di immagini di esempio in GitHub. In alternativa, è possibile usare immagini personalizzate. Sono sufficienti circa 3-5 immagini per classe.
Nota
Non è consigliabile usare modelli personalizzati per ambienti business critical a causa di una potenziale latenza elevata. Quando i clienti eseguono il training di modelli personalizzati in Vision Studio, tali modelli appartengono alla risorsa Visione con la quale sono stati sottoposti a training, quindi il cliente è in grado di effettuare chiamate a questi modelli tramite l'API Analizza immagine. Quando si effettuano queste chiamate, il modello personalizzato viene caricato in memoria e l'infrastruttura di previsione viene inizializzata. Quando ciò accade, i clienti potrebbero riscontrare una latenza più lunga del previsto prima di ricevere i risultati della previsione.
Per iniziare, passare a Vision Studio e selezionare la scheda di analisi immagini. Selezionare quindi il riquadro Modelli personalizzati.
Successivamente, accedere con l'account di Azure e selezionare la risorsa Visione. Se non è presente, è possibile crearne una da questa schermata.
Preparare le immagini per eseguire il training
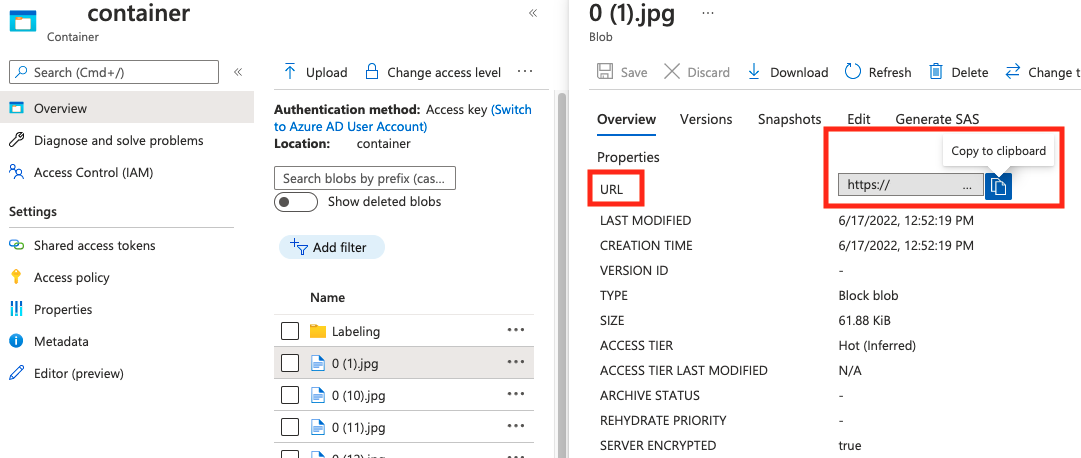
Sarà necessario caricare i dati di training in un contenitore di Archiviazione BLOB di Azure. Passare alla risorsa di archiviazione nel portale di Azure e passare alla scheda Browser archiviazione. Qui è possibile creare un contenitore BLOB e caricare le immagini. Inserirle tutte nella radice del contenitore.
Aggiungere un set di dati
Per eseguire il training di un modello personalizzato, è necessario associarlo a un Set di dati nel quale siano presenti le immagini e le relative informazioni sull'etichetta come dati di training. In Vision Studio, selezionare la scheda Set di dati per visualizzare i set di dati.
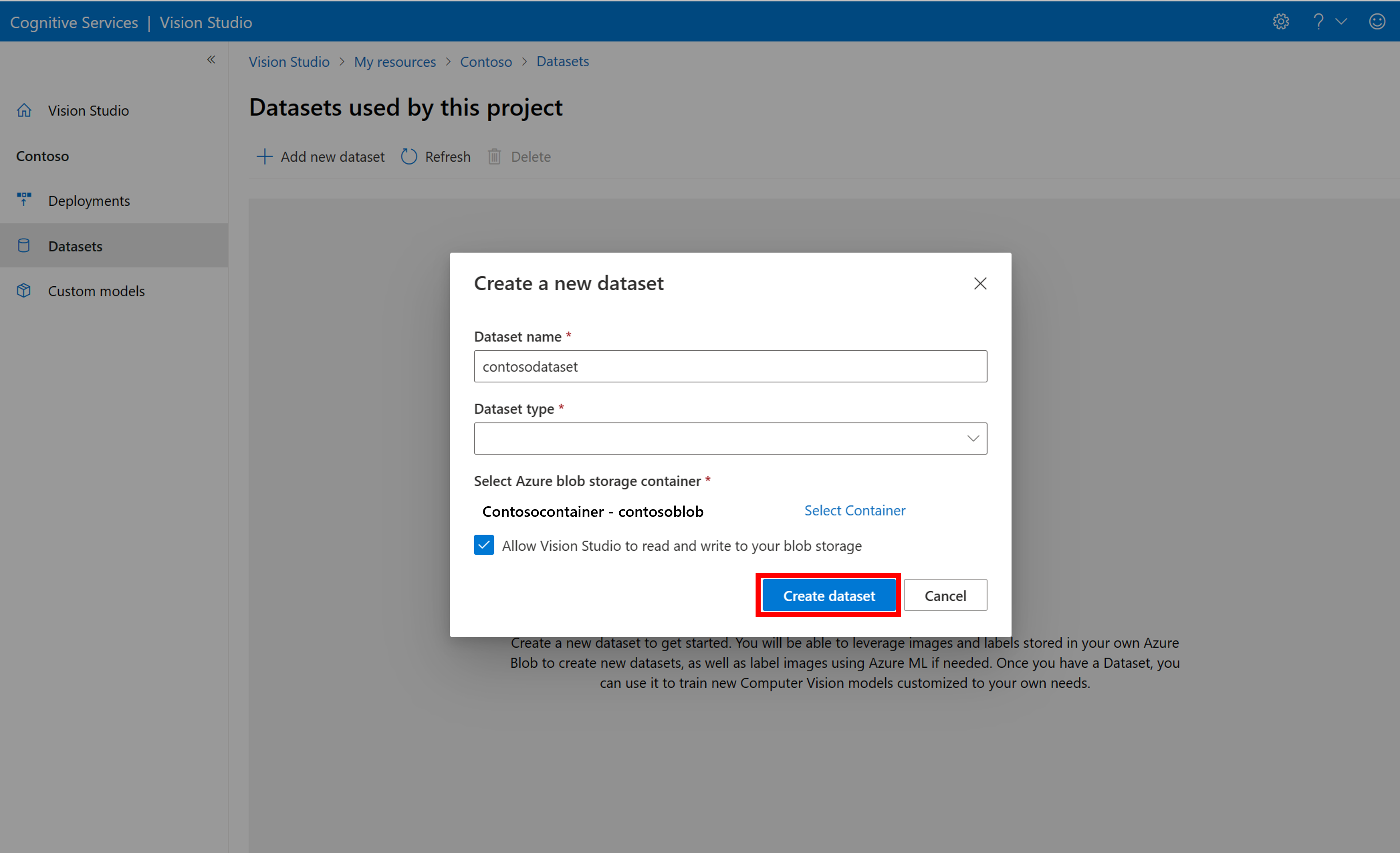
Per creare un nuovo set di dati, selezionare Aggiungi nuovo set di dati. Nella finestra popup immettere un nome e selezionare un tipo di set di dati per il caso d'uso. I modelli di classificazione delle immagini applicano etichette di contenuto all'intera immagine, mentre i modelli di rilevamento oggetti applicano etichette oggetti a posizioni specifiche nell'immagine. I modelli di riconoscimento dei prodotti sono una sottocategoria di modelli di rilevamento oggetti ottimizzati per il rilevamento dei prodotti al dettaglio.
Selezionare quindi il contenitore dall'account di Archiviazione BLOB di Azure in cui sono state archiviate le immagini di training. Selezionare la casella per consentire a Vision Studio l'accesso in lettura e scrittura nel contenitore di archiviazione BLOB. Questo è un passaggio necessario per importare i dati con etichetta. Creazione del set di dati.
Creare un progetto di etichettatura di Azure Machine Learning
Per trasmettere le informazioni sull'etichettatura è necessario disporre di un file COCO. Un modo semplice per generare un file COCO consiste nel creare un progetto di Azure Machine Learning, contenente un flusso di lavoro di etichettatura dei dati.
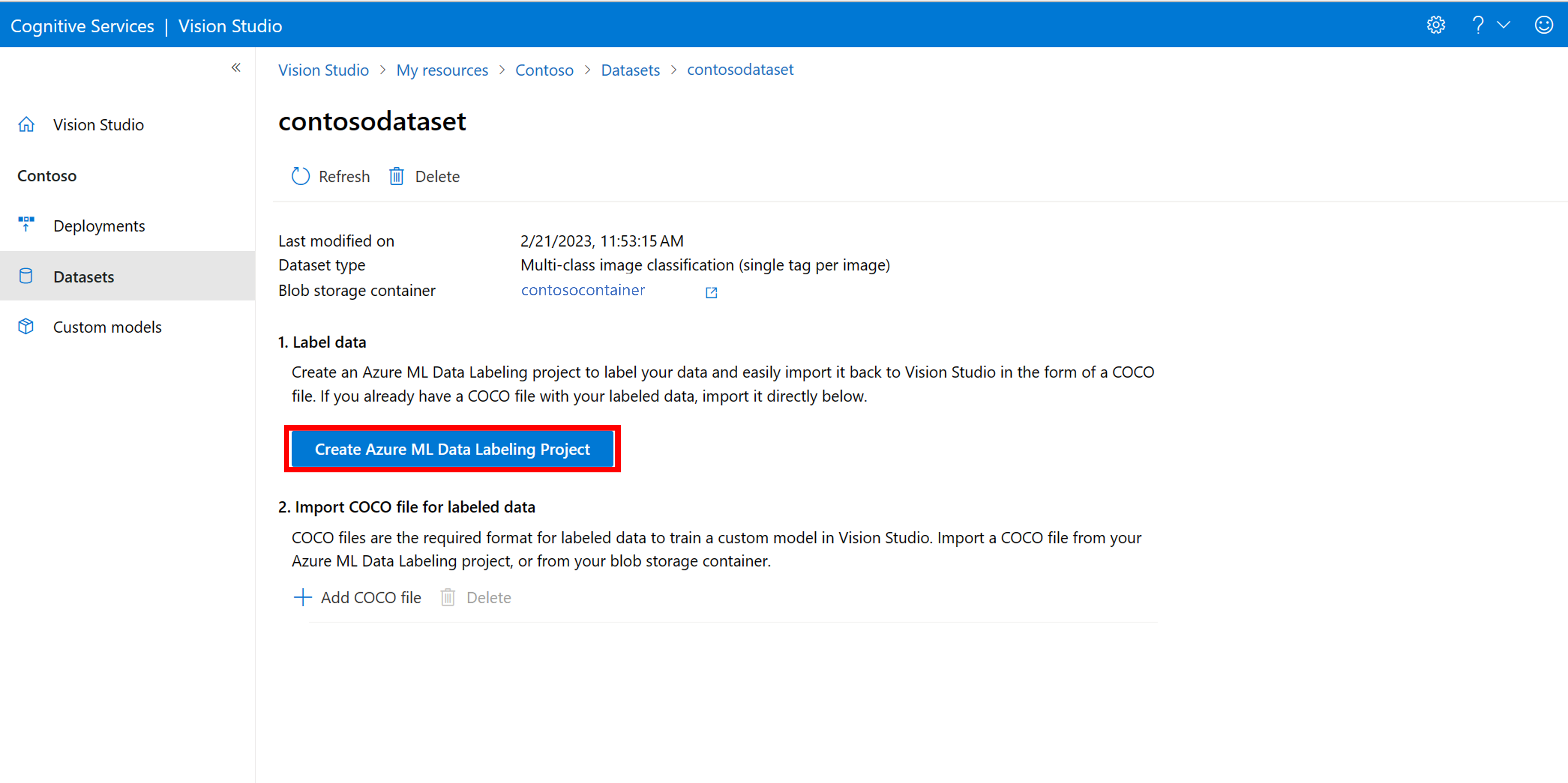
Nella pagina dei dettagli del set di dati, selezionare Aggiungi nuovo progetto di etichettatura dei dati. Denominarlo e selezionare Crea nuova area di lavoro. Verrà visualizzata una nuova scheda del portale di Azure dove è possibile creare il progetto di Azure Machine Learning.
Dopo aver creato il progetto di Azure Machine Learning, tornare alla scheda Vision Studio e selezionarlo in Area di lavoro. Il portale di Azure Machine Learning si apre in una nuova scheda del browser.
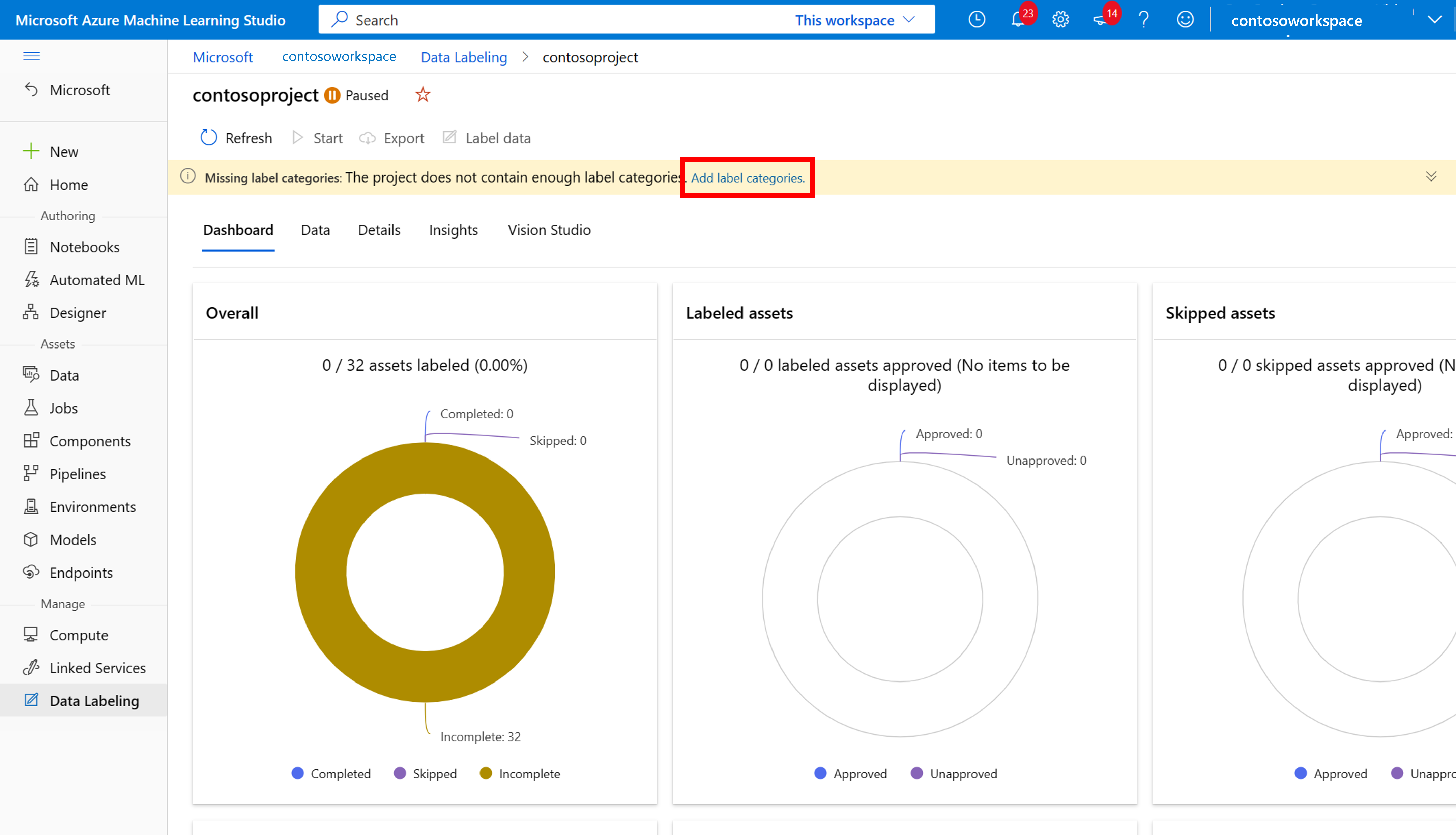
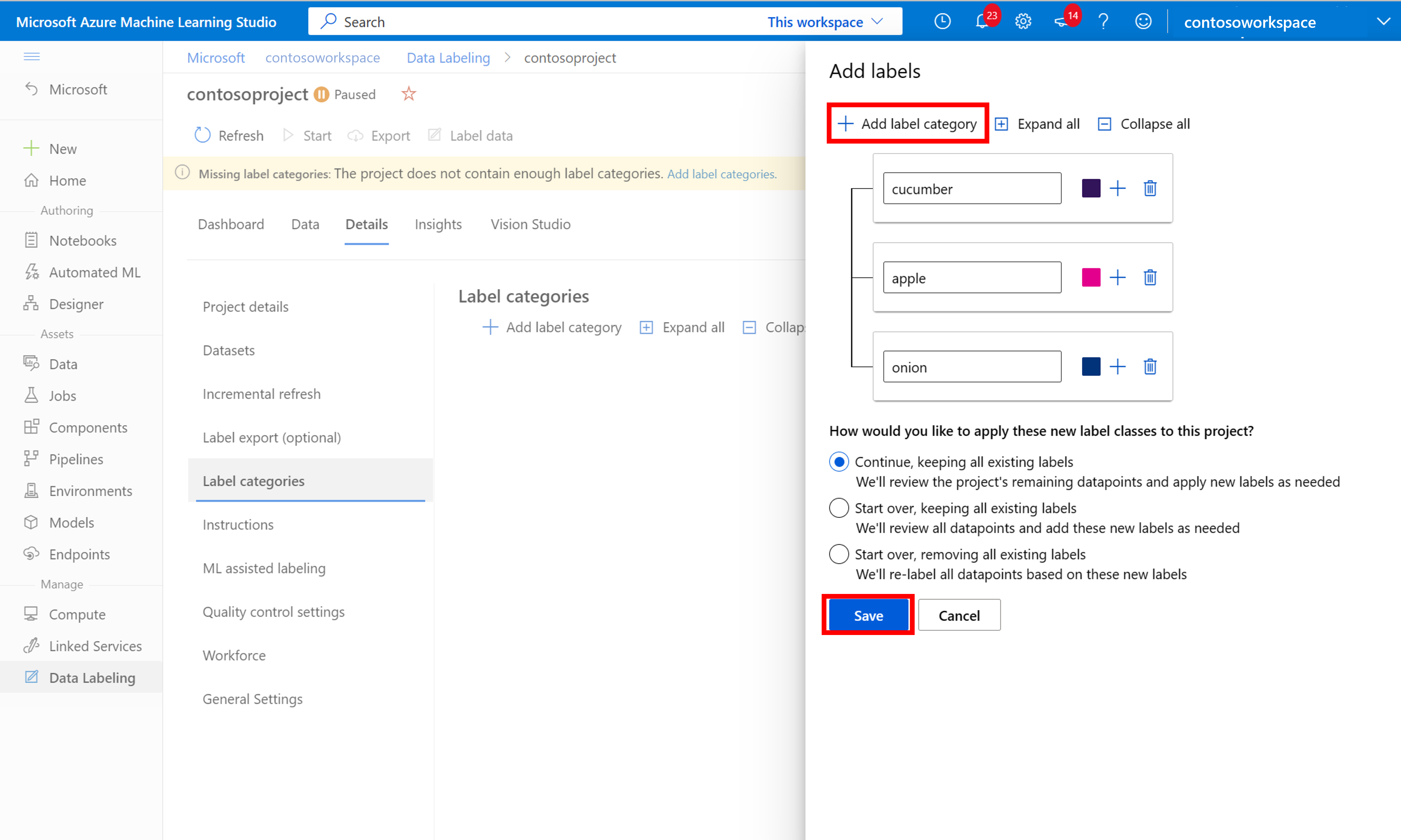
Creare etichette
Per avviare l'etichettatura, seguire le istruzioni della richiesta Aggiungi classi di etichette per aggiungere le classi di etichette.
Dopo aver aggiunto tutte le etichette di classe, salvarle, selezionare Avvia nel progetto e quindi selezionare Etichetta dati nella parte superiore.
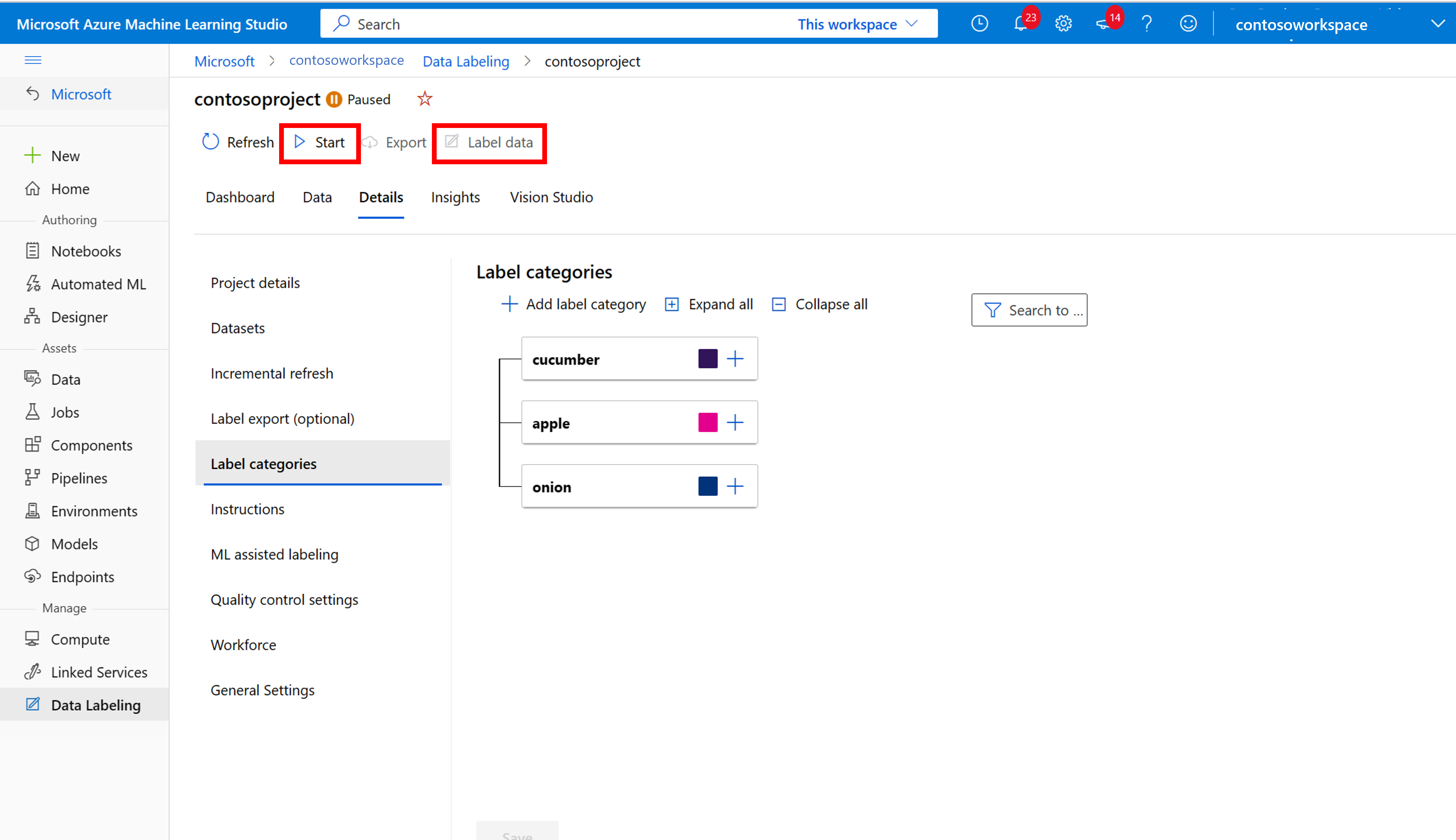
Etichettare manualmente i dati di training
Scegliere Avvia etichettatura e seguire le istruzioni delle richieste per etichettare tutte le immagini. Al termine, tornare alla scheda Vision Studio nel browser.
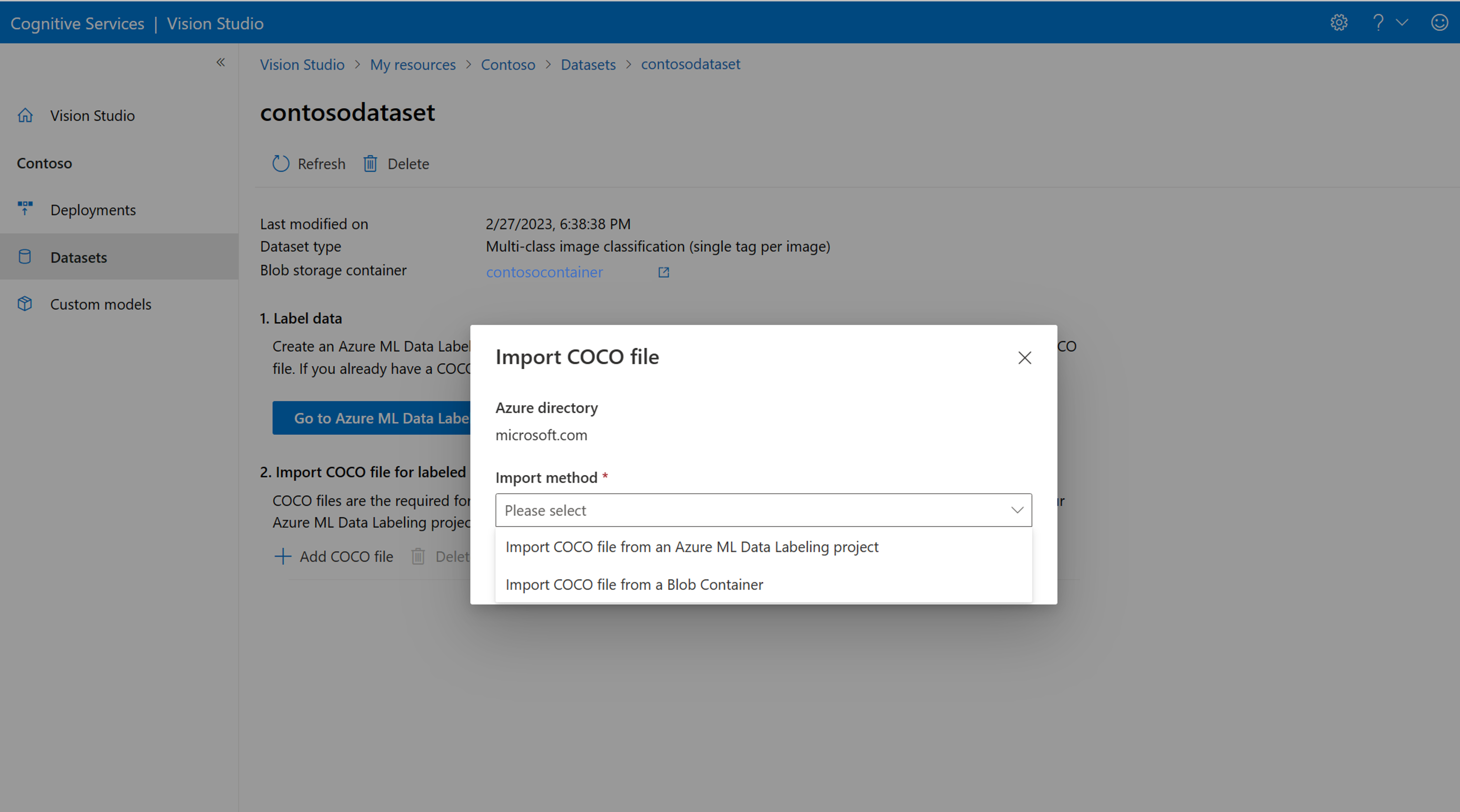
A questo punto, selezionare Aggiungi file COCO, quindi scegliere Importa file COCO da un progetto di etichettatura dei dati di Azure ML. I dati con etichetta vengono importati da Azure Machine Learning.
Il file COCO creato viene ora archiviato nel contenitore Archiviazione di Azure collegato a questo progetto. È ora possibile importarlo nel flusso di lavoro di personalizzazione del modello. selezionare l'ID nell'elenco a discesa. Una volta importato il file COCO nel set di dati, quest'ultimo può essere utilizzato per eseguire il training di un modello.
Nota
Se si vuole importare un file COCO pronto, passare alla scheda Set di dati e selezionare Aggiungi file COCO a questo set di dati. È possibile scegliere di aggiungere un file COCO specifico da un account di archiviazione BLOB o di importare dal progetto di etichettatura di Azure Machine Learning.
Attualmente, Microsoft sta risolvendo un problema che causa l'esito negativo dell'importazione di file COCO con set di dati di grandi dimensioni quando viene avviato in Vision Studio. Per eseguire il training con un set di dati di grandi dimensioni, è consigliabile, in alternativa, utilizzare l'API REST.
Informazioni sui file COCO
I file COCO sono file JSON con campi obbligatori specifici: "images", "annotations" e "categories". Un file COCO di esempio ha un aspetto simile al seguente:
Informazioni di riferimento sui campi del file COCO
Se si genera un file COCO partendo da zero, assicurarsi che tutti i campi obbligatori siano stati compilati con i dati corretti. Le tabelle seguenti descrivono tutti i campi presenti in un file COCO:
"immagini"
Chiave
Type
Description
Obbligatorio?
id
integer
ID immagine univoco, a partire da 1
Sì
width
integer
Larghezza dell'immagine in pixel
Sì
height
integer
Altezza dell'immagine in pixel
Sì
file_name
string
Nome univoco dell’immagine
Sì
absolute_url oppure coco_url
string
Percorso dell’immagine come URI assoluto in un BLOB in un contenitore BLOB. La risorsa Visione deve avere l'autorizzazione a leggere i file di annotazione e tutti i file di immagine cui si fa riferimento.
Sì
Il valore di absolute_url è reperibile nelle proprietà del contenitore BLOB:
"annotazioni"
Chiave
Type
Description
Obbligatorio?
id
integer
ID dell’annotazione
Sì
category_id
integer
ID della categoria definita nella sezione categories
Sì
image_id
integer
ID dell’immagine
Sì
area
integer
Valore di 'Width' x 'Height' (terzo e quarto valore di bbox)
No
bbox
list[float]
Coordinate relative del rettangolo delimitatore (da 0 a 1), nell'ordine 'Left', 'Top', 'Width', 'Height'
Sì
"categorie"
Chiave
Type
Description
Obbligatorio?
id
integer
ID univoco per ogni categoria (classe di etichetta). Devono essere presenti nella sezione annotations.
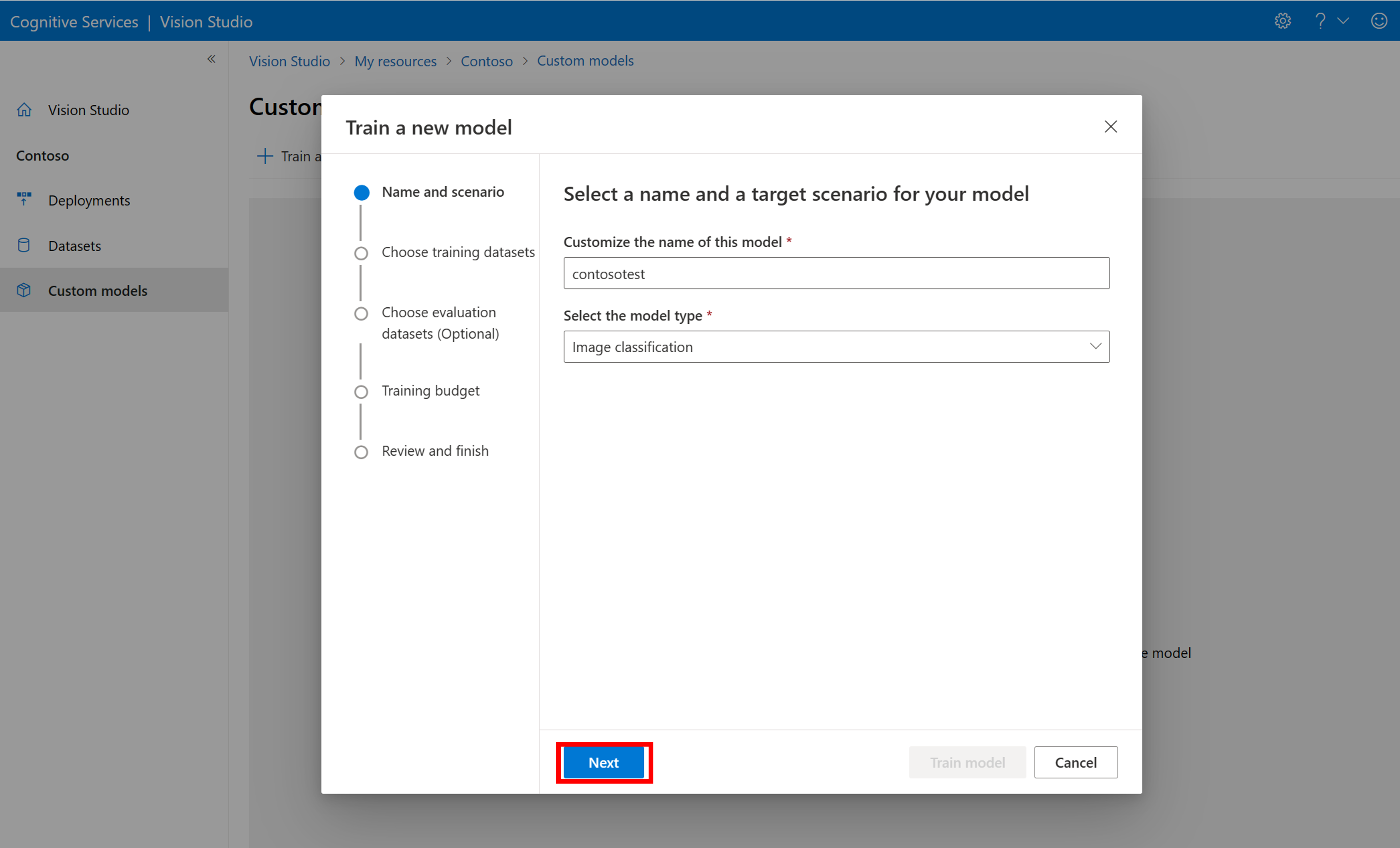
Per avviare il training di un modello con il file COCO, passare alla scheda Modelli personalizzati e selezionare Aggiungi nuovo modello. Immettere un nome per il modello e selezionare Image classification o Object detection come tipo di modello.
Selezionare il set di dati associato al file COCO contenente le informazioni sull'etichettatura.
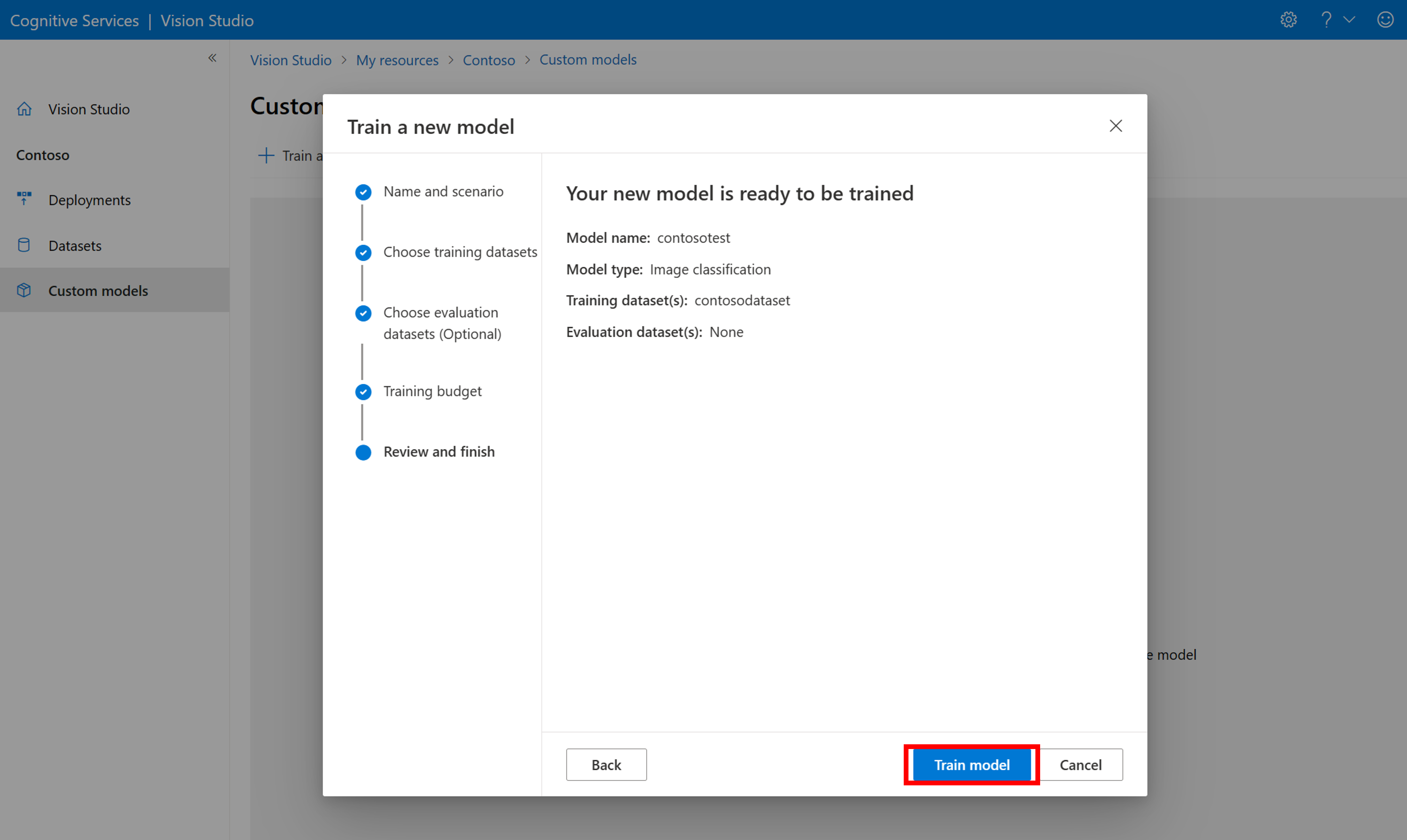
Quindi, selezionare un’allocazione di tempo ed eseguire il training del modello. Per esempi di piccole dimensioni, è possibile usare un budget 1 hour.
Il completamento del training potrebbe richiedere del tempo. I modelli di Image Analysis 4.0 possono essere precisi solo nel caso di set di dati di training di piccole dimensioni, tuttavia il training richiede più tempo rispetto al training dei modelli precedenti.
Valutare il modello sottoposto a training
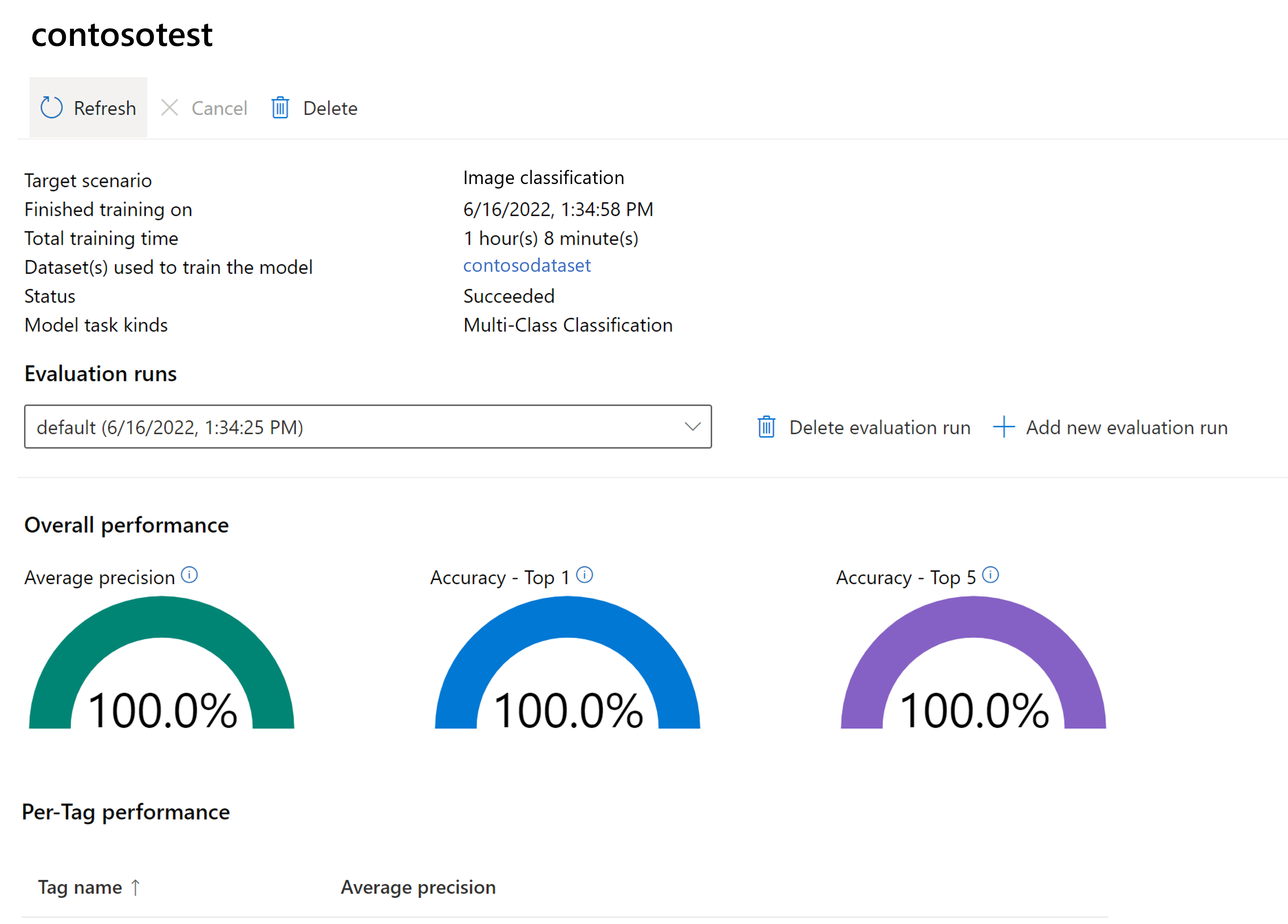
Al termine del training, è possibile visualizzare la valutazione delle prestazioni del modello. Sono utilizzate le metriche seguenti:
Classificazione immagini: precisione media, Accuratezza Top 1, Accuratezza Top 5
Rilevamento oggetti: precisione media @ 30, precisione media @ 50, precisione media @ 75
Se non viene fornito un set di valutazione durante il training del modello, le prestazioni riportate vengono stimate in base a una parte del set di training. Si consiglia vivamente di avvalersi di un set di dati di valutazione (con lo stesso processo descritto in precedenza) per ottenere una previsione attendibile delle prestazioni del modello.
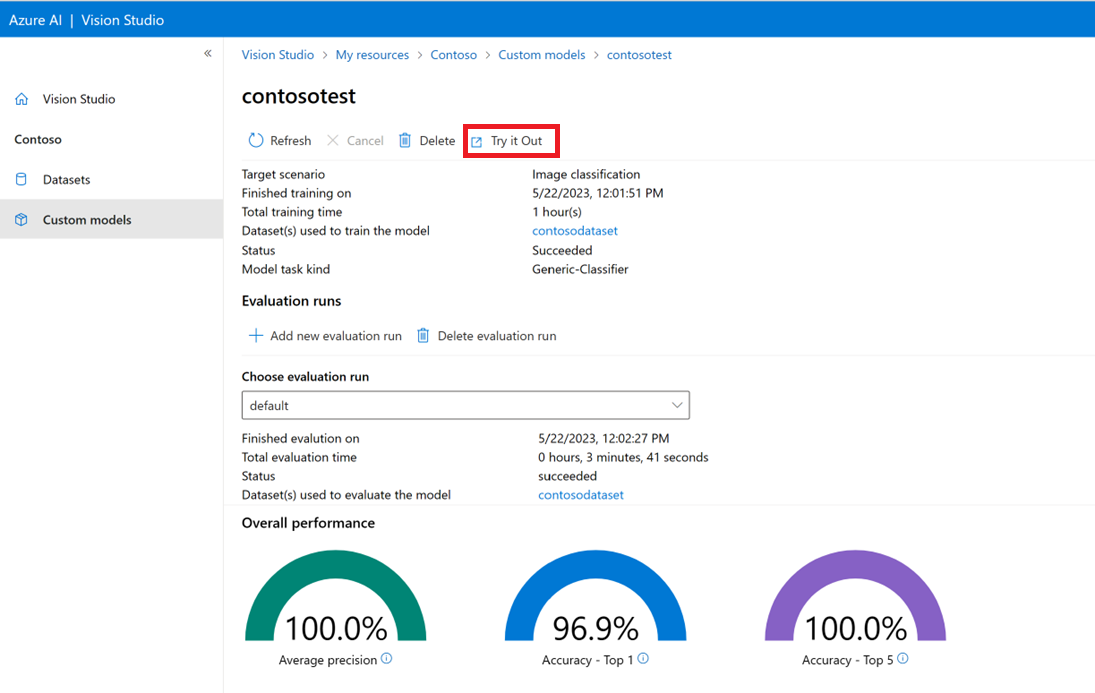
Testare il modello personalizzato in Vision Studio
Dopo aver creato un modello personalizzato, è possibile eseguire il test selezionando il pulsante Prova nella schermata di valutazione del modello.
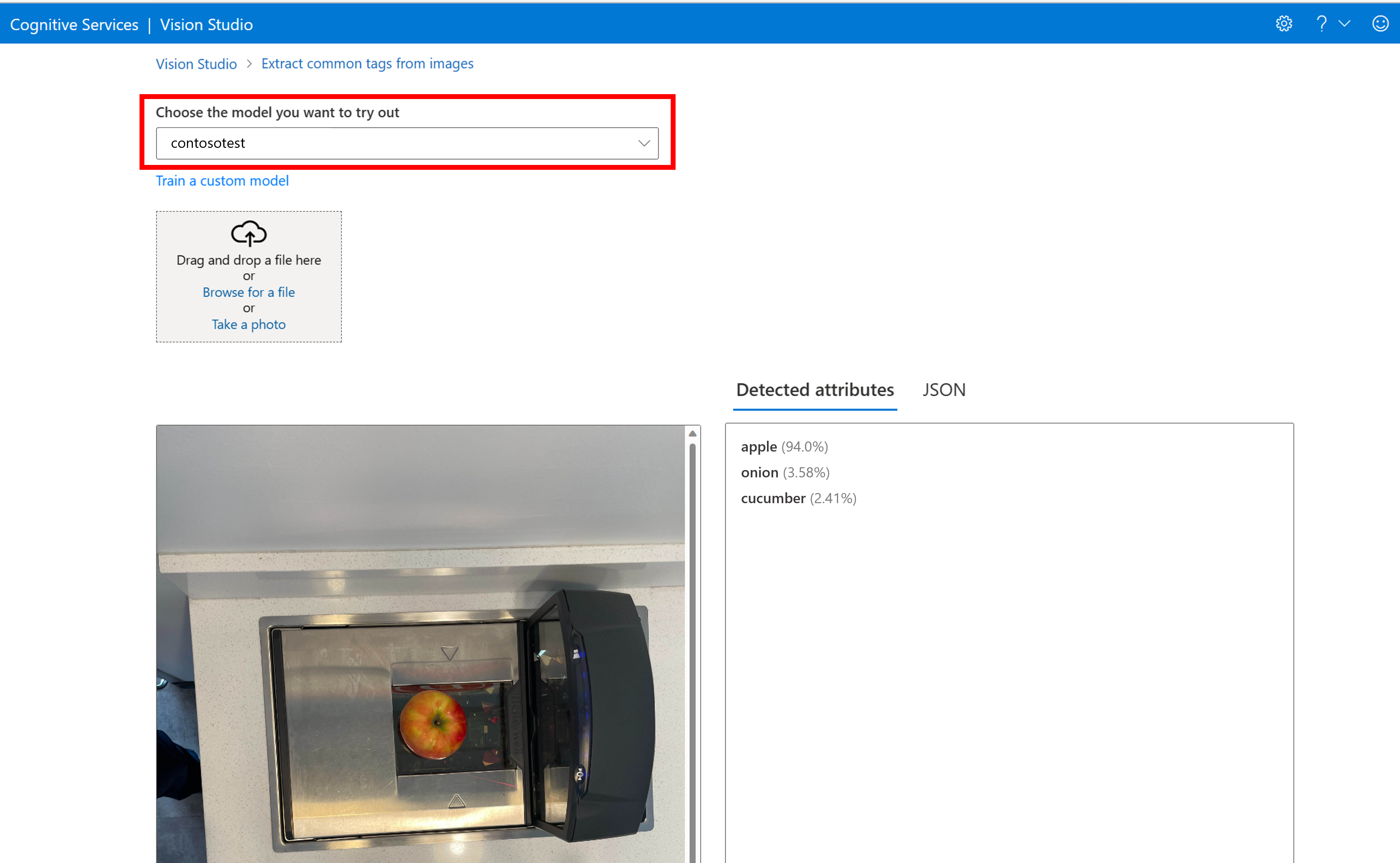
Verrà visualizzata la pagina Estrarre tag comuni dalle immagini. Scegliere il modello personalizzato dal menu a discesa e caricare un’immagine di test.
I risultati della previsione vengono visualizzati nella colonna destra.
Preparare i dati per eseguire il training
La prima cosa da fare è creare un file COCO dai dati di training. Vedere la specifica seguente.
Informazioni sui file COCO
I file COCO sono file JSON con campi obbligatori specifici: "images", "annotations" e "categories". Un file COCO di esempio ha un aspetto simile al seguente:
Informazioni di riferimento sui campi del file COCO
Se si genera un file COCO partendo da zero, assicurarsi che tutti i campi obbligatori siano stati compilati con i dati corretti. Le tabelle seguenti descrivono tutti i campi presenti in un file COCO:
"immagini"
Chiave
Type
Description
Obbligatorio?
id
integer
ID immagine univoco, a partire da 1
Sì
width
integer
Larghezza dell'immagine in pixel
Sì
height
integer
Altezza dell'immagine in pixel
Sì
file_name
string
Nome univoco dell’immagine
Sì
absolute_url oppure coco_url
string
Percorso dell’immagine come URI assoluto in un BLOB in un contenitore BLOB. La risorsa Visione deve avere l'autorizzazione a leggere i file di annotazione e tutti i file di immagine cui si fa riferimento.
Sì
Il valore di absolute_url è reperibile nelle proprietà del contenitore BLOB:
"annotazioni"
Chiave
Type
Description
Obbligatorio?
id
integer
ID dell’annotazione
Sì
category_id
integer
ID della categoria definita nella sezione categories
Sì
image_id
integer
ID dell’immagine
Sì
area
integer
Valore di 'Width' x 'Height' (terzo e quarto valore di bbox)
No
bbox
list[float]
Coordinate relative del rettangolo delimitatore (da 0 a 1), nell'ordine 'Left', 'Top', 'Width', 'Height'
Sì
"categorie"
Chiave
Type
Description
Obbligatorio?
id
integer
ID univoco per ogni categoria (classe di etichetta). Devono essere presenti nella sezione annotations.
Caricare il file COCO in un contenitore di archiviazione BLOB, idealmente quello che contiene le immagini per eseguire il training.
Caricare il set di dati di training
L’API datasets/<dataset-name> consente di creare un nuovo oggetto set di dati che fa riferimento ai dati di training. Apportare le modifiche seguenti al comando cURL:
Sostituire <endpoint> con l'endpoint di Visione di Azure AI.
Sostituire <dataset-name> con un nome per il set di dati.
Sostituire <subscription-key> con la chiave di Visione di Azure AI.
Nel corpo della richiesta impostare "annotationKind" su "imageClassification" o "imageObjectDetection", a seconda del progetto.
Nel corpo della richiesta impostare la "annotationFileUris" matrice su una matrice di stringhe che mostrano i percorsi URI dei file COCO nell'archivio BLOB.
L'API models/<model-name> consente di creare un nuovo modello personalizzato e di associarlo a un set di dati già esistente. Inoltre, avvia il processo di training. Apportare le modifiche seguenti al comando cURL:
Sostituire <endpoint> con l'endpoint di Visione di Azure AI.
Sostituire <model-name> con un nome per il modello.
Sostituire <subscription-key> con la chiave di Visione di Azure AI.
Nel corpo della richiesta impostare "trainingDatasetName" sul nome del set di dati usato nel passaggio precedente.
Nel corpo della richiesta impostare "modelKind" su "Generic-Classifier" o "Generic-Detector", a seconda del progetto.
Valutare le prestazioni del modello in un set di dati
L'API models/<model-name>/evaluations/<eval-name> valuta le prestazioni di un modello già esistente. Apportare le modifiche seguenti al comando cURL:
Sostituire <endpoint> con l'endpoint di Visione di Azure AI.
Sostituire <model-name> con il nome del modello.
Sostituire <eval-name> con un nome che possa identificare la valutazione in modo univoco.
Sostituire <subscription-key> con la chiave di Visione di Azure AI.
Nel corpo della richiesta impostare "testDatasetName" sul nome del set di dati che si desidera utilizzare per la valutazione. Se non si dispone di un set di dati dedicato, è possibile usare lo stesso set di dati usato per eseguire il training.
La chiamata API restituisce un oggetto JSON ModelPerformance, che elenca i punteggi del modello in diverse categorie. Sono utilizzate le metriche seguenti:
Classificazione immagini: precisione media, Accuratezza Top 1, Accuratezza Top 5
Rilevamento oggetti: precisione media @ 30, precisione media @ 50, precisione media @ 75
Testare il modello personalizzato su un’immagine
L'API imageanalysis:analyze esegue operazioni comuni di analisi delle immagini. Specificando alcuni parametri, questa API consente di eseguire query sul modello personalizzato anziché sui modelli predefiniti di Image Analysis. Apportare le modifiche seguenti al comando cURL:
Sostituire <endpoint> con l'endpoint di Visione di Azure AI.
Sostituire <model-name> con il nome del modello.
Sostituire <subscription-key> con la chiave di Visione di Azure AI.
Nel corpo della richiesta impostare "url" sull'URL di un'immagine remota sulla quale si desidera testare il modello.
La chiamata API restituisce un oggetto JSON ImageAnalysisResult, che contiene tutti i tag rilevati per un classificatore di immagini, o gli oggetti per il rilevamento oggetti, con i relativi punteggi di attendibilità.
Nella presente guida si è creato ed eseguito il training di un modello di classificazione immagini personalizzato, avvalendosi dell'analisi delle immagini. In seguito, sarà possibile apprendere maggiori informazioni sull'API Analizza immagine 4.0, per richiamare il modello personalizzato da un'applicazione tramite REST.
Informazioni su come usare il servizio Visione personalizzata di Azure AI per creare modelli di intelligenza artificiale personalizzati per rilevare oggetti o classificare immagini.
Il servizio Analisi immagini usa modelli di intelligenza artificiale con training preliminare per estrarre molte funzionalità visive diverse dalle immagini.
Gestire l'inserimento e la preparazione dei dati, il training e la distribuzione di modelli e il monitoraggio delle soluzioni di apprendimento automatico con Python, Azure Machine Learning e MLflow.