Guida introduttiva: Classificazione personalizzata del testo
Usare questo articolo per iniziare a creare un progetto di classificazione personalizzata del testo in cui eseguire il training di modelli personalizzati per la classificazione del testo. Un modello è un software di intelligenza artificiale sottoposto a training per eseguire una determinata attività. Per questo sistema, i modelli classificano il testo e vengono sottoposti a training apprendendo dai dati contrassegnati.
La classificazione personalizzata del testo supporta due tipi di progetti:
- Classificazione con etichetta singola: è possibile assegnare una singola classe per ogni documento nel set di dati. Ad esempio, la trama di un film può essere classificata solo come "Romanticismo" o "Commedia".
- Classificazione multietichetta: è possibile assegnare più classi per ogni documento nel set di dati. Ad esempio, la trama di un film può essere classificata come “Commedia” o "Romanticismo" e "Commedia".
In questa guida introduttiva è possibile usare i set di dati di esempio forniti per creare una classificazione multietichetta in cui è possibile classificare gli script di film in una o più categorie oppure usare un set di dati di classificazione con etichetta singola in cui è possibile classificare abstract di documenti scientifici in uno dei domini definiti.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito.
Creare una nuova risorsa di Lingua di Azure AI e un account di archiviazione di Azure
Per poter usare la classificazione personalizzata del testo, è necessario creare una risorsa di Lingua di Azure AI che fornisca le credenziali necessarie per creare un progetto e avviare il training di un modello. È anche necessario un account di archiviazione di Azure, in cui caricare il set di dati che verrà usato per compilare il modello.
Importante
Per iniziare rapidamente, è preferibile creare una nuova risorsa di Lingua di Azure AI seguendo la procedura descritta in questo articolo. La procedura descritta in questo articolo consentirà di creare la risorsa Lingua e l'account di archiviazione contemporaneamente, in quanto questa operazione sarebbe più complessa se venisse eseguita in un secondo momento.
Se si dispone di una risorsa preesistente da usare, sarà necessario connetterla all'account di archiviazione.
Creare una nuova risorsa dal portale di Azure
Accedere al portale di Azure per creare una nuova risorsa di Lingua di Azure AI.
Nella finestra visualizzata, selezionare Classificazione personalizzata del testo e Riconoscimento entità denominata personalizzata dalle funzionalità personalizzate. Selezionare Continua per creare la risorsa nella parte inferiore dello schermo.
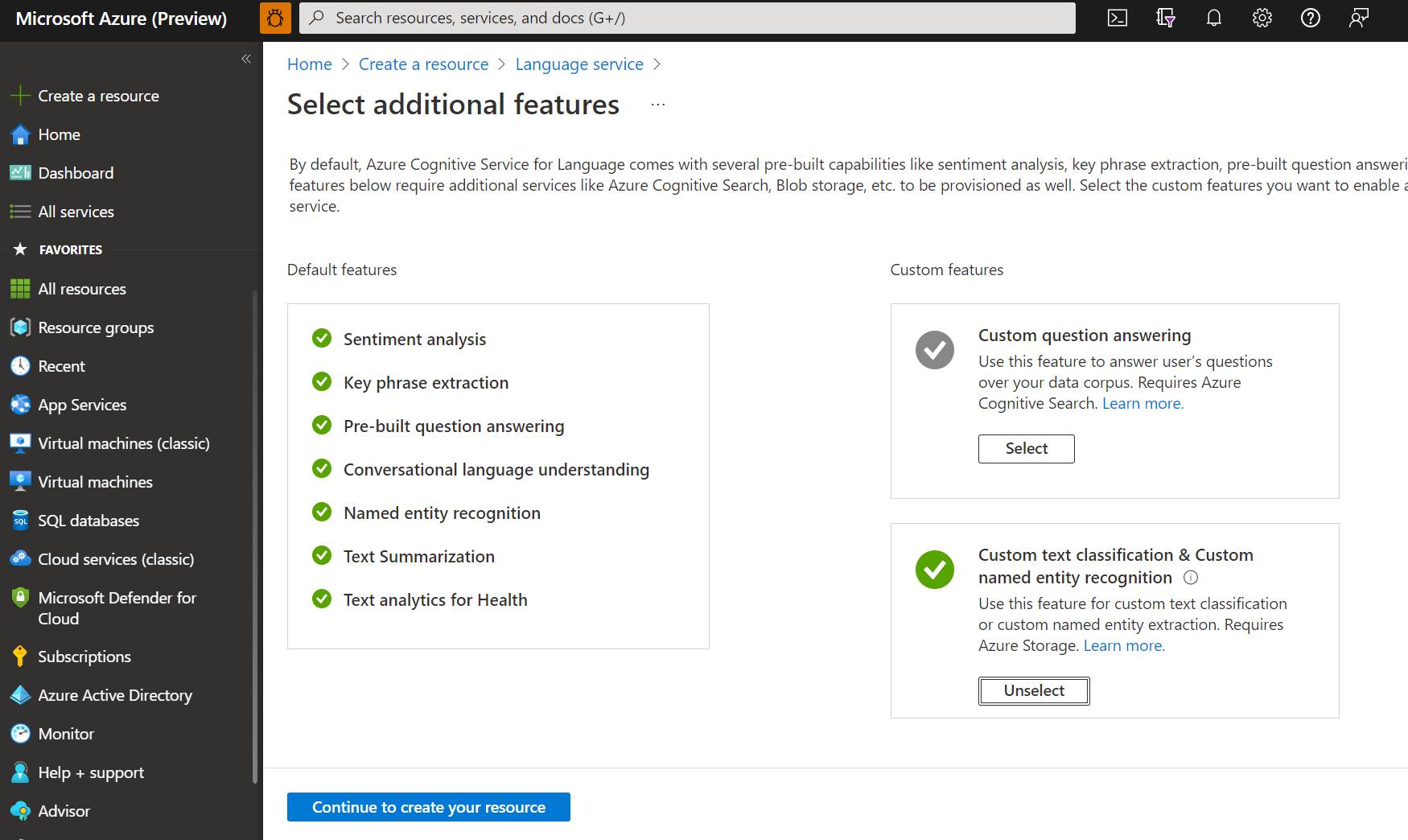
Creare una risorsa linguistica con i dettagli seguenti.
Nome Valore obbligatorio Abbonamento La sottoscrizione di Azure. Gruppo di risorse Un gruppo di risorse di Azure che conterrà la risorsa. È possibile usarne uno esistente o crearne uno nuovo. Area Una delle aree supportate. Ad esempio: “Stati Uniti occidentali 2”. Nome Un nome per la risorsa. Piano tariffario Uno dei piani tariffari supportati. Per provare il servizio, è possibile usare il livello gratuito (F0). Se viene visualizzato un messaggio che indica che “l'account di accesso non è un proprietario del gruppo di risorse dell'account di archiviazione selezionato”, è necessario assegnare all'account un ruolo di proprietario nel gruppo di risorse per poter creare una risorsa linguistica. Per assistenza contattare il proprietario della sottoscrizione di Azure.
È possibile determinare il proprietario della sottoscrizione di Azure eseguendo una ricerca nel gruppo di risorse e seguendo il collegamento alla sottoscrizione associata. Quindi:
- Selezionare la scheda Controllo di accesso (IAM)
- Selezionare Assegnazioni di ruolo
- Filtrare in base a Ruolo:Proprietario.
Nella sezione Classificazione personalizzata del testo e Riconoscimento entità denominata personalizzata, selezionare un account di archiviazione esistente o scegliere Nuovo account di archiviazione. Questi valori consentono di iniziare senza usare necessariamente i valori dell'account di archiviazione che verranno usati in ambienti di produzione. Per evitare la latenza durante la creazione del progetto, connettersi agli account di archiviazione nella stessa area della risorsa linguistica.
Valore dell'account di archiviazione Valore consigliato Nome account di archiviazione Qualsiasi nome Storage account type LRS Standard Accertarsi che sia selezionata l’opzione Avviso intelligenza artificiale responsabile. Selezionare Rivedi e crea nella parte inferiore della pagina.

Caricare dati di esempio nel contenitore BLOB
Dopo aver creato un account di archiviazione di Azure e averlo connesso alla risorsa linguistica, sarà necessario caricare i documenti dal set di dati di esempio nella directory radice del contenitore. Questi documenti verranno usati successivamente per il training del modello.
Scaricare il set di dati di esempio per i progetti di classificazione multietichetta.
Aprire il file .zip ed estrarre la cartella contenente i documenti.
Il set di dati di esempio fornito contiene circa 200 documenti, ognuno dei quali è un riepilogo per un film. Ogni documento appartiene a una o più classi seguenti:
- "Mystery"
- "Drama"
- "Thriller"
- "Comedy"
- "Action"
Nel portale di Azure passare all'account di archiviazione creato e selezionarlo. A tal fine, fare clic su Account di archiviazione e digitare il nome dell'account di archiviazione in Filtro per qualunque campo.
Se il gruppo di risorse non viene visualizzato, accertarsi che il filtro Sottoscrizione uguale a sia impostato su Tutti.
Nell'account di archiviazione selezionare Contenitori nel menu a sinistra, sotto Archiviazione dati. Nella schermata visualizzata selezionare + Contenitore. Assegnare al contenitore il nome example-data e lasciare il livello di accesso pubblico predefinito.
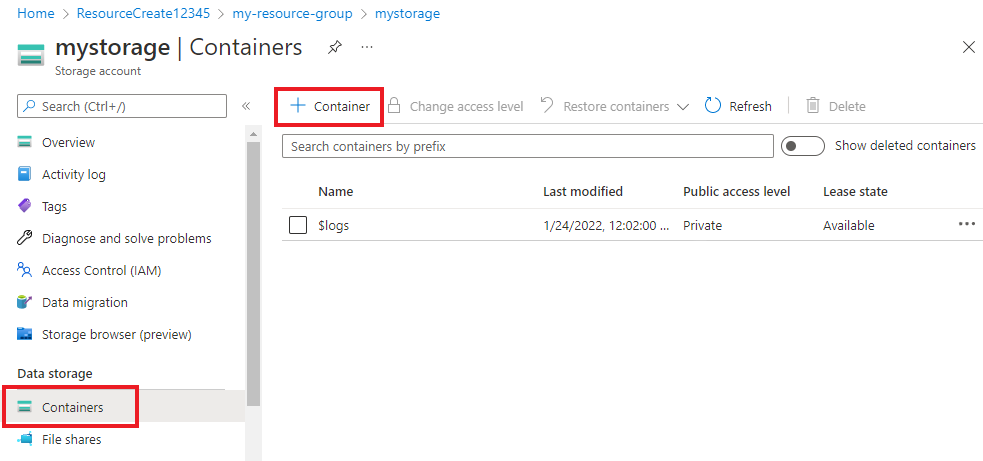
Dopo aver creato il contenitore, selezionarlo. Selezionare quindi il pulsante Carica per selezionare i file
.txte.jsonscaricati in precedenza.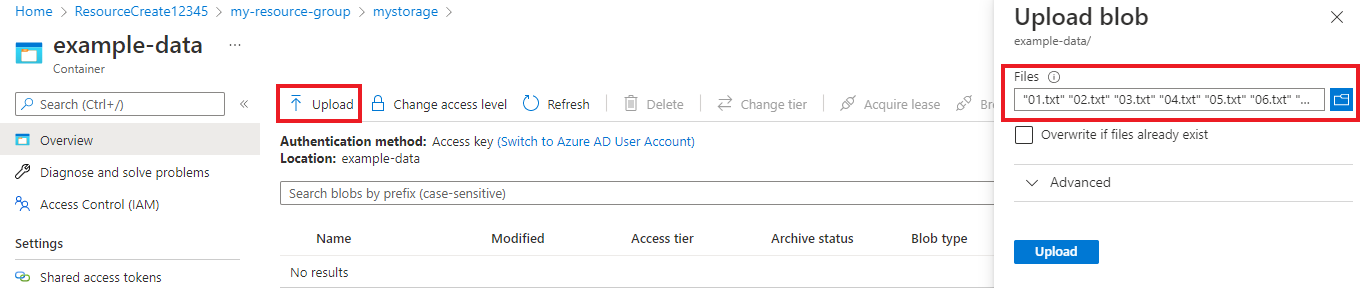


Creare un progetto di classificazione personalizzata del testo
Dopo aver configurato la risorsa e il contenitore di archiviazione, creare un nuovo progetto di classificazione personalizzata del testo. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa linguistica usata.
Accedere a Language Studio. Verrà visualizzata una finestra che consente di selezionare la sottoscrizione e la risorsa linguistica. Selezionare la risorsa linguistica.
Nella sezione Classifica testo di Language Studio, selezionare Classificazione personalizzata del testo.
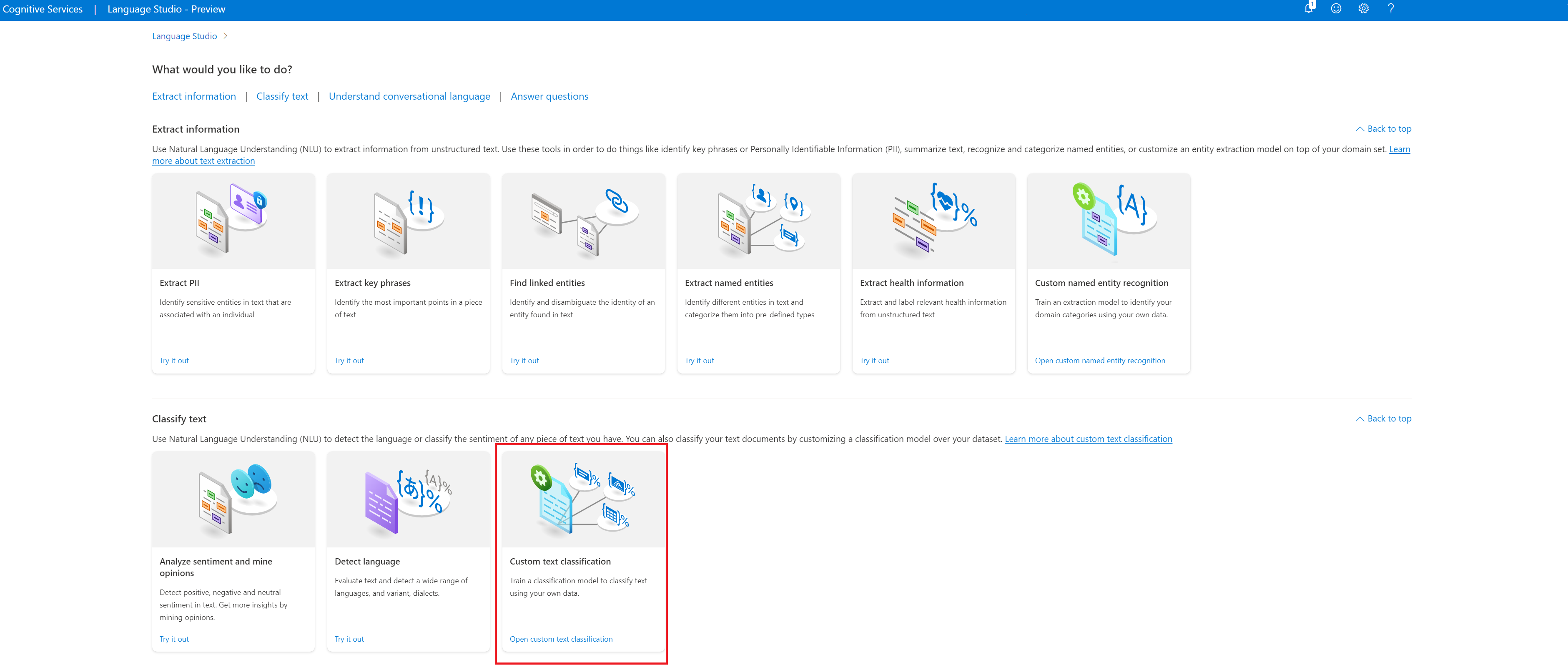
Selezionare Crea nuovo progetto dal menu in alto nella pagina dei progetti. La creazione di un progetto consentirà di etichettare i dati, eseguire il training, valutare, migliorare e distribuire i modelli.
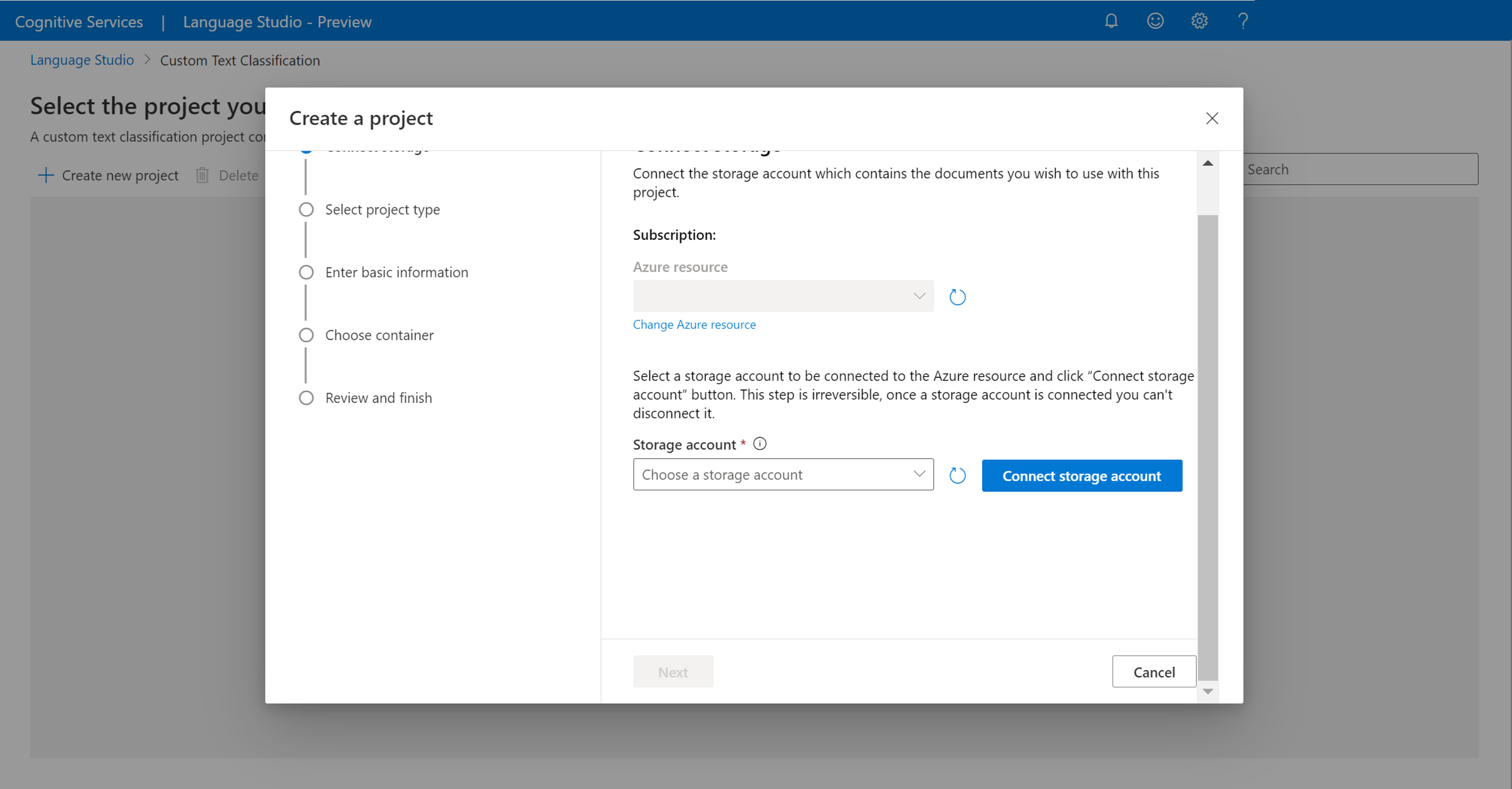
Dopo aver fatto clic su Crea nuovo progetto, verrà visualizzata una finestra che consente di connettere il proprio account di archiviazione. Se è già stato connesso un account di archiviazione, verrà visualizzato l'account di archiviazione connesso. In caso contrario, scegliere l'account di archiviazione dall'elenco a discesa visualizzato e selezionare Connetti account di archiviazione. Verranno impostati i ruoli necessari per l'account di archiviazione. Questo passaggio potrebbe restituire un errore se all’utente non è assegnato il ruolo di proprietario nell'account di archiviazione.
Nota
- Questo passaggio deve essere eseguito una sola volta per ogni nuova risorsa linguistica usata.
- Questo processo è irreversibile, per cui se si connette un account di archiviazione a una risorsa linguistica, non sarà possibile disconnetterlo in un secondo momento.
- È possibile connettere una risorsa linguistica a un solo account di archiviazione.
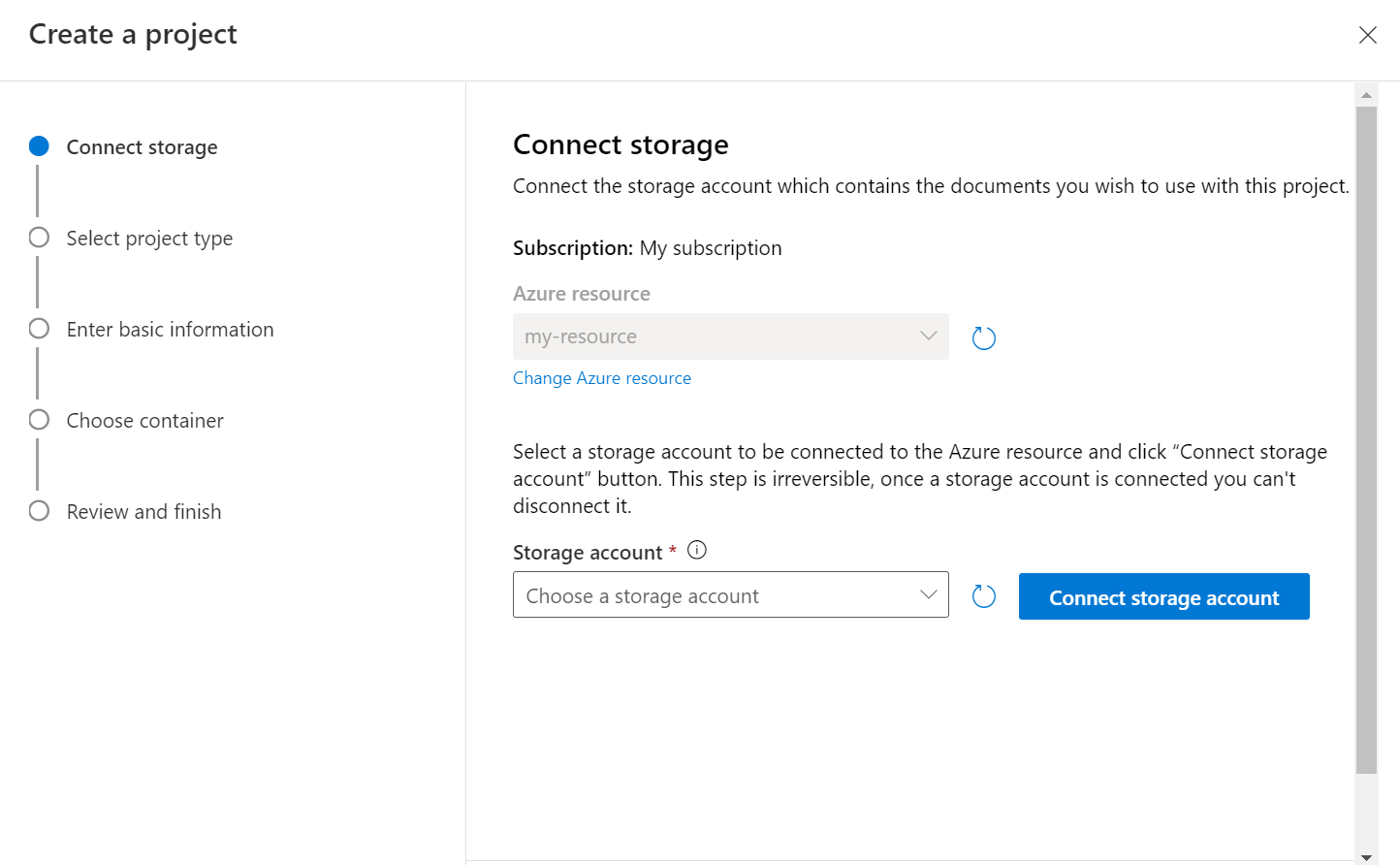
Selezionare il tipo di progetto. È possibile creare un progetto di classificazione multietichetta in cui ogni documento può appartenere a una o più classi o a un progetto di classificazione con etichetta singola in cui ogni documento può appartenere a una sola classe. Il tipo selezionato non potrà essere modificato successivamente. Altre informazioni sui tipi di progetto
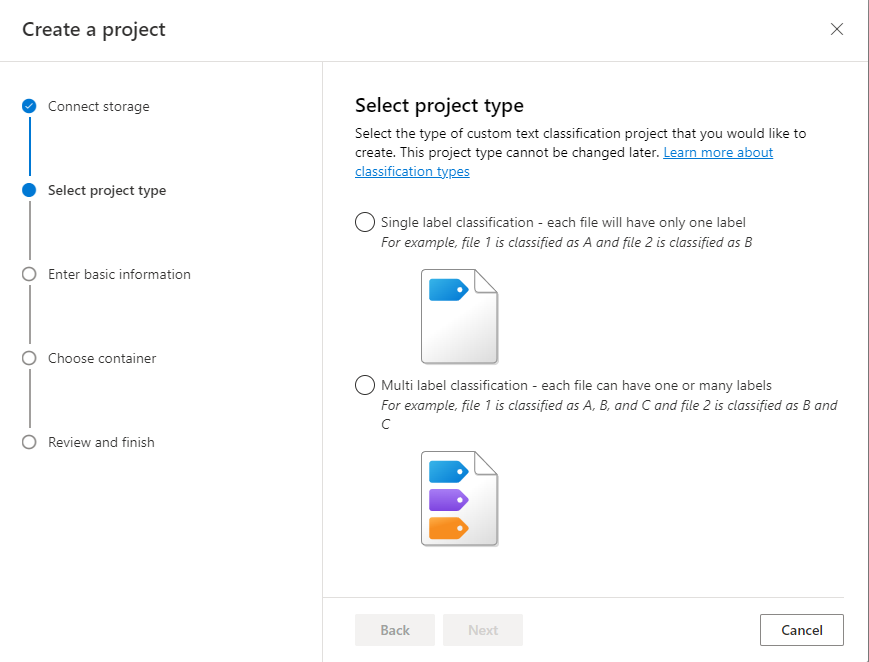
Immettere le informazioni sul progetto, inclusi un nome, una descrizione e la lingua dei documenti nel progetto. Se si usa il set di dati di esempio, selezionare Inglese. Non sarà possibile modificare il nome del progetto in un secondo momento. Selezionare Avanti.
Suggerimento
Il set di dati non deve essere tutto nella stessa lingua. È possibile avere più documenti, ognuno con diverse lingue supportate. Se il set di dati contiene documenti in lingue diverse o se si prevede testo in lingue diverse durante il runtime, selezionare l’opzione Abilita set di dati multilingue quando si immettono le informazioni di base per il progetto. Questa opzione può essere abilitata in un secondo momento dalla pagina Impostazioni progetto.
Selezionare il contenitore in cui è stato caricato il set di dati.
Nota
Se i dati sono già stati etichettati, accertarsi che rispettino il formato supportato e selezionare Sì, i documenti sono già etichettati e il file di etichette JSON è formattato, quindi selezionare il file di etichette dal menu a discesa seguente.
Se si usa uno dei set di dati di esempio, usare il file JSON
webOfScience_labelsFileomovieLabelsincluso. Quindi seleziona Avanti.Esaminare i dati immessi e selezionare Crea progetto.




Eseguire il training del modello
In genere, dopo aver creato un progetto, è possibile procedere e iniziare ad aggiungere tag ai documenti inclusi nel contenitore connesso al progetto. Per questa guida introduttiva è stato importato un set di dati con tag di esempio e il progetto è stato inizializzato con il file di tag JSON di esempio.
Per avviare il training di un modello da Language Studio:
Selezionare Processi di training dal menu a sinistra.
Selezionare Avvia un processo di training dal menu in alto.
Selezionare Esegui il training di un nuovo modello e digitare il nome del modello nella casella di testo. Si può anche sovrascrivere un modello esistente selezionando questa opzione e scegliendo il modello da sovrascrivere dal menu a discesa. La sovrascrittura di un modello sottoposto a training è irreversibile, ma non influisce sui modelli distribuiti fino a quando non si distribuisce il nuovo modello.
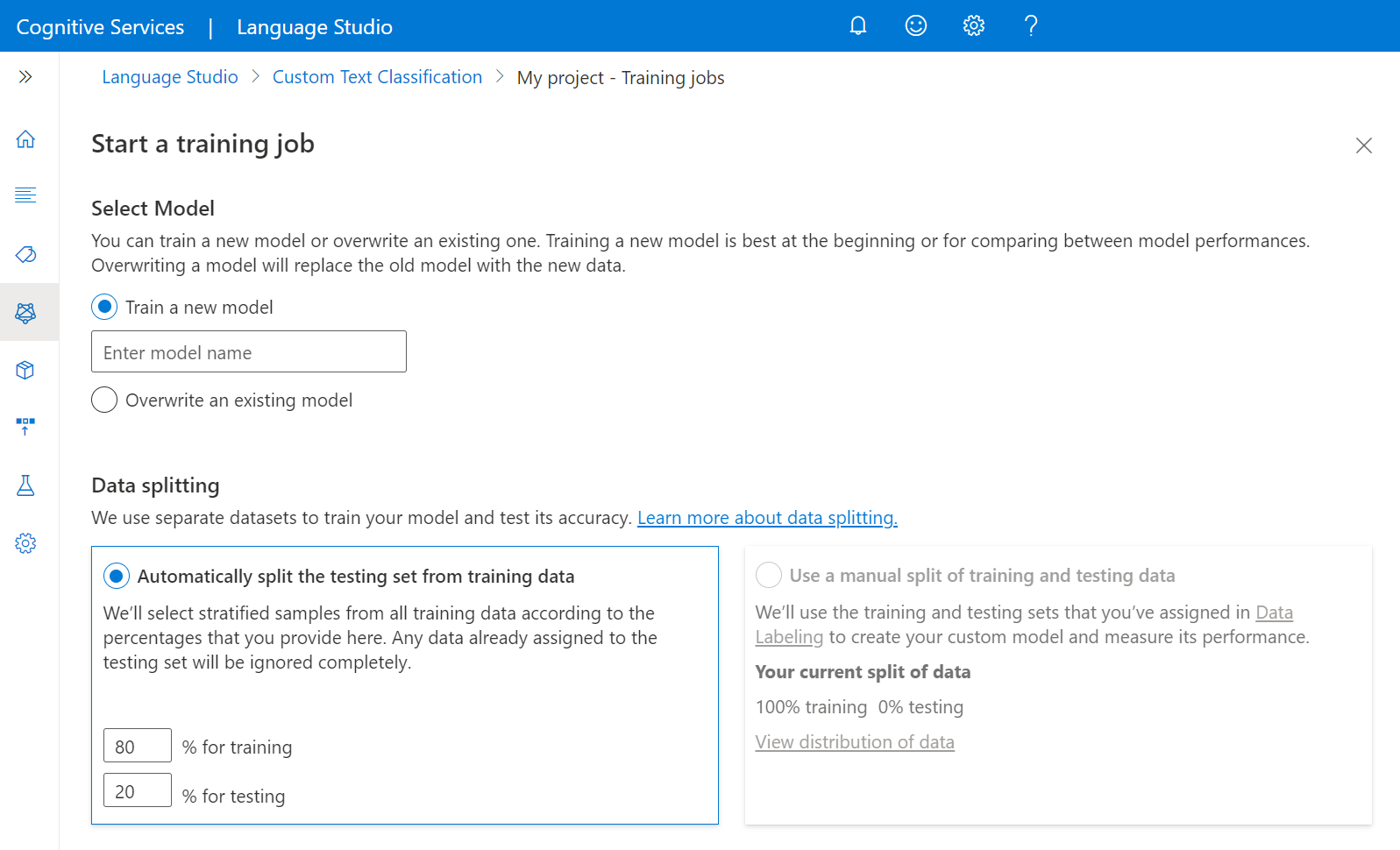
Selezionare il metodo di divisione dei dati. È possibile scegliere Divisione automatica del set di test dai dati di training in modo che il sistema divida i dati etichettati tra il set di training e il set di test in base alle percentuali scelte dall’utente. In alternativa, è possibile scegliere l’opzione Usa una divisione manuale dei dati di training e di test, che è abilitata solo se sono stati aggiunti documenti al set di test durante l’etichettatura dei dati. Per altre informazioni sulla divisione dei dati, vedere Come eseguire il training di un modello.
Selezionare il pulsante Esegui il training.
Se si seleziona l'ID del processo di training dall'elenco, viene visualizzato un riquadro laterale in cui è possibile controllare lo stato di avanzamento del training, lo stato del processo e altri dettagli relativi a questo processo.
Nota
- Solo i processi di training completati correttamente genereranno modelli.
- L’esecuzione del training del modello può richiedere da qualche minuto a diverse ore, in base alle dimensioni dei dati etichettati.
- È possibile eseguire un solo processo di training alla volta. Non è possibile avviare altri processi di training nello stesso progetto fino al completamento del processo in esecuzione.

Distribuire il modello
In genere, dopo il training di un modello, è opportuno rivedere i relativi dettagli di valutazione e apportare miglioramenti in base alla necessità. In questa guida introduttiva, il modello verrà solo distribuito e reso disponibile per una prova in Language Studio; è possibile anche richiamare l'API di stima.
Per distribuire un modello all’interno di Studio di linguaggio:
Selezionare Distribuzione di un modello nel menu a sinistra.
Selezionare Aggiungi distribuzione per avviare un nuovo processo di distribuzione.
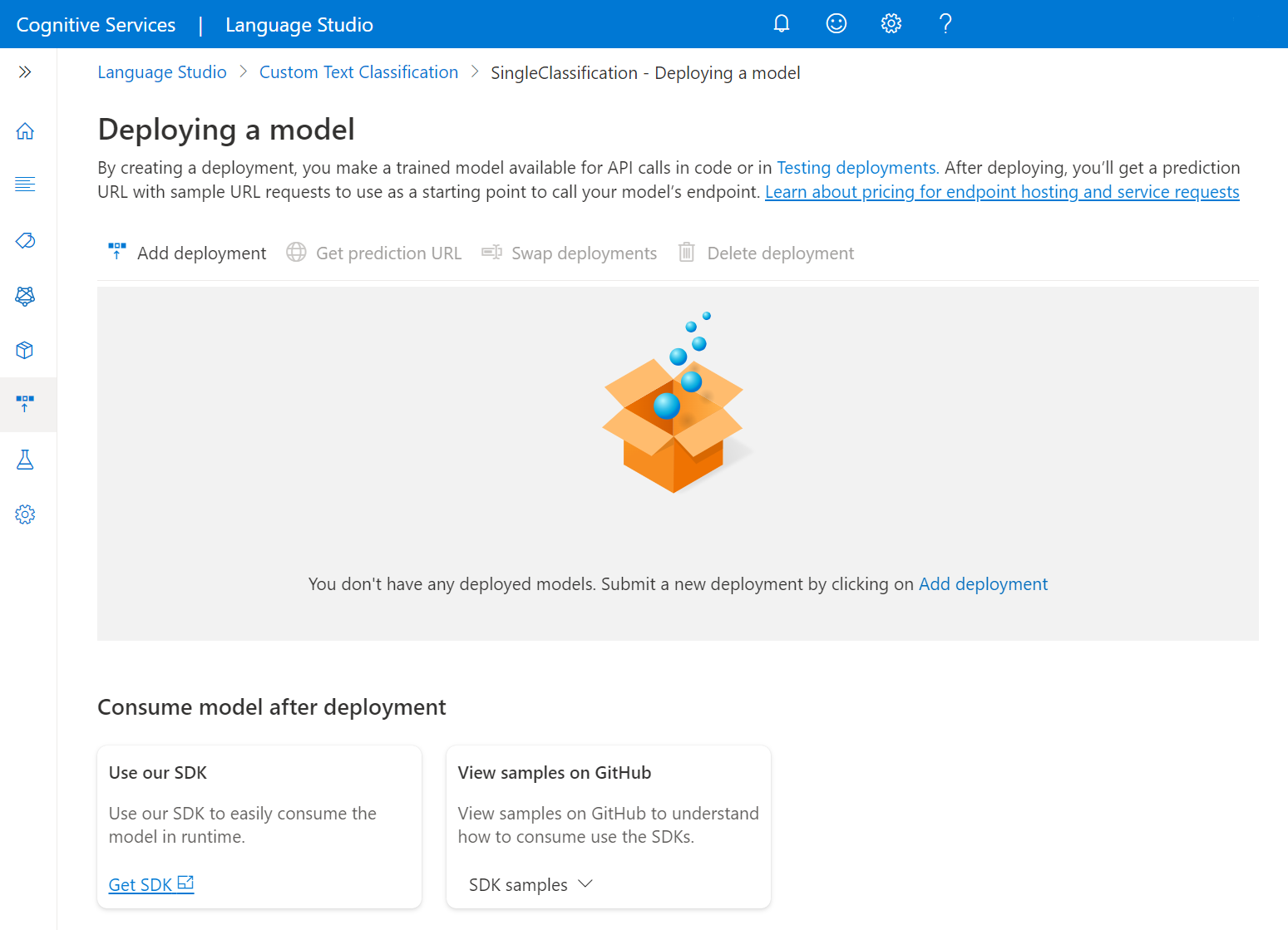
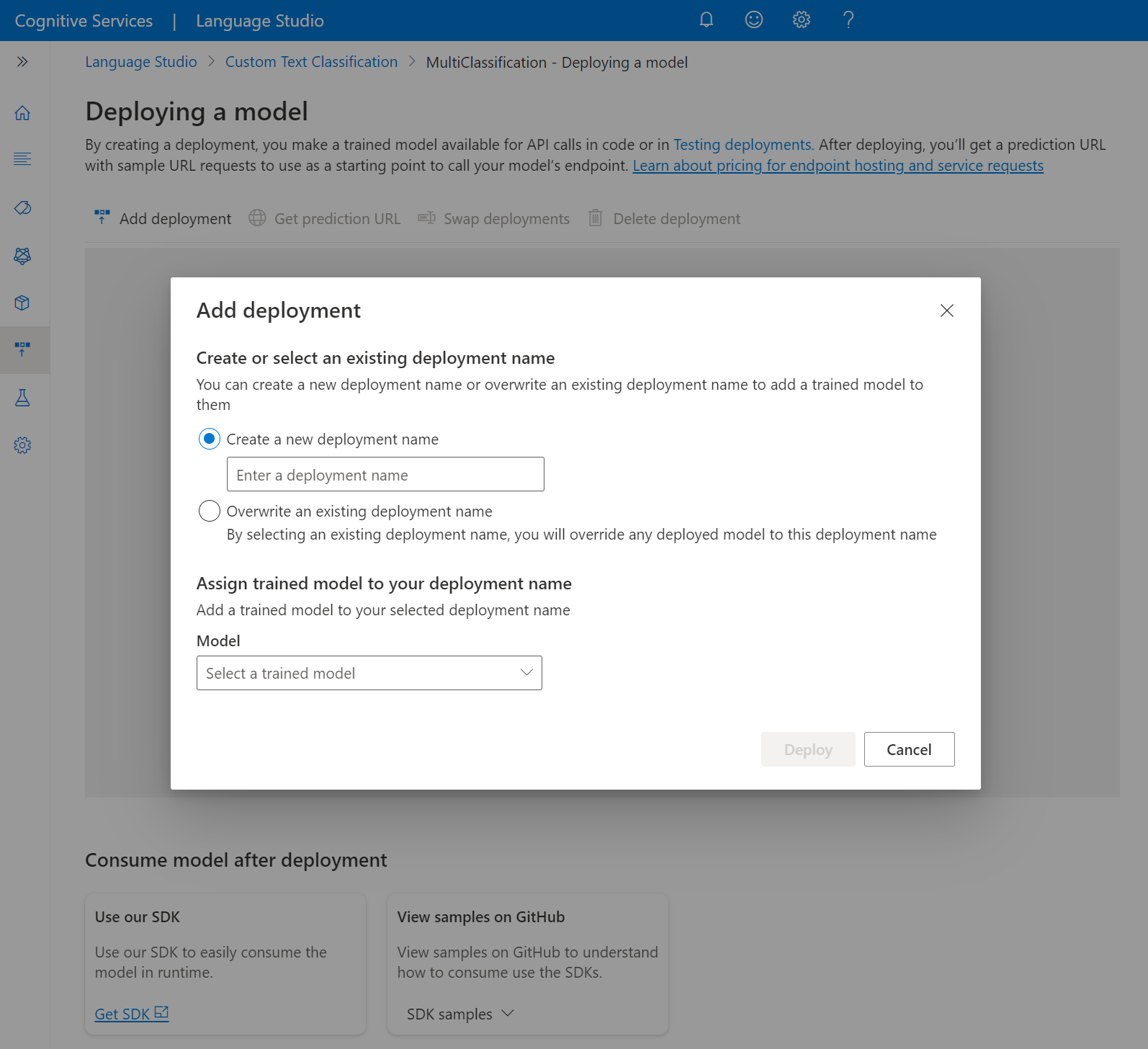
Selezionare Crea nuova distribuzione per creare una nuova distribuzione e assegnare un modello sottoposto a training dall'elenco a discesa seguente. È possibile anche sovrascrivere una distribuzione esistente selezionando questa opzione e scegliendo il modello sottoposto a training da assegnare dall'elenco a discesa seguente.
Nota
La sovrascrittura di una distribuzione esistente non richiede modifiche alla chiamata API di previsione, ma i risultati ottenuti saranno basati sul modello appena assegnato.
Selezionare Distribuisci per avviare il processo di distribuzione.
Al termine della distribuzione verrà visualizzata una data di scadenza. La scadenza della distribuzione indica quando il modello non potrà essere usato per la stima, ossia generalmente dodici mesi dopo la scadenza di una configurazione di training.


Testare il modello
Dopo aver distribuito il modello, è possibile iniziare a usarlo per classificare il testo tramite l'API di stima. In questa guida introduttiva verrà usato Language Studio per inviare l'attività di classificazione personalizzata del testo e visualizzare i risultati. Nel set di dati di esempio scaricato in precedenza è possibile trovare alcuni documenti di test che è possibile usare in questo passaggio.
Per testare i modelli distribuiti in Language Studio:
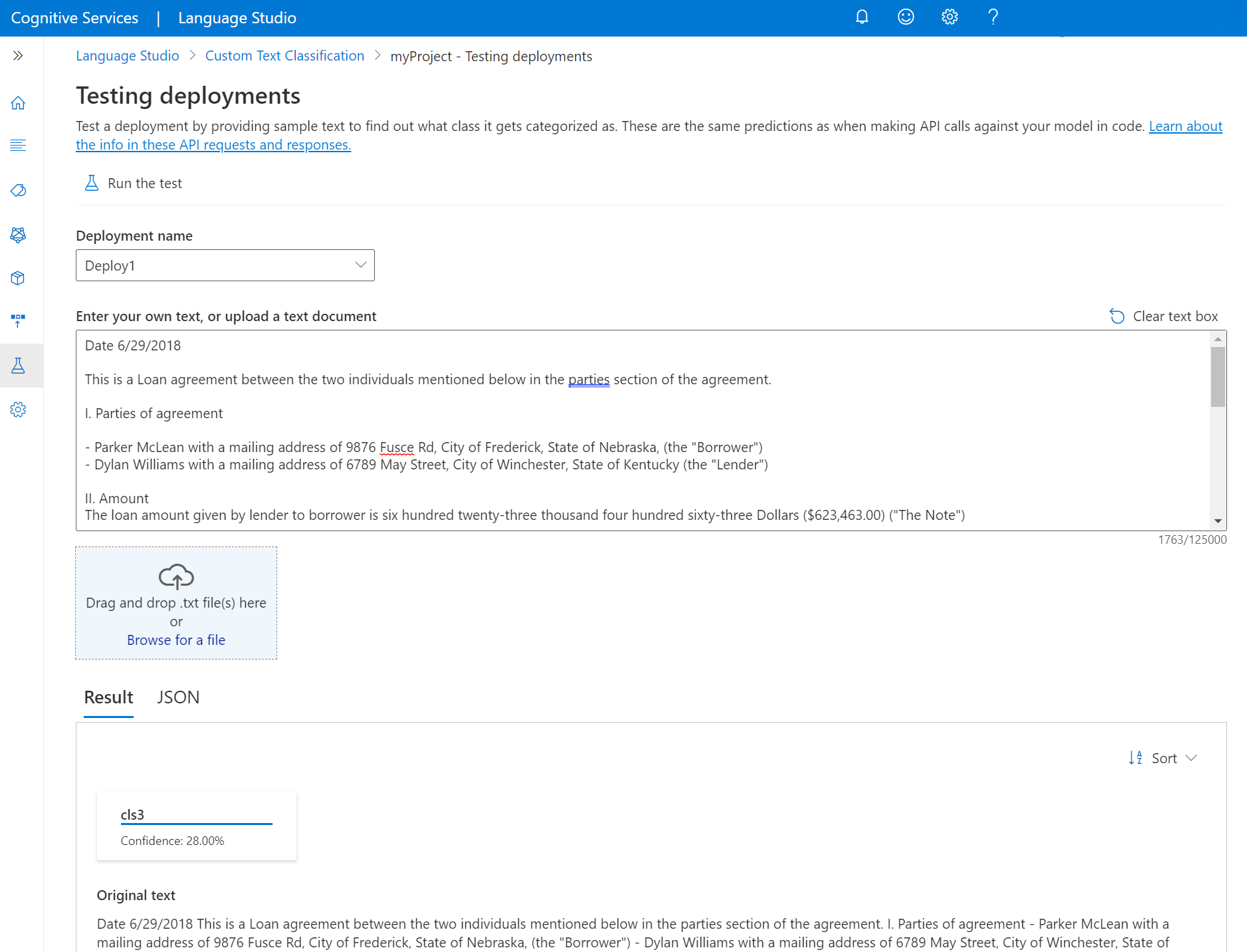
Selezionare Test delle distribuzioni dal menu a sinistra della schermata.
Selezionare la distribuzione da testare. È possibile testare solo i modelli assegnati alle distribuzioni.
Per i progetti multilingue, nell'elenco a discesa lingua selezionare la lingua del testo di cui si esegue il test.
Selezionare dall'elenco a discesa la distribuzione su cui si intende eseguire la query/il test.
Immettere il testo da inviare nella richiesta o caricare un documento
.txtda usare. Se si usa uno dei set di dati di esempio, è possibile usare uno dei file .txt inclusi.Selezionare Esegui il test dal menu in alto.
Nella scheda Risultato è possibile visualizzare le classi stimate per il testo. È anche possibile visualizzare la risposta JSON nella scheda JSON. L'esempio seguente è relativo a un progetto di classificazione con etichetta singola. Un progetto di classificazione multietichetta può restituire un risultato con più classi.

Pulire i progetti
Quando il progetto non è più necessario, è possibile eliminarlo usando Language Studio. Selezionare Classificazione personalizzata del testo nella parte superiore della schermata e quindi selezionare il progetto da eliminare. Per eliminare il progetto, selezionare Elimina dal menu in alto.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito.
Creare una nuova risorsa di Lingua di Azure AI e un account di archiviazione di Azure
Per poter usare la classificazione personalizzata del testo, è necessario creare una risorsa di Lingua di Azure AI che fornisca le credenziali necessarie per creare un progetto e avviare il training di un modello. È necessario anche un account di archiviazione di Azure in cui è possibile caricare il set di dati che verrà usato per la generazione del modello.
Importante
Per iniziare rapidamente, è preferibile creare una nuova risorsa di Lingua di Azure AI seguendo la procedura descritta in questo articolo; tale procedura consentirà di creare la risorsa linguistica e/o di connettere un account di archiviazione contemporaneamente, in quanto questa operazione sarebbe più complessa se venisse eseguita in un secondo momento.
Se si dispone di una risorsa preesistente da usare, sarà necessario connetterla all'account di archiviazione.
Creare una nuova risorsa dal portale di Azure
Accedere al portale di Azure per creare una nuova risorsa di Lingua di Azure AI.
Nella finestra visualizzata, selezionare Classificazione personalizzata del testo e Riconoscimento entità denominata personalizzata dalle funzionalità personalizzate. Selezionare Continua per creare la risorsa nella parte inferiore dello schermo.
Creare una risorsa linguistica con i dettagli seguenti.
Nome Valore obbligatorio Abbonamento La sottoscrizione di Azure. Gruppo di risorse Un gruppo di risorse di Azure che conterrà la risorsa. È possibile usarne uno esistente o crearne uno nuovo. Area Una delle aree supportate. Ad esempio: “Stati Uniti occidentali 2”. Nome Un nome per la risorsa. Piano tariffario Uno dei piani tariffari supportati. Per provare il servizio, è possibile usare il livello gratuito (F0). Se viene visualizzato un messaggio che indica che “l'account di accesso non è un proprietario del gruppo di risorse dell'account di archiviazione selezionato”, è necessario assegnare all'account un ruolo di proprietario nel gruppo di risorse per poter creare una risorsa linguistica. Per assistenza contattare il proprietario della sottoscrizione di Azure.
È possibile determinare il proprietario della sottoscrizione di Azure eseguendo una ricerca nel gruppo di risorse e seguendo il collegamento alla sottoscrizione associata. Quindi:
- Selezionare la scheda Controllo di accesso (IAM)
- Selezionare Assegnazioni di ruolo
- Filtrare in base a Ruolo:Proprietario.
Nella sezione Classificazione personalizzata del testo e Riconoscimento entità denominata personalizzata, selezionare un account di archiviazione esistente o scegliere Nuovo account di archiviazione. Questi valori consentono di iniziare senza usare necessariamente i valori dell'account di archiviazione che verranno usati in ambienti di produzione. Per evitare la latenza durante la creazione del progetto, connettersi agli account di archiviazione nella stessa area della risorsa linguistica.
Valore dell'account di archiviazione Valore consigliato Nome account di archiviazione Qualsiasi nome Storage account type LRS Standard Accertarsi che sia selezionata l’opzione Avviso intelligenza artificiale responsabile. Selezionare Rivedi e crea nella parte inferiore della pagina.
Caricare dati di esempio nel contenitore BLOB
Dopo aver creato un account di archiviazione di Azure e averlo connesso alla risorsa linguistica, sarà necessario caricare i documenti dal set di dati di esempio nella directory radice del contenitore. Questi documenti verranno usati successivamente per il training del modello.
Scaricare il set di dati di esempio per i progetti di classificazione multietichetta.
Aprire il file .zip ed estrarre la cartella contenente i documenti.
Il set di dati di esempio fornito contiene circa 200 documenti, ognuno dei quali è un riepilogo per un film. Ogni documento appartiene a una o più classi seguenti:
- "Mystery"
- "Drama"
- "Thriller"
- "Comedy"
- "Action"
Nel portale di Azure passare all'account di archiviazione creato e selezionarlo. A tal fine, fare clic su Account di archiviazione e digitare il nome dell'account di archiviazione in Filtro per qualunque campo.
Se il gruppo di risorse non viene visualizzato, accertarsi che il filtro Sottoscrizione uguale a sia impostato su Tutti.
Nell'account di archiviazione selezionare Contenitori nel menu a sinistra, sotto Archiviazione dati. Nella schermata visualizzata selezionare + Contenitore. Assegnare al contenitore il nome example-data e lasciare il livello di accesso pubblico predefinito.
Dopo aver creato il contenitore, selezionarlo. Selezionare quindi il pulsante Carica per selezionare i file
.txte.jsonscaricati in precedenza.
Ottenere le chiavi e l’endpoint di una risorsa
Passare alla pagina di panoramica della risorsa nel portale di Azure
Dal menu a sinistra selezionare Chiavi ed endpoint. Si useranno l'endpoint e la chiave per le richieste API

Creare un progetto di classificazione personalizzata del testo
Dopo aver configurato la risorsa e il contenitore di archiviazione, creare un nuovo progetto di classificazione personalizzata del testo. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa linguistica usata.
Attivare un processo di importazione progetto
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per importare il file di etichette. Accertarsi che il file di etichette rispetti il formato accettato.
Se esiste già un progetto con lo stesso nome, i dati di tale progetto vengono sostituiti.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
La versione dell'API che si sta chiamando. Il valore a cui si fa riferimento qui è relativo alla versione più recente rilasciata. Altre informazioni su altre versioni dell’API disponibili | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Corpo
Usare il JSON seguente nella richiesta. Sostituire i valori segnaposto seguenti con i propri valori.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"storageInputContainerName": "{CONTAINER-NAME}",
"projectKind": "customMultiLabelClassification",
"description": "Trying out custom multi label text classification",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"settings": {}
},
"assets": {
"projectKind": "customMultiLabelClassification",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class1"
},
{
"category": "Class2"
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"classes": [
{
"category": "Class2"
}
]
}
]
}
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
| api-version | {API-VERSION} |
La versione dell'API che si sta chiamando. La versione usata qui deve essere la stessa versione dell'API nell'URL. Altre informazioni su altre versioni dell’API disponibili | 2022-05-01 |
| projectName | {PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
| projectKind | customMultiLabelClassification |
Il tipo di progetto. | customMultiLabelClassification |
| linguaggio | {LANGUAGE-CODE} |
Una stringa che specifica il codice lingua per i documenti usati nel progetto. Se il progetto è un progetto multilingue, scegliere il codice lingua della maggior parte dei documenti. Per altre informazioni sul supporto multilingue, vedere Supporto lingue. | en-us |
| multilingual | true |
Un valore booleano che consente di avere documenti in più lingue nel set di dati; quando il modello viene distribuito, è possibile eseguire query sul modello in qualunque lingua supportata (non necessariamente inclusa nei documenti di training). Per altre informazioni sul supporto multilingue, vedere Supporto lingue. | true |
| storageInputContainerName | {CONTAINER-NAME} |
Il nome del contenitore di archiviazione di Azure in cui sono stati caricati i documenti. | myContainer |
| classi | [] | Array contenente tutte le classi incluse nel progetto. Queste sono le classi in cui classificare i documenti. | [] |
| documenti | [] | Array contenente tutti i documenti nel progetto e le classi etichettate per il documento. | [] |
| posizione | {DOCUMENT-NAME} |
Posizione dei documenti nel contenitore di archiviazione. Siccome tutti i documenti sono inclusi nella radice del contenitore, deve essere il nome del documento. | doc1.txt |
| set di dati | {DATASET} |
Il set di test a cui verrà sottoposto questo documento quando verrà diviso prima del training. Per altre informazioni sulla divisione dei dati, vedere Come eseguire il training di un modello. I valori possibili per questo campo sono Train e Test. |
Train |
Dopo aver inviato la richiesta API, si riceverà una risposta 202 che indica che il processo è stato inviato correttamente. Nelle intestazioni della risposta estrarre il valore operation-location. Il formato sarà simile al seguente:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. Questo URL verrà usato per ottenere lo stato del processo di importazione.
Possibili scenari di errore per questa richiesta:
- La risorsa selezionata non dispone delle autorizzazioni appropriate per l'account di archiviazione.
- Il valore
storageInputContainerNamespecificato non esiste. - Il codice lingua usato non è non valido o il tipo del codice lingua non è stringa.
- Il valore
multilingualè una stringa e non un valore booleano.
Ottenere lo stato del processo di importazione
Usare la richiesta GET seguente per ottenere lo stato dell’importazione di un progetto. Sostituire i valori segnaposto seguenti con i propri valori.
Richiesta URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{JOB-ID} |
L’ID per individuare lo stato del training del modello. Questo valore si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che si sta chiamando. Il valore a cui si fa riferimento qui è relativo alla versione più recente rilasciata. Altre informazioni su altre versioni dell’API disponibili | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Eseguire il training del modello
In genere, dopo aver creato un progetto, è possibile procedere e cominciare ad aggiungere tag ai documenti inclusi nel contenitore connesso al progetto. Per questa guida introduttiva è stato importato un set di dati con tag di esempio e il progetto è stato inizializzato con il file di tag JSON di esempio.
Avviare il training di un modello
Dopo aver importato il progetto, è possibile avviare il training del modello.
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per inviare un processo di training. Sostituire i valori segnaposto seguenti con i propri valori.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
La versione dell'API che si sta chiamando. Il valore a cui si fa riferimento qui è relativo alla versione più recente rilasciata. Altre informazioni su altre versioni dell’API disponibili | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della richiesta
Usare il JSON seguente nel corpo della richiesta. Al termine del training, al modello verrà assegnato {MODEL-NAME}. Solo i processi di training riusciti produrranno modelli.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Nome del modello che verrà assegnato al modello dopo aver eseguito il training correttamente. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
È la versione del modello che verrà usata per il training del modello. | 2022-05-01 |
| evaluationOptions | Opzione per dividere i dati tra set di training e set di test. | {} |
|
| kind | percentage |
Metodi di divisione. I possibili valori sono percentage o manual. Per altre informazioni, vedere Come eseguire il training di un modello. |
percentage |
| trainingSplitPercentage | 80 |
Percentuale dei dati con tag da includere nel set di training. Il valore consigliato è 80. |
80 |
| testingSplitPercentage | 20 |
Percentuale dei dati con tag da includere nel set di test. Il valore consigliato è 20. |
20 |
Nota
trainingSplitPercentage e testingSplitPercentage sono necessari solo se Kind è impostato su percentage e la somma di entrambe le percentuali deve essere uguale a 100.
Dopo aver inviato la richiesta API, si riceverà una risposta 202 che indica che il processo è stato inviato correttamente. Nelle intestazioni della risposta estrarre il valore location. Il formato sarà simile al seguente:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. È possibile usare questo URL per ottenere lo stato del training.
Ottenere lo stato del processo di training
Il training potrebbe richiedere qualche minuto tra 10 e 30 minuti. È possibile usare la richiesta seguente per continuare il polling dello stato del processo di training fino a quando non viene completato correttamente.
Usare la seguente richiesta GET per ottenere lo stato dello stato di avanzamento del training del modello. Sostituire i valori segnaposto seguenti con i propri valori.
Richiesta URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{JOB-ID} |
L’ID per individuare lo stato del training del modello. Questo valore si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che si sta chiamando. Il valore a cui si fa riferimento qui è relativo alla versione più recente rilasciata. Per altre informazioni su altre versioni disponibili dell’API, vedere Ciclo di vita di un modello. | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Testo della risposta
Dopo aver inviato la richiesta, si otterrà la risposta seguente.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Distribuire il modello
Generalmente, dopo il training di un modello è opportuno rivedere i relativi dettagli di valutazione e apportare miglioramenti in base alla necessità. In questa guida introduttiva, il modello verrà solo distribuito e reso disponibile per una prova in Language Studio; è possibile anche richiamare l'API di stima.
Inviare un processo di distribuzione
Inviare una richiesta PUT usando l'URL, le intestazioni e il corpo JSON seguenti per inviare un processo di distribuzione. Sostituire i valori segnaposto seguenti con i propri valori.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Il nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{API-VERSION} |
La versione dell'API che si sta chiamando. Il valore a cui si fa riferimento qui è relativo alla versione più recente rilasciata. Altre informazioni su altre versioni dell’API disponibili | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Corpo della richiesta
Usare il JSON seguente nel corpo della richiesta. Usare il nome del modello da assegnare alla distribuzione.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nome del modello che verrà assegnato alla distribuzione. È possibile assegnare solo modelli il cui training è stato eseguito correttamente. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myModel |
Dopo aver inviato la richiesta API, si riceverà una risposta 202 che indica che il processo è stato inviato correttamente. Nelle intestazioni della risposta estrarre il valore operation-location. Il formato sarà simile al seguente:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. È possibile usare questo URL per ottenere lo stato della distribuzione.
Ottenere lo stato del processo di distribuzione
Usare la richiesta GET seguente per eseguire una query dello stato del processo di distribuzione. È possibile usare l'URL ricevuto dal passaggio precedente oppure sostituire i valori segnaposto seguenti con i propri valori.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Il nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Il nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{JOB-ID} |
L’ID per individuare lo stato del training del modello. Si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
La versione dell'API che si sta chiamando. Il valore a cui si fa riferimento qui è relativo alla versione più recente rilasciata. Altre informazioni su altre versioni dell’API disponibili | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Testo della risposta
Dopo aver inviato la richiesta, si otterrà la risposta seguente. Continuare il polling di questo endpoint fino a quando il parametro dello stato diventa "succeeded". Si ottiene un codice 200 indicante l'esito positivo della richiesta.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Classifica testo
Dopo aver distribuito correttamente il modello, è possibile iniziare a usarlo per classificare il testo tramite l'APIStima. Nel set di dati di esempio scaricato in precedenza è possibile trovare alcuni documenti di test che è possibile usare in questo passaggio.
Inviare un’attività di classificazione personalizzata del testo
Usare questa richiesta POST per avviare un'attività di classificazione del testo.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La versione dell'API che si sta chiamando. Il valore a cui si fa riferimento qui è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | La chiave che fornisce l'accesso all’API. |
Corpo
{
"displayName": "Classifying documents",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomMultiLabelClassification",
"taskName": "Multi Label Classification",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Chiave | Segnaposto | Valore | Esempio |
|---|---|---|---|
displayName |
{JOB-NAME} |
Il nome del processo. | MyJobName |
documents |
[{},{}] | Elenco di documenti per cui eseguire le attività. | [{},{}] |
id |
{DOC-ID} |
Nome o ID del documento. | doc1 |
language |
{LANGUAGE-CODE} |
Una stringa che specifica il codice lingua per il documento. Se questa chiave non è specificata, il servizio presuppone la lingua predefinita del progetto selezionata durante la creazione del progetto. Per un elenco dei codici lingua supportati, vedere Supporto lingua. | en-us |
text |
{DOC-TEXT} |
Attività del documento per cui eseguire le attività. | Lorem ipsum dolor sit amet |
tasks |
Elenco di attività da eseguire. | [] |
|
taskName |
CustomMultiLabelClassification | Il nome dell’attività | CustomMultiLabelClassification |
parameters |
Elenco di parametri da passare all’attività. | ||
project-name |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Il nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | prod |
Response
Si riceverà una risposta 202 che indica l'esito positivo. Nelle intestazioni della risposta, estrarre operation-location.
operation-location è formattato come indicato di seguito:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
È possibile usare questo URL per eseguire una query sullo stato di completamento dell'attività e ottenere i risultati al termine dell'attività.
Ottenere i risultati dell’attività
Usare la richiesta GET seguente per eseguire una query sullo stato o sui risultati dell'attività di classificazione del testo.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
La versione dell'API che si sta richiamando. Il valore a cui fa riferimento qui è relativo all’ultima versione del modello rilasciata. | 2022-05-01 |
Intestazioni
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | La chiave che fornisce l'accesso all’API. |
Corpo della risposta
La risposta sarà un documento JSON con i parametri seguenti.
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxxxx-xxxxx-xxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "customMultiClassificationTasks",
"taskName": "Classify documents",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "{DOC-ID}",
"classes": [
{
"category": "Class_1",
"confidenceScore": 0.0551877357
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
Pulire le risorse
Quando il progetto non è più necessario, è possibile eliminarlo con la richiesta DELETE seguente. Sostituire i valori segnaposto con i propri valori.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
La versione dell'API che si sta chiamando. Il valore a cui si fa riferimento qui è relativo alla versione più recente rilasciata. Altre informazioni su altre versioni dell’API disponibili | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | La chiave della risorsa. È usata per l’autenticazione delle richieste API. |
Dopo aver inviato la richiesta API, si riceverà una risposta 202 con l'esito positivo che indica che il progetto è stato eliminato. Risultati di una chiamata con esito positivo con un'intestazione Operation-Location usata per controllare lo stato del processo.
Passaggi successivi
Dopo aver creato un modello di classificazione personalizzata del testo, è possibile:
Quando si inizia a creare progetti di classificazione personalizzata del testo, usare gli articoli sulle procedure per altre informazioni più dettagliate sullo sviluppo del modello: