Prestazioni e scalabilità in Durable Functions (Funzioni di Azure)
Per ottimizzare le prestazioni e la scalabilità, è importante comprendere le caratteristiche univoche di scalabilità di Funzioni permanenti. In questo articolo viene illustrato come i ruoli di lavoro vengono ridimensionati in base al carico e come ottimizzare i vari parametri.
Ridimensionamento del ruolo di lavoro
Un vantaggio fondamentale del concetto di hub attività è che il numero di ruoli di lavoro che elaborano gli elementi di lavoro dell'hub attività può essere regolato continuamente. In particolare, le applicazioni possono aggiungere più lavoratori (scale out) se il lavoro deve essere elaborato più rapidamente e può rimuovere i lavoratori (scale in) se non c'è abbastanza lavoro per mantenere i lavoratori occupati. È anche possibile ridimensionare a zero se l'hub attività è completamente inattiva. Quando viene ridimensionato su zero, non ci sono affatto lavoratori; solo il controller di scalabilità e lo spazio di archiviazione devono rimanere attivi.
Il diagramma seguente illustra questo concetto:
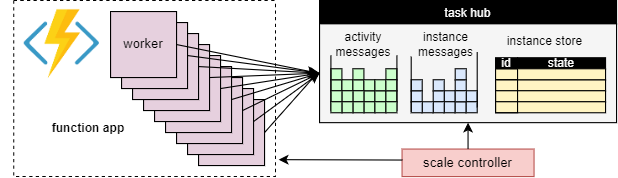
Scalabilità automatica
In modo analogo a tutte le Funzioni di Azure in esecuzione nel piano a consumo e Elastic Premium, le Durable Functions supportano la scalabilità automatica tramite il controller di scalabilità di Funzioni di Azure. Il controller di scalabilità monitora il tempo di attesa dei messaggi e delle attività prima dell'elaborazione. In base a queste latenze, può decidere se aggiungere o rimuovere ruoli di lavoro.
Nota
A partire da Durable Functions 2.0, le app per le funzioni possono essere configurate per l'esecuzione all'interno degli endpoint di servizio protetti dalla rete virtuale nel piano Elastic Premium. In questa configurazione, i trigger di Durable Functions avviano richieste di scalabilità anziché il controller di scalabilità. Per altre informazioni, vedere Monitoraggio della scalabilità di runtime.
In un piano Premium, il ridimensionamento automatico può aiutare a mantenere il numero di ruoli di lavoro (e quindi il costo operativo) approssimativamente proporzionale al carico riscontrato dall'applicazione.
Utilizzo CPU
Le funzioni dell'agente di orchestrazione vengono eseguite su un thread singolo per garantire che l'esecuzione sia deterministica tra più riproduzioni. A causa di questa esecuzione su thread singolo, è importante che i thread delle funzioni dell'agente di orchestrazione non esegua operazioni con uso intensivo della CPU né operazioni di I/O oppure di blocco per qualsiasi motivo. Tutto il lavoro che richiede thread di I/O oppure di blocco o più thread deve essere spostato nelle funzioni di attività.
Le funzioni di attività hanno gli stessi comportamenti delle normali funzioni attivate da coda. In tal modo è possibile eseguire in modo sicuro operazioni di I/O oppure con uso intensivo della CPU e usare più thread. Poiché i trigger di attività sono senza stato, è possibile aumentare il numero di istanze a un numero illimitato di macchine virtuali.
Le funzioni di entità vengono eseguite anche su un singolo thread e le operazioni vengono elaborate una alla volta. Tuttavia, le funzioni di entità non hanno restrizioni sul tipo di codice che è possibile eseguire.
Timeout delle funzioni
Le funzioni di attività, agente di orchestrazione ed entità sono soggette agli stessi timeout di funzione di tutte le Funzioni di Azure. Come regola generale, Durable Functions considera i timeout delle funzioni allo stesso modo delle eccezioni non gestite generate dal codice dell'applicazione.
Ad esempio, se si verifica il timeout di un'attività, l'esecuzione della funzione viene registrata come errore e l'agente di orchestrazione riceve una notifica e gestisce il timeout esattamente come qualsiasi altra eccezione: i tentativi vengono eseguiti se specificati dalla chiamata oppure è possibile eseguire un gestore eccezioni.
Invio in batch dell'operazione di entità
Per migliorare le prestazioni e ridurre i costi, un singolo elemento di lavoro può eseguire un intero batch di operazioni di entità. Nei piani a consumo, ogni batch viene quindi fatturato come singola esecuzione di funzione.
Per impostazione predefinita, le dimensioni massime del batch sono 50 per i piani a consumo e 5000 per tutti gli altri piani. Le dimensioni massime del batch possono essere configurate anche nel file host.json. Se la dimensione massima del batch è 1, l'invio in batch viene effettivamente disabilitato.
Nota
Se l'esecuzione delle singole entità richiede molto tempo, può essere utile limitare le dimensioni massime del batch per ridurre il rischio di timeout delle funzioni, in particolare nei piani di consumo.
Memorizzazione nella cache dell'istanza
In genere, per elaborare un elemento di lavoro di orchestrazione, un ruolo di lavoro deve entrambi
- Recuperare la cronologia dell'orchestrazione.
- Riprodurre il codice dell'agente di orchestrazione usando la cronologia.
Se lo stesso ruolo di lavoro elabora più elementi di lavoro per la stessa orchestrazione, il provider di archiviazione può ottimizzare questo processo memorizzando nella cache la cronologia nella memoria del ruolo di lavoro, eliminando così il primo passaggio. Inoltre, può memorizzare nella cache l'agente di orchestrazione di metà esecuzione, che elimina anche il secondo passaggio, la riproduzione della cronologia.
L'effetto tipico della memorizzazione nella cache è ridotto l'I/O rispetto al servizio di archiviazione sottostante e la velocità effettiva e la latenza complessivamente migliorate. D'altra parte, la memorizzazione nella cache aumenta il consumo di memoria nel ruolo di lavoro.
La memorizzazione nella cache delle istanze è attualmente supportata dal provider di Archiviazione di Azure e dal provider di archiviazione Netherite. La tabella seguente fornisce un confronto.
| Provider di Archiviazione di Azure | Provider di archiviazione Netherite | Provider di archiviazione MSSQL | |
|---|---|---|---|
| Memorizzazione nella cache dell'istanza | Supportata (solo ruolo di lavoro in-process.NET) |
Supportato | Non supportato |
| Impostazione predefinita | Disabilitata | Attivata | n/d |
| Meccanismo | Sessioni estese | Cache dell'istanza | n/d |
| Documentazione | Vedere Sessioni estese | Vedere Cache dell'istanza | n/d |
Suggerimento
La memorizzazione nella cache può ridurre la frequenza di riproduzione delle cronologie, ma non può eliminare completamente la riproduzione. Quando si sviluppano agenti di orchestrazione, è consigliabile testarli in una configurazione che disabilita la memorizzazione nella cache. Questo comportamento di riesecuzione forzata può essere utile per rilevare violazioni dei vincoli del codice della funzione dell'agente di orchestrazione in fase di sviluppo.
Confronto dei meccanismi di memorizzazione nella cache
I provider usano meccanismi diversi per implementare la memorizzazione nella cache e offrono parametri diversi per configurare il comportamento di memorizzazione nella cache.
- Le sessioni estese, usate dal provider di Archiviazione di Azure, mantengono in memoria gli agenti di orchestrazione a metà esecuzione fino a quando non sono inattive per qualche tempo. I parametri per controllare questo meccanismo sono
extendedSessionsEnabledeextendedSessionIdleTimeoutInSeconds. Per altri dettagli, vedere la sezione Sessioni estese della documentazione del provider di Archiviazione di Azure.
Nota
Le sessioni estese sono supportate solo nel ruolo di lavoro in-process .NET.
- La cache dell'istanza, usata dal provider di archiviazione Netherite, mantiene lo stato di tutte le istanze, incluse le relative cronologie, nella memoria del ruolo di lavoro, mantenendo traccia della memoria totale usata. Se le dimensioni della cache superano il limite configurato da
InstanceCacheSizeMB, i dati dell'istanza usati meno di recente vengono rimossi. SeCacheOrchestrationCursorsè impostato su true, la cache archivia anche gli agenti di orchestrazione durante l'archiviazione insieme allo stato dell'istanza. Per altri dettagli, vedere la sezione Cache dell'istanza della documentazione del provider di archiviazione Netherite.
Nota
Le cache delle istanze funzionano per tutti gli SDK del linguaggio, ma l'opzione CacheOrchestrationCursors è disponibile solo per il ruolo di lavoro in-process .NET.
Limitazioni di concorrenza
Una singola istanza del ruolo di lavoro può eseguire più elementi di lavoro contemporaneamente. Ciò consente di aumentare il parallelismo e di utilizzare in modo più efficiente i lavoratori. Tuttavia, se un ruolo di lavoro tenta di elaborare troppi elementi di lavoro contemporaneamente, può esaurire le risorse disponibili, ad esempio il carico della CPU, il numero di connessioni di rete o la memoria disponibile.
Per assicurarsi che un singolo ruolo di lavoro non esegua overcommit, potrebbe essere necessario limitare la concorrenza per istanza. Limitando il numero di funzioni in esecuzione simultaneamente in ogni ruolo di lavoro, è possibile evitare di esaurire i limiti delle risorse per tale ruolo di lavoro.
Nota
Le limitazioni di concorrenza si applicano solo in locale, per limitare ciò che viene attualmente elaborato per ogni ruolo di lavoro. Pertanto, queste limitazioni non limitano la velocità effettiva totale del sistema.
Suggerimento
In alcuni casi, la limitazione della concorrenza per ogni ruolo di lavoro può effettivamente aumentare la velocità effettiva totale del sistema. Ciò può verificarsi quando ogni ruolo di lavoro richiede meno lavoro, causando l'aggiunta di altri ruoli di lavoro da parte del controller di scalabilità con le code, che quindi aumenta la velocità effettiva totale.
Configurazione delle limitazioni
I limiti per la concorrenza per la funzione di attività, per la funzione dell'agente di orchestrazione e per l'entità possono essere configurati nel file host.json. Le impostazioni pertinenti sono durableTask/maxConcurrentActivityFunctions per le funzioni di attività e durableTask/maxConcurrentOrchestratorFunctions per le funzioni dell'agente di orchestrazione e dell'entità. Queste impostazioni controllano il numero massimo di funzioni di orchestrazione, entità o attività caricate in memoria in un singolo ruolo di lavoro.
Nota
Le orchestrazioni e le entità vengono caricate in memoria solo quando elaborano attivamente eventi o operazioni o se la memorizzazione nella cache dell'istanza è abilitata. Dopo aver eseguito la logica e aver atteso (ad esempio, aver raggiunto un'istruzione await (C#) o yield (JavaScript, Python) nel codice della funzione dell'agente di orchestrazione), potrebbero essere scaricati dalla memoria. Le orchestrazioni e le entità scaricate dalla memoria non vengono conteggiate per la limitazione maxConcurrentOrchestratorFunctions. Anche se milioni di orchestrazioni o entità si trovano nello stato "In esecuzione", vengono conteggiate solo per il limite di limitazione quando vengono caricate nella memoria attiva. Un'orchestrazione che pianifica una funzione di attività in modo analogo non viene conteggiato per la limitazione se l'orchestrazione è in attesa del completamento dell'esecuzione dell'attività.
Funzioni 2.0
{
"extensions": {
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
}
Funzioni 1.x
{
"durableTask": {
"maxConcurrentActivityFunctions": 10,
"maxConcurrentOrchestratorFunctions": 10
}
}
Considerazioni sul runtime del linguaggio
Il runtime del linguaggio selezionato può imporre restrizioni rigorose di concorrenza o le funzioni. Ad esempio, le app durable function scritte in Python o PowerShell possono supportare solo l'esecuzione di una singola funzione alla volta in una singola macchina virtuale. Ciò può comportare problemi di prestazioni significativi se non vengono attentamente rilevati. Se, ad esempio, un fanout di un agente di orchestrazione su 10 attività, ma il runtime del linguaggio limita la concorrenza a una sola funzione, 9 delle 10 funzioni di attività saranno bloccate in attesa di una possibilità di esecuzione. Inoltre, queste 9 attività bloccate non saranno in grado di essere bilanciate per altri ruoli di lavoro perché il runtime di Durable Functions li avrà già caricati in memoria. Ciò diventa particolarmente problematico se le funzioni di attività sono a esecuzione prolungata.
Se il runtime del linguaggio in uso pone una restrizione sulla concorrenza, è necessario aggiornare le impostazioni di concorrenza di Durable Functions in modo che corrispondano alle impostazioni di concorrenza del runtime del linguaggio. In questo modo, il runtime di Durable Functions non tenterà di eseguire più funzioni simultaneamente di quanto sia consentito dal runtime del linguaggio, consentendo il bilanciamento del carico delle attività in sospeso ad altre macchine virtuali. Ad esempio, se si dispone di un'app Python che limita la concorrenza a 4 funzioni (ad esempio, è configurata solo con 4 thread in un singolo processo di lavoro del linguaggio o 1 thread in 4 processi di lavoro del linguaggio), è necessario configurare sia maxConcurrentOrchestratorFunctions che maxConcurrentActivityFunctions su 4.
Per altre informazioni e consigli sulle prestazioni per Python, vedere Migliorare le prestazioni della velocità effettiva delle app Python in Funzioni di Azure. Le tecniche indicate in questa documentazione di riferimento per sviluppatori Python possono avere un impatto significativo sulle prestazioni e sulla scalabilità di Durable Functions.
Numero di partizioni
Alcuni provider di archiviazione usano un meccanismo di partizionamento e consentono di specificare un parametro partitionCount.
Quando si usa il partizionamento, i ruoli di lavoro non competono direttamente per i singoli elementi di lavoro. Gli elementi di lavoro vengono invece raggruppati per primi in partitionCount partizioni. Queste partizioni vengono quindi assegnate ai ruoli di lavoro. Questo approccio partizionato alla distribuzione del carico può contribuire a ridurre il numero totale di accessi di archiviazione necessari. Inoltre, può abilitare la memorizzazione nella cache delle istanze e migliorare la località perché crea affinità: tutti gli elementi di lavoro per la stessa istanza vengono elaborati dallo stesso ruolo di lavoro.
Nota
I limiti di partizionamento aumentano il numero di istanze perché al massimo partitionCount ruoli di lavoro possono elaborare gli elementi di lavoro da una coda partizionata.
La tabella seguente illustra, per ogni provider di archiviazione, le code partizionate e l'intervallo consentito e i valori predefiniti per il parametro partitionCount.
| Provider di Archiviazione di Azure | Provider di archiviazione Netherite | Provider di archiviazione MSSQL | |
|---|---|---|---|
| Messaggi di istanza | Partitioned | Partitioned | Non partizionata |
| Messaggi di attività | Non partizionata | Partitioned | Non partizionata |
Impostazione predefinitapartitionCount |
4 | 12 | n/d |
MassimopartitionCount |
16 | 32 | n/d |
| Documentazione | Vedere Scalabilità orizzontale dell'agente di orchestrazione | Vedere Considerazioni sul numero di partizioni | n/d |
Avviso
Il numero di partizioni non può più essere modificato dopo la creazione di un hub attività. È quindi consigliabile impostarlo su un valore sufficientemente grande per soddisfare i requisiti futuri di scalabilità orizzontale per l'istanza dell'hub attività.
Configurazione del numero di partizioni
Il parametro partitionCount può essere specificato nel file host.json. Nell'esempio seguente host.json frammento di codice imposta la proprietà durableTask/storageProvider/partitionCount (o durableTask/partitionCount in Durable Functions 1.x) su 3.
Durable Functions 2.x
{
"extensions": {
"durableTask": {
"storageProvider": {
"partitionCount": 3
}
}
}
}
Durable Functions 1.x
{
"extensions": {
"durableTask": {
"partitionCount": 3
}
}
}
Considerazioni per ridurre al minimo le latenze di chiamata
In circostanze normali, le richieste di chiamata (ad attività, agenti di orchestrazione, entità e così via) devono essere elaborate piuttosto rapidamente. Tuttavia, non esiste alcuna garanzia sulla latenza massima di qualsiasi richiesta di chiamata perché dipende da fattori quali: il tipo di comportamento di scalabilità del piano di servizio app, le impostazioni di concorrenza e le dimensioni del backlog dell'applicazione. Di conseguenza, è consigliabile investire in test di stress per misurare e ottimizzare le latenze della coda dell'applicazione.
Obiettivi di prestazioni
Quando si intende usare Funzioni permanenti per un'applicazione di produzione, è importante prendere in considerazione i requisiti in termini di prestazioni nelle prime fasi del processo di pianificazione. Alcuni scenari di utilizzo di base includono:
- Esecuzione di attività sequenziali: questo scenario descrive una funzione dell'agente di orchestrazione che esegue una serie di funzioni di attività una dopo l'altra ed è analogo all'esempio descritto in Concatenamento di funzioni.
- Esecuzione di attività parallele: questo scenario descrive una funzione dell'agente di orchestrazione che esegue molte funzioni di attività in parallelo tramite il modello fan-out, fan-in.
- Elaborazione di risposte parallele: questo scenario è la parte complementare del modello fan-out, fan-in e si basa sulle prestazioni dello schema fan-in. È importante notare che, a differenza dello schema fan-out, lo schema fan-in viene realizzato da un'unica istanza delle funzioni dell'agente di orchestrazione e pertanto può essere eseguito solo su un'unica macchina virtuale.
- Elaborazione di eventi esterni: questo scenario rappresenta un'unica istanza di funzioni dell'agente di orchestrazione che rimane in attesa su eventi esterni, uno alla volta.
- Elaborazione dell'operazione di entità: questo scenario verifica la velocità con cui una singolaentità Counter può elaborare un flusso costante di operazioni.
I numeri di velocità effettiva per questi scenari vengono forniti nella rispettiva documentazione per i provider di archiviazione. In particolare:
- per il provider di Archiviazione di Azure, vedere Obiettivi di prestazioni.
- per il provider di archiviazione Netherite, vedere Scenari di base.
- per il provider di archiviazione MSSQL, vedere Benchmark della velocità effettiva dell'orchestrazione.
Suggerimento
A differenza dello schema fan-out, le operazioni fan-in sono limitate a un'unica macchina virtuale. Se l'applicazione usa il modello fan-out, fan-in ed è necessario rispettare le prestazioni in ambito fan-in, è possibile applicare lo schema fan-out della funzione di attività tra più orchestrazioni secondarie.