Trasformazione Flowlet nel flusso di dati di mapping
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi all-in-one per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
I flussi di dati sono disponibili sia in Azure Data Factory che in pipeline di Azure Synapse. Questo articolo si applica al mapping dei flussi di dati. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando un flusso di dati di mapping.
Usare la trasformazione flowlet per eseguire un flusso di flusso di dati di mapping creato in precedenza. Per una panoramica dei flowlet, vedere Flowlets in mapping data flow flow | Microsoft Docs
Nota
La trasformazione flowlet nelle pipeline di Azure Data Factory e Synapse Analytics è attualmente in anteprima pubblica
Configurazione
La trasformazione flowlet contiene le impostazioni di configurazione seguenti
Flussolet
Selezionare il flussolet da eseguire. Dopo aver selezionato il flussolet, sarà possibile eseguire il mapping delle colonne di input, se presenti, nella scheda mapping.
Mapping
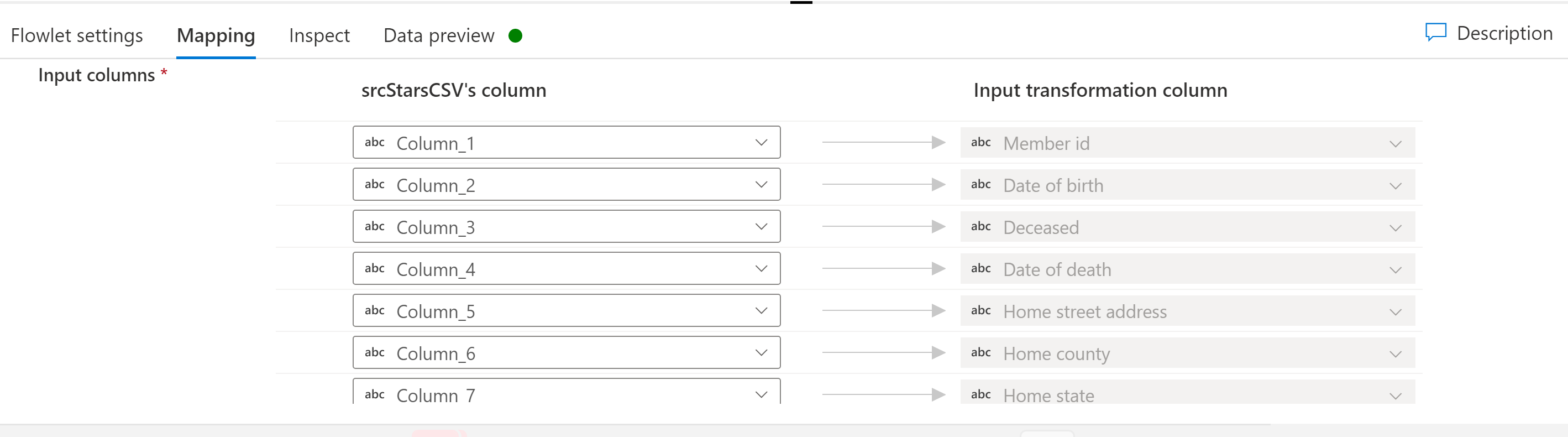
Se il flussolet selezionato include colonne di input, è possibile eseguire il mapping delle colonne dal flusso di input alle colonne di input previste nel flussolet. Questo mapping delle colonne dei flussi di dati di mapping al flussolet consente ai flussilet di fungere da frammenti riutilizzabili della logica del flusso di dati di mapping in molti flussi di dati di mapping.
Script del flusso di dati
Sintassi
<incomingStream>
<transformation> ~> <transformationName>
<outputStream>
Esempio
source1 derive(Test = "test") ~> DerivedColumn1
DerivedColumn1 output() ~> output1
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per