Trasformazione finestra nel flusso di dati di mapping
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
I flussi di dati sono disponibili sia in Azure Data Factory che in Azure Synapse Pipelines. Questo articolo si applica ai flussi di dati di mapping. Se non si ha esperienza con le trasformazioni, vedere l'articolo introduttivo Trasformare i dati usando un flusso di dati di mapping.
La trasformazione Finestra è la posizione in cui verranno definite le aggregazioni basate su finestra delle colonne nei flussi di dati. Nel generatore di espressioni è possibile definire diversi tipi di aggregazioni basate su finestre di dati o temporali (clausola OVER SQL), ad esempio LEAD, LAG, NTILE, CUMEDIST, RANK e così via. Verrà generato un nuovo campo nell'output che include queste aggregazioni. È anche possibile includere campi di raggruppamento facoltativi.
Over (Selezione)
Impostare il partizionamento dei dati di colonna per la trasformazione Finestra. L'equivalente SQL è Partition By nella clausola Over in SQL. Se si vuole creare un calcolo o un'espressione da usare per il partizionamento, è possibile passare il mouse sul nome della colonna e selezionare "computed column" (colonna calcolata).
Ordinamento
Un'altra parte della clausola Over è l'impostazione di Order By. Questa parte imposterà l'ordinamento dei dati. È anche possibile creare un'espressione per calcolare un valore in questo campo della colonna per l'ordinamento.
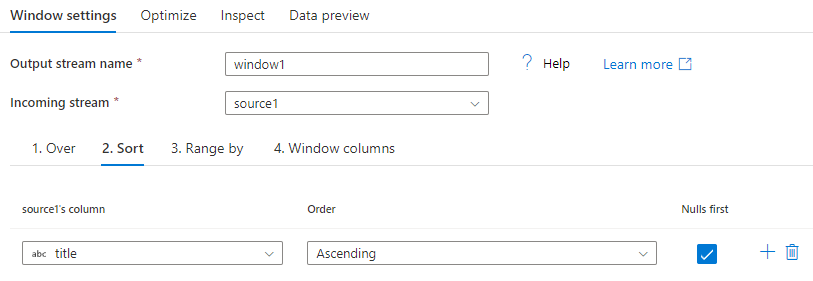
Range By (Criteri intervallo)
Impostare poi l'intervallo della finestra come Unbounded (Non vincolato) o Bounded (Vincolato). Per impostare un intervallo della finestra non vincolato, impostare il dispositivo di scorrimento su Unbounded (Non vincolato) su entrambe le estremità. Se si sceglie un'impostazione compresa tra Unbounded (Non vincolato) e Current Row (Riga corrente), è necessario impostare i valori di inizio e fine per Offset. Entrambi i valori saranno numeri interi positivi. È possibile usare numeri relativi o valori dai dati.
Nel dispositivo di scorrimento della finestra è necessario impostare due valori: i valori prima della riga corrente e i valori dopo la riga corrente. L'offset di inizio e di fine corrisponde ai due selettori nel dispositivo di scorrimento.
Colonne finestra
Infine, usare il generatore di espressioni per definire le aggregazioni da usare con le finestre di dati, come RANK, COUNT, MIN, MAX, DENSE RANK, LEAD, LAG e così via.
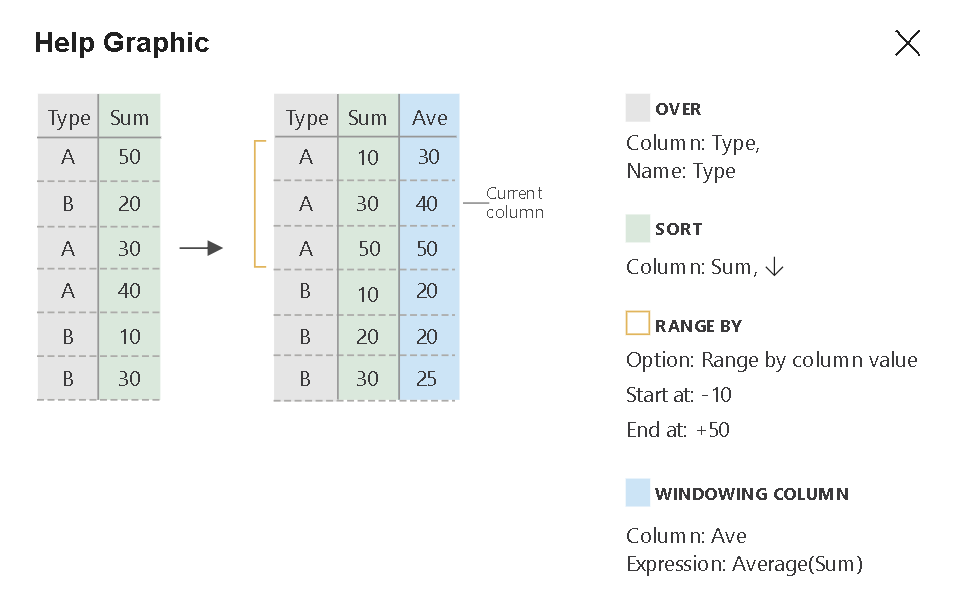
L'elenco completo delle funzioni analitiche e di aggregazione disponibili per l'uso nel linguaggio delle espressioni Flusso di dati tramite il Generatore di espressioni è elencato in Espressioni di trasformazione dati nel flusso di dati di mapping.
Contenuto correlato
Se si sta cercando una semplice aggregazione group-by, usare la trasformazione Aggregazione
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per