Migrazione in tempo reale ad Azure Istanza gestita per Apache Cassandra usando un proxy a doppio scrittura
Laddove possibile, è consigliabile usare la funzionalità nativa Apache Cassandra per eseguire la migrazione dei dati dal cluster esistente ad Azure Istanza gestita per Apache Cassandra configurando un cluster ibrido. Questa funzionalità usa il protocollo gossip di Apache Cassandra per replicare i dati dal data center di origine nel nuovo data center dell'istanza gestita in modo semplice. Tuttavia, potrebbero verificarsi alcuni scenari in cui la versione del database di origine non è compatibile oppure non è possibile configurare un cluster ibrido.
Questa esercitazione descrive come eseguire la migrazione dei dati ad Azure Istanza gestita per Apache Cassandra in modo live usando un proxy a doppia scrittura e Apache Spark. Il proxy a doppia scrittura consente di acquisire le modifiche in tempo reale, mentre viene eseguita la copia bulk dei dati cronologici con Apache Spark. Questo approccio offre i vantaggi seguenti:
- Modifiche minime dell'applicazione. Il proxy può accettare connessioni dal codice dell'applicazione con poche o nessuna modifica alla configurazione. Instrada tutte le richieste al database di origine e instrada le scritture asincrone in una destinazione secondaria.
- Dipendenza del protocollo di collegamento client. Poiché questo approccio non dipende dalle risorse back-end o dai protocolli interni, può essere usato con qualsiasi sistema Cassandra di origine o di destinazione che implementa il protocollo di collegamento Apache Cassandra.
L'immagine seguente illustra l'approccio.

Prerequisiti
Effettuare il provisioning di un Istanza gestita di Azure per il cluster Apache Cassandra usando il portale di Azure o l'interfaccia della riga di comando di Azure. Assicurarsi di potersi connettere al cluster con CQLSH.
Effettuare il provisioning di un account Azure Databricks all'interno della rete virtuale Cassandra gestita. Assicurarsi che l'account disponga dell'accesso di rete al cluster Cassandra di origine. Verrà creato un cluster Spark in questo account per il caricamento cronologico dei dati.
Assicurarsi di aver già eseguito la migrazione dello schema keyspace/table dal database Cassandra di origine al database dell'istanza gestita di Cassandra di destinazione.
Effettuare il provisioning di un cluster Spark
È consigliabile selezionare Azure Databricks runtime versione 7.5, che supporta Spark 3.0.
Aggiungere le dipendenze Spark
È necessario aggiungere la libreria del connettore Apache Spark Cassandra al cluster per connettersi a qualsiasi endpoint Apache Cassandra compatibile con il protocollo di collegamento. Nel cluster selezionare Librerie>Installa nuova>Maven e quindi aggiungere com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 nelle coordinate Maven.
Importante
Se è necessario mantenere l'elemento writetime Apache Cassandra per ogni riga durante la migrazione, è consigliabile usare questo esempio. Il file JAR delle dipendenze in questo esempio contiene anche il connettore Spark, quindi è consigliabile installare quest'ultimo anziché l'assembly del connettore precedente. Questo esempio è utile anche se si vuole eseguire una convalida del confronto delle righe tra origine e destinazione al termine del caricamento dei dati cronologici. Per informazioni dettagliate, vedere le sezioni "eseguire il caricamento dei dati cronologici" e "convalidare l'origine e la destinazione".
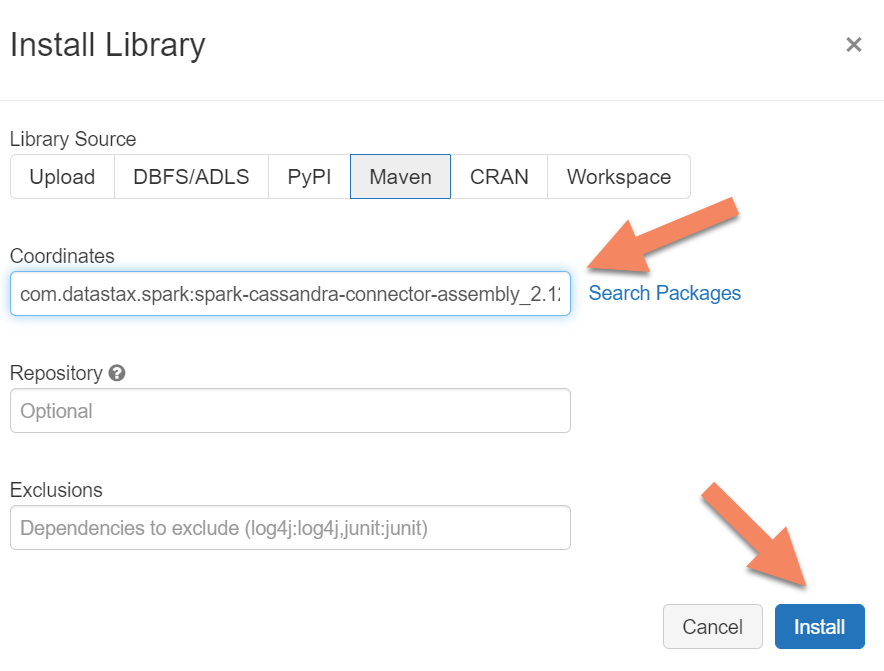
Selezionare Installa e quindi riavviare il cluster al termine dell'installazione.
Nota
Assicurarsi di riavviare il cluster Azure Databricks dopo l'installazione della libreria del connettore Cassandra.
Installare il proxy a doppia scrittura
Per ottenere prestazioni ottimali durante le operazioni di doppia scrittura, è consigliabile installare il proxy in tutti i nodi del cluster Cassandra di origine.
#assuming you do not have git already installed
sudo apt-get install git
#assuming you do not have maven already installed
sudo apt install maven
#clone repo for dual-write proxy
git clone https://github.com/Azure-Samples/cassandra-proxy.git
#change directory
cd cassandra-proxy
#compile the proxy
mvn package
Avviare il proxy a doppia scrittura
È consigliabile installare il proxy in tutti i nodi del cluster Cassandra di origine. Come minimo, eseguire il comando seguente per avviare il proxy in ogni nodo. Sostituire <target-server> con un indirizzo IP o del server da uno dei nodi nel cluster di destinazione. Sostituire <path to JKS file> con il percorso di un file JKS locale e sostituire <keystore password> con la password corrispondente.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password>
L'avvio del proxy in questo modo presuppone che le condizioni seguenti siano vere:
- Gli endpoint di origine e di destinazione hanno lo stesso nome utente e la stessa password.
- Gli endpoint di origine e di destinazione implementano SSL (Secure Sockets Layer).
Se gli endpoint di origine e di destinazione non sono in grado di soddisfare questi criteri, continuare a leggere per altre opzioni di configurazione.
Configurare SSL
Per SSL, è possibile implementare un archivio chiavi esistente, ad esempio quello usato dal cluster di origine, oppure creare un certificato autofirmato usando keytool:
keytool -genkey -keyalg RSA -alias selfsigned -keystore keystore.jks -storepass password -validity 360 -keysize 2048
È anche possibile disabilitare SSL per gli endpoint di origine o di destinazione se non implementano SSL. Usare i flag --disable-source-tls o --disable-target-tls:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password> --disable-source-tls true --disable-target-tls true
Nota
Assicurarsi che l'applicazione client usi lo stesso archivio chiavi e la stessa password di quelli usati per il proxy a doppia scrittura durante la creazione di connessioni SSL al database tramite il proxy.
Configurare le credenziali e la porta
Per impostazione predefinita, le credenziali di origine verranno passate dall'app client. Il proxy userà le credenziali per stabilire connessioni ai cluster di origine e di destinazione. Come accennato in precedenza, questo processo presuppone che le credenziali di origine e di destinazione siano uguali. Se necessario, è possibile specificare un nome utente e una password diversi per l'endpoint Cassandra di destinazione separatamente all'avvio del proxy:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Se non vengono specificate, le porte di origine e di destinazione verranno impostate sul valore predefinito 9042. Se la destinazione o l'endpoint Cassandra di origine viene eseguito su una porta diversa, è possibile usare --source-port o --target-port per specificare un numero di porta diverso:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar localhost <target-server> --source-port 9042 --target-port 10350 --proxy-jks-file <path to JKS file> --proxy-jks-password <keystore password> --target-username <username> --target-password <password>
Distribuire il proxy in modalità remota
In alcuni casi si potrebbe decidere di non installare il proxy nei nodi del cluster, in quanto si preferisce installarlo in un computer separato. In tale scenario è necessario specificare l'indirizzo IP per <source-server>:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar <source-server> <destination-server>
Avviso
Se si preferisce eseguire il proxy in remoto in un computer separato (anziché eseguirlo in tutti i nodi del cluster Apache Cassandra di origine), è consigliabile distribuire il proxy nello stesso numero di computer presenti nel cluster e configurare una sostituzione per i relativi indirizzi IP in system.peer usando la configurazione nel proxy indicato qui. In caso contrario, può influire sulle prestazioni mentre si verifica la migrazione in tempo reale, perché il driver client non sarà in grado di aprire connessioni a tutti i nodi all'interno del cluster.
Consentire zero modifiche al codice dell'applicazione
Per impostazione predefinita, il proxy è in ascolto sulla porta 29042. Il codice dell'applicazione deve essere modificato in modo che punti a questa porta. Tuttavia, è possibile modificare la porta su cui il proxy è in ascolto. Questa operazione potrebbe essere necessaria per eliminare le modifiche al codice a livello dell'applicazione tramite:
- L'esecuzione del server Cassandra di origine su una porta diversa.
- L'esecuzione del proxy sulla porta Cassandra standard 9042.
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042
Nota
L'installazione del proxy nei nodi del cluster non richiede il riavvio dei nodi. Tuttavia, se sono presenti molti client dell'applicazione e si preferisce che il proxy sia in esecuzione sulla porta Cassandra standard 9042 per eliminare eventuali modifiche al codice a livello dell'applicazione, è necessario modificare la porta predefinita di Apache Cassandra. È quindi necessario riavviare i nodi nel cluster e configurare la porta di origine come nuova porta definita per il cluster Cassandra di origine.
Nell'esempio seguente il cluster Cassandra di origine viene modificato per l'esecuzione sulla porta 3074 e il cluster viene avviato sulla porta 9042:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --proxy-port 9042 --source-port 3074
Forzare i protocolli
Il proxy dispone di funzionalità per forzare i protocolli, un'operazione che potrebbe essere necessaria se l'endpoint di origine è più avanzato di quello di destinazione o se non è altrimenti supportato. In tal caso, è possibile specificare --protocol-version e --cql-version per forzare il protocollo e rispettare l'endpoint di destinazione:
java -jar target/cassandra-proxy-1.0-SNAPSHOT-fat.jar source-server destination-server --protocol-version 4 --cql-version 3.11
Una volta che il proxy a doppia scrittura è in esecuzione, sarà necessario modificare la porta nel client dell'applicazione e riavviare. In alternativa, modificare la porta Cassandra e riavviare il cluster se si è scelto tale approccio. Il proxy avvierà quindi l'inoltro delle scritture all'endpoint di destinazione. Vedere le informazioni su monitoraggio e metriche disponibili nello strumento proxy.
Eseguire il caricamento dei dati cronologici
Per caricare i dati, creare un notebook Scala nell'account Azure Databricks. Sostituire le configurazioni Cassandra di origine e di destinazione con le credenziali corrispondenti e sostituire i keyspace e le tabelle di origine e di destinazione. In base alle esigenze, aggiungere altre variabili per ogni tabella all'esempio seguente e quindi procedere con l'esecuzione. Dopo che l'applicazione inizia a inviare richieste al proxy a doppia scrittura, è possibile eseguire la migrazione dei dati cronologici.
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//set timestamp to ensure it is before read job starts
val timestamp: Long = System.currentTimeMillis / 1000
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.option("writetime", timestamp)
.mode(SaveMode.Append)
.save
Nota
Nell'esempio scala precedente si noterà che timestamp è impostato sull'ora corrente prima di eseguire la lettura di tutti i dati nella tabella di origine. Successivamente, writetime viene impostato su questo timestamp retrodatato. In questo modo, i record scritti dal caricamento dei dati cronologici nell'endpoint di destinazione non possono sovrascrivere gli aggiornamenti con un timestamp successivo provenienti dal proxy a doppia scrittura mentre è in corso la lettura dei dati cronologici.
Importante
Se, per qualsiasi motivo, è necessario mantenere timestamp esatti, è consigliabile adottare un approccio alla migrazione dei dati cronologici che mantiene i timestamp, come illustrato in questo esempio. Il file JAR delle dipendenze nell'esempio contiene anche il connettore Spark, quindi non è necessario installare l'assembly del connettore Spark indicato nei prerequisiti precedenti, in quanto se sono entrambi installati nel cluster Spark si verificheranno conflitti.
Convalidare l'origine e la destinazione
Al termine del caricamento dei dati cronologici, i database devono essere sincronizzati e pronti per il cutover. Tuttavia, è consigliabile convalidare l'origine e la destinazione per assicurarsi che corrispondano prima di procedere al cutover.
Nota
Se è stato usato l'esempio cassandra migrator indicato in precedenza per conservare writetime, è possibile convalidare la migrazione confrontando le righe nell'origine e nella destinazione in base a determinate tolleranze.