Esercitazione: indicizzare i BLOB JSON annidati da Archiviazione di Azure con le API REST
Azure AI Search consente di indicizzare i documenti e le matrici JSON in Archiviazione BLOB di Azure usando un indicizzatore in grado di leggere dati semistrutturati. I dati semistrutturati contengono tag o contrassegni che separano il contenuto all'interno dei dati, Si differenziano dai dati non strutturati, che devono essere completamente indicizzati, e dai dati strutturati formalmente in base a un modello di dati, ad esempio uno schema di database relazionale, che può essere indicizzato campo per campo.
Questa esercitazione illustra come indicizzare matrici JSON annidate. Usa un client REST e le API REST per la ricerca per eseguire le attività seguenti:
- Configurare dati di esempio e configurare un'origine dati
azureblob - Creare un indice di Azure AI Search in cui includere contenuto ricercabile
- Creare ed eseguire un indicizzatore per leggere il contenitore ed estrarre contenuto ricercabile
- Eseguire una ricerca nell'indice che appena creato
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Prerequisiti
Visual Studio Code con un client REST.
Azure AI Search. Creare o trovare una risorsa di Azure AI Search esistente nella sottoscrizione corrente.
Nota
È possibile usare il servizio gratuito per questa esercitazione. Un servizio di ricerca gratuito consente di usare solo tre indici, tre indicizzatori e tre origini dati. Questa esercitazione crea un elemento per ogni tipo. Prima di iniziare, assicurarsi che lo spazio nel servizio sia sufficiente per accettare le nuove risorse.
Scaricare i file
Scaricare un file ZIP del repository di dati di esempio ed estrarre i contenuti. Procedura
I dati di esempio sono un singolo file JSON contenente una matrice JSON e 1.521 elementi JSON annidati. I dati di esempio provengono da NY Philharmonic Performance History su Kaggle. È stato scelto un file JSON per rimanere al di sotto dei limiti di archiviazione del livello gratuito.
Ecco il primo JSON annidato nel file. Il resto del file include altre 1.520 istanze di concerti.
{
"id": "7358870b-65c8-43d5-ab56-514bde52db88-0.1",
"programID": "11640",
"orchestra": "New York Philharmonic",
"season": "2011-12",
"concerts": [
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-07T04:00:00Z",
"Time": "7:30PM"
},
{
"eventType": "Non-Subscription",
"Location": "Manhattan, NY",
"Venue": "Avery Fisher Hall",
"Date": "2011-09-08T04:00:00Z",
"Time": "7:30PM"
}
],
"works": [
{
"ID": "5733*",
"composerName": "Bernstein, Leonard",
"workTitle": "WEST SIDE STORY (WITH FILM)",
"conductorName": "Newman, David",
"soloists": []
},
{
"ID": "0*",
"interval": "Intermission",
"soloists": []
}
]
}
Caricare i dati di esempio in Archiviazione di Azure
In Archiviazione di Azure, creare un nuovo contenitore e assegnargli il nome ny-philharmonic-free.
Ottenere una stringa di connessione di archiviazione in modo da poter formulare una connessione in Azure AI Search.
A sinistra, selezionare Chiavi di accesso.
Copiare la stringa di connessione per la chiave uno o la chiave due. La stringa di connessione è simile all'esempio seguente:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
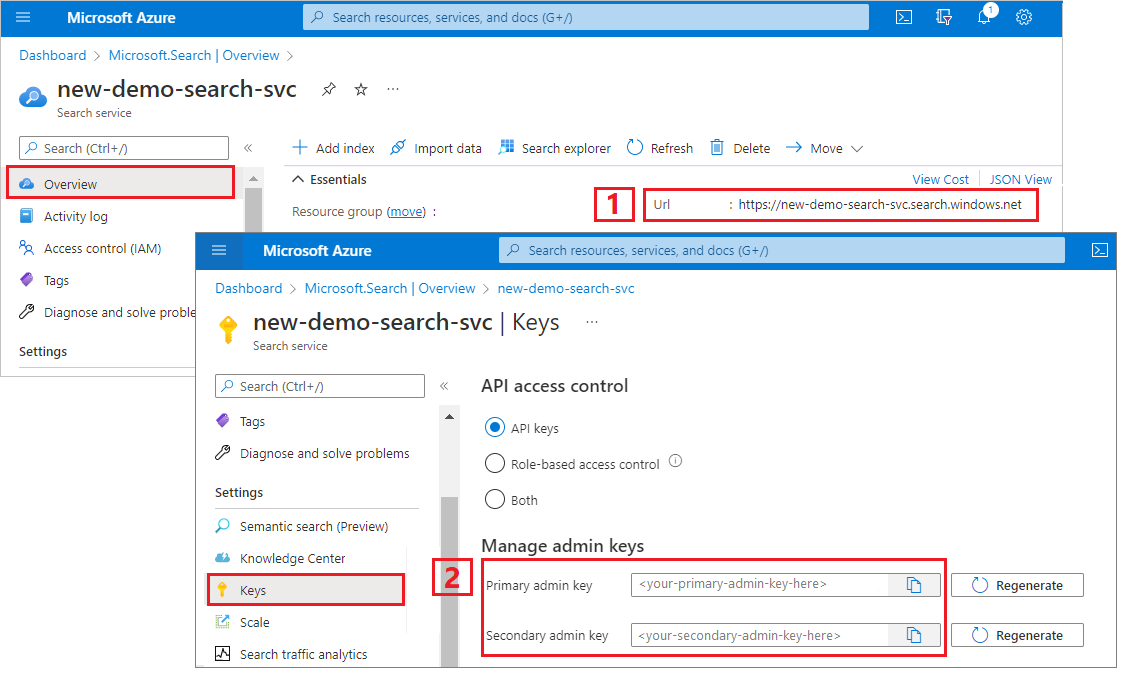
Copiare l'URL del servizio di ricerca e la chiave API
Per questa esercitazione, le connessioni ad Azure AI Search richiedono un endpoint e una chiave API. È possibile ottenere questi valori dal portale di Azure.
Accedere al portale di Azure, passare alla pagina Panoramica del servizio di ricerca e quindi copiare l'URL. Un endpoint di esempio potrebbe essere simile a
https://mydemo.search.windows.net.In Impostazioni>Chiavi, copiare una chiave amministratore. Le chiavi amministratore vengono usate per aggiungere, modificare ed eliminare oggetti. Sono disponibili due chiavi amministratore intercambiabili. Copiarne una.
Configurare il file REST
Avviare Visual Studio Code e creare un nuovo file
Specificare i valori per le variabili usate nella richiesta:
@baseUrl = PUT-YOUR-SEARCH-SERVICE-ENDPOINT-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE @storageConnection = PUT-YOUR-STORAGE-CONNECTION-STRING-HERE @blobContainer = PUT-YOUR-CONTAINER-NAME-HERESalvare il file usando un'estensione
.resto.http.
Per informazioni sul client REST, vedere Avvio rapido: ricerca di testo tramite REST.
Creare un'origine dati
Creare un'origine dati (REST) crea una connessione all'origine dati che specifica i dati da indicizzare.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Inviare la richiesta. La risposta dovrebbe essere simile alla seguente:
HTTP/1.1 201 Created
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
ETag: "0x8DC43A5FDB8448F"
Location: https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net:443/datasources('ny-philharmonic-ds')?api-version=2024-07-01
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: 7ca53f73-1054-4959-bc1f-616148a9c74a
elapsed-time: 111
Date: Wed, 13 Mar 2024 21:38:58 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/$metadata#datasources/$entity",
"@odata.etag": "\"0x8DC43A5FDB8448F\"",
"name": "ny-philharmonic-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": null
},
"container": {
"name": "ny-philharmonic-free",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null,
"encryptionKey": null
}
Creare un indice
Creare un indice (REST) crea un indice di ricerca nel servizio di ricerca. Un indice specifica tutti i parametri e i relativi attributi.
Per i JSON annidati, i campi dell'indice devono essere identici ai campi di origine. Attualmente, Azure AI Search non supporta i mapping dei campi ai JSON annidati. Per questo motivo, deve esserci corrispondenza esatta tra i nomi dei campi e i tipi di dati. L'indice seguente è allineato agli elementi JSON nel contenuto non elaborato.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "ny-philharmonic-index",
"fields": [
{"name": "programID", "type": "Edm.String", "key": true, "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "orchestra", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{"name": "season", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "facetable": true, "sortable": true},
{ "name": "concerts", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "eventType", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "Location", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Venue", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Date", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "Time", "type": "Edm.String", "searchable": false, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
},
{ "name": "works", "type": "Collection(Edm.ComplexType)",
"fields": [
{ "name": "ID", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": false, "sortable": false, "facetable": false},
{ "name": "composerName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "workTitle", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "conductorName", "type": "Edm.String", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true },
{ "name": "soloists", "type": "Collection(Edm.String)", "searchable": true, "retrievable": true, "filterable": true, "sortable": false, "facetable": true }
]
}
]
}
Punti principali:
Non è possibile usare i mapping dei campi per riconciliare le differenze nei nomi dei campi o nei tipi di dati. Questo schema di indice è progettato per eseguire il mirroring del contenuto non elaborato.
I JSON annidati vengono modellati come
Collection(Edm.ComplextType). Nel contenuto non elaborato, esistono più concerti per ogni stagione e più opere per ogni concerto. Per supportare questa struttura, usare le raccolte per tipi complessi.Nel contenuto non elaborato,
DateeTimesono stringhe, quindi anche i tipi di dati corrispondenti nell'indice sono stringhe.
Creare ed eseguire un indicizzatore
Creare un indicizzatore crea un indicizzatore nel servizio di ricerca. Un indicizzatore si connette all'origine dati, ai carichi e ai dati dell'indice, oltre a fornire facoltativamente una pianificazione per l'automatizzazione dell'aggiornamento dei dati.
La configurazione dell'indicizzatore include la modalità di analisi jsonArray e un oggetto documentRoot.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name" : "ny-philharmonic-indexer",
"dataSourceName" : "ny-philharmonic-ds",
"targetIndexName" : "ny-philharmonic-index",
"parameters" : {
"configuration" : {
"parsingMode" : "jsonArray", "documentRoot": "/programs"}
},
"fieldMappings" : [
]
}
Punti principali:
Il file di contenuto non elaborato contiene una matrice JSON (
"programs") con 1.526 strutture JSON annidate. ImpostareparsingModesujsonArrayper indicare all'indicizzatore che ogni BLOB contiene una matrice JSON. Poiché il codice JSON annidato si avvia a un livello inferiore, impostaredocumentRootsu/programs.L'indicizzatore viene eseguito per alcuni minuti. Attendere il completamento dell'esecuzione dell'indicizzatore prima di eseguire query.
Esegui query
È possibile iniziare a eseguire ricerche subito dopo aver caricato il primo documento.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"count": true
}
Inviare la richiesta. Si tratta di una query di ricerca full-text non specificata che restituisce tutti i campi contrassegnati come recuperabili nell'indice, insieme al numero di documenti. La risposta dovrebbe essere simile alla seguente:
HTTP/1.1 200 OK
Transfer-Encoding: chunked
Content-Type: application/json; odata.metadata=minimal; odata.streaming=true; charset=utf-8
Content-Encoding: gzip
Vary: Accept-Encoding
Server: Microsoft-IIS/10.0
Strict-Transport-Security: max-age=2592000, max-age=15724800; includeSubDomains
Preference-Applied: odata.include-annotations="*"
OData-Version: 4.0
request-id: a95c4021-f7b4-450b-ba55-596e59ecb6ec
elapsed-time: 106
Date: Wed, 13 Mar 2024 22:09:59 GMT
Connection: close
{
"@odata.context": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes('ny-philharmonic-index')/$metadata#docs(*)",
"@odata.count": 1521,
"@search.nextPageParameters": {
"search": "*",
"count": true,
"skip": 50
},
"value": [
],
"@odata.nextLink": "https://<YOUR-SEARCH-SERVICE-NAME>.search.windows.net/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01"
}
Aggiungere un parametro search per la ricerca in una stringa. Aggiungere un parametro select per limitare i risultati a un minor numero di campi. Aggiungere un oggetto filter per restringere ulteriormente la ricerca.
### Query the index
POST {{baseUrl}}/indexes/ny-philharmonic-index/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "puccini",
"count": true,
"select": "season, concerts/Date, works/composerName, works/workTitle",
"filter": "season gt '2015-16'"
}
Nella risposta vengono restituiti due documenti.
Per quanto riguarda i filtri, è anche possibile usare gli operatori logici (and, or e not) e gli operatori di confronto (eq, ne, gt, lt, ge e le). Per i confronti tra stringhe viene fatta distinzione tra maiuscole e minuscole. Per altre informazioni ed esempi, vedere Creare una query.
Nota
Il parametro $filter funziona solo nei campi contrassegnati come filtrabili al momento della creazione dell'indice.
Reimpostare ed eseguire di nuovo
Gli indicizzatori possono essere reimpostati, cancellando la cronologia di esecuzione, consentendo una riesecuzione completa. Le richieste GET seguenti sono per la reimpostazione, seguite da una riesecuzione.
### Reset the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/reset?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Run the indexer
POST {{baseUrl}}/indexers/ny-philharmonic-indexer/run?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
### Check indexer status
GET {{baseUrl}}/indexers/ny-philharmonic-indexer/status?api-version=2024-07-01 HTTP/1.1
api-key: {{apiKey}}
Pulire le risorse
Quando si lavora nella propria sottoscrizione, alla fine di un progetto è opportuno rimuovere le risorse che non sono più necessarie. Le risorse che rimangono in esecuzione hanno un costo. È possibile eliminare risorse singole oppure gruppi di risorse per eliminare l'intero set di risorse.
È possibile usare il portale per eliminare indici, indicizzatori e origini dati.
Passaggi successivi
Dopo aver acquisito familiarità con i concetti di base dell'indicizzazione BLOB di Azure, si esaminerà in dettaglio la configurazione dell'indicizzatore per i BLOB JSON in Archiviazione di Azure.