Configurare MPI per HPC
Si applica a: ✔️ macchine virtuali Linux ✔️ macchine virtuali Windows ✔️ set di scalabilità flessibili ✔️ set di scalabilità uniformi
Message Passing Interface (MPI) è una libreria aperta e uno standard de facto per la parallelizzazione della memoria distribuita. Si utilizza comunemente in molti carichi di lavoro HPC. I carichi di lavoro HPC nelle VM con supporto RDMA serie HB e serie N possono usare MPI per comunicare tramite la rete InfiniBand a bassa latenza e larghezza di banda elevata.
- Le dimensioni delle macchine virtuali abilitate per SR-IOV in Azure consentono l'uso di quasi qualsiasi tipo di MPI con Mellanox OFED.
- Nelle VM non abilitate per SR-IOV, le implementazioni MPI supportate usano l'interfaccia Microsoft Network Direct (ND) per comunicare tra macchine virtuali. Di conseguenza, sono supportate solo le versioni Microsoft MPI (MS-MPI) 2012 R2 o successive e Intel MPI 5.x. Le versioni successive (2017, 2018) della libreria di runtime MPI Intel potrebbero non essere compatibili con i driver RDMA di Azure.
Per le VM con supporto RDMA abilitate a SR-IOV, sono idonee le immagini di VM Ubuntu-HPC e le immagini di VM AlmaLinux-HPC. Queste immagini di macchina virtuale sono ottimizzate e precaricate con i driver OFED per RDMA, varie librerie MPI di uso comune e pacchetti di elaborazione scientifica e sono il modo più semplice per iniziare.
Anche se gli esempi indicati riguardano RHEL, i passaggi sono generici e possono essere usati per qualsiasi sistema operativo Linux compatibile, ad esempio Ubuntu (18.04, 20.04, 22.04) e SLES (12 SP4 e 15 SP4). Altri esempi per la configurazione di altre implementazioni MPI in altre distribuzioni sono disponibili nel repository azhpc-images.
Nota
L'esecuzione di processi MPI in macchine virtuali abilitate a SR-IOV con determinate librerie MPI (ad esempio MPI della piattaforma) potrebbe richiedere la configurazione di chiavi di partizione (p-keys) in un tenant per l'isolamento e la sicurezza. Seguire la procedura descritta nella sezione Individuare le chiavi di partizione per informazioni dettagliate su come determinare i valori p-key e impostarli correttamente per un processo MPI con la libreria MPI indicata.
Nota
I frammenti di codice riportati di seguito sono esempi. È consigliabile usare le versioni stabili più recenti dei pacchetti o fare riferimento al repository azhpc-images.
Scelta della libreria MPI
Se un'applicazione HPC consiglia una specifica libreria MPI, provare prima di tutto tale versione. Se si ha flessibilità per quanto riguarda la scelta della libreria MPI e per ottenere prestazioni ottimali, provare HPC-X. Nel complesso, MPI HPC-X offre prestazioni ottimali utilizzando il framework UCX per l'interfaccia InfiniBand, inoltre sfrutta tutte le funzionalità hardware e software InfiniBand di Mellanox. HPC-X e OpenMPI sono compatibili con ABI, pertanto è possibile eseguire dinamicamente un'applicazione HPC con HPC-X compilata con OpenMPI. Analogamente, Intel MPI, MVAPICH e MPICH supportano ABI.
La figura seguente illustra l'architettura per le librerie MPI più diffuse.
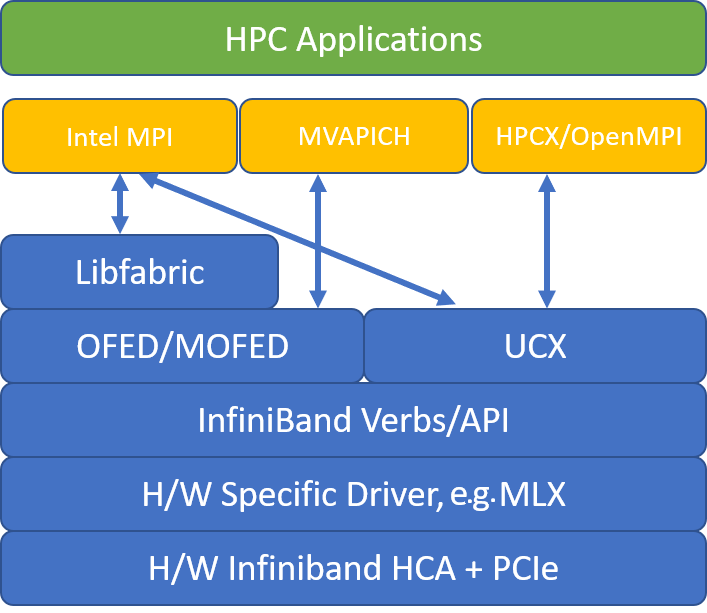
HPC-X
Il toolkit del software HPC-X contiene UCX e HCOLL e può essere compilato con UCX.
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.windows.net/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
Il comando seguente illustra alcuni argomenti mpirun consigliati per HPC-X e OpenMPI.
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
dove:
| Parametro | Descrizione |
|---|---|
NPROCS |
Specifica il numero di processi MPI. Ad esempio: -n 16. |
$HOSTFILE |
Specifica un file contenente il nome host o l'indirizzo IP, per indicare il percorso nel quale vengono eseguiti i processi MPI. Ad esempio: --hostfile hosts. |
$NUMBER_PROCESSES_PER_NUMA |
Specifica il numero di processi MPI eseguiti in ogni dominio NUMA. Per specificare, ad esempio, quattro processi MPI per NUMA, usare --map-by ppr:4:numa:pe=1. |
$NUMBER_THREADS_PER_PROCESS |
Specifica il numero di thread per ogni processo MPI. Per specificare, ad esempio, un processo MPI e quattro thread per NUMA, usare --map-by ppr:1:numa:pe=4. |
-report-bindings |
Stampa il mapping tra processi MPI e core, che risulta utile per verificare che l'aggiunta dei processi MPI sia corretta. |
$MPI_EXECUTABLE |
Specifica il collegamento creato dall'eseguibile MPI nelle librerie MPI. I wrapper del compilatore MPI eseguono questa operazione automaticamente. Ad esempio, mpicc o mpif90. |
Un esempio di esecuzione del microbenchmark di latenza OSU è il seguente:
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
Ottimizzazione dei collettivi MPI
Le primitive di comunicazione collettiva MPI offrono un modo flessibile e dinamico per implementare le operazioni di comunicazione di gruppo. Esse sono ampiamente usate in diverse applicazioni scientifiche parallele e hanno un impatto significativo sulle prestazioni complessive dell'applicazione. Vedere l'articolo TechCommunity per informazioni dettagliate sui parametri di configurazione per ottimizzare le prestazioni delle comunicazioni collettive usando HPC-X e la libreria HCOLL per la comunicazione collettiva.
Ad esempio, se si sospetta che l'applicazione MPI strettamente associata stia eseguendo una quantità eccessiva di comunicazioni collettive, si potrebbe provare ad abilitare i collettivi gerarchici (HCOLL). Per abilitare tali funzionalità, usare i parametri seguenti.
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
Nota
Con HPC-X 2.7.4+, potrebbe essere necessario passare esplicitamente a LD_LIBRARY_PATH se la versione UCX in MOFED e quella in HPC-X sono diverse.
OpenMPI
Installare UCX come descritto in precedenza. HCOLL fa parte del toolkit software HPC-X e non richiede un'installazione speciale.
OpenMPI può essere installato dai pacchetti disponibili nel repository.
sudo yum install –y openmpi
È consigliabile creare una versione stabile più recente di OpenMPI con UCX.
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
Per ottenere prestazioni ottimali, eseguire OpenMPI con ucx e hcoll. Vedere anche l'esempio con HPC-X.
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
Controllare la chiave di partizione, come indicato in precedenza.
Intel MPI
Scaricare la versione scelta di Intel MPI. La versione Intel MPI 2019 è stata spostata dal framework Open Fabrics Alliance (OFA) al framework di Open Fabric Interfaces (OFI) e attualmente supporta libfabric. Sono disponibili due provider per il supporto InfiniBand: mlx e verbs. Modificare la variabile di ambiente I_MPI_FABRICS in base alla versione.
- Intel MPI 2019 e 2021: usare
I_MPI_FABRICS=shm:ofi,I_MPI_OFI_PROVIDER=mlx. Il providermlxusa UCX. È stato rilevato che l'uso dei verbi è instabile e meno efficiente. Per maggiori dettagli, vedere l'articolo TechCommunity. - Intel MPI 2018: usare
I_MPI_FABRICS=shm:ofa - Intel MPI 2016: usare
I_MPI_DAPL_PROVIDER=ofa-v2-ib0
Si riportano alcuni argomenti mpirun suggeriti per Intel MPI 2019 aggiornamento 5+.
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
dove:
| Parametro | Descrizione |
|---|---|
FI_PROVIDER |
Specifica il provider libfabric da usare, che influirà sull'API, sul protocollo e sulla rete usata. verbi è un'altra opzione, ma generalmente mlx offre prestazioni migliori. |
I_MPI_DEBUG |
Specifica il livello di output di debug aggiuntivo, che può fornire informazioni dettagliate sulla posizione in cui vengono aggiunti i processi e su quale protocollo e rete vengono usati. |
I_MPI_PIN_DOMAIN |
Specifica il modo in cui si vogliono aggiungere i processi. È, ad esempio, possibile aggiungerli a core, socket o domini NUMA. In questo esempio questa variabile di ambiente viene impostata su numa; ciò significa che i processi saranno aggiunti ai domini del nodo NUMA. |
Ottimizzazione dei collettivi MPI
Sono disponibili altre opzioni che è possibile provare, soprattutto se le operazioni collettive utilizzano tempo notevole. Intel MPI 2019 update5+ supporta il provider mlx e usa il framework UCX per comunicare con InfiniBand. Supporta anche HCOLL.
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
Macchine virtuali non SR-IOV
Per le macchine virtuali non SR-IOV, un esempio di download del runtime 5.x nella versione di valutazione gratuita è il seguente:
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
Per la procedura di installazione, vedere Intel MPI Library installation guide (Guida all'installazione di Intel MPI Library). Facoltativamente, si potrebbe abilitare ptrace per i processi non di debugger, non radice (necessari per le versioni più recenti di Intel MPI).
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
Per le versioni delle immagini delle VM SUSE Linux Enterprise Server - SLES 12 SP3 per HPC, SLES 12 SP3 per HPC (Premium), SLES 12 SP1 per HPC, SLES 12 SP1 per HPC (Premium), SLES 12 SP4 e SLES 15, i driver RDMA vengono installati e i pacchetti Intel MPI vengono distribuiti nella macchina virtuale. Installare Intel MPI eseguendo il comando seguente:
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
Si riporta di seguito un esempio di compilazione MVAPICH2. Potrebbero essere disponibili versioni più recenti di quelle usate di seguito.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
Un esempio di esecuzione del microbenchmark di latenza OSU è il seguente:
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
L'elenco seguente contiene alcuni argomenti consigliati di mpirun.
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
dove:
| Parametro | Descrizione |
|---|---|
MV2_CPU_BINDING_POLICY |
Specifica i criteri di associazione da usare, che influiscono sull'aggiunta dei processi agli ID core. In questo caso, si specifica scatter, in modo tale che i processi vengano distribuiti uniformemente tra i domini NUMA. |
MV2_CPU_BINDING_LEVEL |
Specifica la posizione in cui aggiungere i processi. In tal caso, impostarlo su numanode e i processi saranno aggiunti alle unità di domini NUMA. |
MV2_SHOW_CPU_BINDING |
Specifica se si vogliono ottenere informazioni di debug sulla posizione in cui sono stati aggiunti i processi. |
MV2_SHOW_HCA_BINDING |
Specifica se si vogliono ottenere informazioni di debug sulla scheda del canale host usata da ogni processo. |
Platform MPI
Installare i pacchetti necessari per Platform MPI Community Edition.
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
Seguire il processo di installazione.
MPICH
Installare UCX come descritto in precedenza. Compilare MPICH.
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
Eseguire MPICH.
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
Controllare la chiave di partizione, come indicato in precedenza.
Benchmark MPI OSU
Scaricare i benchmark MPI OSU e untar.
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar –xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
Compilare i benchmark usando una particolare libreria MPI:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
I benchmark MPI si trovano nella cartella mpi/.
Individuare le chiavi di partizione
Individuare le chiavi di partizione (p-keys) per comunicare con altre macchine virtuali all'interno dello stesso tenant (set di disponibilità o set di scalabilità di macchine virtuali).
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
La più grande delle due è la chiave del tenant che deve essere usata con MPI. Esempio: se di seguito sono riportate delle p-keys, 0x800b deve essere usato con MPI.
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
Le interfacce note sono denominate mlx5_ib* all'interno delle immagini di macchine virtuali HPC.
Finché il tenant (set di disponibilità o set di scalabilità di macchine virtuali) esiste, le PKEY restano invariate. Ciò è vero anche quando i nodi vengono aggiunti/eliminati. I nuovi tenant ottengono diverse PKEY.
Configurare i limiti utente per MPI
Configurare i limiti utente per MPI.
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
Configurare le chiavi SSH per MPI
Configurare le chiavi SSH per i tipi MPI che lo richiedono.
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
La sintassi precedente presuppone una home directory condivisa, altrimenti la directory .ssh deve essere copiata in ogni nodo.
Passaggi successivi
- Informazioni sulle macchine virtuali abilitate a InfiniBand serie HB eserie N.
- Esaminare la panoramica della serie HBv3 e la panoramica della serie HC.
- Leggere Posizionamento ottimale del processo MPI per le macchine virtuali serie HB.
- Per informazioni sugli annunci, sugli esempi di carico di lavoro HPC e sui risultati delle prestazioni più recenti, vedere i Blog della community tecnica di Calcolo di Azure.
- Per un quadro generale sull'architettura per l'esecuzione di carichi di lavoro HPC, vedere HPC (High Performance Computing) in Azure.