Riprogettare la topologia di ricerca aziendale per requisiti di prestazioni specifici in SharePoint
SI APPLICA A: 2013 2016 2019 Subscription Edition
2013 2016 2019 Subscription Edition  SharePoint in Microsoft 365
SharePoint in Microsoft 365
Se l'ambiente di ricerca prevede requisiti di prestazioni specifici non soddisfatti seguendo le indicazioni contenute in Pianificare l'architettura di ricerca a livello aziendale in SharePoint Server 2016, implementare la scalabilità della topologia dell'architettura di ricerca a livello aziendale:
Riprogettare la topologia (questo articolo)
Implementare la topologia riprogettata (Gestire la topologia di ricerca in SharePoint Server)
Si ha familiarità con i componenti del sistema di ricerca in SharePoint Server 2016 e con come interagiscono? Leggendo Panoramica dell'architettura di ricerca in SharePoint Server e architetture di ricerca per SharePoint Server 2016 (o Architetture di ricerca per SharePoint Server 2013) prima di iniziare, si acquisirà familiarità con l'architettura di ricerca, i componenti di ricerca, i database di ricerca e la topologia di ricerca.
In questo articolo verrà descritto in modo dettagliato come riprogettare la topologia di ricerca per soddisfare requisiti di prestazioni specifici:
Passaggio 1: quali sono i requisiti di prestazioni specifici?
Passaggio 2: per quali componenti di ricerca deve essere implementata la scalabilità?
Passaggio 3: scegliere se eseguire i server fisicamente o virtualmente
Passaggio 4: quali server devono ospitare ogni componente o database di ricerca specifico?
Passaggio 5: quali sono i requisiti hardware di cui tenere conto?
Dopo aver effettuato questi passaggi, si avranno le seguenti informazioni:
Il numero di ciascun tipo di componente e database di ricerca richiesto dalla topologia.
In quali server applicazioni e server di database distribuire ogni componente di ricerca.
Quali risorse hardware sono richieste da ogni server applicazioni e server di database.
Passaggio 1: quali sono i requisiti di prestazioni specifici?
Verificare di conoscere le esigenze aziendali alla base dei requisiti di prestazioni specifici. Ad esempio, la ricerca di notizie e dati finanziari richiedono dati aggiornati indicizzati quasi in tempo reale, mentre i servizi di supporto per controversie legali richiedono l'inserimento di batch di dati che vengono indicizzati una sola volta. Esprimere i requisiti di prestazioni in uno o più dei seguenti modi:
Numero di elementi indicizzati.
Numero di elementi di cui la soluzione di ricerca deve eseguire la ricerca per indicizzazione al secondo e relativa latenza.
Numero di query che devono essere gestite al secondo dalla soluzione di ricerca e relativa latenza.
Oltre a questi requisiti di prestazioni, è possibile che l'ambiente presenti requisiti per la pertinenza dei risultati delle query e per la ridondanza della topologia di ricerca. In alcune situazioni è possibile che non siano presenti requisiti di prestazioni specifici, ma che venga identificato un collo di bottiglia nell'architettura di ricerca che può influire sulle prestazioni. Verrà trattato anche questo caso.
Passaggio 2: per quali componenti di ricerca deve essere implementata la scalabilità?
Per garantire prestazioni elevate o rimuovere un collo di bottiglia, è possibile aggiungere ulteriori componenti di ricerca oppure aggiungere ulteriori risorse ai server che ospitano i componenti di ricerca. L'aggiunta di ulteriori componenti di ricerca è nota come scalabilità orizzontale, mentre l'aggiunta di ulteriori risorse ai server è nota come scalabilità verticale. Per quali componenti di ricerca implementare la scalabilità orizzontale o per quali server implementare la scalabilità verticale dipende dalla metrica delle prestazioni da migliorare o dal collo di bottiglia da rimuovere. Ecco alcuni esempi:
Se l'ambiente richiede una frequenza di query maggiore e le risorse di CPU per l'indicizzazione costituiscono un collo di bottiglia, aggiungere un'altra replica di indice a ogni partizione dell'indice. In questo modo la ricerca riuscirà a gestire più query in parallelo.
Se le risorse di CPU per l'elaborazione del contenuto sottoposto a ricerca per indicizzazione costituiscono un collo di bottiglia, implementare la scalabilità orizzontale del numero di componenti di elaborazione del contenuto. È anche possibile implementare la scalabilità verticale dei componenti di elaborazione del contenuto eseguendoli in server con CPU in numero maggiore o più veloci. Entrambi i tipi di scalabilità comportano l'uso di più risorse di CPU per l'elaborazione del contenuto.
Se i componenti di analisi non completano le analisi in modo sufficientemente rapido, implementare la scalabilità verticale delle risorse di processore, delle operazioni di input/output al secondo su disco o della larghezza di banda di rete dei server che ospitano i componenti di analisi.
Si noti che non è supportata una scalabilità orizzontale illimitata del numero di componenti o database di ricerca. Esaminare i limiti massimi in Limiti relativi alla ricerca e rispettare tali limiti per garantire comunicazioni efficienti e tempestive tra i componenti e i database di ricerca. Se necessario, ridurre la capacità dell'architettura di ricerca riducendo il numero dei componenti di ricerca.
Le seguenti sezioni contengono linee guida per la scelta dei componenti o dei database di ricerca per cui implementare la scalabilità per soddisfare ogni requisito:
Come aumentare la frequenza di inserimento e il livello di aggiornamento dei risultati
Come ridurre la latenza delle query e aumentarne la velocità effettiva
Come rendere ridondanti i componenti e i database di ricerca
Come gestire più elementi nell'indice
Quando la quantità di elementi indicizzati aumenta mentre la frequenza di modifica degli elementi indicizzati resta invariata, aumentare la capacità della topologia di ricerca implementando la scalabilità orizzontale di questi componenti e database di ricerca:
| Componente o database di ricerca | Linee guida |
|---|---|
| Componente di indicizzazione | Usare una partizione di indice per ogni 20 milioni1 di elementi indicizzati. Ogni partizione contiene una o più repliche della partizione. Tutte le partizioni devono avere lo stesso numero di repliche. Un componente di indicizzazione rappresenta una replica di indice. Se pertanto si vogliono due repliche dell'indice, è necessario il doppio di componenti di indicizzazione rispetto alle partizioni di indice. Ad esempio, un indice ridondante con 80 milioni2 di elementi richiede quattro partizioni. Otto componenti di indicizzazione rappresentano le quattro partizioni quando si usano due repliche per ogni partizione. |
| Database di ricerca per indicizzazione | Usare un database di ricerca per indicizzazione per ogni 20 milioni di elementi nel corpo del contenuto. Ad esempio, un indice con 100 milioni di elementi richiede cinque database di ricerca per indicizzazione. Se l'incremento di elementi indicizzati implica una maggiore frequenza di ricerca per indicizzazione, sono necessarie anche più risorse di input/output al secondo per gestire i database di ricerca per indicizzazione. Se la frequenza della ricerca per indicizzazione è pari a un documento al secondo, il database di ricerca per indicizzazione richiede circa 10 operazioni di input/output al secondo. |
| Database dei collegamenti | Usare un database dei collegamenti per ogni 60 milioni di elementi nel corpo del contenuto. Ad esempio, un indice con 100 milioni di elementi richiede due database dei collegamenti. Se il contenuto aggiunto implica una maggiore frequenza di ricerca per indicizzazione, potrebbero essere necessarie più risorse di input/output al secondo per gestire i database dei collegamenti. |
| Database di report di analisi | Il numero di database di report analitici necessari dipende dal modo in cui l'ambiente di ricerca usa l'analisi e dalla frequenza. In generale, aggiungere un database di report di analisi quando le prestazioni di analisi iniziano a diminuire. Ad esempio, quando l'aggiornamento notturno del database inizia a richiedere più tempo. Ciò può verificarsi quando il database raggiunge una dimensione di 250 GB o 20 milioni di righe in totale o quando il numero di visualizzazioni al giorno raggiunge 500.000 elementi univoci. |
110 milioni di elementi con SharePoint Server 2013 o con SharePoint Server 2016 in esecuzione con meno risorse di archiviazione di 500 GB, 32 GB di RAM e otto core CPU.
240 milioni di elementi con SharePoint Server 2013 o SharePoint Server 2016 in esecuzione con meno risorse di archiviazione di 500 GB, 32 GB di RAM e otto core CPU.
Come aumentare la frequenza di inserimento e il livello di aggiornamento dei risultati
In alcune situazioni potrebbe essere necessario aumentare la frequenza di inserimento. Un esempio è se l'ambiente richiede risultati molto recenti e il volume di contenuto è vicino al limite massimo per l'elemento per l'architettura di ricerca o il contenuto cambia spesso. Il contenuto potrebbe cambiare spesso se gli utenti usavano per archiviare i file in un sito del team, ma ora archiviano i file in OneDrive mentre lavorano su di essi. La ricerca indicizza tutte le modifiche apportate dagli utenti ai file.
È utile comprendere quali sono i fattori che influiscono sulla velocità con cui il servizio di ricerca inserisce gli elementi:
Velocità con cui il servizio di ricerca può eseguire la ricerca per indicizzazione degli elementi. Questo dipende dai seguenti fattori:
Velocità della connessione tra i componenti di ricerca per indicizzazione e le origini contenuto.
Tipo e dimensioni medie degli elementi da sottoporre a ricerca per indicizzazione.
Prestazioni del computer SQL Server che ospita i database di ricerca per indicizzazione.
Quantità di CPU e di risorse di memoria dei componenti di ricerca per indicizzazione.
Entità dell'elaborazione del contenuto richiesta da ogni elemento prima dell'indicizzazione.
Numero di partizioni dell'indice. Un numero elevato di partizioni permette al servizio di ricerca di distribuire il carico dell'indicizzazione.
Ecco cosa fare:
Controllare il livello di aggiornamento dei risultati nella farm esaminando la distribuzione della data degli elementi sottoposti a ricerca per indicizzazione. Con il sito Web Amministrazione centrale SharePoint passare a Report di stato ricerca per indicizzazione e selezionare Aggiornamento ricerca per indicizzazione. Una distribuzione della data accettabile per la propria farm dipende dai requisiti aziendali. Ecco un esempio: se la pagina Aggiornamento ricerca per indicizzazione indica che sono necessarie quattro ore per indicizzare il 90% del contenuto mentre il proprio requisito è di 30 minuti, aumentare la frequenza di inserimento.
Nella pagina Aggiornamento ricerca per indicizzazione individuare in quale periodo del giorno i risultati non sono abbastanza aggiornati.
Seguire le linee guida per aumentare la velocità di inserimento in tali periodi di tempo.
Miglioramento del livello di aggiornamento di un'origine contenuto specifica
Controllare la pianificazione della ricerca per indicizzazione e identificare le origini contenuto sottoposte a ricerca per indicizzazione negli intervalli di tempo in cui il livello di aggiornamento è insufficiente. In caso di livello di aggiornamento insufficiente per un'origine contenuto specifica, considerare quanto segue:
Aumentare la velocità della connessione tra il server che ospita il componente di ricerca per indicizzazione e l'origine contenuto. La richiesta di larghezza di banda di rete per il componente di ricerca per indicizzazione dipende dalla frequenza della ricerca per indicizzazione, il download degli elementi dalle origini contenuto e il passaggio degli elementi al componente di elaborazione del contenuto.
Se l'origine contenuto è SharePoint, è possibile che la farm necessiti di più destinazioni di ricerca per indicizzazione dedicate. Per informazioni sulle destinazioni della ricerca per indicizzazione, vedere Gestire il carico di ricerca per indicizzazione (SharePoint Server 2010).
Migliorare le prestazioni del database del contenuto. Per informazioni, vedere Procedure consigliate per SQL Server in una server farm di SharePoint.
Aumento del numero di risorse di elaborazione per la ricerca per indicizzazione
Se il componente di ricerca per indicizzazione usa spesso il 100% delle risorse di processore, valutare l'opportunità di aggiungere un altro componente di ricerca per indicizzazione o ulteriori risorse di processore nei server che ospitano i componenti di ricerca per indicizzazione. La richiesta di risorse di processore dipende dalla frequenza di ricerca per indicizzazione, l'individuazione di collegamenti e la gestione della ricerca per indicizzazione. La ricerca per indicizzazione in genere è sufficientemente veloce con due componenti di ricerca per indicizzazione in architetture di ricerca quali le architetture di ricerca di esempio di piccole e medie dimensioni stimate da Microsoft. Le architetture di ricerca come quelle di dimensioni grandi e molto grandi di esempio potrebbero necessitare di più di due componenti di ricerca per indicizzazione.
Aumento del numero di risorse di elaborazione per il database di ricerca per indicizzazione
Controllare se i computer SQL Server che ospitano i database di ricerca per indicizzazione contengono risorse sufficienti. A tale scopo, leggere Procedure consigliate per SQL Server in una server farm di SharePoint.
Se tutti i database di ricerca per indicizzazione usano numerose risorse di processore, valutare l'opportunità di aggiungere ulteriori risorse di processore nel computer SQL Server che ospita i database o aggiungere un altro computer SQL Server con lo stesso numero di database di ricerca per indicizzazione dei computer SQL Server esistenti. Se ad esempio sono presenti due computer SQL Server ciascuno con tre database di ricerca per indicizzazione, aggiungerne un altro con tre database di ricerca per indicizzazione.
Se solo uno o alcuni database di ricerca per indicizzazione usano molte risorse del processore, ciò significa che il carico non è uniforme tra i database di ricerca per indicizzazione. Valutare la possibilità di bilanciare il contenuto tra tutti i database di ricerca per indicizzazione. Si noti che durante il ribilanciamento della ricerca viene sospesa la ricerca per indicizzazione, quindi i risultati sono meno aggiornati durante il ribilanciamento e fino a quando la ricerca per indicizzazione non ha raggiunto le modifiche apportate durante la pausa. È possibile attivare il ribilanciamento con il pulsante Bilanciamento nella pagina Database . In Amministrazione ricerca passare a Log di ricerca per indicizzazione e selezionare Database.
Aumento del numero di risorse di elaborazione e memoria per l'elaborazione del contenuto
Se il componente di elaborazione del contenuto usa fino a quasi il 100% delle risorse della CPU, valutare l'opportunità di aggiungere più componenti di elaborazione del contenuto o più risorse della CPU ai server che ospitano il componente di elaborazione del contenuto.
Se si nota che la memoria si riavvia spesso, valutare l'opportunità di aumentare la quantità di memoria nei server che ospitano i componenti di elaborazione del contenuto. 2 GB di memoria di lavoro per core di CPU è una buona soluzione.
Aumento del numero di partizioni di indice
Controllare l'attività di elaborazione del contenuto. A tale scopo, accedere ad Amministrazione ricerca, selezionare Report di stato ricerca per indicizzazione e quindi Attività di elaborazione del contenuto. Se l'indicizzazione è l'attività che richiede più tempo, valutare l'opportunità di suddividere l'indice in più partizioni. Un numero maggiore di partizioni permette al servizio di ricerca di distribuire il carico dell'indicizzazione.
Se si aggiungono altre partizioni in un'installazione in esecuzione, l'indice ripartiziona se stesso. La ripartizione dell'indice può richiedere diverse ore o giorni. Il tempo necessario dipende dallo stato della farm all'inizio della ripartizione.
Come ridurre la latenza delle query e aumentarne la velocità effettiva
Il numero di query al secondo gestite dal servizio di ricerca è noto come velocità effettiva delle query. La velocità effettiva delle query dipende dal tempo impiegato dal servizio di ricerca per elaborare una query e dal tempo di attesa di una query dovuto alla non disponibilità di una risorsa di elaborazione. La somma del tempo di elaborazione e del tempo di attesa è nota come latenza delle query. La riduzione della latenza delle query determina un aumento della velocità effettiva delle query. Per ridurre la latenza delle query, applicare una o entrambe le seguenti linee guida:
| Linee guida |
|---|
| Riduzione del tempo di elaborazione per le query |
| Riduzione del tempo di attesa per le query |
Riduzione del tempo di elaborazione per le query
Valutare l'opportunità di aggiungere ulteriori partizioni all'indice. Un numero maggiore di partizioni comporta un numero inferiore di elementi contenuti in ciascuna di esse. Con meno elementi, ogni partizione risponde più velocemente alle query. Un numero eccessivo di partizioni però non è una buona soluzione. Dal momento che il componente di elaborazione delle query deve unire le risposte di ciascuna partizione per produrre una risposta per una query, questa operazione richiede più tempo se l'indice contiene più partizioni. Tutte le partizioni devono avere lo stesso numero di repliche.
Quando si aggiungono altre partizioni in un'installazione in esecuzione, l'indice si ripartiziona automaticamente. La ripartizione dell'indice può richiedere diverse ore o giorni. Il tempo necessario dipende dallo stato della farm all'inizio della ripartizione.
Riduzione del tempo di attesa per le query
Prendere in considerazione queste azioni:
Aggiungere ulteriori repliche dell'indice. Quando si aggiungono più repliche, il servizio di ricerca distribuisce le query tra le repliche e le gestisce in parallelo. Un componente di indicizzazione rappresenta una replica di indice. Dal momento che tutte le partizioni devono avere lo stesso numero di repliche, aggiungere un componente di indicizzazione a ciascuna partizione dell'indice. Quando si aggiungono componenti di indicizzazione come repliche a partizioni esistenti in un'installazione in esecuzione, il servizio di ricerca effettua automaticamente il seeding delle nuove repliche con dati della partizione di indice. È possibile che trascorrano alcune ore prima che le nuove repliche siano operative.
Aggiungere ulteriore memoria nei server che ospitano i componenti di indicizzazione.
Nei server che ospitano i componenti di indicizzazione passare a una risorsa di archiviazione più veloce per l'indice, ad esempio un'unità SSD (Solid State Drive).
Aggiungere ulteriori risorse di processore nei server che ospitano i componenti di indicizzazione. In questo modo i componenti possono gestire più query al secondo. Se ad esempio il server ha una CPU da 2 GHz, un core può gestire:
Cinque query al secondo se l'indice contiene un milione di elementi.
Due query al secondo se l'indice contiene cinque milioni di elementi.
Una query al secondo se l'indice contiene 10 milioni di elementi.
Aggiungere ulteriori risorse di processore nei server che ospitano i componenti di elaborazione delle query. In questo modo i componenti possono gestire più query al secondo, soprattutto nel caso di query complesse e poco frequenti. La richiesta di risorse di processore per il componente di elaborazione delle query dipende dalla frequenza di query e dal numero di trasformazioni di query. Un componente di elaborazione delle query in genere necessita di un core di CPU per quattro query al secondo.
Come ridurre il tempo di elaborazione dell'analisi
L'elaborazione dell'analisi viene eseguita ogni notte. Il componente di elaborazione dell'analisi archivia dati intermedi nel server che ospita il componente e archivia i risultati dell'analisi nel database di report di analisi. Se un errore impedisce l'elaborazione dell'analisi, questo non incide sulla ricerca per indicizzazione dei documenti o sulla risposta alle query. La pertinenza dei risultati delle query però non sarà ottimale.
Prendere in considerazione queste azioni:
Se l'ambiente richiede una pertinenza ottimale per i risultati delle query e l'elaborazione dell'analisi non è sufficientemente veloce per soddisfare questo requisito, aggiungere ulteriori dischi (spindle) o dischi più veloci.
Se l'elaborazione dell'analisi inizia a richiedere più tempo del solito, aggiungere un database di report di analisi. È possibile osservare questo tipo di rallentamento quando il database raggiunge una dimensione di 250 GB o di 20 milioni di righe in totale oppure quando il numero di visualizzazioni al giorno raggiunge il valore di 500.000 elementi univoci.
Se l'elaborazione dell'analisi richiede più di 24 ore, aggiungere ulteriori componenti di elaborazione dell'analisi oppure aggiungere ulteriori risorse di processore nei server che ospitano i componenti di elaborazione dell'analisi. La richiesta di risorse di processore dipende dal numero di elementi contenuti nell'indice e dall'attività nel sito.
Se l'elaborazione dell'analisi non viene mai completata o si visualizzano avvisi relativi all'integrità per i dischi nei server che ospitano i componenti dell'analisi, aggiungere ulteriore spazio su disco nei server. Affinché il componente di analisi elabori più dati intermedi con una velocità maggiore, valutare l'opportunità di aggiungere altri componenti di elaborazione dell'analisi o altre risorse di processore nel server che ospita il componente di elaborazione dell'analisi.
Come rendere ridondanti i componenti e i database di ricerca
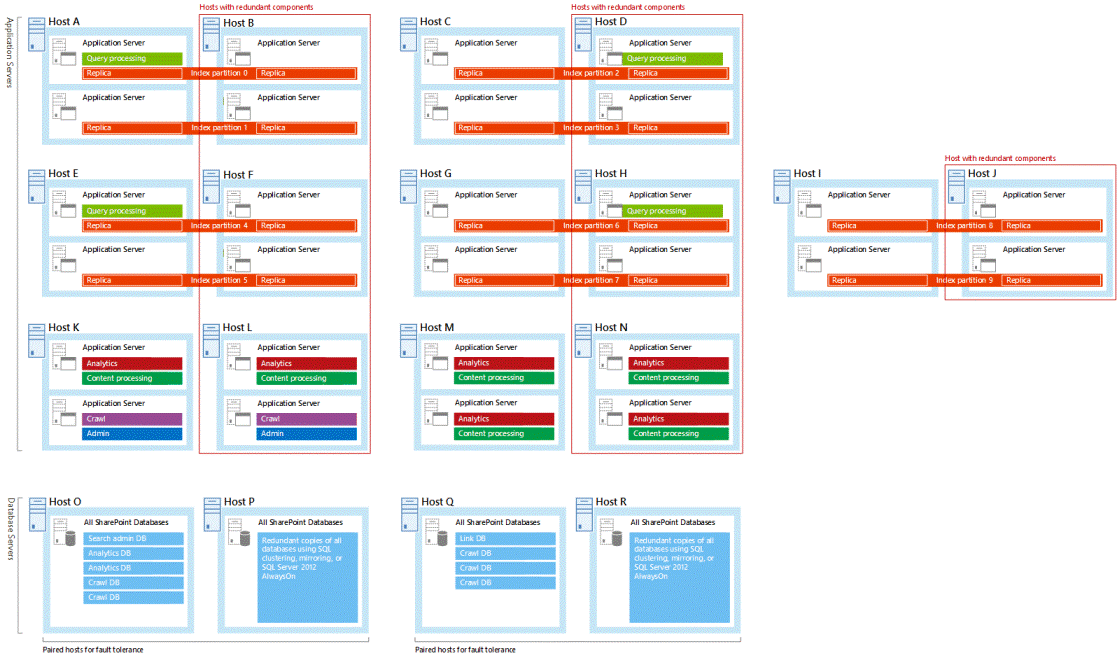
L'architettura di ricerca supporta la disponibilità elevata quando vengono ospitati componenti e database di ricerca ridondanti su domini separati. È consigliabile progettare la topologia di ricerca con componenti e database di ricerca ridondanti. Tutte le architetture di ricerca di esempio testate da Microsoft hanno componenti e database di ricerca ridondanti. Potrebbe essere utile studiare questi esempi quando si lavora alla propria topologia (vedere Architetture di ricerca organizzazione per SharePoint 2016).
Seguire queste linee guida:
Come rendere ridondante l'indice
L'indice è ridondante se ha due o più repliche di indice per partizione di indice. Se si verifica un errore in un server che ospita una replica di indice, è possibile che si verifichi una riduzione delle prestazioni, ma il servizio di ricerca può comunque gestire le query e gli elementi di indice. Se però l'ambiente richiede sempre prestazioni invariate, il servizio di ricerca necessita di un numero maggiore di componenti di indicizzazione ridondanti. Si supponga ad esempio di aver progettato una topologia di ricerca con due repliche per partizione per ridurre il tempo di attesa per le query e che l'ambiente richieda sempre un tempo di attesa breve per le query. In questo caso è necessario aumentare il numero di repliche di indice per partizione.
Tutte le partizioni devono avere lo stesso numero di repliche. Un componente di indicizzazione rappresenta una replica di indice. Se pertanto si desiderano due repliche dell'indice, è necessario il doppio dei componenti di indicizzazione rispetto alle partizioni di indice. Ad esempio, con un SharePoint Server 2016indice ridondante con 80 milioni di elementi sono necessarie quattro partizioni. Otto componenti di indicizzazione rappresentano le quattro partizioni quando si usano due repliche per ogni partizione.
Se si aggiungono componenti di indicizzazione come repliche a partizioni esistenti in un'installazione in esecuzione, il servizio di ricerca effettua automaticamente il seeding delle nuove repliche con dati della partizione di indice. È possibile che trascorrano alcune ore prima che le nuove repliche siano operative.
Come rendere ridondanti i componenti di ricerca per indicizzazione, elaborazione del contenuto, elaborazione delle query, elaborazione dell'analisi e amministrazione della ricerca
Usare il componente di ricerca per indicizzazione come esempio. Se è necessario disconnettere uno dei server che ospita un componente di ricerca per indicizzazione per la manutenzione, è possibile che i risultati risultino meno aggiornati, ma il servizio di ricerca può comunque eseguire la ricerca per indicizzazione di tutto il contenuto. Se però l'ambiente richiede sempre lo stesso livello di aggiornamento dei risultati, il servizio di ricerca necessita di un numero maggiore di componenti di ricerca per indicizzazione ridondanti. Si supponga ad esempio di aver progettato la topologia di ricerca con tre componenti di ricerca per indicizzazione e di voler mantenere invariato il livello di aggiornamento dei risultati anche se si verificano errori in due server con componenti di ricerca per indicizzazione. In questo caso, aggiungere altri due componenti di ricerca per indicizzazione.
Il componente di amministrazione della ricerca rappresenta un'eccezione a questo principio. Un componente di amministrazione della ricerca ha capacità sufficiente per topologie di ricerca di qualsiasi dimensione. Per garantire la ridondanza quindi sono sufficienti due componenti di amministrazione della ricerca.
I componenti di elaborazione del contenuto bilanciano il carico l'uno con l'alto e pertanto la presenza di componenti di elaborazione del contenuto ridondanti aumenta la capacità di elaborare gli elementi.
Come rendere ridondanti i database di ricerca
Per rendere i database di ricerca ridondanti, utilizzare le alternative disponibilità elevata offerte da SQL Server (vedere Creare un'architettura e una strategia a disponibilità elevata per SharePoint Server).
Passaggio 3: scegliere se eseguire i server fisicamente o virtualmente
Quando in origine è stata pianificata l'architettura di ricerca, si è deciso di usare server fisici o macchine virtuali o una combinazione di entrambi. Valutare se questa decisione è ancora valida. Se ora sono presenti più componenti di ricerca, è possibile usare macchine virtuali per semplificare la gestione dell'architettura. È più semplice ad esempio sostituire una macchina virtuale in cui si è verificato un errore anziché un computer fisico. Si noti inoltre che sebbene un ambiente virtuale sia più facile da gestire, il livello di prestazioni a volte può essere leggermente inferiore rispetto a un ambiente fisico. Un server fisico può ospitare più componenti di ricerca nello stesso server rispetto a un server virtuale. In Overview of farm virtualization and architectures for SharePoint 2013 sono disponibili informazioni utili.
Passaggio 4: quali server devono ospitare ogni componente o database di ricerca specifico?
Dopo aver riprogettato la topologia di ricerca, il passaggio successivo consiste nell'assegnare i componenti e i database di ricerca a server fisici o virtuali. Non esiste un modo ottimale per assegnare componenti di ricerca a server fisici o macchine virtuali, ma ecco alcune linee guida:
Un tipo di componente di ricerca per server
Ogni server fisico o macchina virtuale può ospitare solo un componente di ricerca di ogni tipo. Il componente di indicizzazione rappresenta un'eccezione. I server fisici o le macchine virtuali possono ospitare fino a quattro componenti di indicizzazione. Per informazioni su questi limiti, vedere Limiti software statici e configurabili per SharePoint 2013.
Separazione tra i componenti di elaborazione bulk e in tempo reale
Evitare di combinare i componenti di ricerca di elaborazione bulk e in tempo reale nello stesso server fisico o nella stessa macchina virtuale. I componenti di ricerca per indicizzazione, elaborazione del contenuto ed elaborazione dell'analisi eseguono l'elaborazione bulk. I componenti di elaborazione di indice e query invece eseguono l'elaborazione in tempo reale.
Non combinare componenti di ricerca che usano le stesse risorse
Evitare di combinare in un server fisico o in una macchina virtuale componenti di ricerca che usano le stesse risorse. Ecco una tabella che descrive la quantità relativa di risorse richieste da ciascun componente.
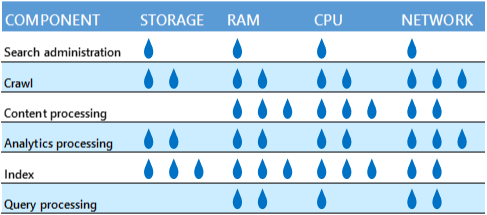
Ad esempio, potrebbe non essere una buona idea posizionare un componente di ricerca per indicizzazione e un componente di elaborazione dell'analisi nello stesso server, perché usano entrambi una quantità elevata di larghezza di banda di rete. Questo problema non sussiste se invece il server fisico o la macchina virtuale ha una capacità di rete sufficiente.
Un altro esempio è l'architettura di ricerca di esempio di dimensioni molto grandi stimata da Microsoft. Sono presenti i componenti di amministrazione della ricerca e della ricerca per indicizzazione in macchine virtuali distinte. Questo è utile per la velocità di ricerca per indicizzazione perché i due componenti in caso contrario potrebbero competere per le risorse processore.
Uso di domini di errore
Assegnare componenti di ricerca ridondanti a host in domini di errore separati.
Passaggio 5: quali sono i requisiti hardware di cui tenere conto?
Il passaggio successivo consiste nel pianificare i componenti hardware necessari:
Risorse minime per il componente di elaborazione dell'analisi
Scelta della modalità di supporto della disponibilità elevata per l'architettura di ricerca
Scelta della quantità di risorse hardware per i server host
Ogni componente e database di ricerca richiede una quantità minima di risorse hardware del server host per funzionare correttamente. Tuttavia, maggiore è il numero di risorse hardware presenti, migliori saranno le prestazioni dell'architettura di ricerca. È consigliabile pertanto implementare risorse hardware superiori alla quantità minima richiesta. Le risorse richieste da ogni componente di ricerca dipendono dal carico di lavoro, a sua volta determinato principalmente dalla frequenza della ricerca per indicizzazione, dalla frequenza delle query e dal numero di elementi indicizzati.
Se ad esempio si ospitano macchine virtuali in Windows Server 2008 R2 Service Pack 1 (SP1), non è possibile usare più di quattro core di CPU per macchina virtuale. Con Windows Server 2012 o versioni successive, si usano otto o più core di CPU per macchina virtuale. È quindi possibile implementare la scalabilità orizzontale con più core di CPU per ogni macchina virtuale anziché implementare la scalabilità verticale con più macchine virtuali. Configurare i server o le macchine virtuali che ospitano gli stessi componenti di ricerca con le stesse risorse hardware. Usare il componente di indicizzazione come esempio. Se si ospitano partizioni di indice in macchine virtuali, la macchina virtuale con le prestazioni inferiori determina le prestazioni dell'intera architettura di ricerca.
Risorse di archiviazione generale
Verificare che ogni server host abbia spazio su disco sufficiente per l'installazione di base del sistema operativo Windows Server e per i file di programma di SharePoint Server 2016. Il server host necessita anche di spazio su disco disponibile per le operazioni di diagnostica quali la registrazione, il debug e la creazione di dump della memoria, per le operazioni quotidiane e per il file di paging. In genere 80 GB di spazio su disco sono sufficienti per il sistema operativo Windows Server e per i file di programma di SharePoint Server 2016.
Aggiungere spazio di archiviazione per i log SQL per ogni server di database. Se non si imposta il server di database in modo da eseguire spesso il backup dei database, i log SQL usano una quantità elevata di spazio di archiviazione. Per altre informazioni su come pianificare i database SQL, vedere Pianificazione e configurazione dell'archiviazione e della capacità di SQL Server (SharePoint Server).
L'archiviazione minima richiesta dal database di report di analisi può variare. Questo perché la quantità di spazio di archiviazione dipende dal modo in cui gli utenti interagiscono con SharePoint Server 2016. Quando gli utenti interagiscono frequentemente, in genere sono presenti più eventi da archiviare. Controllare la quantità di spazio di archiviazione usata dall'architettura di ricerca corrente per il database di analisi e assegnare almeno questa quantità per la topologia riprogettata.
Risorse minime per il componente di indicizzazione
Queste sono le risorse minime richieste da un server o da una macchina virtuale per ospitare un componente di indicizzazione oppure per ospitare un componente di indicizzazione e un componente di elaborazione delle query:
| Spazio di archiviazione | Memoria | Processore | Larghezza di banda di rete |
| 500 GB per l'indice1 | 32 GB1 | 64 bit, minimo 8 core1, 2. | 2 Gb/s |
1Con SharePoint Server 2013 la quantità minima di risorse è di 500 GB di spazio di archiviazione, 16 GB di RAM e quattro core CPU.
2È possibile utilizzare quattro core CPU e 16 GB di RAM con SharePoint Server 2016, ma poi ogni componente dell'indice può contenere un massimo di 10 milioni di elementi (anziché 20 milioni).
Risorse minime per il componente di elaborazione dell'analisi
Queste sono le risorse minime richieste da un server o da una macchina virtuale per ospitare un componente di elaborazione dell'analisi:
| Spazio di archiviazione | Memoria | Processore | Larghezza di banda di rete |
| 300 GB per l'elaborazione locale dell'analisi | 8 GB | 64 bit, minimo 4 core, ma consigliati 8 core. | 2 Gb/s |
Se il server ospita un componente di elaborazione dell'analisi e uno o più componenti di elaborazione bulk, aumentare la memoria a 16 GB.
Risorse minime per i componenti di ricerca per indicizzazione, elaborazione del contenuto, elaborazione delle query e amministrazione della ricerca
Queste sono le risorse minime richieste da un server o da una macchina virtuale per ospitare uno di questi componenti:
| Spazio di archiviazione | Memoria | Processore | Larghezza di banda di rete |
| Non richiesto | 8 GB | 64 bit, minimo 4 core, ma consigliati 8 core. | 2 Gb/s |
Se il server ospita due o più di questi componenti, aumentare la memoria a 16 GB.
Il componente di elaborazione delle query richiede una larghezza di banda di rete appropriata. La richiesta di larghezza di banda di rete dipende dal numero di partizioni di indice e dalle dimensioni delle query e dei risultati. Ad esempio, 20 query al secondo per componente di elaborazione delle query (20 QPS/QPC) e un indice con 20 partizioni di indice comportano 200 Mbps di traffico in ingresso e 100 Mbps di traffico in uscita per il server o la macchina virtuale che ospita il componente di elaborazione delle query.
Risorse minime per i database di ricerca
Queste sono le risorse minime richieste da un server o da una macchina virtuale per ospitare uno o più database di ricerca:
| Spazio di archiviazione | Memoria | Processore | Larghezza di banda di rete |
| Lo spazio di archiviazione richiesto dal database di report di analisi varia in base alla uso e alla frequenza dell'analisi da parte dell'ambiente di ricerca. Usare come linea guida la quantità corrente di spazio di archiviazione per il database di report di analisi. | 8 GB per distribuzioni di piccole dimensioni. 16 GB per distribuzioni di medie dimensioni. |
64 bit, 4 core. | 2 Gb/s |
Pianificazione delle prestazioni di archiviazione
La velocità di archiviazione incide sulle prestazioni di ricerca. Assicurarsi che la velocità di archiviazione sia sufficiente per gestire il traffico dei componenti e database di ricerca. La velocità del disco è misurata in operazioni di input/output al secondo.
Il modo in cui si decide di distribuire i dati dai componenti di ricerca e dal sistema operativo nell'archiviazione influisce sulle prestazioni di ricerca. È consigliabile:
Suddividere i file del sistema operativo Windows Server, i file di programma di SharePoint Server 2016 e i log di diagnostica su tre volumi di archiviazione o partizioni di memoria separate con prestazioni normali.
Archiviare i dati dei componenti di ricerca in un volume di archiviazione o partizione di memoria separata. Per i componenti di indicizzazione, questo spazio di archiviazione deve avere inoltre prestazioni elevate.
Nota
[!NOTA] È possibile impostare un percorso personalizzato per i dati dei componenti di ricerca quando si installa SharePoint Server 2016 in un host. Tutti i componenti di ricerca presenti nell'host che devono archiviare dati usano questo percorso. Per cambiare questo percorso in un secondo momento, è necessario reinstallare SharePoint Server 2016.
Scelta del tipo di risorse di archiviazione
Per una panoramica delle architetture di archiviazione e sui tipi di dischi, vedere Pianificazione e configurazione dell'archiviazione e della capacità di SQL Server (SharePoint Server 2016). I server che ospitano i componenti di indicizzazione, analisi, elaborazione e amministrazione delle ricerche o i database di ricerca richiedono supporti di archiviazione in grado di mantenere una latenza bassa, assicurando comunque un numero sufficiente di operazioni di input/output al secondo. Nelle tabelle seguenti è indicato il numero di operazioni di input/output al secondo richiesto da ognuno di questi componenti e database di ricerca.
Se si distribuisce un sistema di archiviazione condiviso come SAN/NAS, il carico massimo del disco di un componente di ricerca coincide generalmente con quello di un altro componente di ricerca. Per ottenere il numero di operazioni di input/output al secondo richiesto dalla ricerca dal sistema di archiviazione condivisa, è necessario sommare il requisito di operazioni di input/output al secondo di ognuno di questi componenti.
Requisiti di input/output al secondo per i componenti di ricerca
| Nome componente | Dettagli componente | Requisiti di input/output al secondo | Uso di volume di archiviazione//partizione di memoria separata |
|---|---|---|---|
| Componente di indicizzazione | Usa l'archiviazione durante l'unione dell'indice e durante la gestione e la risposta alle query. | 300 operazioni di input/output al secondo per letture casuali a 64 KB. 100 operazioni di input/output al secondo per scritture casuali a 256 KB. 200 MB/s per letture sequenziali. 200 MB/s per scritture sequenziali. |
Sì |
| Componente di analisi | Analizza i dati in locale, con elaborazione bulk. | No | Sì |
| Componente di ricerca per indicizzazione | Archivia localmente il contenuto scaricato, prima di inviarlo a un componente di elaborazione del contenuto. L'archiviazione è limitata dalla larghezza di banda della rete. | No | Sì |
Requisiti di input/output al secondo per i database di ricerca
| Nome database | Requisiti di input/output al secondo | Carico tipico sul sottosistema I/O. |
|---|---|---|
| Database di ricerca per indicizzazione | Numero medio-alto di operazioni di input/output al secondo | 10 operazioni di input/output al secondo per una frequenza di ricerca per indicizzazione di un documento al secondo. |
| Database dei collegamenti | Numero medio di operazioni di input/output al secondo | 10 operazioni di input/output al secondo per un milione di elementi nell'indice di ricerca. |
| Database di amministrazione della ricerca | Numero ridotto di operazioni di input/output al secondo | Non applicabile. |
| Database di report di analisi | Numero medio di operazioni di input/output al secondo | Non applicabile. |
Scelta della modalità di supporto della disponibilità elevata per l'architettura di ricerca
Se non si ha familiarità con le strategie di disponibilità elevata, ecco un articolo introduttivo: Creare un'architettura e una strategia a disponibilità elevata per SharePoint Server. Se si ospitano componenti e database di ricerca ridondanti in domini di errore separati, un'interruzione del servizio in una parte della farm non comporta l'interruzione dell'intero servizio. Si verificherà tuttavia una riduzione delle prestazioni di ricerca, perché i componenti di ricerca non possono condividere ulteriormente il carico. Per ridurre il rischio di perdere un singolo server, è opportuno migliorare la ridondanza locale. Per ogni server host nell'architettura di ricerca:
Usare l'archiviazione RAID in ogni server.
Installare più connessioni di rete ridondanti in ogni server.
Installare più alimentatori ridondanti con cablaggio indipendente o un gruppo di continuità per ogni server.
Tutte le architetture di ricerca di esempio ospitano componenti di ricerca ridondanti in server indipendenti. Nelle architetture di ricerca di esempio l'host più a destra in ogni coppia di host è ridondante. Questa è l'architettura di ricerca di grandi dimensioni con gli host ridondanti evidenziati.