Preparare i dati e caricarli nell'account di archiviazione
Importante
A partire dal 20 settembre 2023 non sarà possibile creare nuove risorse di Rilevamento anomalie. Il servizio Rilevamento anomalie verrà ritirato il 1° ottobre 2026.
Il rilevamento anomalie multivariato richiede il training per l’elaborazione dei dati e un account di archiviazione di Azure per archiviare i dati per ulteriori passaggi di training e inferenza.
Preparazione dei dati
Prima di tutto è necessario preparare i dati per il training e l'inferenza.
Schema dei dati di input
Il rilevamento anomalie multivariato supporta due tipi di schemi dati: OneTable e MultiTable. È possibile usare uno di questi schemi per preparare i dati e caricarli nell'account di archiviazione per ulteriore training e inferenza.

Schema 1: OneTable
OneTable è un file CSV che contiene tutte le variabili su cui si desidera eseguire il training per un modello rilevamento anomalie multivariato e una colonna timestamp. Scaricare i dati di esempio di OneTable
I valori
timestampdevono essere conformi a ISO 8601. I valori di altre variabili in altre colonne possono esserenumeri interi o decimali con un numero qualsiasi di cifre decimali.Le variabili per il training e le variabili per l'inferenza devono essere coerenti. Ad esempio, se si usa
series_1,series_2,series_3,series_4eseries_5per il training, è necessario fornire esattamente le stesse variabili per l'inferenza.Esempio:

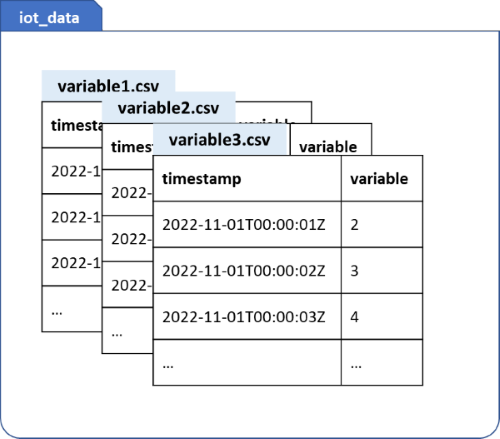
Schema 2: MultiTable
MultiTable è costituito da più file CSV in una cartella di file e ogni file CSV contiene solo due colonne di una variabile, con i nomi esatti delle colonne: timestamp e valore. Scaricare i dati di esempio di Multiple Tables e decomprimerli.
I valori
timestampdevono essere conformi a ISO 8601. I valorivaluepossono essere numeri interi o decimali con un numero qualsiasi di cifre decimali.Il nome del file CSV verrà usato come nome della variabile e deve essere univoco. Ad esempio, temperature.csv e humidity.csv.
Le variabili per il training e le variabili per l'inferenza devono essere coerenti. Ad esempio, se si usa
series_1,series_2,series_3,series_4eseries_5per il training, è necessario fornire esattamente le stesse variabili per l'inferenza.Esempio:
Nota
Se i timestamp hanno ore, minuti e/o secondi, assicurarsi che vengano arrotondati correttamente prima di chiamare le API. Ad esempio, se la frequenza dei dati deve essere un punto dati ogni 30 secondi, ma vengono visualizzati timestamp come "12:00:01" e "12:00:28", è un segnale forte che è consigliabile pre-elaborare i timestamp in nuovi valori come "12:00:00" e "12:00:30". Per informazioni dettagliate, vedere la sezione "Arrotondamento timestamp" nel documento sulle procedure consigliate.
Caricare i dati nell'account di archiviazione
Dopo aver preparato i dati con uno dei due schemi precedenti, è possibile caricare il file CSV (OneTable) o la cartella dati (MultiTable) nell'account di archiviazione.
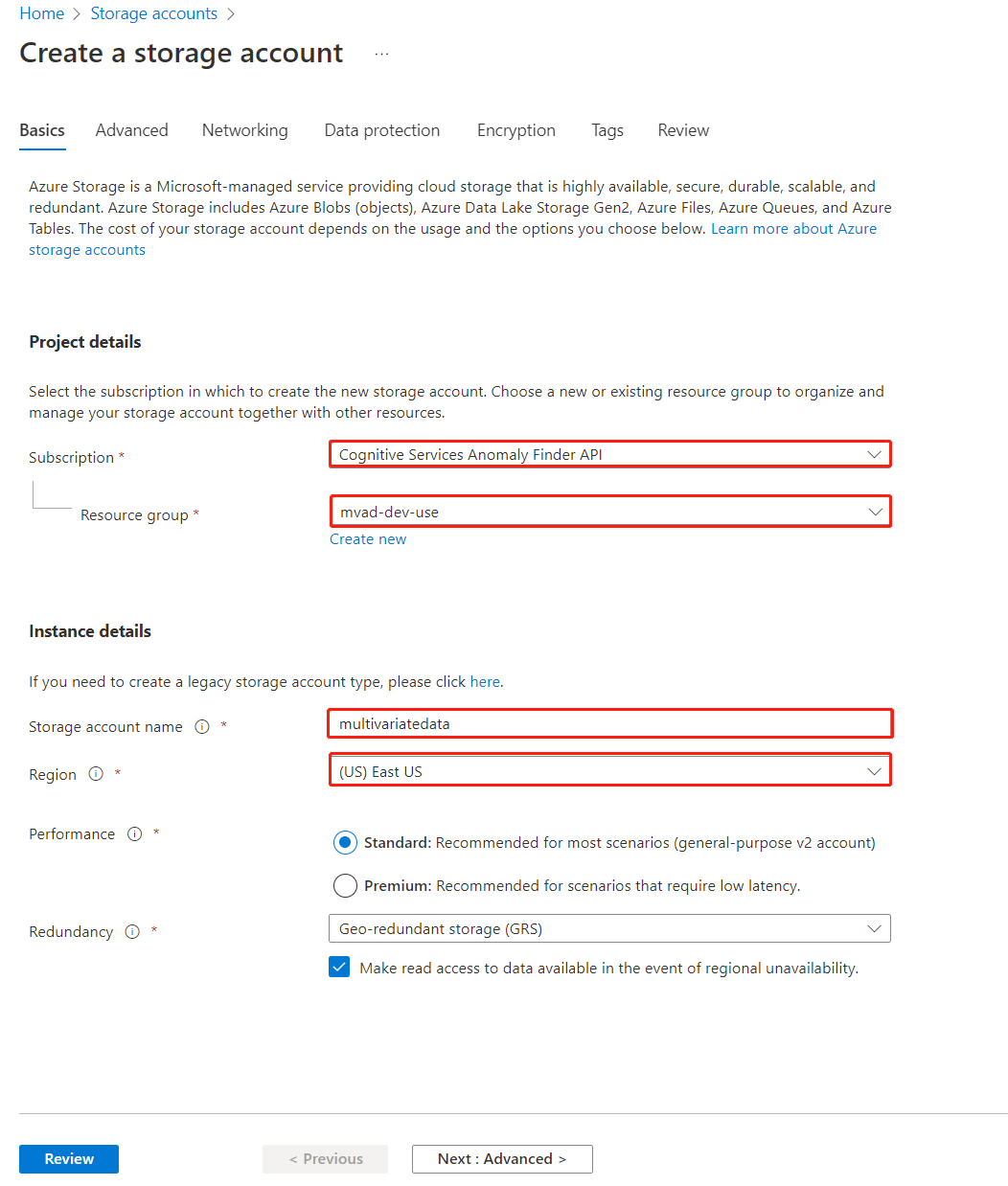
Creare un account di archiviazione, compilare i campi, passaggi simili a quelli previsti per la creazione della risorsa Rilevamento anomalie.
Selezionare Contenitore a sinistra della risorsa account di archiviazione e selezionare +Contenitore per crearne uno che archivierà i dati.
Caricare i dati nel contenitore.
Caricare i dati di OneTable
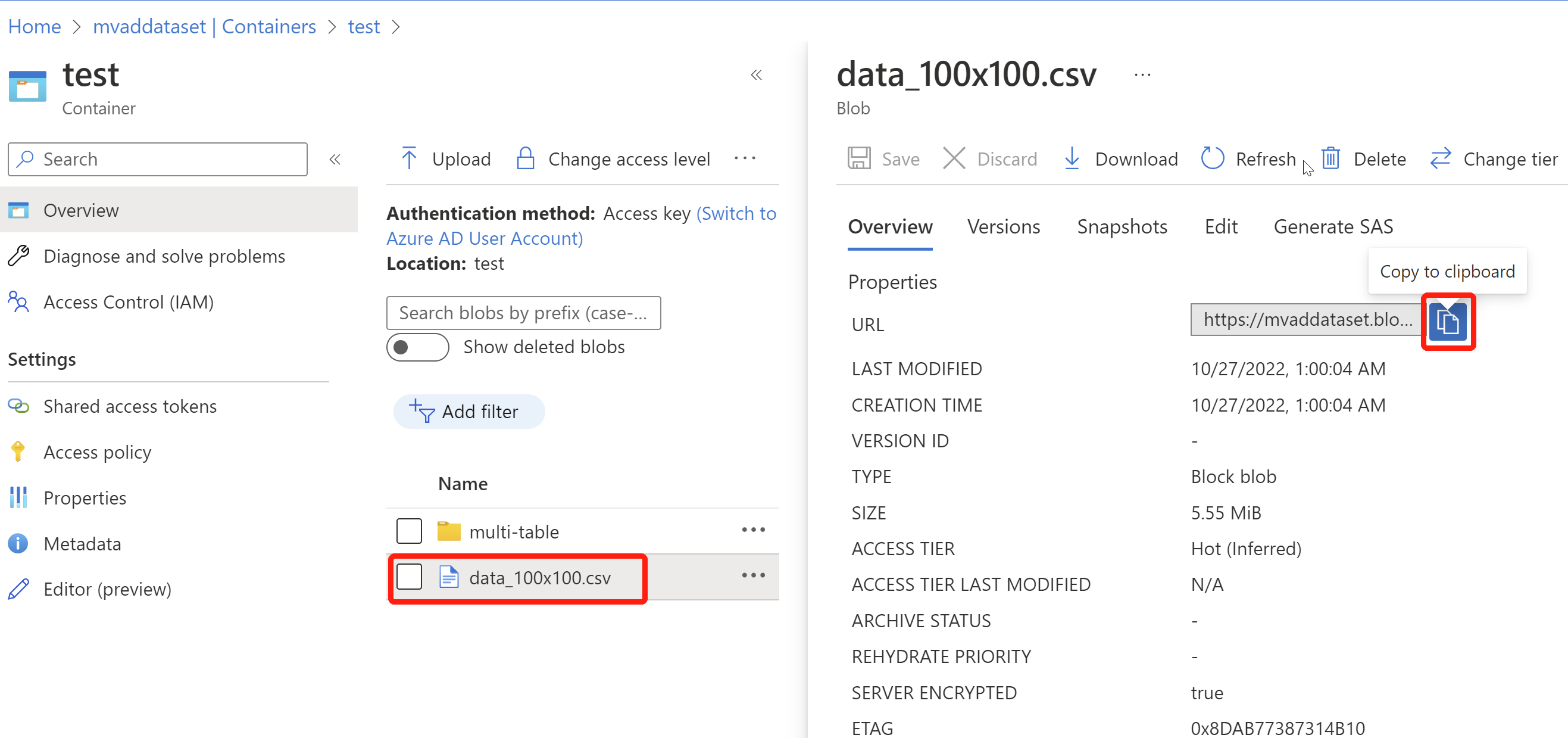
Passare al contenitore creato e selezionare Carica, quindi scegliere il file CSV preparato e caricarlo.
Dopo aver caricato i dati, selezionare il file CSV e copiare l'URL del BLOB tramite il piccolo pulsante blu. Incollare l'URL in un luogo pratico per ulteriori passaggi.
Caricare i dati MultiTable
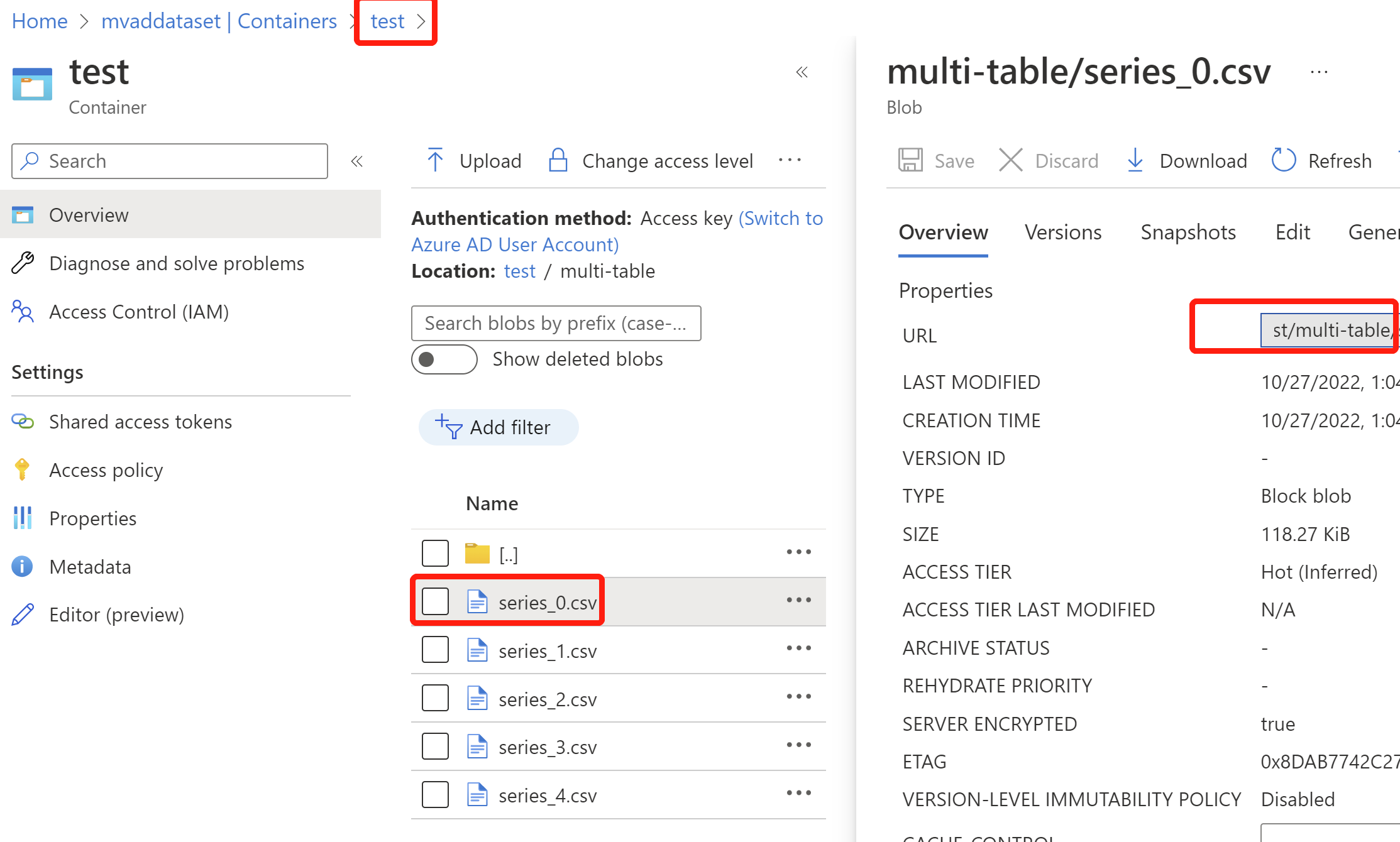
Passare al contenitore creato e selezionare Carica, quindi selezionare Avanzate e indicare il nome di una cartella in Carica nella cartella, quindi selezionare tutte le variabili in file CSV separati e caricarli.
Dopo aver caricato i dati, accedere alla cartella e selezionare un file CSV al suo interno, copiare l'URL del BLOB e mantenere solo la parte che precede il nome del file CSV, in modo che l'URL finale del BLOB sia collegato alla cartella. Incollare l'URL in un luogo pratico per ulteriori passaggi.
Concedere a Rilevamento anomalie l'accesso in lettura dei dati nell'account di archiviazione.
- Nel contenitore selezionare Controllo di accesso (IAM) a sinistra, selezionare + Aggiungi per aggiungere un'assegnazione di ruolo. Se si nota che l'assegnazione di ruolo è disabilitata, contattare il proprietario dell'account di archiviazione in modo che aggiunga il ruolo Proprietario al contenitore.
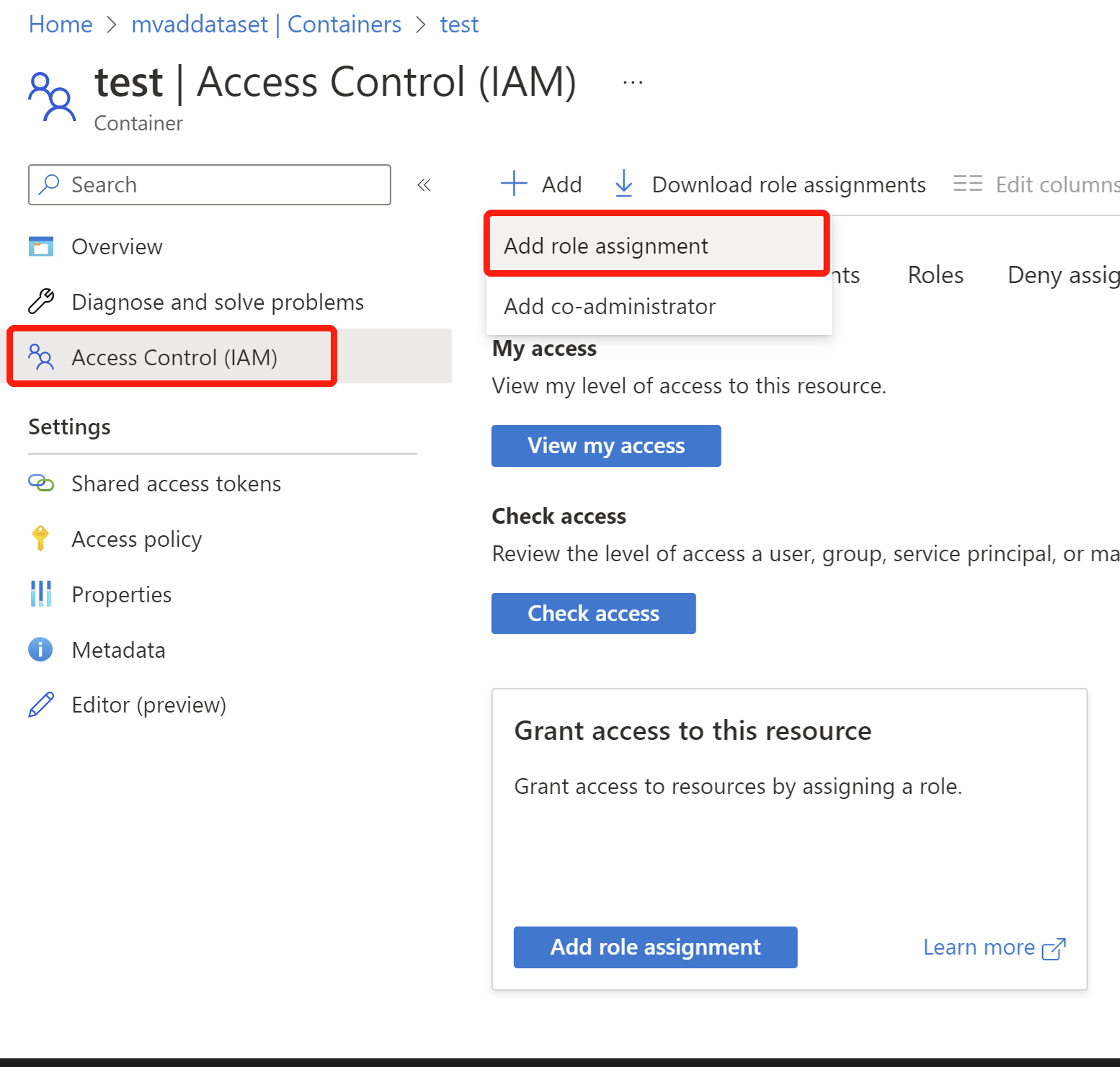
- Cercare e selezionare il ruolo Lettore dati BLOB di archiviazione e selezionare Avanti. Tecnicamente, i ruoli evidenziati di seguito e il ruolo Proprietario dovrebbero funzionare.
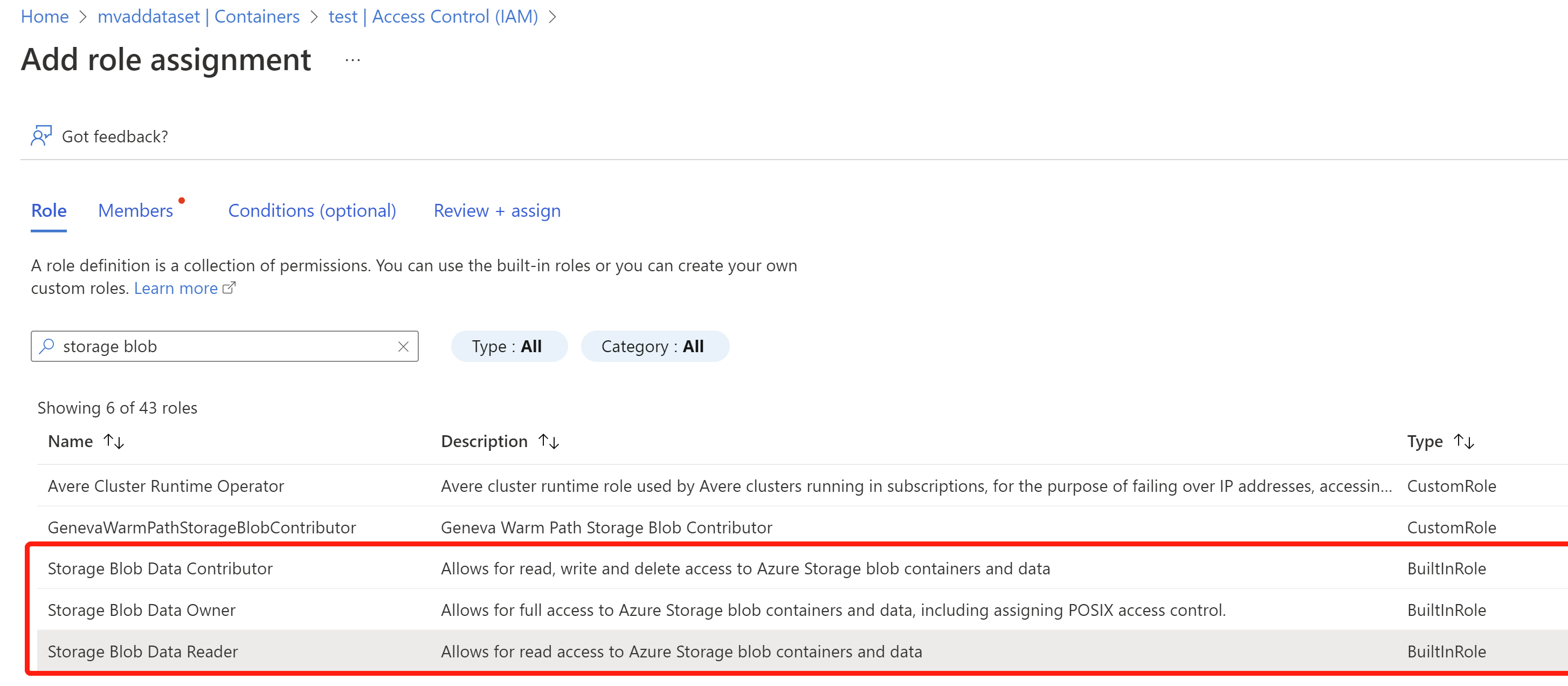
- Selezionare Assegna accesso all'identità gestita e Seleziona membri, quindi scegliere la risorsa rilevamento anomalie creata in precedenza, quindi selezionare Rivedi e assegna.