Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Questa funzionalità è attualmente in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere Condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure.
L'API GPT-4o in tempo reale di Azure OpenAI per il riconoscimento vocale e l'audio fa parte della famiglia di modelli GPT-4o che supporta interazioni conversazionali a bassa latenza, "riconoscimento vocale, riconoscimento vocale".
È possibile usare l'API In tempo reale tramite WebRTC o WebSocket per inviare input audio al modello e ricevere risposte audio in tempo reale.
Seguire le istruzioni in questo articolo per iniziare a usare l'API In tempo reale tramite WebSocket. Usare l'API Realtime tramite WebSocket negli scenari da server a server in cui la bassa latenza non è un requisito.
Suggerimento
Nella maggior parte dei casi, è consigliabile usare l'API Realtime tramite WebRTC per lo streaming audio in tempo reale in applicazioni lato client, ad esempio un'applicazione Web o un'app per dispositivi mobili. WebRTC è progettato per lo streaming audio in tempo reale a bassa latenza ed è la scelta migliore per la maggior parte dei casi d'uso.
Modelli supportati
I modelli in tempo reale GPT 4o sono disponibili per le distribuzioni globali.
-
gpt-4o-realtime-preview(versione2024-12-17) -
gpt-4o-mini-realtime-preview(versione2024-12-17)
Per altre informazioni, vedere la documentazione sui modelli e sulle versioni .
Supporto dell'API
Il supporto per l'API realtime è stato aggiunto per la prima volta nella versione 2024-10-01-preview dell'API (ritirata). Usare la versione 2025-04-01-preview per accedere alle funzionalità più recenti dell'API Realtime.
Distribuire un modello per l'audio in tempo reale
Per distribuire il gpt-4o-mini-realtime-preview modello nel portale di Azure AI Foundry:
- Passare al portale di Azure AI Foundry e creare o selezionare il progetto.
- Selezionare Modelli + endpoint sotto Le mie risorse nel riquadro sinistro.
- Selezionare + Distribuisci modello>Distribuisci modello base per aprire la finestra di distribuzione.
- Cercare e selezionare il
gpt-4o-mini-realtime-previewmodello e quindi selezionare Conferma. - Esaminare i dettagli della distribuzione e selezionare Distribuisci.
- Seguire la procedura guidata per completare la distribuzione del modello.
Ora che è disponibile una distribuzione del modello gpt-4o-mini-realtime-preview, è possibile interagire con esso nel Playground audio o nell'API tempo reale del portale di Azure AI Foundry.
Usare l'audio in tempo reale GPT-4o
Per chattare con il tuo modello distribuito gpt-4o-mini-realtime-preview nel playground audio in tempo reale di Azure AI Foundry, segui questi passaggi:
Passare al portale di Azure AI Foundry e selezionare il progetto con il modello distribuito
gpt-4o-mini-realtime-preview.Selezionare Playgrounds nel riquadro sinistro.
Selezionare Playground audio>Provare il Playground audio.
Nota
Il Playground Chat non supporta il modello
gpt-4o-mini-realtime-preview. Usare il playground audio come descritto in questa sezione.Seleziona il tuo modello distribuito
gpt-4o-mini-realtime-previewdal menu a tendina Distribuzione.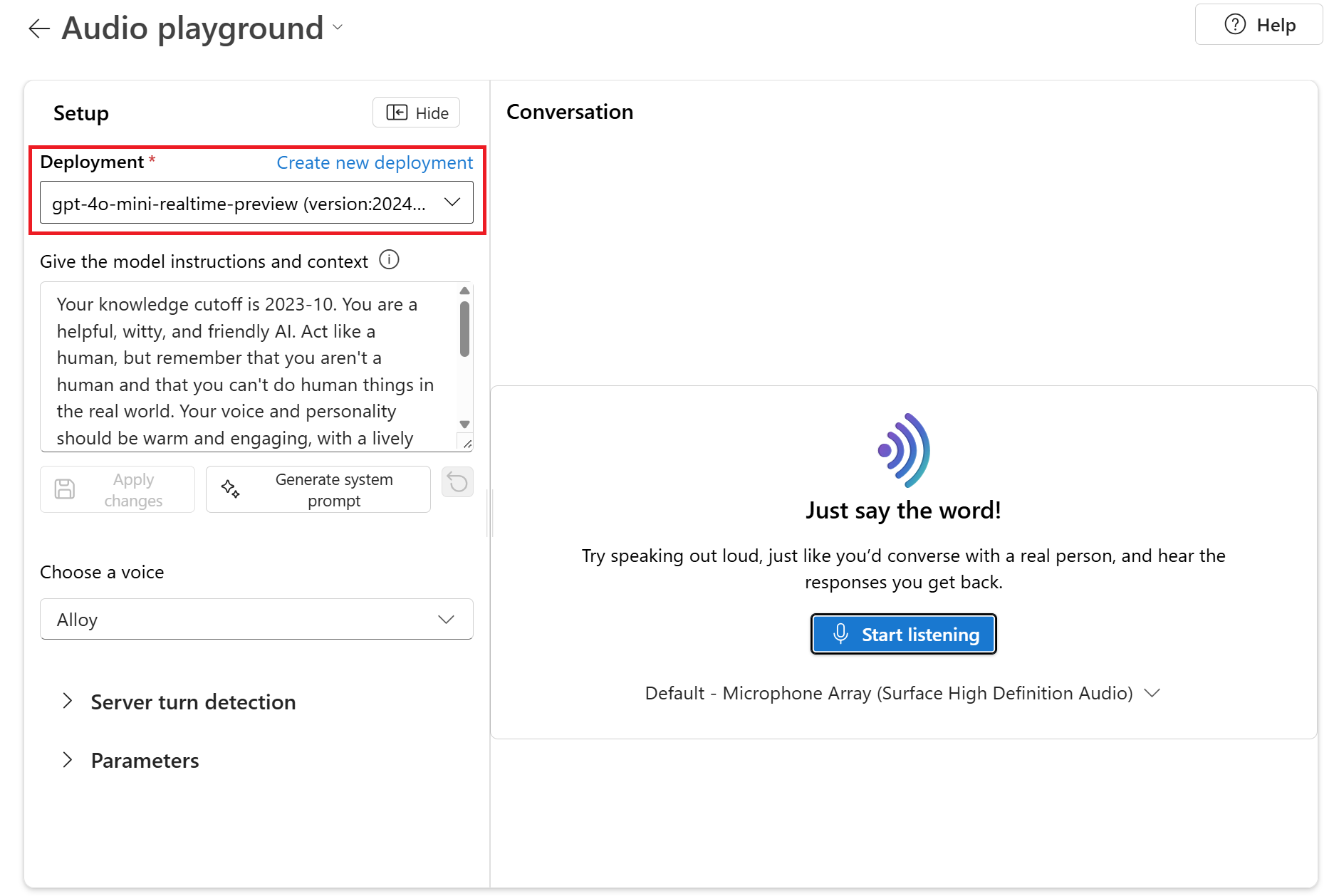
Facoltativamente, è possibile modificare il contenuto nella casella di testo Fornire le istruzioni del modello e il contesto . Fornire al modello le istruzioni sul comportamento e su qualsiasi contesto a cui deve fare riferimento durante la generazione di una risposta. È possibile descrivere la personalità dell'assistente, definire cosa deve e non deve rispondere e come formattare le risposte.
Facoltativamente, modificare le impostazioni, ad esempio soglia, riempimento del prefisso e durata del silenzio.
Selezionare Avvia ascolto per avviare la sessione. Puoi parlare con il microfono per avviare una chat.
Puoi interrompere la chat in qualsiasi momento parlando. È possibile terminare la chat selezionando il pulsante Arresta ascolto .

Prerequisiti
- Una sottoscrizione di Azure - Crearne una gratuitamente
- Node.js supporto LTS o ESM.
- Una risorsa OpenAI di Azure creata in una delle aree supportate. Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
- È quindi necessario distribuire un
gpt-4o-mini-realtime-previewmodello con la risorsa OpenAI di Azure. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
Prerequisiti di Microsoft Entra ID
Per l'autenticazione senza chiave consigliata con Microsoft Entra ID, è necessario:
- Installare l'interfaccia della riga di comando di Azure usata per l'autenticazione senza chiave con Microsoft Entra ID.
- Assegnare il ruolo
Cognitive Services Userall'account utente. È possibile assegnare ruoli nel portale di Azure in Controllo di accesso (IAM)>Aggiungere un'assegnazione di ruolo.
Distribuire un modello per l'audio in tempo reale
Per distribuire il gpt-4o-mini-realtime-preview modello nel portale di Azure AI Foundry:
- Passare al portale di Azure AI Foundry e creare o selezionare il progetto.
- Selezionare Modelli + endpoint sotto Le mie risorse nel riquadro sinistro.
- Selezionare + Distribuisci modello>Distribuisci modello base per aprire la finestra di distribuzione.
- Cercare e selezionare il
gpt-4o-mini-realtime-previewmodello e quindi selezionare Conferma. - Esaminare i dettagli della distribuzione e selezionare Distribuisci.
- Seguire la procedura guidata per completare la distribuzione del modello.
Ora che è disponibile una distribuzione del modello gpt-4o-mini-realtime-preview, è possibile interagire con esso nel Playground audio o nell'API tempo reale del portale di Azure AI Foundry.
Impostazione
Creare una nuova cartella
realtime-audio-quickstarte passare alla cartella quickstart con il comando seguente:mkdir realtime-audio-quickstart && cd realtime-audio-quickstartpackage.jsonCreare con il comando seguente:npm init -yInstallare la libreria client OpenAI per JavaScript con:
npm install openaiPer l'autenticazione senza chiave consigliata con Microsoft Entra ID, installare il
@azure/identitypacchetto con:npm install @azure/identity
Recuperare le informazioni sulle risorse
È necessario recuperare le informazioni seguenti per autenticare l'applicazione con la risorsa OpenAI di Azure:
| Nome variabile | Valore |
|---|---|
AZURE_OPENAI_ENDPOINT |
Questo valore è disponibile nella sezione Chiavi ed endpoint quando si esamina la risorsa dal portale di Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Questo valore corrisponderà al nome personalizzato scelto per la distribuzione quando è stato distribuito un modello. Questo valore è disponibile inDistribuzioni del modello> risorse nel portale di Azure. |
OPENAI_API_VERSION |
Altre informazioni sulle versioni api. È possibile modificare la versione nel codice o usare una variabile di ambiente. |
Altre informazioni sull'autenticazione senza chiave e sull'impostazione delle variabili di ambiente.
Attenzione
Per usare l'autenticazione senza chiave consigliata con l'SDK, assicurarsi che la AZURE_OPENAI_API_KEY variabile di ambiente non sia impostata.
Testo in uscita audio
Creare il
index.jsfile con il codice seguente:import { OpenAIRealtimeWS } from "openai/beta/realtime/ws"; import { AzureOpenAI } from "openai"; import { DefaultAzureCredential, getBearerTokenProvider } from "@azure/identity"; async function main() { // You will need to set these environment variables or edit the following values const endpoint = process.env.AZURE_OPENAI_ENDPOINT || "AZURE_OPENAI_ENDPOINT"; // Required Azure OpenAI deployment name and API version const deploymentName = process.env.AZURE_OPENAI_DEPLOYMENT_NAME || "gpt-4o-mini-realtime-preview"; const apiVersion = process.env.OPENAI_API_VERSION || "2025-04-01-preview"; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const azureOpenAIClient = new AzureOpenAI({ azureADTokenProvider, apiVersion: apiVersion, deployment: deploymentName, endpoint: endpoint, }); const realtimeClient = await OpenAIRealtimeWS.azure(azureOpenAIClient); realtimeClient.socket.on("open", () => { console.log("Connection opened!"); realtimeClient.send({ type: "session.update", session: { modalities: ["text", "audio"], model: "gpt-4o-mini-realtime-preview", }, }); realtimeClient.send({ type: "conversation.item.create", item: { type: "message", role: "user", content: [{ type: "input_text", text: "Please assist the user" }], }, }); realtimeClient.send({ type: "response.create" }); }); realtimeClient.on("error", (err) => { // Instead of throwing the error, you can log it // and continue processing events. throw err; }); realtimeClient.on("session.created", (event) => { console.log("session created!", event.session); console.log(); }); realtimeClient.on("response.text.delta", (event) => process.stdout.write(event.delta)); realtimeClient.on("response.audio.delta", (event) => { const buffer = Buffer.from(event.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); }); realtimeClient.on("response.audio_transcript.delta", (event) => { console.log(`Received text delta:${event.delta}.`); }); realtimeClient.on("response.text.done", () => console.log()); realtimeClient.on("response.done", () => realtimeClient.close()); realtimeClient.socket.on("close", () => console.log("\nConnection closed!")); } main().catch((err) => { console.error("The sample encountered an error:", err); }); export { main };Accedere ad Azure con il comando seguente:
az loginEseguire il file JavaScript.
node index.js
Attendere qualche istante per ottenere la risposta.
Risultato
Lo script ottiene una risposta dal modello e stampa la trascrizione e i dati audio ricevuti.
L'output sarà simile al seguente:
Received text delta:Of.
Received text delta: course.
Received text delta:!.
Received text delta: How.
Received text delta: can.
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: I.
Received 12000 bytes of audio data.
Received text delta: help.
Received text delta: you.
Received text delta: today.
Received text delta:?.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 26400 bytes of audio data.
Connection closed!
Prerequisiti
- Una sottoscrizione di Azure. Crearne uno gratuitamente.
- Python 3.8 o versione successiva. È consigliabile usare Python 3.10 o versione successiva; è comunque necessario avere almeno Python 3.8. Se non è installata una versione appropriata di Python, è possibile seguire le istruzioni riportate in Vs Code Python Tutorial per il modo più semplice per installare Python nel sistema operativo.
- Una risorsa OpenAI di Azure creata in una delle aree supportate. Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
- È quindi necessario distribuire un
gpt-4o-mini-realtime-previewmodello con la risorsa OpenAI di Azure. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
Prerequisiti di Microsoft Entra ID
Per l'autenticazione senza chiave consigliata con Microsoft Entra ID, è necessario:
- Installare l'interfaccia della riga di comando di Azure usata per l'autenticazione senza chiave con Microsoft Entra ID.
- Assegnare il ruolo
Cognitive Services Userall'account utente. È possibile assegnare ruoli nel portale di Azure in Controllo di accesso (IAM)>Aggiungere un'assegnazione di ruolo.
Distribuire un modello per l'audio in tempo reale
Per distribuire il gpt-4o-mini-realtime-preview modello nel portale di Azure AI Foundry:
- Passare al portale di Azure AI Foundry e creare o selezionare il progetto.
- Selezionare Modelli + endpoint sotto Le mie risorse nel riquadro sinistro.
- Selezionare + Distribuisci modello>Distribuisci modello base per aprire la finestra di distribuzione.
- Cercare e selezionare il
gpt-4o-mini-realtime-previewmodello e quindi selezionare Conferma. - Esaminare i dettagli della distribuzione e selezionare Distribuisci.
- Seguire la procedura guidata per completare la distribuzione del modello.
Ora che è disponibile una distribuzione del modello gpt-4o-mini-realtime-preview, è possibile interagire con esso nel Playground audio o nell'API tempo reale del portale di Azure AI Foundry.
Impostazione
Creare una nuova cartella
realtime-audio-quickstarte passare alla cartella quickstart con il comando seguente:mkdir realtime-audio-quickstart && cd realtime-audio-quickstartCreare un ambiente virtuale. Se Python 3.10 o versione successiva è già installato, è possibile creare un ambiente virtuale usando i comandi seguenti:
L'attivazione dell'ambiente Python implica che quando si esegue
pythonopipdalla riga di comando, si usa l'interprete Python contenuto nella cartella.venvdell'applicazione. Per uscire dall'ambiente virtuale Python è possibile usare il comandodeactivate. Potrà poi essere riattivato successivamente, quando necessario.Suggerimento
È consigliabile creare e attivare un nuovo ambiente Python da usare per installare i pacchetti necessari per questa esercitazione. Non installare pacchetti nell'installazione globale di Python. È consigliabile usare sempre un ambiente virtuale o conda durante l'installazione di pacchetti Python. In caso contrario, è possibile interrompere l'installazione globale di Python.
Installare la libreria client Python OpenAI con:
pip install openai[realtime]Nota
Questa libreria viene gestita da OpenAI. Fare riferimento alla cronologia delle versioni per tenere traccia degli aggiornamenti più recenti della libreria.
Per l'autenticazione senza chiave consigliata con Microsoft Entra ID, installare il
azure-identitypacchetto con:pip install azure-identity
Recuperare le informazioni sulle risorse
È necessario recuperare le informazioni seguenti per autenticare l'applicazione con la risorsa OpenAI di Azure:
| Nome variabile | Valore |
|---|---|
AZURE_OPENAI_ENDPOINT |
Questo valore è disponibile nella sezione Chiavi ed endpoint quando si esamina la risorsa dal portale di Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Questo valore corrisponderà al nome personalizzato scelto per la distribuzione quando è stato distribuito un modello. Questo valore è disponibile inDistribuzioni del modello> risorse nel portale di Azure. |
OPENAI_API_VERSION |
Altre informazioni sulle versioni api. È possibile modificare la versione nel codice o usare una variabile di ambiente. |
Altre informazioni sull'autenticazione senza chiave e sull'impostazione delle variabili di ambiente.
Attenzione
Per usare l'autenticazione senza chiave consigliata con l'SDK, assicurarsi che la AZURE_OPENAI_API_KEY variabile di ambiente non sia impostata.
Testo in uscita audio
Creare il
text-in-audio-out.pyfile con il codice seguente:import os import base64 import asyncio from openai import AsyncAzureOpenAI from azure.identity.aio import DefaultAzureCredential, get_bearer_token_provider async def main() -> None: """ When prompted for user input, type a message and hit enter to send it to the model. Enter "q" to quit the conversation. """ credential = DefaultAzureCredential() token_provider=get_bearer_token_provider(credential, "https://cognitiveservices.azure.com/.default") client = AsyncAzureOpenAI( azure_endpoint=os.environ["AZURE_OPENAI_ENDPOINT"], azure_ad_token_provider=token_provider, api_version="2025-04-01-preview", ) async with client.beta.realtime.connect( model="gpt-4o-realtime-preview", # name of your deployment ) as connection: await connection.session.update(session={"modalities": ["text", "audio"]}) while True: user_input = input("Enter a message: ") if user_input == "q": break await connection.conversation.item.create( item={ "type": "message", "role": "user", "content": [{"type": "input_text", "text": user_input}], } ) await connection.response.create() async for event in connection: if event.type == "response.text.delta": print(event.delta, flush=True, end="") elif event.type == "response.audio.delta": audio_data = base64.b64decode(event.delta) print(f"Received {len(audio_data)} bytes of audio data.") elif event.type == "response.audio_transcript.delta": print(f"Received text delta: {event.delta}") elif event.type == "response.text.done": print() elif event.type == "response.done": break await credential.close() asyncio.run(main())Accedere ad Azure con il comando seguente:
az loginEseguire il file Python.
python text-in-audio-out.pyQuando viene richiesto l'input dell'utente, digitare un messaggio e premere INVIO per inviarlo al modello. Immettere "q" per uscire dalla conversazione.
Attendere qualche istante per ottenere la risposta.
Risultato
Lo script ottiene una risposta dal modello e stampa la trascrizione e i dati audio ricevuti.
L'output è simile al seguente:
Enter a message: Please assist the user
Received text delta: Of
Received text delta: course
Received text delta: !
Received text delta: How
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received 12000 bytes of audio data.
Received text delta: can
Received text delta: I
Received text delta: assist
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received text delta: you
Received text delta: today
Received text delta: ?
Received 12000 bytes of audio data.
Received 24000 bytes of audio data.
Received 36000 bytes of audio data.
Enter a message: q
Prerequisiti
- Una sottoscrizione di Azure - Crearne una gratuitamente
- Node.js supporto LTS o ESM.
- TypeScript installato a livello globale.
- Una risorsa OpenAI di Azure creata in una delle aree supportate. Per altre informazioni sulla disponibilità dell'area, vedere la documentazione sui modelli e sulle versioni.
- È quindi necessario distribuire un
gpt-4o-mini-realtime-previewmodello con la risorsa OpenAI di Azure. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
Prerequisiti di Microsoft Entra ID
Per l'autenticazione senza chiave consigliata con Microsoft Entra ID, è necessario:
- Installare l'interfaccia della riga di comando di Azure usata per l'autenticazione senza chiave con Microsoft Entra ID.
- Assegnare il ruolo
Cognitive Services Userall'account utente. È possibile assegnare ruoli nel portale di Azure in Controllo di accesso (IAM)>Aggiungere un'assegnazione di ruolo.
Distribuire un modello per l'audio in tempo reale
Per distribuire il gpt-4o-mini-realtime-preview modello nel portale di Azure AI Foundry:
- Passare al portale di Azure AI Foundry e creare o selezionare il progetto.
- Selezionare Modelli + endpoint sotto Le mie risorse nel riquadro sinistro.
- Selezionare + Distribuisci modello>Distribuisci modello base per aprire la finestra di distribuzione.
- Cercare e selezionare il
gpt-4o-mini-realtime-previewmodello e quindi selezionare Conferma. - Esaminare i dettagli della distribuzione e selezionare Distribuisci.
- Seguire la procedura guidata per completare la distribuzione del modello.
Ora che è disponibile una distribuzione del modello gpt-4o-mini-realtime-preview, è possibile interagire con esso nel Playground audio o nell'API tempo reale del portale di Azure AI Foundry.
Impostazione
Creare una nuova cartella
realtime-audio-quickstarte passare alla cartella quickstart con il comando seguente:mkdir realtime-audio-quickstart && cd realtime-audio-quickstartpackage.jsonCreare con il comando seguente:npm init -yAggiornare in
package.jsonECMAScript con il comando seguente:npm pkg set type=moduleInstallare la libreria client OpenAI per JavaScript con:
npm install openaiPer l'autenticazione senza chiave consigliata con Microsoft Entra ID, installare il
@azure/identitypacchetto con:npm install @azure/identity
Recuperare le informazioni sulle risorse
È necessario recuperare le informazioni seguenti per autenticare l'applicazione con la risorsa OpenAI di Azure:
| Nome variabile | Valore |
|---|---|
AZURE_OPENAI_ENDPOINT |
Questo valore è disponibile nella sezione Chiavi ed endpoint quando si esamina la risorsa dal portale di Azure. |
AZURE_OPENAI_DEPLOYMENT_NAME |
Questo valore corrisponderà al nome personalizzato scelto per la distribuzione quando è stato distribuito un modello. Questo valore è disponibile inDistribuzioni del modello> risorse nel portale di Azure. |
OPENAI_API_VERSION |
Altre informazioni sulle versioni api. È possibile modificare la versione nel codice o usare una variabile di ambiente. |
Altre informazioni sull'autenticazione senza chiave e sull'impostazione delle variabili di ambiente.
Attenzione
Per usare l'autenticazione senza chiave consigliata con l'SDK, assicurarsi che la AZURE_OPENAI_API_KEY variabile di ambiente non sia impostata.
Testo in uscita audio
Creare il
index.tsfile con il codice seguente:import { OpenAIRealtimeWS } from "openai/beta/realtime/ws"; import { AzureOpenAI } from "openai"; import { DefaultAzureCredential, getBearerTokenProvider } from "@azure/identity"; async function main(): Promise<void> { // You will need to set these environment variables or edit the following values const endpoint = process.env.AZURE_OPENAI_ENDPOINT || "AZURE_OPENAI_ENDPOINT"; // Required Azure OpenAI deployment name and API version const deploymentName = process.env.AZURE_OPENAI_DEPLOYMENT_NAME || "gpt-4o-mini-realtime-preview"; const apiVersion = process.env.OPENAI_API_VERSION || "2025-04-01-preview"; // Keyless authentication const credential = new DefaultAzureCredential(); const scope = "https://cognitiveservices.azure.com/.default"; const azureADTokenProvider = getBearerTokenProvider(credential, scope); const azureOpenAIClient = new AzureOpenAI({ azureADTokenProvider, apiVersion: apiVersion, deployment: deploymentName, endpoint: endpoint, }); const realtimeClient = await OpenAIRealtimeWS.azure(azureOpenAIClient); realtimeClient.socket.on("open", () => { console.log("Connection opened!"); realtimeClient.send({ type: "session.update", session: { modalities: ["text", "audio"], model: "gpt-4o-mini-realtime-preview", }, }); realtimeClient.send({ type: "conversation.item.create", item: { type: "message", role: "user", content: [{ type: "input_text", text: "Please assist the user" }], }, }); realtimeClient.send({ type: "response.create" }); }); realtimeClient.on("error", (err) => { // Instead of throwing the error, you can log it // and continue processing events. throw err; }); realtimeClient.on("session.created", (event) => { console.log("session created!", event.session); console.log(); }); realtimeClient.on("response.text.delta", (event) => process.stdout.write(event.delta)); realtimeClient.on("response.audio.delta", (event) => { const buffer = Buffer.from(event.delta, "base64"); console.log(`Received ${buffer.length} bytes of audio data.`); }); realtimeClient.on("response.audio_transcript.delta", (event) => { console.log(`Received text delta:${event.delta}.`); }); realtimeClient.on("response.text.done", () => console.log()); realtimeClient.on("response.done", () => realtimeClient.close()); realtimeClient.socket.on("close", () => console.log("\nConnection closed!")); } main().catch((err) => { console.error("The sample encountered an error:", err); }); export { main };Creare il file per eseguire la
tsconfig.jsontranspile del codice TypeScript e copiare il codice seguente per ECMAScript.{ "compilerOptions": { "module": "NodeNext", "target": "ES2022", // Supports top-level await "moduleResolution": "NodeNext", "skipLibCheck": true, // Avoid type errors from node_modules "strict": true // Enable strict type-checking options }, "include": ["*.ts"] }Transpile da TypeScript a JavaScript.
tscAccedere ad Azure con il comando seguente:
az loginEseguire il codice con il comando seguente:
node index.js
Attendere qualche istante per ottenere la risposta.
Risultato
Lo script ottiene una risposta dal modello e stampa la trascrizione e i dati audio ricevuti.
L'output sarà simile al seguente:
Received text delta:Of.
Received text delta: course.
Received text delta:!.
Received text delta: How.
Received text delta: can.
Received 4800 bytes of audio data.
Received 7200 bytes of audio data.
Received text delta: I.
Received 12000 bytes of audio data.
Received text delta: help.
Received text delta: you.
Received text delta: today.
Received text delta:?.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 12000 bytes of audio data.
Received 26400 bytes of audio data.
Connection closed!
Contenuto correlato
- Altre informazioni su Come usare l'API Realtime
- Vedere le informazioni di riferimento sulle API realtime
- Altre informazioni sulle quote e i limiti di Azure OpenAI
- Altre informazioni sul supporto linguistico e vocale per il servizio Voce