Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Gli strumenti di Riconoscimento vocale di Azure in Foundry forniscono funzionalità vocali, sintesi vocale e altre funzionalità tramite una risorsa Microsoft Foundry. È possibile trascrivere il parlato in testo con alta precisione, produrre voci di sintesi vocale con audio naturale, tradurre audio parlato e condurre conversazioni vocali di intelligenza artificiale in tempo reale.

È possibile creare voci personalizzate, aggiungere parole specifiche al vocabolario di base o creare modelli personalizzati. Eseguire Voce di Azure ovunque, nel cloud o nella rete perimetrale in contenitori. Abilitare applicazioni, strumenti e dispositivi per la voce usando l'interfaccia della riga di comando di Voce, Speech SDK e le API REST.
Riconoscimento vocale di Azure è disponibile per molte lingue, aree e punti di prezzo.
Scenari
Gli scenari comuni per il riconoscimento vocale includono:
- Didascalia: Informazioni su come sincronizzare le didascalie con l'audio di input, applicare filtri per i contenuti volgari, ottenere risultati parziali, applicare personalizzazioni e identificare le lingue parlate per scenari multilingue.
- Creazione di contenuti audio: usare le voci neurali per creare interazioni con chatbot e agenti vocali più naturali e coinvolgenti, convertire testi digitali come e-book in audiobook e migliorare i sistemi di navigazione in auto.
- Call center: trascrivere le chiamate in tempo reale o elaborare un batch di chiamate, oscurare le informazioni personali ed estrarre dettagli come la valutazione per gestire il caso d'uso del call center.
- Apprendimento linguistico: fornire feedback sulla valutazione della pronuncia agli studenti di lingua, supportare la trascrizione in tempo reale per conversazioni di apprendimento remoto e leggere materiali didattici ad alta voce con voci neurali.
- Voice Live: creare interfacce conversazionali naturali e umane per applicazioni ed esperienze. La funzionalità Voice Live offre un'interazione veloce e affidabile tra un'implementazione umana e un agente.
- Traduzione vocale: generare una traduzione vocale di alta qualità in tempo reale o generare automaticamente video tradotti in un'ampia gamma di lingue.
- Creazione di avatar video: creare avatar video sintetici, realistici e di alta qualità per varie applicazioni in tempo reale e batch, garantendo le pratiche di IA responsabile.
Microsoft usa Azure Speech per molti scenari, ad esempio i sottotitoli in Microsoft Teams, la dettatura in Microsoft Office 365 e la funzione Leggi ad alta voce nel browser Microsoft Edge.
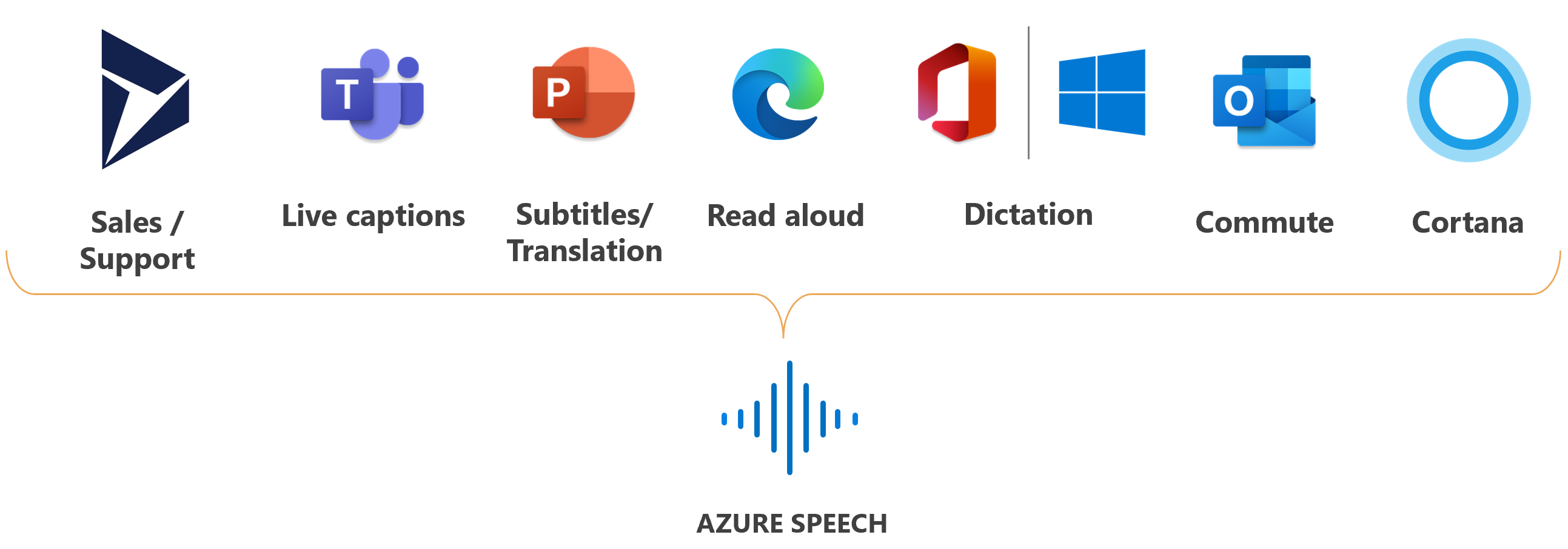
Capacità
Le sezioni seguenti riepilogano le funzionalità di Riconoscimento vocale di Azure e forniscono collegamenti per altre informazioni.
Riconoscimento vocale
Usare speech to text per convertire l'audio in testo. Scegliere tra:
- Trascrizione in tempo reale per l'audio in streaming.
- Trascrizione rapida per i file audio preregistrati.
- Trascrizione batch per l'elaborazione di volumi elevati di audio in modo asincrono.
Il modello di base potrebbe non essere sufficiente se l'audio contiene rumore ambientale o include un gergo specifico del settore e del dominio. In questi casi, è possibile creare ed eseguire il training di modelli di riconoscimento vocale personalizzati con dati acustici, linguistici e di pronuncia. I modelli di riconoscimento vocale personalizzati sono privati e possono offrire un vantaggio competitivo.
Testo di cui eseguire il riconoscimento vocale
Con la sintesi vocale, è possibile convertire il testo di input in parlato sintetizzato naturale. Usare le voci neurali, che sono voci umane basate su reti neurali profonde. Usare Speech Synthesis Markup Language (SSML) per ottimizzare il passo, la pronuncia, la frequenza di pronuncia, il volume e altro ancora.
Le opzioni vocali includono:
- Voce standard: è possibile scegliere tra voci predefinite altamente naturali. Controllare gli esempi vocali standard in Voice Gallery e determinare la voce appropriata per le esigenze aziendali.
- Voce personalizzata: è possibile creare una voce personalizzata riconoscibile e univoca per il marchio o il prodotto. Le voci personalizzate sono private e possono offrire un vantaggio competitivo. Controllare gli esempi vocali personalizzati.
Avatar sintesi vocale
L'avatar testo in voce converte il testo in un video digitale di un essere umano fotorealistico che parla con una voce naturale. Il video può essere sintetizzato in modo asincrono o in tempo reale. È possibile creare applicazioni integrate con avatar di sintesi vocale tramite un'API o usare l'avatar sintesi vocale in Foundry per creare contenuto video senza scrivere codice. La funzionalità consente di offrire video avatar di discussione sintetici e di alta qualità per varie applicazioni, rispettando al tempo stesso le procedure di IA responsabili.
È possibile scegliere tra una gamma di voci standard per l'avatar. Il supporto della lingua per l'avatar di sintesi vocale equivale al supporto linguistico per la sintesi vocale.
Traduzione vocale
La traduzione vocale consente di attivare la traduzione vocale in tempo reale e in più lingue in applicazioni, strumenti e dispositivi. Usare questa funzionalità per la traduzione vocale e la traduzione del parlato in testo.
Discorso LLM (anteprima)
Approfitta di un modello di riconoscimento vocale potenziato da un modello di linguaggio su larga scala (LLM) nel modello di linguaggio su larga scala per il riconoscimento vocale. Questa funzionalità supporta attualmente le attività seguenti:
-
transcribe: converte l'audio preregistrato in testo. -
translate: converte l'audio preregistrato in testo in una lingua di destinazione specificata.
Il modello di riconoscimento vocale avanzato con LLM offre una migliore qualità, una comprensione contestuale approfondita, un supporto multilingue e funzionalità di ottimizzazione delle richieste. Il riconoscimento vocale LLM condivide le stesse prestazioni di inferenza ultra veloci della trascrizione rapida. I casi d'uso includono la generazione di didascalie e sottotitoli da file audio, il riepilogo delle note della riunione, l'assistenza degli agenti del call center, la trascrizione di messaggi vocali e altro ancora.
Identificazione della lingua
L'identificazione della lingua consente di identificare le lingue parlate nell'audio confrontandole con un elenco di lingue supportate. Usare l'identificazione della lingua in autonomia, con il riconoscimento vocale o la traduzione vocale.
Valutazione della pronuncia
La valutazione della pronuncia valuta la pronuncia vocale e fornisce ai parlanti un feedback sull'accuratezza e sulla scorrevolezza dell'audio parlato. Usando la valutazione della pronuncia, gli studenti della lingua possono esercitarsi, ottenere feedback istantaneo e migliorare la pronuncia in modo che possano parlare e presentare con fiducia.
Consegna e presenza
È possibile distribuire le funzionalità di Riconoscimento vocale di Azure nel cloud o in locale.
Usando i contenitori, è possibile avvicinare il servizio ai dati per motivi di conformità, sicurezza o altri motivi operativi.
La distribuzione di Riconoscimento vocale di Azure nei cloud sovrani è disponibile per alcune entità governative e per i partner. Ad esempio, il cloud di Azure per enti pubblici è disponibile per le entità governative degli Stati Uniti e i relativi partner. Azure gestito dal cloud 21Vianet è disponibile per le organizzazioni che hanno una presenza aziendale in Cina. Per ulteriori informazioni, vedere Servizio di riconoscimento vocale su cloud sovrani.
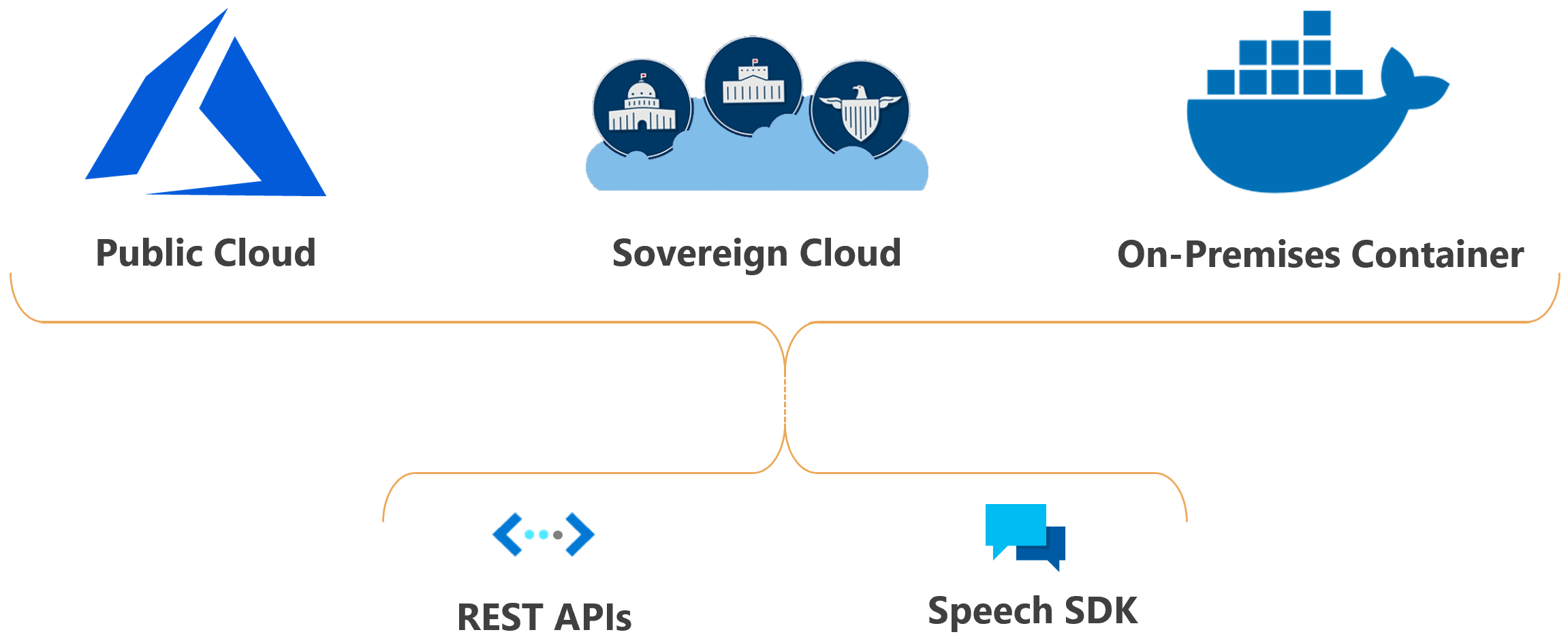
Integrazione di Riconoscimento vocale di Azure nell'applicazione
Speech Studio è un set di strumenti basati sull'interfaccia utente per la creazione e l'integrazione di funzionalità di Riconoscimento vocale di Azure nelle applicazioni. I progetti vengono creati in Speech Studio usando un approccio senza codice. È quindi possibile fare riferimento a tali asset nelle applicazioni usando:
Speech SDK. Questo SDK espone molte delle funzionalità di Riconoscimento vocale di Azure che è possibile usare per sviluppare applicazioni abilitate per il riconoscimento vocale. Speech SDK è disponibile in molti linguaggi di programmazione e in tutte le piattaforme.
CLI vocale. Con questo strumento da riga di comando è possibile usare Riconoscimento vocale di Azure senza dover scrivere codice. La maggior parte delle funzionalità di Speech SDK è disponibile nell'interfaccia della riga di comando per Voce e alcune funzionalità e personalizzazioni avanzate sono semplificate nell'interfaccia della riga di comando per Voce.
API REST. In alcuni casi, non è possibile oppure non si dovrebbe usare il Speech SDK. In questi casi, è possibile usare le API REST per accedere a Riconoscimento vocale di Azure. Ad esempio, usare le API REST per la trascrizione batch.
Esempi di codice
Il codice di esempio per Riconoscimento vocale di Azure è disponibile in GitHub. Questi esempi esaminano gli scenari comuni, ad esempio la lettura di audio da un file o streaming, il riconoscimento continuo e singolo e l'uso di modelli personalizzati. Usare i collegamenti seguenti per visualizzare esempi SDK e REST:
- Esempi di riconoscimento vocale, da testo a voce e traduzione vocale (SDK)
- Batch transcription samples (REST) (Esempi di trascrizione batch (REST))
- Esempi di Sintesi vocale (REST)
IA responsabile
Un sistema di intelligenza artificiale include non solo la tecnologia, ma anche le persone che lo usano, le persone interessate da questa tecnologia e l'ambiente in cui viene distribuita. Usare le risorse seguenti per apprendere l'uso e la distribuzione responsabili dell'intelligenza artificiale nei sistemi.
Riconoscimento vocale
- Nota sulla trasparenza e casi d'uso
- Caratteristiche e limitazioni
- Integrazione e uso responsabile
- Dati, privacy e sicurezza
Valutazione della pronuncia
Voce personalizzata
- Nota sulla trasparenza e casi d'uso
- Caratteristiche e limitazioni
- Accesso limitato
- Distribuzione responsabile della sintesi vocale
- Informativa per i talenti vocali
- Informativa per i modelli di progettazione
- Informativa per gli schemi progettuali
- Codice di comportamento
- Dati, privacy e sicurezza
Contenuti correlati
Per le funzionalità di Riconoscimento vocale di Azure sono disponibili le guide introduttive seguenti. Ogni guida introduttiva ti insegna i modelli di progettazione di base in molti dei linguaggi di programmazione più popolari e ti consentirà di eseguire il codice in meno di 10 minuti.