Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa panoramica vengono illustrati i vantaggi e le caratteristiche della funzionalità di sintesi vocale del servizio Voce, che fa parte dei servizi di Intelligenza artificiale di Azure.
La sintesi vocale consente ad applicazioni, strumenti o dispositivi di convertire il testo in una voce sintetizzata simile a quella umana. La funzionalità di sintesi vocale è nota anche come conversione da testo a voce. Usa voci standard simili a quelle umane già pronte, o crea una voce personalizzata unica per il tuo prodotto o marchio. Per un elenco completo di voci, lingue e impostazioni locali supportate, vedere Lingue e voci supportate per il servizio Voce.
Funzionalità di base
La sintesi vocale include le funzionalità seguenti:
| Funzionalità | Riassunto | Demo |
|---|---|---|
| Voce standard (denominata Neural nella pagina dei prezzi) | Voci predefinite con caratteristiche estremamente naturali. Creare una sottoscrizione di Azure e una risorsa voce e quindi usare Speech SDK o visitare il portale di Speech Studio e selezionare voci standard per iniziare. Vedere le informazioni sui prezzi. | Consultare la raccolta di voci e determinare la voce più adatta alle esigenze aziendali. |
| Voce personalizzata | Funzionalità self-service facile da usare per la creazione di una voce naturale per il marchio, con accesso limitato per l'uso responsabile. Creare una sottoscrizione di Azure e una risorsa di Azure AI Foundry e quindi applicarla per usare la voce personalizzata. Dopo che ti è stato concesso l'accesso, vai alla documentazione di ottimizzazione vocale professionale per iniziare. Vedere le informazioni sui prezzi. | Esaminare i campioni vocali. |
Altre informazioni sulle funzionalità di sintesi vocale neurale
La sintesi vocale usa reti neurali profonde per rendere le voci dei computer quasi indistinguibili dalle registrazioni delle persone. Grazie all'articolazione chiara delle parole, la sintesi vocale neurale riduce in modo significativo le difficoltà di ascolto quando gli utenti interagiscono con i sistemi di intelligenza artificiale.
I modelli di accento e intonazione nella lingua parlata sono detti prosodia. I sistemi di sintesi vocale tradizionali suddividono la prosodia in passaggi distinti di analisi linguistica e previsione acustica, regolati da modelli indipendenti. Ciò può causare scarsa nitidezza o rumori di fondo nella sintesi vocale.
Di seguito sono illustrate altre informazioni sulle funzionalità di sintesi vocale neurale nel servizio Voce e su come queste consentano di superare i limiti dei sistemi di sintesi vocale tradizionali:
Sintesi vocale in tempo reale: usare Speech SDK o l'API REST per convertire il testo in voce usando voci standard o voci personalizzate.
Sintesi asincrona di audio di lunga durata: tramite l'API di sintesi batch viene sintetizzare in modo asincrono il testo in file di sintesi vocali più lunghi di 10 minuti (ad esempio, audiolibri o conferenze). A differenza della sintesi eseguita tramite Speech SDK o l'API REST di riconoscimento vocale, le risposte non vengono restituite in tempo reale. L'idea è che le richieste vengono inviate in modo asincrono, viene effettuato il polling delle risposte e l'audio sintetizzato viene scaricato quando il servizio lo rende disponibile.
Voci standard: Riconoscimento vocale di Azure usa reti neurali profonde per superare i limiti della sintesi vocale tradizionale relativa allo stress e all'intonazione nel linguaggio parlato. La previsione della prosodia e la sintesi vocale avvengono simultaneamente, con risultati più fluidi e naturali. Ogni modello vocale standard è disponibile a 24 kHz e ad alta fedeltà a 48 kHz. È possibile usare le voci neurali per:
- Rendere le interazioni con chatbot e assistenti vocali più naturali e coinvolgenti.
- Convertire testi digitali come gli e-book in audiolibri.
- Migliorare i sistemi di navigazione per le auto.
Per un elenco completo delle voci neurali standard di Azure AI Speech, vedere Lingua e supporto vocale per il servizio Voce.
Migliorare l'output della sintesi vocale con SSML: Speech Synthesis Markup Language (SSML) è un linguaggio di markup basato su XML usato per personalizzare gli output della sintesi vocale. Con SSML è possibile modificare il tono, aggiungere pause, migliorare la pronuncia, modificare la velocità del parlato, regolare il volume e attribuire più voci a un singolo documento.
È possibile usare SSML per definire un lessico personalizzato o passare a modi di parlare diversi. Con le voci multilingue, è anche possibile modificare la lingua parlata tramite SSML. Per migliorare l'output vocale per uno scenario specifico, vedere Migliorare la sintesi con Speech Synthesis Markup Language e Sintesi vocale con lo strumento Creazione di contenuto audio.
Visemi: i visemi sono le posizioni chiave quando si osserva una persona che parla, tra cui la posizione delle labbra, della mascella e della lingua nella produzione di un particolare fonema. I visemi hanno una forte correlazione con voci e fonemi.
Usando gli eventi dei visemi in Speech SDK, è possibile generare dati di animazione facciale. Questi dati possono essere usati per animare i visi nelle comunicazioni basate sulla lettura labiale, per l'istruzione, per l'intrattenimento e per l'assistenza clienti. Il visema è attualmente supportato solo per le
en-USper la lingua (inglese Stati Uniti).
Annotazioni
Oltre alle voci neurali non HD (Speech Neural) di Azure per intelligenza artificiale, è anche possibile usare le voci HD (Speech High Definition) di Voce di Azure AI e le voci neurali (HD e non HD) di Azure OpenAI. Le voci HD offrono una qualità più elevata per scenari più versatili.
Alcune voci non supportano tutti i tag SSML (Speech Synthesis Markup Language). Sono inclusi testo neurale per voce HD, voci personali e voci incorporate.
- Per le voci HD (Speech High Definition) di Azure per intelligenza artificiale, vedere il supporto di SSML qui.
- Per la voce personale, è possibile trovare il supporto SSML qui.
- Per le voci incorporate, vedere il supporto di SSML qui.
Introduzione
Per iniziare a usare la sintesi vocale, vedere la guida di avvio rapido. La sintesi vocale è disponibile tramite Speech SDK, l'API REST e l'interfaccia della riga di comando del servizio Voce.
Suggerimento
Per eseguire la sintesi vocale con un approccio senza codice, provare lo strumento Creazione di contenuto audio in Speech Studio.
Codice di esempio
Il codice di esempio per la sintesi vocale è disponibile in GitHub. Questi esempi illustrano la sintesi vocale nei linguaggi di programmazione più diffusi:
Voce personalizzata
Oltre alle voci standard, è possibile creare voci personalizzate uniche per il prodotto o il marchio. La voce personalizzata è un termine generico che include l'ottimizzazione vocale professionale e la voce personale. Per iniziare, sono sufficienti alcuni file audio e le trascrizioni associate. Per altre informazioni, vedere la documentazione sull'ottimizzazione vocale professionale.
Nota sui prezzi
Caratteri fatturabili
Quando si usa la funzionalità di sintesi vocale, viene addebitato un costo per ogni carattere convertito in parlato, inclusa la punteggiatura. Anche se il documento SSML stesso non è fatturabile, gli elementi facoltativi usati per definire il modo in cui il testo viene convertito in parlato, ad esempio i fonemi e il tono, vengono conteggiati come caratteri fatturabili. Ecco un elenco degli elementi fatturabili:
- Testo passato alla funzionalità di sintesi vocale nel corpo SSML della richiesta
- Tutto il markup all'interno del campo di testo del corpo della richiesta nel formato SSML, ad eccezione dei tag
<speak>e<voice> - Lettere, punteggiatura, spazi, tabulazioni, markup e tutti gli spazi vuoti
- Ogni elemento di codice definito in Unicode
Per informazioni dettagliate, vedere Prezzi del servizio Voce.
Importante
Ogni carattere cinese viene conteggiato come due caratteri ai fini della fatturazione, inclusi i caratteri kanji usati in giapponese, hanja usati in coreano o hanzi usati in altre lingue.
Tempo di addestramento del modello e tempo di hosting per la voce personalizzata
Il training e l'hosting di Sintesi vocale vengono calcolati per ora e fatturati al secondo. Per il prezzo unitario di fatturazione, vedere Prezzi del servizio Voce.
Il tempo di ottimizzazione vocale professionale viene misurato in base all'ora di calcolo (un'unità per misurare il tempo di esecuzione del computer). In genere, quando si esegue il training di un modello vocale, vengono eseguite in parallelo due attività di calcolo. Le ore di calcolo conteggiate sono pertanto maggiori del tempo di training effettivo. Per l'ottimizzazione della voce professionale, in genere sono necessarie da 20 a 40 ore di calcolo per eseguire il training di una voce di tipo singolo e circa 90 ore di calcolo per eseguire il training di una voce multi-stile. Il tempo di ottimizzazione della voce professionale viene fatturato con un limite di 96 ore di calcolo. Nel caso in cui venga eseguito il training di un modello vocale in 98 ore di calcolo, vengono quindi addebitate solo 96 ore di calcolo.
L'hosting dell'endpoint vocale personalizzato viene misurato in base all'ora effettiva (ora). Il tempo di hosting (ore) per ogni endpoint viene calcolato alle 00:00 UTC ogni giorno per le 24 ore precedenti. Se, ad esempio, l'endpoint è stato attivo per 24 ore il giorno 1, vengono addebitate 24 ore alle 00:00 UTC del secondo giorno. Se l'endpoint è stato appena creato o sospeso durante il giorno, viene addebitato il tempo di esecuzione accumulato fino alle 00:00 UTC del secondo giorno. Se l'endpoint non è attualmente ospitato, non viene fatturato. Oltre al calcolo giornaliero eseguito alle 00:00 UTC di ogni giorno, la fatturazione viene attivata immediatamente quando un endpoint viene eliminato o sospeso. Ad esempio, per un endpoint creato alle 08:00 UTC il 1° dicembre, il tempo di hosting viene calcolato come 16 ore alle 00:00 UTC del 2 dicembre e 24 ore alle 00:00 UTC del 3 dicembre. Se l'utente sospende l'hosting dell'endpoint alle 16:30 UTC del 3 dicembre, per la fatturazione verrà calcolata la durata (16,5 ore) dalle 00:00 alle 16:30 UTC del 3 dicembre.
Voce neurale personalizzata
Quando si usa la funzionalità voce personale, vengono fatturati sia l'archiviazione del profilo che la sintesi.
- Archiviazione dei profili: dopo la creazione di un profilo vocale personale, verrà fatturata fino a quando non viene rimossa dal sistema. L'unità di fatturazione è per voce al giorno. Se l'archiviazione vocale dura meno di 24 ore, viene comunque fatturata come un giorno intero.
- Sintesi: viene fatturata per carattere. Per informazioni dettagliate sui caratteri fatturabili, vedere la sezione relativa ai caratteri fatturabili precedente.
Avatar di Sintesi vocale
Quando si usa la funzionalità avatar di sintesi vocale, gli addebiti vengono fatturati al secondo in base alla lunghezza dell'output video. Tuttavia, per l'avatar in tempo reale, gli addebiti vengono fatturati al secondo in base al momento in cui l'avatar è attivo, indipendentemente dal fatto che stia parlando o resti silenzioso. Per ottimizzare i costi per l'utilizzo dell'avatar in tempo reale, fare riferimento ai suggerimenti "Usa video locale per inattività" forniti nel codice di esempio di chat avatar.
Il training personalizzato dell'avatar per il riconoscimento vocale è il tempo misurato da "ora di calcolo" (tempo di esecuzione del computer) e fatturato al secondo. La durata del training varia a seconda della quantità di dati usata. In genere sono necessarie 20-40 ore di calcolo in media per eseguire il training di un avatar personalizzato. Il tempo di training dell'avatar viene fatturato con un limite di 96 ore di calcolo. Pertanto, nel caso in cui un modello avatar venga sottoposto a training in 98 ore di calcolo, viene addebitato solo l'addebito per 96 ore di calcolo.
L'hosting dell’avatar viene fatturato al secondo per endpoint. È possibile sospendere l'endpoint per risparmiare sui costi. Per sospendere l'endpoint, è possibile eliminarlo direttamente. Per usarlo di nuovo, ridistribuire l'endpoint.
Monitorare le metriche di sintesi vocale di Azure
Il monitoraggio delle metriche chiave associate ai servizi di sintesi vocale è fondamentale per la gestione dell'utilizzo delle risorse e il controllo dei costi. Questa sezione illustra come trovare informazioni sull'utilizzo nel portale di Azure e fornire definizioni dettagliate delle metriche chiave. Per altre informazioni sulle metriche di Monitoraggio di Azure, vedere Panoramica delle metriche di Monitoraggio di Azure.
Come trovare informazioni sull'utilizzo nel portale di Azure
Per gestire in modo efficace le risorse di Azure, è essenziale accedere ed esaminare regolarmente le informazioni sull'utilizzo. Ecco come trovare le informazioni sull'utilizzo:
Passare al portale di Azure e accedere con il proprio account Azure.
Passare a Risorse e selezionare la risorsa da monitorare.
Selezionare Metriche in Monitoraggio dal menu a sinistra.
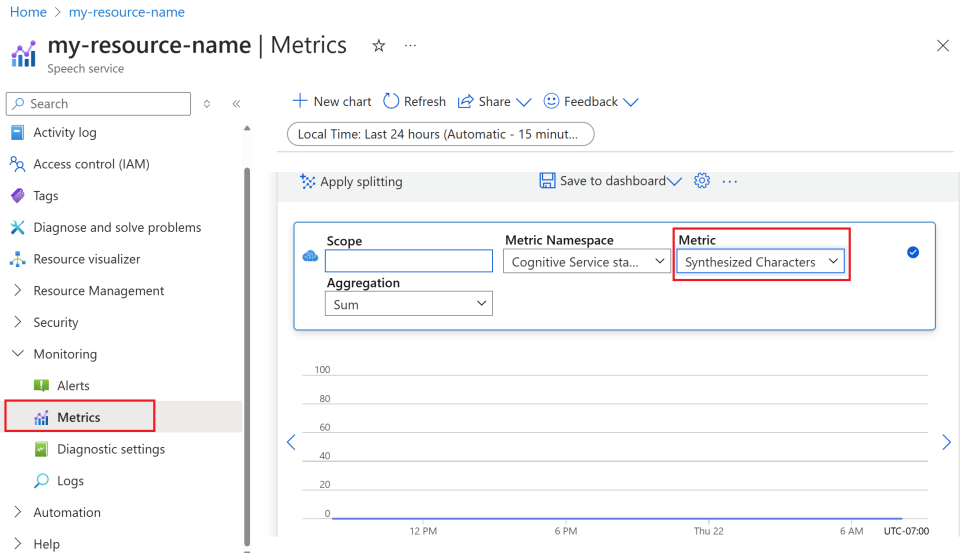
Personalizzare le visualizzazioni delle metriche.
È possibile filtrare i dati in base al tipo di risorsa, al tipo di metrica, all'intervallo di tempo e ad altri parametri per creare visualizzazioni personalizzate allineate alle esigenze di monitoraggio. È anche possibile salvare la visualizzazione delle metriche nei dashboard selezionando Salva nel dashboard per semplificare l'accesso alle metriche usate di frequente.
Configurare gli avvisi.
Per gestire l'utilizzo in modo più efficace, configurare gli avvisi passando alla scheda Avvisi in Monitoraggio dal menu a sinistra. Gli avvisi possono inviare notifiche quando l'utilizzo raggiunge soglie specifiche, evitando costi imprevisti.
Definizione delle metriche
Ecco una tabella che riepiloga le metriche chiave per il riconoscimento vocale del testo di Azure.
| Nome metrica | Descrizione |
|---|---|
| Caratteri sintetizzati | Tiene traccia del numero di caratteri convertiti in parlato, inclusa la voce standard e la voce personalizzata. Per informazioni dettagliate sui caratteri fatturabili, vedere Caratteri fatturabili. |
| Video secondi sintetizzati | Misura la durata totale del video sintetizzato, tra cui la sintesi avatar batch, la sintesi avatar in tempo reale e la sintesi avatar personalizzata. |
| Modello avatar che ospita secondi | Tiene traccia del tempo totale in secondi in cui è ospitato il modello avatar personalizzato. |
| Ore di hosting del modello vocale | Tiene traccia del tempo totale, espresso in ore, in cui il modello vocale personalizzato è ospitato. |
| Minuti di training del modello vocale | Misura il tempo totale in minuti per il training del modello vocale personalizzato. |
Documentazione di riferimento
IA responsabile
Un sistema di intelligenza artificiale include non solo la tecnologia ma anche le persone che ne fanno uso, le persone interessate e l'ambiente di distribuzione. Leggere le note sulla trasparenza per informazioni sull'uso e sulla distribuzione dell'intelligenza artificiale responsabile nei propri sistemi.
- Note sulla trasparenza e casi d'uso per la voce personalizzata
- Caratteristiche e limitazioni per l'uso della voce personalizzata
- Accesso limitato alla voce personalizzata
- Linee guida per la distribuzione responsabile della tecnologia vocale sintetica
- Informativa per i talenti vocali
- Linee guida sulla progettazione di informative
- Modelli di progettazione della divulgazione
- Codice di comportamento per le integrazioni di sintesi vocale
- Dati, privacy e sicurezza per la voce personalizzata