Aggiungere un set di dati di training per la voce neurale professionale
Quando si è pronti per creare una voce di sintesi vocale personalizzata per l'applicazione, il primo passaggio consiste nel raccogliere le registrazioni audio e gli script associati per avviare il training del modello vocale. Per informazioni dettagliate sulla registrazione di campioni vocali, vedere l'esercitazione. Il Servizio voce usa questi dati per creare un'intonazione vocale unica che corrisponda alla voce nelle registrazioni. Dopo aver eseguito il training della voce, è possibile iniziare a sintetizzare il parlato nelle applicazioni.
Tutti i dati caricati devono soddisfare i requisiti del tipo di dati scelto. È importante formattare correttamente i dati prima di caricarli, in modo da garantirne l'elaborazione accurata da parte del Servizio voce. Per verificare che i dati siano formattati correttamente, vedere Tipi di dati di training.
Nota
- Gli utenti con una sottoscrizione Standard (S0) possono caricare cinque file di dati contemporaneamente. Se si raggiunge il limite, attendere il completamento dell'importazione di almeno uno dei file di dati. Quindi riprovare.
- Il numero massimo di file di dati che è consentito importare per ogni sottoscrizione è di 500 file .zip per gli utenti della sottoscrizione standard (S0). Per altre informazioni, vedere quote e limiti del servizio Voce.
Caricare i dati
Quando si è pronti a caricare i dati, passare alla scheda Prepara i dati di training per aggiungere il primo set di training e caricare i dati. Un set di training è un insieme di espressioni audio e i relativi script di mapping usati per il training di un modello vocale. È possibile usare un set di training per organizzare i dati di training. Il servizio verifica la disponibilità dei dati per ogni set di training. È possibile importare più dati in un set di training.
Per caricare i dati di training, seguire questa procedura:
- Accedere a Speech Studio.
- Selezionare Voce personalizzata> Nome progetto >Preparare i dati di training>Caricare i dati.
- Nella procedura guidata Carica dati scegliere un tipo di dati e quindi selezionare Avanti.
- Selezionare i file locali dal computer o immettere l'URL di Archivio BLOB di Azure per caricare i dati.
- In Specificare il set di training di destinazione, selezionare un set di training esistente o crearne uno nuovo. Se è stato creato un nuovo set di training, assicurarsi che sia selezionato nell'elenco a discesa prima di continuare.
- Selezionare Avanti.
- Immettere un nome e una descrizione per i dati, quindi selezionare Avanti.
- Esaminare i dettagli di caricamento e selezionare Invia.
Nota
Gli ID duplicati non vengono accettati. Le espressioni con lo stesso ID verranno rimosse.
I nomi audio duplicati vengono rimossi dal training. Assicurarsi che i dati selezionati non contengano gli stessi nomi audio all'interno del file .zip o in più file .zip. Se gli ID delle espressioni (nei file audio o script) sono duplicati, vengono rifiutati.
I file di dati vengono convalidati automaticamente quando si seleziona Invia. La convalida dei dati include una serie di controlli sui file audio per verificare il formato dei file, le dimensioni e la frequenza di campionamento. In caso di errori, correggerli e inviarli di nuovo.
Dopo aver caricato i dati, è possibile controllare i dettagli nella visualizzazione dei dettagli del set di training. Nella pagina dei dettagli è possibile controllare ulteriormente il problema della pronuncia e il livello di rumore per ognuno dei dati. Il punteggio di pronuncia a livello di frase varia da 0 a 100. Un punteggio della pronuncia inferiore a 70 generalmente indica un errore di riconoscimento vocale o una mancata corrispondenza dello script. Le espressioni con un punteggio complessivo inferiore a 70 verranno rifiutate. Un forte accento può ridurre il punteggio di pronuncia e influire sulla voce digitale generata.
Risolvere i problemi dei dati online
Dopo il caricamento, è possibile controllare i dettagli dei dati del set di training. Prima di continuare a eseguire il training del modello vocale, è necessario provare a risolvere eventuali problemi relativi ai dati.
È possibile identificare e risolvere i problemi di dati per ogni espressione in Speech Studio.
Nella pagina dei dettagli passare alla pagina Dati accettati o Dati rifiutati. Selezionare singole espressioni da modificare, quindi selezionare Modifica.
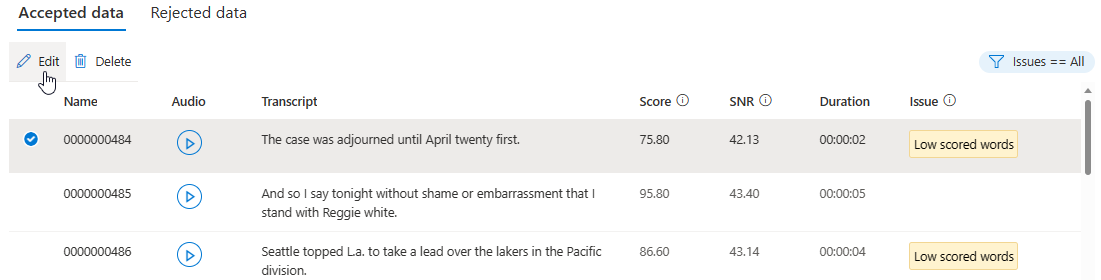
È possibile scegliere quali problemi di dati visualizzare in base ai propri criteri.
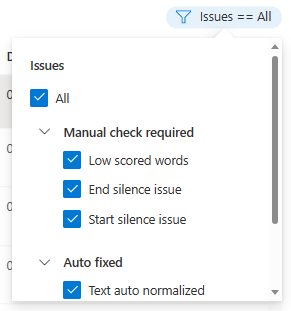
Verrà visualizzata la finestra di modifica.
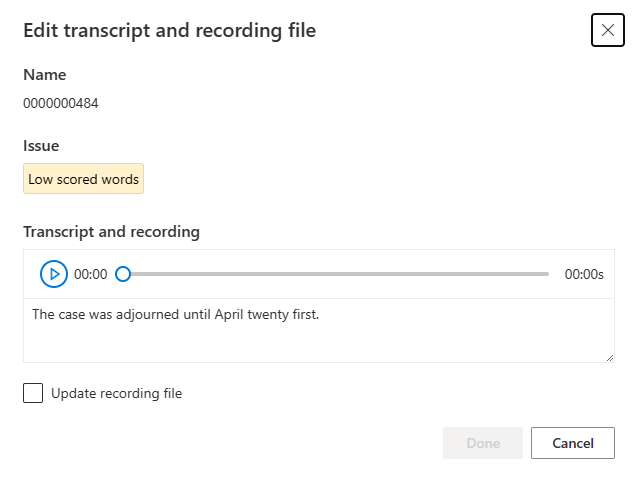
Aggiornare la trascrizione o il file di registrazione in base alla descrizione del problema nella finestra di modifica.
È possibile modificare la trascrizione nella casella di testo, quindi selezionare Fine
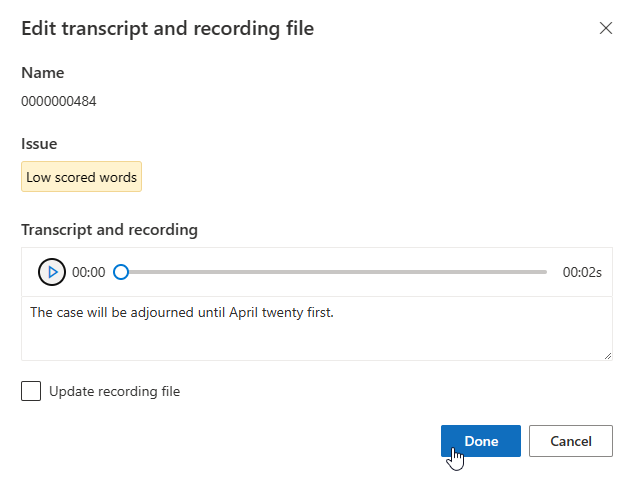
Se è necessario aggiornare il file di registrazione, selezionare Aggiorna file di registrazione, quindi caricare il file di registrazione fisso (.wav).
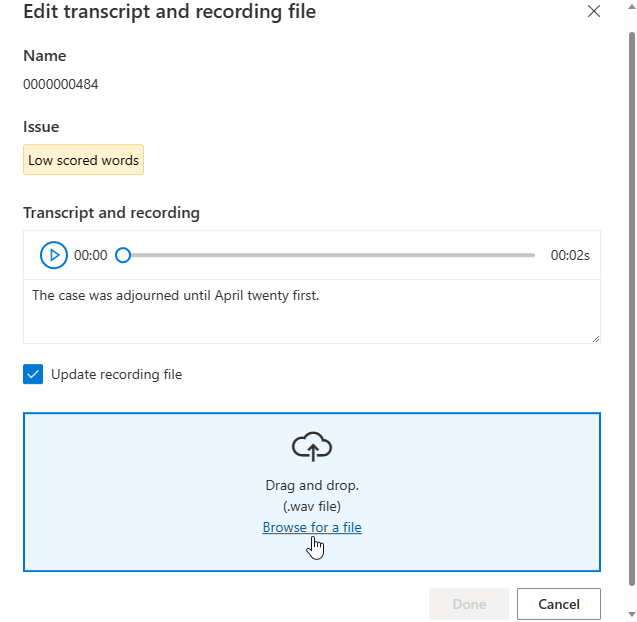
Dopo aver apportato le modifiche ai dati, è necessario verificare la qualità dei dati facendo clic su Analizza dati prima di usare questo set di dati per il training.
Non è possibile selezionare questo set di training per il modello di training prima del completamento dell'analisi.
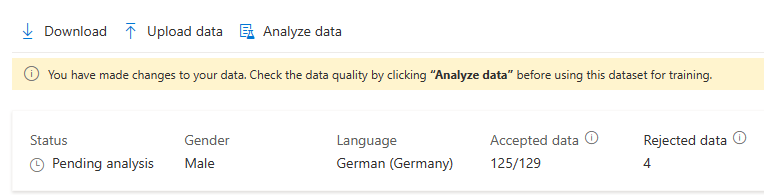
È anche possibile eliminare le espressioni con problemi selezionandole e facendo clic su Elimina.
Problemi tipici dei dati
I problemi si dividono in tre tipi. Fare riferimento alle tabelle seguenti per controllare i rispettivi tipi di errore.
Rifiutato automaticamente
I dati con questi errori non verranno usati per il training. I dati importati con errori verranno ignorati, quindi non è necessario eliminarli. È possibile correggere questi errori di dati online o caricare nuovamente i dati corretti per il training.
| Categoria | Nome | Descrizione |
|---|---|---|
| Script | Separatore non valido | È necessario separare l'ID dell'espressione e il contenuto dello script con un carattere Tab. |
| Script | ID script non valido | L'ID riga di script deve essere numerico. |
| Script | Script duplicato | Ogni riga del contenuto dello script deve essere univoca. La riga viene duplicata con {}. |
| Script | Script troppo lungo | Lo script deve essere inferiore a 1,000 caratteri. |
| Script | Nessun audio corrispondente | L'ID di ogni espressione (ogni riga del file di script) deve corrispondere all'ID audio. |
| Script | Nessuno script valido | Nessun script valido trovato in questo set di dati. Correggere le righe di script visualizzate nell'elenco dettagliato dei problemi. |
| Audio | Nessuno script corrispondente | Nessun file audio corrisponde all'ID dello script. Il nome dei file .wav deve corrispondere agli ID del file di script. |
| Audio | Formato audio non valido | Il formato audio dei file .wav non è valido. Controllare il formato di file .wav usando uno strumento audio come SoX. |
| Audio | Frequenza di campionamento bassa | La frequenza di campionamento dei file .wav non può essere inferiore a 16 KHz. |
| Audio | Audio troppo lungo | La durata dell'audio è superiore a 30 secondi. Suddividere l'audio lungo in più file. È consigliabile rendere le espressioni più brevi di 15 secondi. |
| Audio | Nessun audio valido | Nessun audio valido trovato in questo set di dati. Controllare i dati audio e caricarli di nuovo. |
| Mancata corrispondenza | Espressione con punteggio basso | Il punteggio della pronuncia a livello di frase è inferiore a 70. Rivedere lo script e il contenuto audio per assicurarsi che corrispondano. |
Corretto automaticamente
Gli errori seguenti vengono corretti automaticamente, ma è necessario controllare e verificare che le correzioni siano state effettuate correttamente.
| Categoria | Nome | Descrizione |
|---|---|---|
| Mancata corrispondenza | Correzione automatica del silenzio | Il silenzio iniziale è stato rilevato come più breve di 100 ms ed è stato esteso automaticamente a 100 ms. Scaricare il set di dati normalizzato ed esaminarlo. |
| Mancata corrispondenza | Correzione automatica del silenzio | Il silenzio finale è stato rilevato come più breve di 100 ms ed è stato esteso automaticamente a 100 ms. Scaricare il set di dati normalizzato ed esaminarlo. |
| Script | Testo normalizzato automaticamente | Il testo viene normalizzato automaticamente per cifre, simboli e abbreviazioni. Rivedere il copione e l'audio per verificare che corrispondano. |
Controllo manuale obbligatorio
Gli errori non risolti elencati nella tabella successiva influiscono sulla qualità del training, ma i dati con questi errori non verranno esclusi durante il training. Per un training di qualità superiore, è consigliabile correggere manualmente questi errori.
| Categoria | Nome | Descrizione |
|---|---|---|
| Script | Testo non normalizzato | Questo script contiene simboli. Normalizzare i simboli in modo che corrispondano all'audio. Ad esempio, normalizzare / per barra. |
| Script | Espressioni di domanda non sufficienti | Almeno il 10% del totale delle espressioni deve essere costituito da frasi interrogative. In questo modo il modello vocale esprime correttamente il tono interrogativo. |
| Script | Espressioni esclamative non sufficienti | Almeno il 10% del totale delle espressioni deve essere costituito da frasi esclamative. In questo modo il modello vocale esprime correttamente un tono eccitato. |
| Script | Nessuna punteggiatura finale valida | Aggiungere uno dei seguenti elementi alla fine della riga: un punto fermo (metà larghezza '.' o larghezza intera '。'), punto esclamativo (a metà larghezza '!' o a larghezza intera '!), o punto interrogativo (a metà larghezza '?' o a larghezza intera '?'). |
| Audio | Bassa frequenza di campionamento per la voce neurale | È consigliabile che la frequenza di campionamento dei file .wav sia di 24 KHz o superiore per creare voci neurali. Se è inferiore, verrà automaticamente elevata a 24 KHz. |
| Volume | Volume complessivo troppo basso | Il volume non dovrebbe essere inferiore a -18 dB (10% del volume massimo). Controllare il livello medio del volume entro l'intervallo corretto durante la registrazione del campione o la preparazione dei dati. |
| Volume | Overflow del volume | Il volume di overflow viene rilevato in corrispondenza di {}. Regolare l'apparecchiatura di registrazione per evitare l'overflow del volume al suo valore di picco. |
| Volume | Problema del silenzio iniziale | I primi 100 ms di silenzio non sono puliti. Ridurre il livello di rumore di fondo della registrazione e lasciare i primi 100 ms all'inizio in silenzio. |
| Volume | Problema di chiusura del silenzio | Gli ultimi 100 ms di silenzio non sono puliti. Ridurre il livello di rumore di fondo della registrazione e lasciare gli ultimi 100 ms alla fine in silenzio. |
| Mancata corrispondenza | Parole con punteggio basso | Rivedere lo script e il contenuto audio per assicurarsi che corrispondano e controllare il livello di rumore di fondo. Ridurre la lunghezza dei lunghi silenzi o dividere l'audio in più espressioni se è troppo lungo. |
| Mancata corrispondenza | Problema del silenzio iniziale | L'audio aggiuntivo è stato ascoltato prima della prima parola. Rivedere lo script e il contenuto audio per assicurarsi che corrispondano, controllare il livello di rumore di fondo e rendere i primi 100 ms silenziosi. |
| Mancata corrispondenza | Problema di chiusura del silenzio | Dopo l'ultima parola si è sentito un audio aggiuntivo. Rivedere lo script e il contenuto audio per assicurarsi che corrispondano, controllare il livello di rumore di fondo e rendere gli ultimi 100 ms silenziosi. |
| Mancata corrispondenza | Basso rapporto segnale-rumore | Il livello SNR audio è inferiore a 20 dB. È consigliabile selezionare almeno 35 dB. |
| Mancata corrispondenza | Nessun punteggio disponibile | Non è stato possibile riconoscere il contenuto vocale in questo audio. Controllare l'audio e il contenuto dello script per verificare che l'audio sia valido e corrisponda allo script. |
Passaggi successivi
È necessario un set di dati di training per creare una voce neurale professionale. Un set di dati di training include file audio e file di script. I file audio sono registrazioni del talento vocale che legge i file di script. I file di script sono il testo dei file audio.
In questo articolo si crea un set di training e si ottiene l'ID della risorsa. Quindi, usando l'ID della risorsa, è possibile caricare un set di file audio e file di script.
Creare un set di training
Per creare un set di training, usare l'operazione TrainingSets_Create dell'API vocale personalizzata. Creare il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà
projectIdobbligatoria. Vedere creare un progetto. - Impostare la proprietà
voiceKindobbligatoria suMaleo suFemale. Il tipo non può essere modificato in un secondo momento. - Impostare la proprietà
localeobbligatoria. Usare le impostazioni locali dei dati del set di training. Le impostazioni locali del set di training devono corrispondere alle impostazioni locali dell'istruzione di consenso. Le impostazioni locali non possono essere modificate in un secondo momento. Qui è possibile trovare l'elenco delle impostazioni locali di sintesi vocale. - Facoltativamente, impostare la proprietà
descriptionper la descrizione del set di training. La descrizione del set di training può essere modificata in un secondo momento.
Effettuare una richiesta HTTP PUT usando l'URI come illustrato nell'esempio di TrainingSets_Create seguente.
- Sostituire
YourResourceKeycon la chiave della risorsa Voce. - Sostituire
YourResourceRegioncon l'area della risorsa Voce. - Sostituire
JessicaTrainingSetIdcon un ID set di training di propria scelta. L'ID con distinzione tra maiuscole e minuscole verrà usato nell'URI del set di training e non può essere modificato in un secondo momento.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2023-12-01-preview"
Dovrebbe essere visualizzato un corpo della risposta nel formato seguente:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Caricare i dati del set di training
Per caricare un set di training di audio e script, usare l'operazione TrainingSets_UploadData dell'API vocale personalizzata.
Prima di chiamare questa API, archiviare i file di registrazione e di script nel BLOB di Azure. Nell'esempio seguente, i file di registrazione sono https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav, i file di script sono https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Creare il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà
kindobbligatoria suAudioAndScript. Il tipo determina il tipo di set di training. - Impostare la proprietà
audiosobbligatoria. All'interno della proprietàaudiosimpostare le proprietà seguenti:- Impostare la proprietà
containerUrlobbligatoria sull'URL del contenitore di Archiviazione BLOB di Azure che contiene i file audio. Usare la firma di accesso condiviso (SAS) per un contenitore con autorizzazioni di lettura ed elenco. - Impostare la proprietà
extensionsobbligatoria sulle estensioni dei file audio. - Facoltativamente, impostare la proprietà
prefixper impostare un prefisso per il nome del BLOB.
- Impostare la proprietà
- Impostare la proprietà
scriptsobbligatoria. All'interno della proprietàscriptsimpostare le proprietà seguenti:- Impostare la proprietà
containerUrlobbligatoria sull'URL del contenitore di Archiviazione BLOB di Azure che contiene i file di script. Usare la firma di accesso condiviso (SAS) per un contenitore con autorizzazioni di lettura ed elenco. - Impostare la proprietà
extensionsobbligatoria sulle estensioni dei file di script. - Facoltativamente, impostare la proprietà
prefixper impostare un prefisso per il nome del BLOB.
- Impostare la proprietà
Effettuare una richiesta HTTP POST usando l'URI come illustrato nell'esempio di TrainingSets_UploadData seguente.
- Sostituire
YourResourceKeycon la chiave della risorsa Voce. - Sostituire
YourResourceRegioncon l'area della risorsa Voce. - Sostituire
JessicaTrainingSetIdse è stato specificato un ID set di training diverso nel passaggio precedente.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2023-12-01-preview"
L'intestazione della risposta contiene la proprietà Operation-Location. Usare questo URI per ottenere informazioni dettagliate sull'operazione di TrainingSets_UploadData. Ecco un esempio dell'intestazione della risposta:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2023-12-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per