Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo offre procedure consigliate per la preparazione di esempi vocali di alta qualità per l'ottimizzazione della voce professionale. Per comprendere come vengono elaborati i dati e i requisiti minimi per l'accettazione dei dati, vedere Caricare i dati.
La creazione di una voce professionale di alta qualità da zero non è un'impresa casuale. Il componente centrale di una voce personalizzata è una grande raccolta di campioni audio di riconoscimento vocale umano. È fondamentale che queste registrazioni audio siano di alta qualità. È necessario pertanto scegliere un talento vocale con esperienza in questi tipi di registrazioni e affidare la registrazione a un tecnico del suono che usi apparecchiature professionali.
Prima di eseguire queste registrazioni, tuttavia, è necessario creare uno script costituito dalle parole che vengono lette dal talento vocale per realizzare i campioni audio.
Per creare una registrazione vocale di livello professionale, è necessario fare attenzione a molti piccoli dettagli, che sono tuttavia estremamente importanti. Questa guida è una roadmap di un processo che consente di ottenere risultati validi e coerenti.
Suggerimenti per la preparazione dei dati per una voce di alta qualità
Una voce personalizzata altamente naturale dipende da diversi fattori, ad esempio la qualità e le dimensioni dei dati di training.
La qualità dei dati di training è un fattore principale. Ad esempio, nello stesso set di training, un volume costante, un rateo di parlata, una tonalità di parlata e uno stile di parlata coerenti sono essenziali per creare una voce personalizzata di alta qualità. È anche consigliabile evitare rumori di fondo nella registrazione e assicurarsi che lo script e la registrazione corrispondano. Per garantire la qualità dei dati, è necessario seguire i criteri di selezione dello script e i requisiti di registrazione.
Per quanto riguarda le dimensioni dei dati di training, nella maggior parte dei casi è possibile creare una voce personalizzata ragionevole con 300 espressioni. In base ai test, l'aggiunta di più dati di training nella maggior parte dei linguaggi non migliora necessariamente la naturalezza della voce stessa (testata usando il punteggio MOS) ma, con più dati di training che coprono più istanze di parole, è possibile ridurre la percentuale di parti del discorso insoddisfacenti per la voce, ad esempio glitch. Per ascoltare le parti insoddisfacenti del suono vocale, vedere gli esempi di GitHub.
In alcuni casi, si potrebbe volere un utente vocale con caratteristiche uniche. Ad esempio, un personaggio animato ha bisogno di una voce con uno stile di pronuncia particolare o una voce con un’intonazione dinamica. Per questi casi, è consigliabile preparare almeno 1000 espressioni (preferibilmente 2000) e registrarle in uno studio di registrazione professionale. Per altre informazioni su come migliorare la qualità del modello vocale, vedere caratteristiche e limitazioni per l'uso della voce personalizzata.
Ruoli nella registrazione vocale
Esistono quattro ruoli di base in un progetto di registrazione vocale personalizzato:
| Ruolo | Scopo |
|---|---|
| Talento vocale | La voce di questa persona costituisce la base della voce personalizzata. |
| Tecnico di registrazione | Controlla gli aspetti tecnici della registrazione e fa funzionare le apparecchiature di registrazione. |
| Responsabile | Prepara lo script e sovrintende alle prestazioni del talento vocale. |
| Redattore | Finalizza i file audio e li prepara per il caricamento nel servizio Voce. |
Una singola persona può ricoprire più di un ruolo. In questa guida si presuppone che l'utente ricopra il ruolo di responsabile e che recluti sia un talento vocale che un tecnico di registrazione. Nel caso in cui si voglia eseguire in modo autonomo le registrazioni, nell'articolo sono presenti alcune informazioni sul ruolo di tecnico di registrazione. Il ruolo di editor non è necessario fino a quando non viene eseguita la sessione di registrazione. Nel frattempo, il responsabile e il tecnico di registrazione possono assumere questo ruolo.
Scegliere il talento vocale
Gli attori con esperienza nel doppiaggio, nel lavoro con la voce dei personaggi, nell'annuncio o nella lettura di notizie sono degli ottimi talenti vocali. Scegliere un talento vocale con la voce naturale che si preferisce. È possibile creare voci uniche per il "personaggio", ma per la maggior parte dei talenti risulta più difficile riprodurle in modo uniforme e lo sforzo può provocare tensione nella voce. Il fattore più importante per la scelta di un talento vocale è l'uniformità. Le registrazioni per lo stesso stile di voce dovrebbero sembrare tutte come se fossero state fatte nello stesso giorno nella stessa stanza. È possibile avvicinarsi a questa situazione ideale tramite procedure e tecniche ottimali di registrazione.
Il talento vocale deve essere in grado di parlare con velocità, livello di volume, intonazione e tono uniformi con dettatura chiara. Devono anche essere in grado di controllare la variazione dell’intonazione, l'effetto emotivo e i manierismi vocali. La registrazione di campioni vocali può essere più faticosa rispetto ad altri tipi di lavoro vocale, quindi la maggior parte dei talenti vocali può registrare solo per due o tre ore al giorno. Limitare le sessioni a tre o quattro giorni alla settimana, con un giorno di riposo tra l'una e l'altra, se possibile.
Lavora con il tuo talento vocale per sviluppare un personaggio che definisce il suono complessivo e il tono emotivo della voce personalizzata. Definire gli stili di pronuncia per il personaggio e chiedere al talento vocale di leggere lo script in modo che sia allineato agli stili desiderati. Assicurarsi che lo stile di pronuncia rimanga uniforme in tutte le registrazioni per un set di dati di training.
Ad esempio, un personaggio con una personalità naturalmente allegra avrebbe una nota di ottimismo nella voce. Tuttavia, questa personalità deve essere espressa in modo uniforme in tutte le registrazioni per un set di dati di training. Ascoltare le voci esistenti per avere un'idea di ciò che si sta cercando.
Suggerimento
In genere è consigliabile essere proprietari delle registrazioni vocali eseguite. Il talento vocale deve essere pertanto disponibile a prestare la propria opera su commissione per il progetto.
Creare uno script
Il punto iniziale di qualsiasi sessione di registrazione vocale personalizzata è lo script, che contiene le espressioni da pronunciare con il proprio voice talent. Con il termine "espressioni" si indicano sia le frasi complete che quelle più brevi. La creazione di una voce personalizzata richiede almeno 300 espressioni registrate come dati di training.
Le espressioni nello script possono provenire da origini diverse, ad esempio romanzi, saggistica, trascrizioni di discorsi, notiziari e qualsiasi altra origine disponibile in forma stampata. Per una breve discussione sui potenziali problemi legali, vedere la sezione "Aspetti legali". È anche possibile scrivere un testo personalizzato.
Le espressioni non devono provenire dalla stessa origine, dallo stesso tipo di origine, né essere in alcun modo correlate. Se tuttavia nell'applicazione di riconoscimento vocale si usano frasi standard, ad esempio "Accesso eseguito", assicurasi di includerle nello script. Dà alla tua voce personalizzata una migliore possibilità di pronunciare bene quelle frasi.
È consigliabile che gli script di registrazione includano frasi generali e frasi specifiche del dominio. Ad esempio, se si prevede di registrare 2.000 frasi, 1.000 di esse potrebbero essere frasi generali, potrebbero essere presenti altre 1.000 frasi dal dominio di destinazione o dal caso d'uso dell'applicazione.
Sono disponibili script di esempio nei domini "Generale", "Chat" e "Customer Service" per ogni lingua per preparare gli script di registrazione. È possibile usare questi script condivisi Microsoft per le registrazioni direttamente o usarli come riferimento per crearne uno personalizzato.
Criteri di selezione script
Di seguito sono riportate alcune linee guida generali che è possibile seguire per creare un buon corpus (esempi audio registrati) per l'ottimizzazione vocale professionale.
Per la maggior parte dei casi d'uso, è consigliabile che le frasi siano comprese tra 2 e 15 secondi, contenenti da 5 a 30 parole per le lingue latine o da 4 a 80 parole per le lingue non latine. Punta a bilanciare lo script per includere una varietà di tipologie di frasi e di lunghezze. Verificare che lo script non includa frasi duplicate.
Se il caso d'uso richiede un'alta enfasi su domande, esclamazioni o una combinazione di frasi particolarmente lunghe e brevi, è consigliabile includere una buona parte di frasi come domande o esclamazioni, insieme a frasi molto brevi e frasi più lunghe fino a 20 secondi di lunghezza.
Per informazioni su come bilanciare i diversi tipi di frasi, vedere la tabella seguente:
Tipi di frasi Copertura Frasi dichiarative Le frasi dichiarative devono essere pari al 70-80% dello script. Parola/frase breve Gli script con parole/frasi brevi devono essere circa il 10% delle espressioni totali, con 5-7 parole per caso.
Parole brevi o frasi devono essere separate da virgole per aiutare a ricordare ai talenti vocali di sospendere brevemente durante la lettura.Frasi di domanda (facoltativo) Le frasi interrogative dovrebbero costituire circa il 10%-20% dello script di dominio, includendo il 5%-10% di toni ascendenti e il 5%-10% di toni discendenti.
Queste frasi sono necessarie se si vuole che la voce generata comunicherà con precisione le domande.Frasi esclamative (facoltativo) Le frasi esclamative devono essere circa il 10%-20% dello script.
Queste frasi sono necessarie se si vuole che la voce generata trasmetta in modo accurato le esclamazioni.Nota
È possibile stimare il numero di parole in una frase presupponendo una frequenza di parlato in parole al secondo in base alla lingua.
Le procedure consigliate includono:
- Copertura bilanciata per parti del Servizio cognitivo di Azure per la voce, come verbi, sostantivi, aggettivi e così via.
- Copertura bilanciata per le pronunce. Includere tutte le lettere da A a Z in modo che il motore di sintesi vocale impari a pronunciare ogni lettera nel proprio stile.
- Script leggibili, comprensibili e basati sul buon senso da far leggere all’oratore.
- Evitare troppi modelli simili per parole/frasi, ad esempio "facile" e "più facile".
- Includere diversi formati di numeri: indirizzo, unità, telefono, quantità, data e così via, in tutti i tipi di frasi.
- Includi frasi ortografiche se è qualcosa che la voce personalizzata leggerà. Ad esempio, "L'ortografia di Apple è A P P L E".
Nota
Per la modalità di elaborazione contestuale, che offre intonazioni più naturali e funzionalità di conversazione migliori:
- Usare il testo a livello di paragrafo anziché il testo a livello di frase per le registrazioni. Questo approccio consente di acquisire il flusso vocale naturale tra frasi e mantiene le informazioni contestuali.
- Ogni registrazione dovrebbe essere idealmente più lunga di 30 secondi (contenente più di 60 parole per le lingue latine o 160 parole per le lingue non latine).
- È possibile usare un set di training contestuale con più di 30 minuti di audio totale o 300 espressioni per il training di una voce personalizzata.
Non inserire più frasi in un'unica riga/espressione. Separare ogni riga in base all'espressione.
Assicurarsi che la frase sia pulita. In genere, non includere troppe parole non standard come numeri o abbreviazioni perché sono difficili da leggere. Alcune applicazioni potrebbero richiedere la lettura di molti numeri o acronimi. In questi casi, è possibile includere queste parole, ma è necessario normalizzarle nella forma parlata.
Di seguito sono riportate alcune procedure consigliate, ad esempio:
- Per le righe con abbreviazioni, anziché "BTW", scrivere "by the way".
- Per le righe con cifre, invece di "911", scrivere "nove uno uno".
- Per le righe con acronimi, invece di "ABC", scrivere "A B C".
Con questo, assicurarsi che il proprio talento vocale pronunci queste parole in modo previsto. Mantenere gli script e le registrazioni corrispondenti durante il processo di training.
Lo script deve includere molte parole e frasi diverse, con diversi tipi di lunghezze, strutture e intonazioni.
Controllare lo script con attenzione per verificare la presenza di errori. Se possibile, far eseguire il controllo anche a un'altra persona. Quando si esamina lo script con il talento vocale, è possibile che vengano rilevati altri errori.
Differenza tra script di talento vocale e script di training
Lo script di training può differire dallo script di talento vocale, in particolare per gli script che contengono cifre, simboli, abbreviazioni, data e ora. Gli script preparati per il talento vocale devono seguire convenzioni di lettura native, ad esempio il 50% e $45. Gli script usati per il training devono essere normalizzati in modo che corrispondano alla registrazione audio, ad esempio cinque percento e quarantacinque dollari.
Nota
Vengono forniti alcuni script di esempio per il talento vocale in GitHub. Per usare gli script di esempio per il training, è necessario normalizzarli in base alle registrazioni del talento vocale prima di caricare il file.
La tabella seguente illustra la differenza tra script per il talento vocale e lo script normalizzato per il training.
| Categoria | Esempio di script per il talento vocale | Esempio di script di training (normalizzato) |
|---|---|---|
| Cifre | 123 | centoventitré |
| Simboli | 50% | cinquanta percento |
| Abbreviazione | Al più presto | Il più presto possibile |
| Data e ora | 3 marzo alle 17:00 | Il tre marzo alle cinque del pomeriggio |
Difetti tipici di uno script
La scarsa qualità dello script può influire negativamente sui risultati del training. Per ottenere risultati di training di alta qualità, è fondamentale evitare difetti.
I difetti dello script rientrano in genere nelle categorie seguenti:
| Categoria | Esempio |
|---|---|
| Contenuto senza significato. | "Idee verdi senza colori dormono furiosamente". |
| Frasi incomplete. | - "Questa era la mia ultima vigilia" (nessun soggetto, nessun significato specifico) - "Sono già divertenti (senza virgolette alla fine, non è una frase completa) |
| Errore nelle frasi. | - Iniziare con una lettera minuscola - Nessuna punteggiatura finale, se necessaria - Errore ortografico - Mancanza di punteggiatura: nessun punto alla fine (tranne nel titolo delle notizie) - Termina con simboli, tranne virgola, domanda, esclamazione - Formato errato, ad esempio: - 45$ (deve essere $45) - Nessuno spazio o spazio in eccesso tra parola/punteggiatura |
| La duplicazione in formato simile, una per ogni modello è sufficiente. | - "Ora sono le 13:00 a New York" - "Ora sono le 14:00 a New York" - "Ora sono le 15:00 a New York" - "Ora sono le 13:00 a Seattle" - "Ora sono le 13:00 a Washington D.C." |
| Parole esterne non comuni: nello script sono accettabili solo parole straniere di uso comune. | In inglese si potrebbe usare la parola francese "faux" nel discorso comune, ma un'espressione francese come "coincer la bulle" sarebbe insolito. |
| Emoji o altri simboli non comuni |
Formato dello script
Lo script viene usato durante le sessioni di registrazione, quindi è possibile configurarlo in modo da semplificarne l'uso. Creare il file di testo richiesto da Speech Studio separatamente.
Un formato di script di base include le tre colonne indicate di seguito:
- Numero di espressioni, a partire da 1. La numerazione semplifica a tutte le persone nello studio il riferimento a un'espressione specifica ("riproviamo l'espressione numero 356"). Per numerare le righe della tabella in modo automatico, è possibile usare la funzionalità di numerazione dei paragrafi di Microsoft Word.
- Una colonna vuota in cui scrivere il numero di "take" o il time code di ogni espressione per individuarla nella registrazione completata.
- Testo dell'espressione.
Nota
La maggior parte degli studi esegue la registrazione in brevi segmenti noti come "take". Ogni take contiene in genere un numero di espressioni compreso tra 10 e 24. Annotare il numero del take è sufficiente per trovare un'espressione in un secondo momento. Se si esegue la registrazione in uno studio che preferisce registrare segmenti più lunghi, è opportuno prendere nota del time code. Nello studio sarà in tal caso disponibile uno schermo per la visualizzazione dei dati temporali appropriato.
Lasciare spazio sufficiente dopo ogni riga per scrivere le note. Verificare che nessuna espressione sia suddivisa in più pagine. Numerare le pagine e stampare lo script su un lato del foglio.
Stampare tre copie dello script: una per il talento vocale, una per il tecnico di registrazione e una per il responsabile. Usare graffette anziché punti metallici, dato che uno speaker con esperienza separa le pagine per evitare di fare rumore quando le gira.
Dichiarazione del talento vocale
Per addestrare una voce neurale, è necessario creare un profilo di talento vocale con un file audio registrato dal talent vocale che acconsente all'uso dei dati del suo discorso per raffinare un modello vocale professionale. Quando si prepara lo script di registrazione, assicurarsi di includere la frase dichiarativa.
Aspetti legali
In base alle norme sul copyright, la lettura di un testo protetto da copyright da parte di un attore può essere una prestazione per cui l'autore del lavoro dovrebbe essere ricompensato. Queste prestazioni non saranno riconoscibili nel prodotto finale, la voce personalizzata. Tuttavia, la legittimità dell'uso di un testo protetto da copyright per questo scopo non è comunque definita in modo adeguato. Microsoft non può offrire consulenza legale in relazione a questo problema e consiglia pertanto di rivolgersi al proprio legale.
È possibile tuttavia evitare completamente questi problemi. Sono disponibili molte origini di testo che si possono usare senza licenza né autorizzazione.
| Origine del testo | Descrizione |
|---|---|
| CMU Arctic corpus | Circa 1100 frasi selezionate da testi non protetti da copyright per l'uso specifico in progetti di sintesi vocale. Si tratta di un punto di partenza eccellente. |
| Testi non più protetti da copyright |
Si tratta in genere di testi pubblicati prima del 1923. Per l'inglese, sul sito Project Gutenberg sono disponibili decine di migliaia di tali testi. Può essere opportuno, tuttavia, concentrarsi su testi più recenti perché la lingua si avvicina di più all'inglese moderno. |
| Testi per enti pubblici | I testi creati dagli enti pubblici degli Stati Uniti non sono protetti da copyright negli Stati Uniti, ma possono esserlo in altri paesi. |
| Pubblico dominio | Testi per cui viene fatta rinuncia esplicita al diritto di copyright o che sono definiti di pubblico dominio. In alcune giurisdizioni può non essere possibile rinunciare completamente al copyright. |
| Testi concessi in licenza | Testi distribuiti in base a una licenza, ad esempio Creative Commons o la GNU Free Documentation License (GFDL). Wikipedia usa la licenza GFDL. Alcune licenze, tuttavia, possono imporre restrizioni alle prestazioni del contenuto concesso in licenza che potrebbero influire sulla creazione di un modello vocale personalizzato, quindi leggere attentamente la licenza. |
Registrazione dello script
Registrare lo script in uno studio di registrazione professionale specializzato in attività vocali. In uno studio di questo tipo sono disponibili un banco di registrazione, le apparecchiature adeguate e le persone esperte per farle funzionare. È consigliabile non saltare la registrazione.
Discutere il progetto con il tecnico di registrazione di studio e ascoltarne i consigli. La registrazione deve avere una compressione minima o assente di intervallo dinamico (massimo 4:1). È fondamentale che l'audio sia caratterizzato da un volume uniforme e da un rapporto segnale/rumore elevato e che sia privo di suoni non desiderati.
Requisiti di registrazione
Per ottenere risultati di training di alta qualità, seguire i requisiti seguenti durante la registrazione o la preparazione dei dati:
Pronuncia chiara e corretta
Velocità naturale: non troppo lenta o troppo veloce tra i file audio.
Volume appropriato, prosodia e interruzione: stabile all'interno della stessa frase o tra frasi, interruzione corretta per la punteggiatura.
Nessun rumore durante la registrazione
Adattare il proprio design personale
Nessun accento sbagliato: adattarsi alla progettazione di destinazione
Nessuna pronuncia errata
È possibile fare riferimento alla specifica seguente per preparare i campioni audio come procedura consigliata.
| Proprietà | Valore |
|---|---|
| Formato del file | *.wav, Mono |
| Frequenza di campionamento | 24 kHz |
| Formato del campione | 16 bit, PCM |
| Livelli di volume di picco | Da -3 dB a -6 dB |
| SNR (Signal-to-noise ratio, rapporto segnale/rumore) | > 35 dB |
| Silenzio | - Dovrebbe esserci un po’ di silenzio (si consiglia 100 ms) all'inizio e alla fine, ma non più di 200 ms - Silenzio tra parole o frasi < -30 dB - Silenzio nell'onda dopo la pronuncia dell'ultima parola <-60 dB |
| Rumore o eco dell'ambiente | - Il livello di rumore all'inizio dell'onda prima di parlare < -70 dB |
Nota
È possibile registrare una frequenza di campionamento e una profondità di bit più elevata, ad esempio nel formato PCM a 48 KHz a 24 bit. Durante l'ottimizzazione della voce neurale professionale, verrà ridotta automaticamente a 24 kHz 16 bit PCM.
Un rapporto segnale/rumore superiore indica un livello di rumore inferiore nell'audio. Generalmente è possibile raggiungere un rapporto segnale/rumore superiore a 35 eseguendo la registrazione in studi professionali. L'audio con un rapporto segnale/rumore inferiore a 20 può determinare la presenza di rumore nella voce generata.
Valutare se ripetere la registrazione di qualsiasi espressione con punteggi di pronuncia o rapporti segnale/rumore particolarmente bassi. Se non è possibile ripetere la registrazione, è consigliabile escludere tali espressioni dai dati.
Errori audio tipici
Per ottenere risultati di training di alta qualità, è consigliabile evitare errori audio. Gli errori audio rientrano in genere nelle categorie seguenti:
Il nome del file audio non corrisponde all'ID dello script.
Il file WAR ha un formato non valido e non può essere letto.
La frequenza di campionamento audio è inferiore a 16 KHz. È consigliabile che la frequenza di campionamento dei file .wav sia uguale o superiore a 24 KHz per la voce neurale di alta qualità.
Il picco del volume non rientra nell'intervallo compreso tra -3 dB (70% del volume massimo) e -6 dB (50%).
Overflow della forma d'onda: la forma d'onda viene tagliata al suo valore di picco e pertanto non è completa.
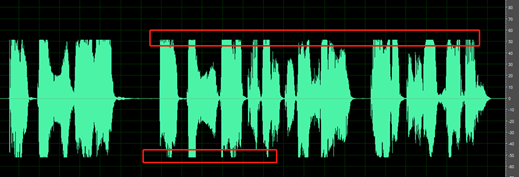
Le parti silenziose della registrazione non sono pulite. Si possono sentire suoni come il rumore ambientale, il rumore della bocca e l'eco.
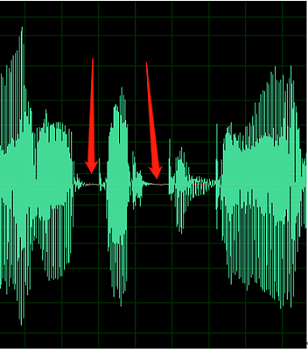
Ad esempio, l'audio seguente contiene il rumore dell'ambiente tra i discorsi.
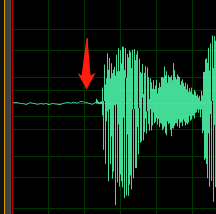
Il campione seguente contiene segni di offset DC o eco.
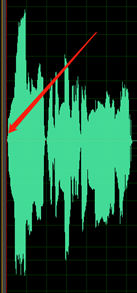
Il volume complessivo è troppo basso. I dati sono contrassegnati come un problema se il volume è inferiore a -18 dB (10% del volume massimo). Assicurarsi che tutti i file audio siano coerenti allo stesso livello di volume.
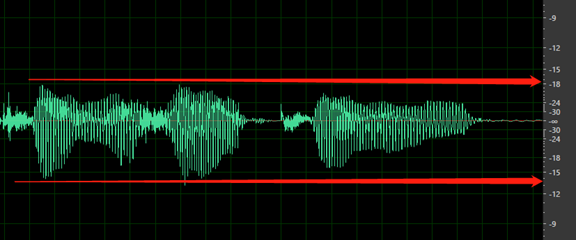
Nessun silenzio prima della prima parola o dopo l'ultima parola. Inoltre, il silenzio iniziale o finale non deve essere più lungo di 200 ms o più breve di 100 ms.
Modalità autonoma
Se si vuole eseguire la registrazione in modo autonomo anziché in uno studio di registrazione, di seguito vengono indicate alcuni istruzioni. Grazie all'aumento della home recording e del podcasting, attualmente è più facile trovare consigli e risorse online.
Il "banco di registrazione" deve essere una piccola stanza senza eco o rumori di fondo percepibili. La stanza deve essere silenziosa e insonorizzata il più possibile. È possibile usare tendaggi sulle pareti per ridurre l'eco e per attenuare i suoni della stanza.
Usare un microfono unidirezionale da studio di qualità elevata (abbreviato in "mic") progettato per la registrazione vocale. I microfoni Sennheiser, AKG e anche i nuovi microfoni Zoom consentono di ottenere ottimi risultati. È possibile acquistare un microfono unidirezionale o noleggiarne uno da una società di apparecchiature audiovisive. Cercare un microfono con un'interfaccia USB. Questo tipo di microfono combina in modo efficiente l'elemento microfono, il preamplificatore e il convertitore analogico-digitale in un unico componente, semplificando il collegamento.
È anche possibile usare un microfono analogico. Molte società di noleggio offrono microfoni meno recenti noti per il loro carattere vocale. Un dispositivo analogico professionale usa connettori XLR bilanciati anziché il connettore da 1/4" usato nelle apparecchiature consumer. Se si decide di usare un dispositivo analogico, è necessario procurarsi anche un preamplificatore e un'interfaccia audio per computer con tali connettori.
Installare il microfono su un supporto o su un'asta e installare un filtro pop davanti al microfono per eliminare il rumore derivante da consonanti occlusive come "p" e "b". Alcuni microfoni sono dotati di un supporto a sospensione che li isola dalle vibrazioni del supporto e risulta estremamente utile.
Il talento vocale deve mantenere una distanza costante dal microfono. Contrassegnare sul pavimento i punti in cui deve trovarsi il talento vocale. Se il talento vocale vuole sedersi, prestare particolare attenzione a monitorare la distanza del microfono ed evitare rumori della sedia.
Usare un supporto per lo script. Evitare di posizionare il supporto con un'angolazione tale da poter riflettere il suono verso il microfono.
La persona che fa funzionare le apparecchiature di registrazione, ovvero il tecnico di registrazione, deve trovarsi una stanza separata rispetto al talento vocale nel banco di registrazione (un circuito di talkback).
La registrazione deve contenere meno rumore possibile, con l'obiettivo di -80 dB.
Ascoltare con attenzione una registrazione di silenzio presso il banco, cercare di capire da dove proviene il rumore ed eliminare la causa. Fonti comuni di rumore sono i condotti dell'aria, gli alimentatori delle lampade fluorescenti, il traffico nelle vicinanze e le ventole della apparecchiature (presenti anche nei PC notebook). Cavi e microfoni possono rilevare rumori elettrici dai cavi CA, in genere interferenze o ronzii. Un ronzio può anche essere causato da un loop di massa, dovuto alla presenza di apparecchiature collegate a più di un circuito elettrico.
Suggerimento
In alcuni casi è possibile usare un equalizzatore o un software di riduzione del rumore per rimuovere il rumore dalle registrazioni, anche se è sempre consigliabile eliminarlo all'origine.
I livelli devono essere impostati in modo che la maggior parte dell'intervallo dinamico disponibile della registrazione digitale venga usato senza overdriving. Ciò significa impostare l'audio ad alto volume, ma non così alto da renderlo distorto. Nella figura seguente è riportato un esempio della forma d'onda di una registrazione valida:
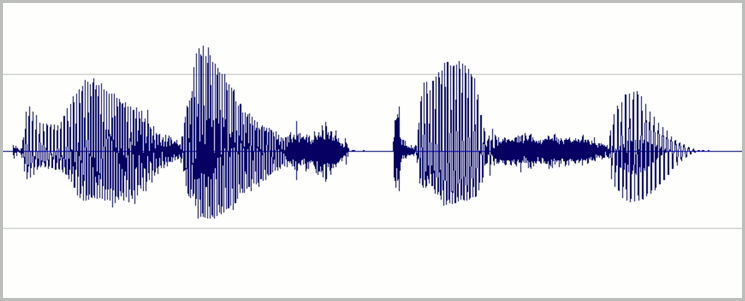
In questo caso viene usata la maggior parte dell'intervallo (altezza), ma i picchi più alti del segnale non raggiungono la parte superiore o inferiore dell'intervallo stesso. È anche possibile notare che il silenzio nella registrazione è approssimabile a una linea orizzontale sottile, che indica un basso livello di rumore. Questa registrazione è caratterizzata da un intervallo dinamico e da un rapporto segnale/rumore accettabili.
Registrare direttamente nel computer usando un'interfaccia audio di alta qualità o una porta USB, a seconda del microfono in uso. Se si usa un dispositivo analogico, mantenere semplice la catena audio: microfono, preamplificatore, interfaccia audio, computer. È possibile ottenere mensilmente in licenza Avid Pro Tools e Adobe Audition a un costo ragionevole. Se il budget è estremamente ridotto, provare l'utilità gratuita Audacity.
Registrare a una qualità monofonica di 44,1 KHz a 16 bit (qualità CD) o superiore. Lo standard attuale è di 48 KHz 24 bit, se l'apparecchiatura in uso lo supporta. L'audio verrà ridotto a 24 KHz a 16 bit prima di inviarlo a Speech Studio. Si noti che è importante avere una registrazione originale di qualità elevata nel caso in cui sia necessario apportare delle modifiche.
È consigliabile che persone diverse ricoprano i ruoli di responsabile, tecnico e talento vocale. Non provare a eseguire tutte le operazioni in modo autonomo. In caso di necessità, una sola persona può ricoprire il ruolo di responsabile e di tecnico.
Prima della sessione
Per evitare di sprecare tempo in studio, esaminare lo script con il talento vocale prima della sessione di registrazione. Il talento vocale deve acquisire familiarità con il testo nonché chiarire la pronuncia delle parole che non conosce.
Nota
La maggior parte degli studi di registrazione consente di visualizzare in modo elettronico gli script nel banco di registrazione. In questo caso digitare le note direttamente nel documento dello script. È tuttavia opportuno avere una copia cartacea per prendere appunti durante la sessione. Anche la maggior parte dei tecnici vuole in genere una copia cartacea. Predisporre anche una terza copia stampata come backup per il talento vocale qualora il computer si arresti.
Il talento vocale potrebbe chiedere quale parola deve essere enfatizzata in un'espressione ("parola operativa"). Comunicare al talento vocale che si vuole una lettura naturale senza alcuna enfasi particolare. L'enfasi può essere aggiunta in fase di sintesi vocale, ma non deve far parte della registrazione originale.
Indicare al talento vocale di pronunciare distintamente le parole. Ogni parola dello script deve essere pronunciata come è stata scritta. I suoni non devono essere omessi né confusi, come talvolta avviene in un discorso casuale, a meno che non siano stati scritti in tal modo nello script.
| Testo scritto | Pronuncia casuale indesiderata |
|---|---|
| lo hanno eliminato | l'hanno eliminato |
| le luci erano quattro | le luci erano quattro |
| come è il tempo oggi | com'è il tempo oggi |
| non avere paura | non aver paura |
Il talento non deve aggiungere pause distinte tra le parole. La frase deve fluire in modo naturale, anche se suona un po' formale. Per raggiungere questo risultato, è necessaria una certa pratica.
Sessione di registrazione
Creare una registrazione di riferimento, denominata file di corrispondenza, di un'espressione tipica all'inizio della sessione. Chiedere al talento vocale di ripetere questa riga all'incirca a ogni pagina. Confrontare ogni volta la nuova registrazione con il riferimento. Questa procedura consente al talento vocale di mantenere l'uniformità in volume, tempo, tono e intonazione. Nel frattempo il tecnico può usare il file di corrispondenza come riferimento per controllare i livelli e l'uniformità complessiva del suono.
Il file di corrispondenza è particolarmente importante quando si riprende la registrazione dopo un'interruzione o in un altro giorno. Riprodurlo più volte per il talento e farlo ripetere ogni volta fino a quando la corrispondenza non sarà perfetta.
Per registrare un corpus con uno stile specifico, scegliere attentamente gli script che presentano lo stile desiderato. Durante la registrazione, assicurarsi che il talento vocale mantenga l'uniformità a livello di volume, tempo, tonalità e tono per ottenere registrazioni che incorporano lo stile previsto.
Invitare il talento vocale a respirare profondamente e a fare una pausa prima di ogni espressione. Registrare un paio di secondi di silenzio tra le espressioni. Le parole devono essere pronunciate allo stesso modo ogni volta che vengono visualizzate, tenendo conto del contesto. Ad esempio, "viola" come verbo è pronunciato in modo diverso da "viola" come sostantivo.
Registrare circa cinque secondi di silenzio prima che la prima registrazione acquisisca il rumore di fondo della stanza. Questa procedura consente a Speech Studio di compensare il rumore nelle registrazioni.
Suggerimento
Occorre acquisire solo il talento vocale, pertanto è possibile creare una registrazione monofonica (a singolo canale) solo delle righe lette. Se tuttavia si registra in formato stereo, è possibile usare il secondo canale per registrare la conversazione nella sala di controllo per acquisire le discussioni di righe o take particolari. Rimuovere questa traccia dalla versione caricata in Speech Studio.
Ascoltare con attenzione, usando le cuffie, la prestazione del talento vocale. Verificare che la dizione sia buona, ma naturale, che la pronuncia sia corretta e che non siano presenti suoni non desiderati. Non esitare a chiedere al talento vocale di registrare nuovamente un'espressione che non soddisfa gli standard.
Suggerimento
Se si usa un numero elevato di espressioni, una singola espressione potrebbe non avere un effetto evidente sulla voce personalizzata risultante. Potrebbe essere più opportuno prendere semplicemente nota di qualsiasi espressione con problemi, escluderli dal set di dati e vedere come si verifica la voce personalizzata. È sempre possibile tornare allo studio e registrare gli esempi mancanti in un secondo momento.
Prendere nota del numero di take o del time code per ogni espressione. Chiedere al tecnico se può contrassegnare ogni espressione nei metadati o nel foglio della segnalazione della registrazione.
Concedere momenti di pausa e offrire bevande per consentire al talento vocale di mantenere la voce in buono stato.
Al termine della sessione
Gli studi di registrazione moderni si avvalgono dell'uso dei computer. Al termine della sessione vengono restituiti uno o più file audio, non un nastro. Tali file sono probabilmente in formato WAV o AIFF in qualità CD (44,1 KHz 16 bit) o superiore. La frequenza di 24 KHz 16 bit è comune e consigliata. La frequenza di campionamento predefinita per una voce personalizzata è 24 KHz. È consigliabile usare una frequenza di campionamento di 24 KHz e superiore per i dati di training. Le frequenze di campionamento più elevate, ad esempio 96 KHz, non sono in genere necessarie.
Speech Studio richiede che ogni espressione fornita sia presente nel proprio file. Ogni file audio fornito dallo studio contiene più espressioni. L'attività di post-produzione primaria, di conseguenza, consiste nel suddividere le registrazioni e prepararle per l'invio. Il tecnico di registrazione potrebbe aver posizionato i marcatori nel file (oppure aver fornito un foglio separato) per indicare dove inizia ogni espressione.
Usare le note per trovare i take esatti desiderati, quindi usare un'utilità di modifica del suono, ad esempio Avid Pro Tools, Adobe Audition o Audacity gratuito per copiare ogni espressione in un nuovo file.
Ascoltare attentamente ogni file. In questa fase è possibile modificare i disturbi meno evidenti indesiderati non rilevati durante la registrazione, ad esempio un lieve rumore delle labbra prima di una riga, ma occorre prestare attenzione a non rimuovere alcuna parola effettiva. Se non è possibile correggere un file, rimuoverlo dal set di dati, prendendo nota dell'operazione eseguita.
Convertire ogni file in 16 bit e una frequenza di campionamento di 24 KHz e superiore prima di salvare e, se è stata registrata la conversazione in studio, rimuovere il secondo canale. Salvare ogni file in formato WAV, denominando i file con il numero di espressione presente nello script.
Creare infine la trascrizione che associa ogni file con estensione wav con la versione in formato testo dell'espressione corrispondente. Il training del modello vocale include i dettagli del formato richiesto. È possibile copiare il testo direttamente dallo script. Creare quindi un file ZIP dei file WAV e la trascrizione del testo.
Archiviare le registrazioni originali in un luogo sicuro nel caso in cui siano necessarie in un secondo momento. Conservare anche lo script e le note.
Passaggi successivi
Si è pronti per caricare le registrazioni e creare la voce personalizzata.