Come distribuire ed eseguire l’inferenza di una distribuzione di calcolo gestita con codice
Il catalogo modelli di Studio AI offre più di 1.600 modelli; il modo più comune per distribuirli è l'opzione di distribuzione di calcolo gestita, nota anche come distribuzione online gestita.
La distribuzione di un modello linguistico di grandi dimensioni (LLM) lo rende disponibile per l'uso in un sito Web, in un'applicazione o in altri ambienti di produzione. Solitamente, la distribuzione comporta l'hosting del modello in un server o nel cloud, nonché la creazione di un'API o di un'altra interfaccia per consentire agli utenti di interagire con il modello. È possibile richiamare la distribuzione per l'inferenza in tempo reale di applicazioni di intelligenza artificiale generativa, ad esempio chat e copilota.
Questo articolo illustra come distribuire modelli usando l'SDK di Azure Machine Learning. L'articolo illustra anche come eseguire l'inferenza nel modello distribuito.
Ottenere l'ID modello
È possibile distribuire modelli di calcolo gestiti usando l'SDK di Azure Machine Learning, ma prima si deve esplorare il catalogo modelli e ottenere l'ID modello necessario per la distribuzione.
Accedere a Studio AI della piattaforma Azure e passare alla Home page.
Selezionare Catalogo modelli nella barra laterale sinistra.
Nel filtro Opzioni di distribuzione selezionare Calcolo gestito.
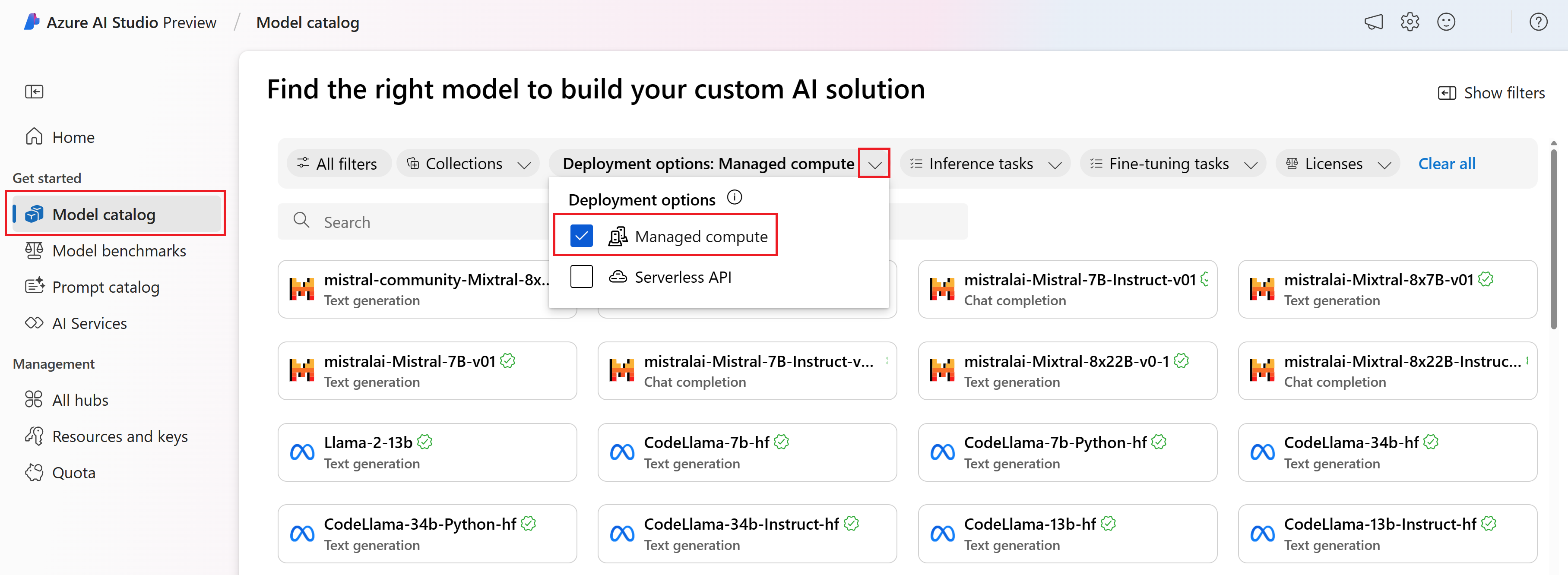
Seleziona un modello.
Copiare l'ID modello dalla pagina dei dettagli del modello selezionato. Verrà visualizzata una schermata simile alla seguente:
azureml://registries/azureml/models/deepset-roberta-base-squad2/versions/16

Distribuire il modello
Distribuire il modello.
Innanzitutto, è necessario installare l'SDK di Azure Machine Learning.
pip install azure-ai-ml
pip install azure-identity
Usare questo codice per eseguire l'autenticazione con Azure Machine Learning e creare un oggetto client. Sostituire i segnaposto con l'ID sottoscrizione, il nome del gruppo di risorse e il nome del progetto di Studio AI specifici.
from azure.ai.ml import MLClient
from azure.identity import InteractiveBrowserCredential
client = MLClient(
credential=InteractiveBrowserCredential,
subscription_id="your subscription name goes here",
resource_group_name="your resource group name goes here",
workspace_name="your project name goes here",
)
Per l'opzione di distribuzione calcolo gestito, è necessario creare un endpoint prima della distribuzione di un modello. Si consideri l'endpoint come un contenitore in grado di ospitare più distribuzioni di modelli. I nomi degli endpoint devono essere univoci all'interno di un'area, quindi in questo esempio si usa il timestamp per creare un nome endpoint univoco.
import time, sys
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
ProbeSettings,
)
# Make the endpoint name unique
timestamp = int(time.time())
online_endpoint_name = "customize your endpoint name here" + str(timestamp)
# Create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
auth_mode="key",
)
workspace_ml_client.begin_create_or_update(endpoint).wait()
Creare una distribuzione. È possibile trovare l'ID modello nel catalogo modelli.
model_name = "azureml://registries/azureml/models/deepset-roberta-base-squad2/versions/16"
demo_deployment = ManagedOnlineDeployment(
name="demo",
endpoint_name=online_endpoint_name,
model=model_name,
instance_type="Standard_DS3_v2",
instance_count=2,
liveness_probe=ProbeSettings(
failure_threshold=30,
success_threshold=1,
timeout=2,
period=10,
initial_delay=1000,
),
readiness_probe=ProbeSettings(
failure_threshold=10,
success_threshold=1,
timeout=10,
period=10,
initial_delay=1000,
),
)
workspace_ml_client.online_deployments.begin_create_or_update(demo_deployment).wait()
endpoint.traffic = {"demo": 100}
workspace_ml_client.begin_create_or_update(endpoint).result()
Eseguire l'inferenza della distribuzione
Per testare l'inferenza sono necessari dei dati JSON di esempio. Creare sample_score.json con l’esempio seguente.
{
"inputs": {
"question": [
"Where do I live?",
"Where do I live?",
"What's my name?",
"Which name is also used to describe the Amazon rainforest in English?"
],
"context": [
"My name is Wolfgang and I live in Berlin",
"My name is Sarah and I live in London",
"My name is Clara and I live in Berkeley.",
"The Amazon rainforest (Portuguese: Floresta Amaz\u00f4nica or Amaz\u00f4nia; Spanish: Selva Amaz\u00f3nica, Amazon\u00eda or usually Amazonia; French: For\u00eat amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain \"Amazonas\" in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species."
]
}
}
Eseguire l'inferenza con sample_score.json. Modificare il percorso in base alla posizione cui è stato salvato il file JSON di esempio.
scoring_file = "./sample_score.json"
response = workspace_ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="demo",
request_file=scoring_file,
)
response_json = json.loads(response)
print(json.dumps(response_json, indent=2))
Eliminare l'endpoint di distribuzione
Per eliminare le distribuzioni in Studio AI, selezionare il pulsante Elimina nel pannello superiore della pagina dei dettagli della distribuzione.
Considerazioni sulla quota
Per distribuire ed eseguire l'inferenza di endpoint in tempo reale, si utilizza la quota di core della macchina virtuale (VM) assegnata alla sottoscrizione in base all'area. Quando ci si iscrive a Studio AI, si riceve una quota di macchina virtuale predefinita per le diverse famiglie di VM disponibili nell'area. È possibile continuare a creare distribuzioni fino a raggiungere il limite di quota. A questo punto è possibile richiedere un aumento della quota.
Passaggi successivi
- Altre informazioni su ciò che è possibile fare in Studio AI
- Risposte alle domande frequenti nell'articolo Domande frequenti su Azure per intelligenza artificiale