TDSP è una metodologia di data science agile e iterativa che è possibile usare per offrire in modo efficiente soluzioni di analisi predittiva e applicazioni di intelligenza artificiale. TDSP migliora la collaborazione e l'apprendimento dei team consigliando modi ottimali per consentire ai ruoli del team di collaborare. Il TDSP incorpora procedure consigliate e framework di Microsoft e altri leader del settore per aiutare il team a implementare in modo efficace le iniziative di data science. TDSP consente di sfruttare appieno i vantaggi del programma di analisi.
Questo articolo offre una panoramica del TDSP e dei relativi componenti principali. Vengono fornite indicazioni su come implementare il TDSP usando gli strumenti e l'infrastruttura Microsoft. È possibile trovare risorse più dettagliate in tutto l'articolo.
Componenti principali del TDSP
Il TDSP include i componenti chiave seguenti:
- Definizione del ciclo di vita di data science
- Struttura di progetto standardizzata
- Infrastruttura e risorse ideali per i progetti di data science
- IA responsabile: e un impegno per il progresso dell'IA, guidato dai principi etici
Ciclo di vita del data science
Il TDSP fornisce un ciclo di vita che è possibile usare per strutturare lo sviluppo dei progetti di data science. Il ciclo di vita descrive tutti i passaggi da seguire per la riuscita dei progetti.
È possibile combinare il TDSP basato su attività con altri cicli di vita di data science, ad esempio il processo standard tra i settori per il data mining (CRISP-DM), il processo di individuazione delle informazioni nei database (KDD) o un altro processo personalizzato. In generale queste diverse metodologie hanno molto in comune.
Usare questo ciclo di vita se si ha un progetto di data science che fa parte di un'applicazione intelligente. Le applicazioni intelligenti distribuiscono modelli di Machine Learning o intelligenza artificiale per l'analisi predittiva. È anche possibile usare questo processo per progetti esplorativi di data science e progetti di analisi improvvisati.
Il ciclo di vita del TDSP è costituito da cinque fasi principali eseguite dal team in modo iterativo. Queste fasi includono:
- Comprensione del business
- Acquisizione e comprensione dei dati
- Modellazione
- Distribuzione
- Accettazione del cliente
Ecco una rappresentazione visiva del ciclo di vita di TDSP:
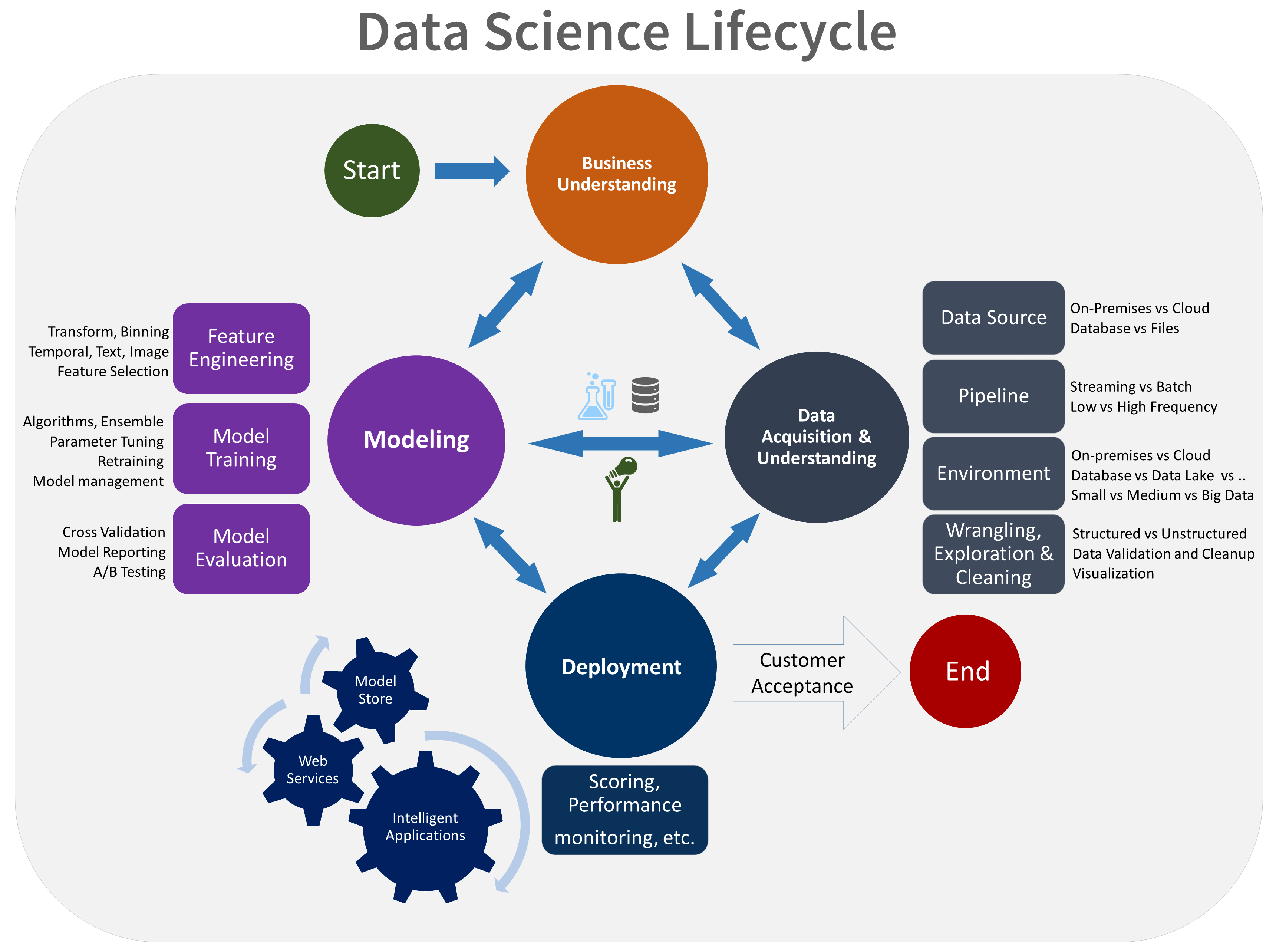
Per altre informazioni sugli obiettivi, le attività e gli artefatti della documentazione per ogni fase, vedere Ciclo di vita di TDSP.
Queste attività e elementi sono allineati ai ruoli del progetto, ad esempio:
- Architetto di soluzioni
- Responsabile di progetto
- Data engineer
- Data scientist
- Sviluppatore di applicazioni
- Responsabile progetto
Il diagramma seguente mostra le attività (in blu) e gli artefatti (in verde) che corrispondono a ogni fase del ciclo di vita rappresentato sull'asse orizzontale e per i ruoli rappresentati sull'asse verticale.

Struttura di progetto standardizzata
Il team può usare l'infrastruttura di Azure per organizzare gli asset di data science.
Azure Machine Learning supporta MLflow open source. È consigliabile usare MLflow per la gestione dei progetti di data science e intelligenza artificiale. MLflow è progettato per gestire il ciclo di vita completo di Machine Learning. Esegue il training e gestisce modelli su piattaforme diverse, in modo da poter usare un set coerente di strumenti indipendentemente dalla posizione in cui vengono eseguiti gli esperimenti. È possibile usare MLflow localmente nel computer, in una destinazione di calcolo remota, in una macchina virtuale o in un'istanza di calcolo di Machine Learning.
MLflow è costituito da diverse funzionalità chiave:
Tenere traccia degli esperimenti: è possibile usare MLflow per tenere traccia degli esperimenti, inclusi parametri, versioni del codice, metriche e file di output. Questa funzionalità consente di confrontare diverse esecuzioni e di gestire in modo efficiente il processo di sperimentazione.
Codice del pacchetto: fornisce un formato standardizzato per la creazione di pacchetti di codice di Machine Learning, che include dipendenze e configurazioni. Questo pacchetto semplifica la riproduzione delle esecuzioni e la condivisione del codice con altri utenti.
Gestire i modelli: MLflow offre funzionalità per gestire i modelli di versione e . Supporta diversi framework di Machine Learning in modo che sia possibile archiviare, versione e gestire i modelli.
Gestire e distribuire modelli: MLflow integra funzionalità di distribuzione e gestione dei modelli in modo da poter distribuire facilmente i modelli in ambienti diversi.
Registrare i modelli: è possibile gestire il ciclo di vita di un modello, che include il controllo delle versioni, le transizioni di fase e le annotazioni. È possibile usare MLflow per gestire un archivio modelli centralizzato in un ambiente collaborativo.
Usare un'API e un'interfaccia utente: all'interno di Azure, MLflow è incluso nell'API di Machine Learning versione 2, in modo da poter interagire con il sistema a livello di codice. È possibile usare il portale di Azure per interagire con un'interfaccia utente.
MLflow semplifica e standardizza il processo di sviluppo di Machine Learning, dalla sperimentazione alla distribuzione.
Machine Learning si integra con i repository Git, in modo da poter usare servizi compatibili con Git, ad esempio GitHub, GitLab, Bitbucket, Azure DevOps o un altro servizio compatibile con Git. Oltre agli asset già rilevati in Machine Learning, il team può sviluppare la propria tassonomia all'interno del servizio compatibile con Git per archiviare altri dati del progetto, ad esempio:
- Documentazione
- Dati del progetto: ad esempio, il report finale del progetto
- Report dei dati: ad esempio, il dizionario dati o i report sulla qualità dei dati
- Modello: ad esempio, report del modello
- Codice
- Preparazione dei dati
- Sviluppo del modello
- Operazionalizzazione, che include sicurezza e conformità
Infrastruttura e risorse
Il TDSP fornisce consigli su come gestire l'infrastruttura di archiviazione e analisi condivisa nelle categorie seguenti:
- File system cloud per archiviare i set di dati
- Database cloud
- Cluster Big Data che usano SQL o Spark
- Servizi di intelligenza artificiale e Machine Learning
File system cloud per archiviare i set di dati
I file system cloud sono fondamentali per il TDSP per diversi motivi:
Archiviazione centralizzata dei dati: i file system cloud offrono una posizione centralizzata per archiviare i set di dati, essenziale per la collaborazione tra i membri del team di data science. La centralizzazione garantisce che tutti i membri del team possano accedere ai dati più aggiornati e riducono il rischio di usare set di dati obsoleti o incoerenti.
Scalabilità: i file system cloud possono gestire grandi volumi di dati, comuni nei progetti di data science. I file system offrono soluzioni di archiviazione scalabili che aumentano con le esigenze del progetto. Consentono ai team di archiviare ed elaborare set di dati di grandi dimensioni senza doversi preoccupare delle limitazioni hardware.
Accessibilità: con i file system cloud è possibile accedere ai dati da qualsiasi posizione con una connessione Internet. Questo accesso è importante per i team distribuiti o quando i membri del team devono lavorare in remoto. I file system cloud facilitano la collaborazione senza problemi e assicurano che i dati siano sempre accessibili.
Sicurezza e conformità: i provider di servizi cloud spesso implementano misure di sicurezza affidabili, tra cui crittografia, controlli di accesso e conformità agli standard e alle normative del settore. Le misure di sicurezza avanzate possono proteggere i dati sensibili e aiutare il team a soddisfare i requisiti legali e normativi.
Controllo della versione: i file system cloud includono spesso funzionalità di controllo della versione che i team possono usare per tenere traccia delle modifiche apportate ai set di dati nel tempo. Il controllo della versione è fondamentale per mantenere l'integrità dei dati e riprodurre i risultati nei progetti di data science. Consente inoltre di controllare e risolvere eventuali problemi che si verificano.
Integrazione con gli strumenti: i file system cloud possono integrarsi perfettamente con vari strumenti e piattaforme di data science. L'integrazione degli strumenti supporta l'inserimento, l'elaborazione dei dati e l'analisi dei dati più semplici. Ad esempio, Archiviazione di Azure si integra bene con Machine Learning, Azure Databricks e altri strumenti di data science.
Collaborazione e condivisione: i file system cloud semplificano la condivisione di set di dati con altri membri del team o stakeholder. Questi sistemi supportano funzionalità collaborative, ad esempio cartelle condivise e gestione delle autorizzazioni. Le funzionalità di collaborazione facilitano il lavoro in team e assicurano che le persone giuste abbiano accesso ai dati di cui hanno bisogno.
Efficienza dei costi: i file system cloud possono essere più convenienti rispetto alla gestione delle soluzioni di archiviazione locali. I provider di servizi cloud hanno modelli di determinazione dei prezzi flessibili che includono opzioni con pagamento in base al consumo, che consentono di gestire i costi in base ai requisiti effettivi di utilizzo e archiviazione del progetto di data science.
Ripristino di emergenza: i file system cloud in genere includono funzionalità per il backup dei dati e il ripristino di emergenza. Queste funzionalità consentono di proteggere i dati da errori hardware, eliminazioni accidentali e altre emergenze. Offre tranquillità e supporta la continuità nelle operazioni di data science.
Automazione e integrazione del flusso di lavoro: i sistemi di archiviazione cloud possono integrarsi in flussi di lavoro automatizzati, che consentono un semplice trasferimento dei dati tra diverse fasi del processo di data science. L'automazione può contribuire a migliorare l'efficienza e ridurre lo sforzo manuale necessario per gestire i dati.
Risorse di Azure consigliate per i file system cloud
- Archiviazione BLOB di Azure: documentazione completa su Archiviazione BLOB di Azure, che è un servizio di archiviazione oggetti scalabile per i dati non strutturati.
- Azure Data Lake Storage : informazioni su Azure Data Lake Storage Gen2, progettate per l'analisi dei Big Data e supportano set di dati su larga scala.
- File di Azure: informazioni dettagliate sulle File di Azure, che fornisce condivisioni file completamente gestite nel cloud.
In sintesi, i file system cloud sono fondamentali per il TDSP poiché forniscono soluzioni di archiviazione scalabili, sicure e accessibili che supportano l'intero ciclo di vita dei dati. I file system cloud consentono una perfetta integrazione dei dati da varie origini, che supportano l'acquisizione e la comprensione completi dei dati. I data scientist possono usare i file system cloud per archiviare, gestire e accedere in modo efficiente a set di dati di grandi dimensioni. Questa funzionalità è essenziale per il training e la distribuzione di modelli di Machine Learning. Questi sistemi migliorano anche la collaborazione consentendo ai membri del team di condividere e lavorare contemporaneamente sui dati in un ambiente unificato. I file system cloud offrono funzionalità di sicurezza affidabili che consentono di proteggere i dati e renderli conformi ai requisiti normativi, fondamentali per mantenere l'integrità e l'attendibilità dei dati.
Database cloud
I database cloud svolgono un ruolo fondamentale nel TDSP per diversi motivi:
Scalabilità: i database cloud offrono soluzioni scalabili che possono aumentare facilmente per soddisfare le crescenti esigenze di dati di un progetto. La scalabilità è fondamentale per i progetti di data science che gestiscono spesso set di dati complessi e di grandi dimensioni. I database cloud possono gestire carichi di lavoro diversi senza la necessità di interventi manuali o aggiornamenti hardware.
Ottimizzazione delle prestazioni: gli sviluppatori ottimizzano i database cloud per ottenere prestazioni usando funzionalità come l'indicizzazione automatica, l'ottimizzazione delle query e il bilanciamento del carico. Queste funzionalità consentono di garantire che il recupero e l'elaborazione dei dati siano veloci ed efficienti, fondamentale per le attività di data science che richiedono l'accesso ai dati in tempo reale o quasi in tempo reale.
Accessibilità e collaborazione: Teams può accedere ai dati archiviati nei database cloud da qualsiasi posizione. Questa accessibilità promuove la collaborazione tra i membri del team che potrebbero essere distribuiti geograficamente. L'accessibilità e la collaborazione sono importanti per i team distribuiti o per le persone che lavorano in remoto. I database cloud supportano ambienti multiutente che consentono l'accesso simultaneo e la collaborazione.
Integrazione con gli strumenti di data science: i database cloud si integrano perfettamente con vari strumenti e piattaforme di data science. Ad esempio, i database cloud di Azure si integrano bene con Machine Learning, Power BI e altri strumenti di analisi dei dati. Questa integrazione semplifica la pipeline di dati, dall'inserimento e dall'archiviazione all'analisi e alla visualizzazione.
Sicurezza e conformità: i provider di servizi cloud implementano misure di sicurezza affidabili che includono crittografia dei dati, controlli di accesso e conformità agli standard e alle normative del settore. Le misure di sicurezza proteggono i dati sensibili e aiutano il team a soddisfare i requisiti legali e normativi. Le funzionalità di sicurezza sono fondamentali per mantenere l'integrità e la privacy dei dati.
Efficienza dei costi: i database cloud spesso operano su un modello con pagamento in base al consumo, che può essere più conveniente rispetto alla gestione di sistemi di database locali. Questa flessibilità dei prezzi consente alle organizzazioni di gestire i budget in modo efficace e pagare solo per le risorse di archiviazione e calcolo usate.
Backup automatici e ripristino di emergenza: i database cloud offrono soluzioni di backup e ripristino di emergenza automatiche. Queste soluzioni consentono di evitare la perdita di dati in caso di errori hardware, eliminazioni accidentali o altre emergenze. L'affidabilità è fondamentale per mantenere la continuità e l'integrità dei dati nei progetti di data science.
Elaborazione dei dati in tempo reale: molti database cloud supportano l'elaborazione e l'analisi dei dati in tempo reale, essenziali per le attività di data science che richiedono le informazioni più aggiornate. Questa funzionalità consente ai data scientist di prendere decisioni tempestive in base ai dati disponibili più recenti.
Integrazione dei dati: i database cloud possono essere facilmente integrati con altre origini dati, database, data lake e feed di dati esterni. L'integrazione consente ai data scientist di combinare dati provenienti da più origini e offre una visualizzazione completa e un'analisi più sofisticata.
Flessibilità e varietà: i database cloud sono disponibili in varie forme, ad esempio database relazionali, database NoSQL e data warehouse. Questa varietà consente ai team di data science di scegliere il tipo di database migliore per le proprie esigenze specifiche, sia che richiedano l'archiviazione strutturata dei dati, la gestione dei dati non strutturata o l'analisi dei dati su larga scala.
Supporto per l'analisi avanzata: i database cloud spesso sono dotati di supporto predefinito per l'analisi avanzata e l'apprendimento automatico. Ad esempio, database SQL di Azure fornisce servizi di Machine Learning predefiniti. Questi servizi consentono ai data scientist di eseguire analisi avanzate direttamente all'interno dell'ambiente di database.
Risorse di Azure consigliate per i database cloud
- database SQL di Azure - Documentazione su database SQL di Azure, un servizio di database relazionale completamente gestito.
- Azure Cosmos DB : informazioni su Azure Cosmos DB, un servizio di database multimodello distribuito a livello globale.
- Database di Azure per PostgreSQL - Guida a Database di Azure per PostgreSQL, un servizio di database gestito per lo sviluppo e la distribuzione di app.
- Database di Azure per MySQL: informazioni dettagliate su Database di Azure per MySQL, un servizio gestito per i database MySQL.
In sintesi, i database cloud sono fondamentali per TDSP perché offrono soluzioni di archiviazione e gestione dei dati scalabili, affidabili ed efficienti che supportano progetti basati sui dati. Semplificano l'integrazione dei dati senza problemi, che consentono ai data scientist di inserire, pre-elaborare e analizzare set di dati di grandi dimensioni da varie origini. I database cloud consentono l'esecuzione rapida di query e l'elaborazione dei dati, essenziale per sviluppare, testare e distribuire modelli di Machine Learning. Inoltre, i database cloud migliorano la collaborazione fornendo una piattaforma centralizzata per consentire ai membri del team di accedere e lavorare contemporaneamente con i dati. Infine, i database cloud offrono funzionalità di sicurezza avanzate e supporto per la conformità per mantenere i dati protetti e conformi agli standard normativi, che è fondamentale per mantenere l'integrità e l'attendibilità dei dati.
Cluster Big Data che usano SQL o Spark
I cluster Big Data, ad esempio quelli che usano SQL o Spark, sono fondamentali per il TDSP per diversi motivi:
Gestione di grandi volumi di dati: i cluster Big Data sono progettati per gestire in modo efficiente volumi elevati di dati. I progetti di data science spesso implicano set di dati di grandi dimensioni che superano la capacità dei database tradizionali. I cluster Big Data basati su SQL e Spark possono gestire ed elaborare questi dati su larga scala.
Elaborazione distribuita: i cluster Big Data usano il calcolo distribuito per distribuire i dati e le attività di calcolo tra più nodi. La funzionalità di elaborazione parallela accelera notevolmente le attività di elaborazione e analisi dei dati, che è essenziale per ottenere informazioni tempestive nei progetti di data science.
Scalabilità: i cluster Big Data offrono scalabilità elevata, sia orizzontalmente aggiungendo più nodi che verticalmente aumentando la potenza dei nodi esistenti. La scalabilità consente di garantire che l'infrastruttura dati aumenti con le esigenze del progetto gestendo l'aumento delle dimensioni dei dati e della complessità.
Integrazione con gli strumenti di data science: i cluster Big Data si integrano bene con vari strumenti e piattaforme di data science. Spark, ad esempio, si integra perfettamente con Hadoop e i cluster SQL funzionano con vari strumenti di analisi dei dati. L'integrazione facilita un flusso di lavoro uniforme dall'inserimento dati all'analisi e alla visualizzazione.
Analisi avanzata: i cluster Big Data supportano analisi avanzate e Machine Learning. Spark offre ad esempio le librerie predefinite seguenti:
- Machine learning, MLlib
- Elaborazione dei gragrafi, GraphX
- Elaborazione di flussi, Spark Streaming
Queste funzionalità consentono ai data scientist di eseguire analisi complesse direttamente all'interno del cluster.
Elaborazione dei dati in tempo reale: cluster Big Data, in particolare quelli che usano Spark, supportano l'elaborazione dei dati in tempo reale. Questa funzionalità è fondamentale per i progetti che richiedono l'analisi dei dati fino al minuto e il processo decisionale. L'elaborazione in tempo reale è utile in scenari come il rilevamento delle frodi, le raccomandazioni in tempo reale e i prezzi dinamici.
Trasformazione dei dati ed estrazione, trasformazione, caricamento (ETL): i cluster Big Data sono ideali per la trasformazione dei dati e i processi ETL. Possono gestire in modo efficiente trasformazioni, pulizia e aggregazioni complesse dei dati, che sono spesso necessarie prima che i dati possano essere analizzati.
Efficienza dei costi: i cluster Big Data possono essere convenienti, soprattutto quando si usano soluzioni basate sul cloud come Azure Databricks e altri servizi cloud. Questi servizi offrono modelli di determinazione dei prezzi flessibili che includono il pagamento in base al consumo, che possono essere più economici rispetto alla gestione dell'infrastruttura Big Data locale.
Tolleranza di errore: i cluster Big Data sono progettati tenendo presente la tolleranza di errore. Replicano i dati tra i nodi per garantire che il sistema rimanga operativo anche se alcuni nodi hanno esito negativo. Questa affidabilità è fondamentale per mantenere l'integrità e la disponibilità dei dati nei progetti di data science.
Integrazione di Data Lake: i cluster Big Data spesso si integrano perfettamente con data lake, che consentono ai data scientist di accedere e analizzare origini dati diverse in modo unificato. L'integrazione promuove analisi più complete supportando una combinazione di dati strutturati e non strutturati.
Elaborazione basata su SQL: per i data scientist che hanno familiarità con SQL, cluster Big Data che riguardano query SQL, ad esempio Spark SQL o SQL in Hadoop, offrono un'interfaccia familiare per eseguire query e analizzare i Big Data. Questa facilità d'uso può accelerare il processo di analisi e renderlo più accessibile a un'ampia gamma di utenti.
Collaborazione e condivisione: i cluster Big Data supportano ambienti collaborativi in cui più data scientist e analisti possono collaborare con gli stessi set di dati. Forniscono funzionalità per condividere codice, notebook e risultati che favoriscono il lavoro in team e la condivisione delle conoscenze.
Sicurezza e conformità: i cluster Big Data offrono funzionalità di sicurezza affidabili, ad esempio crittografia dei dati, controlli di accesso e conformità agli standard di settore. Le funzionalità di sicurezza proteggono i dati sensibili e aiutano il team a soddisfare i requisiti normativi.
Risorse di Azure consigliate per i cluster Big Data
- Apache Spark in Machine Learning: integrazione di Machine Learning con Azure Synapse Analytics consente di accedere facilmente alle risorse di calcolo distribuite tramite il framework Apache Spark.
- Synapse Analytics: documentazione completa per Synapse Analytics, che integra Big Data e data warehousing.
In sintesi, i cluster Big Data, sia SQL che Spark, sono fondamentali per il TDSP, perché forniscono la potenza di calcolo e la scalabilità necessarie per gestire in modo efficiente grandi quantità di dati. I cluster Big Data consentono ai data scientist di eseguire query complesse e analisi avanzate su set di dati di grandi dimensioni che facilitano informazioni dettagliate e lo sviluppo accurato dei modelli. Quando si usa il calcolo distribuito, questi cluster consentono l'elaborazione e l'analisi rapide dei dati, accelerando il flusso di lavoro complessivo di data science. I cluster Big Data supportano anche l'integrazione senza problemi con varie origini dati e strumenti, che migliorano la possibilità di inserire, elaborare e analizzare i dati da più ambienti. I cluster Big Data promuovono anche la collaborazione e la riproducibilità fornendo una piattaforma unificata in cui i team possono condividere efficacemente risorse, flussi di lavoro e risultati.
Intelligenza artificiale e Machine Learning Services
I servizi di intelligenza artificiale e Machine Learning (ML) sono parte integrante del TDSP per diversi motivi:
Analisi avanzata: i servizi di intelligenza artificiale e Machine Learning consentono l'analisi avanzata. I data scientist possono usare l'analisi avanzata per individuare modelli complessi, eseguire stime e generare informazioni dettagliate che non sono possibili con i metodi analitici tradizionali. Queste funzionalità avanzate sono fondamentali per la creazione di soluzioni di data science ad alto impatto.
Automazione delle attività ripetitive: i servizi di intelligenza artificiale e Machine Learning possono automatizzare attività ripetitive, ad esempio la pulizia dei dati, la progettazione delle funzionalità e il training del modello. L'automazione consente di risparmiare tempo e aiuta i data scientist a concentrarsi su aspetti più strategici del progetto, migliorando così la produttività complessiva.
Miglioramento dell'accuratezza e delle prestazioni: i modelli di Machine Learning possono migliorare l'accuratezza e le prestazioni delle stime e delle analisi imparando dai dati. Questi modelli possono migliorare continuamente man mano che diventano esposti a più dati, il che porta a un processo decisionale migliore e a risultati più affidabili.
Scalabilità: i servizi di intelligenza artificiale e Machine Learning offerti dalle piattaforme cloud, ad esempio Machine Learning, sono altamente scalabili. Possono gestire grandi volumi di dati e calcoli complessi, che consentono ai team di data science di ridimensionare le proprie soluzioni per soddisfare le crescenti esigenze senza preoccuparsi delle limitazioni dell'infrastruttura sottostanti.
Integrazione con altri strumenti: i servizi di intelligenza artificiale e Machine Learning si integrano perfettamente con altri strumenti e servizi all'interno dell'ecosistema Microsoft, ad esempio Azure Data Lake, Azure Databricks e Power BI. L'integrazione supporta un flusso di lavoro semplificato dall'inserimento e dall'elaborazione dei dati alla distribuzione e alla visualizzazione del modello.
Distribuzione e gestione dei modelli: i servizi di intelligenza artificiale e Machine Learning offrono strumenti affidabili per la distribuzione e la gestione di modelli di Machine Learning nell'ambiente di produzione. Funzionalità come il controllo della versione, il monitoraggio e la ripetizione automatica del training consentono di garantire che i modelli rimangano accurati ed efficaci nel tempo. Questo approccio semplifica la manutenzione delle soluzioni ml.
Elaborazione in tempo reale: i servizi di intelligenza artificiale e Machine Learning supportano l'elaborazione dei dati in tempo reale e il processo decisionale. L'elaborazione in tempo reale è essenziale per le applicazioni che richiedono informazioni dettagliate e azioni immediate, ad esempio il rilevamento delle frodi, i prezzi dinamici e i sistemi di raccomandazione.
Personalizzazione e flessibilità: i servizi di intelligenza artificiale e Machine Learning offrono una gamma di opzioni personalizzabili, da modelli predefiniti e API ai framework per la creazione di modelli personalizzati da zero. Questa flessibilità consente ai team di data science di adattare soluzioni a specifiche esigenze aziendali e casi d'uso.
Accesso agli algoritmi all'avanguardia: i servizi di intelligenza artificiale e Machine Learning forniscono ai data scientist l'accesso ad algoritmi e tecnologie all'avanguardia sviluppati da ricercatori leader. L'accesso garantisce che il team possa usare i miglioramenti più recenti nell'intelligenza artificiale e ml per i propri progetti.
Collaborazione e condivisione: le piattaforme di intelligenza artificiale e Machine Learning supportano ambienti di sviluppo collaborativo, in cui più membri del team possono collaborare nello stesso progetto, condividere codice e riprodurre esperimenti. La collaborazione migliora il lavoro in team e garantisce coerenza nello sviluppo di modelli.
Efficienza dei costi: i servizi di intelligenza artificiale e Machine Learning nel cloud possono essere più convenienti rispetto alla creazione e alla gestione di soluzioni locali. I provider di servizi cloud hanno modelli di determinazione dei prezzi flessibili che includono opzioni con pagamento in base al consumo, che possono ridurre i costi e ottimizzare l'utilizzo delle risorse.
Sicurezza e conformità avanzata: i servizi di intelligenza artificiale e Machine Learning sono dotati di solide funzionalità di sicurezza, tra cui crittografia dei dati, controlli di accesso sicuri e conformità agli standard e alle normative del settore. Queste funzionalità consentono di proteggere i dati e i modelli e soddisfare i requisiti legali e normativi.
Modelli e API predefiniti: molti servizi di intelligenza artificiale e Machine Learning forniscono modelli predefiniti e API per attività comuni, ad esempio l'elaborazione del linguaggio naturale, il riconoscimento delle immagini e il rilevamento delle anomalie. Le soluzioni predefinite possono accelerare lo sviluppo e la distribuzione e aiutare i team a integrare rapidamente le funzionalità di intelligenza artificiale nelle applicazioni.
Sperimentazione e prototipazione: le piattaforme di intelligenza artificiale e Machine Learning offrono ambienti per la sperimentazione e la creazione di prototipi rapidi. I data scientist possono testare rapidamente algoritmi, parametri e set di dati diversi per trovare la soluzione migliore. Sperimentazione e creazione di prototipi supportano un approccio iterativo allo sviluppo di modelli.
Risorse di Azure consigliate per i servizi di Intelligenza artificiale e Machine Learning
Machine Learning è la risorsa principale consigliata per l'applicazione di data science e TDSP. Azure offre anche servizi di intelligenza artificiale pronti per l'uso per applicazioni specifiche.
- Machine Learning: pagina principale della documentazione per Machine Learning che illustra la configurazione, il training del modello, la distribuzione e così via.
- Servizi di intelligenza artificiale di Azure: informazioni sui servizi di intelligenza artificiale che forniscono modelli di intelligenza artificiale predefiniti per le attività di visione, riconoscimento vocale, lingua e processo decisionale.
In sintesi, i servizi di intelligenza artificiale e Machine Learning sono fondamentali per il TDSP, perché forniscono potenti strumenti e framework che semplificano lo sviluppo, il training e la distribuzione di modelli di Machine Learning. Questi servizi automatizzano attività complesse, ad esempio la selezione degli algoritmi e l'ottimizzazione degli iperparametri, che accelerano notevolmente il processo di sviluppo del modello. Questi servizi forniscono anche un'infrastruttura scalabile che consente ai data scientist di gestire in modo efficiente set di dati di grandi dimensioni e attività a elevato utilizzo di calcolo. Gli strumenti di intelligenza artificiale e Machine Learning si integrano perfettamente con altri servizi di Azure e migliorano l'inserimento dei dati, la pre-elaborazione e la distribuzione del modello. L'integrazione consente di garantire un flusso di lavoro end-to-end uniforme. Inoltre, questi servizi favoriscono la collaborazione e la riproducibilità. I team possono condividere informazioni dettagliate ed sperimentare in modo efficace i risultati e i modelli mantenendo standard elevati di sicurezza e conformità.
Intelligenza artificiale responsabile
Con le soluzioni di intelligenza artificiale o Machine Learning, Microsoft promuove gli strumenti di intelligenza artificiale responsabili all'interno delle soluzioni di intelligenza artificiale e Machine Learning. Questi strumenti supportano microsoft Responsible AI Standard. Il carico di lavoro deve comunque risolvere singolarmente i danni correlati all'intelligenza artificiale.
Citazioni con peer reviewing
Il TDSP è una metodologia ben consolidata usata dai team in tutti gli impegni Microsoft. Il TDSP è documentato e studiato in letteratura con revisione peer. Le citazioni offrono l'opportunità di esaminare le funzionalità e le applicazioni TDSP. Per altre informazioni e un elenco di citazioni, vedere Ciclo di vita di TDSP.