Approcci architetturali per IA e ML in soluzioni multi-tenant
Un numero sempre crescente di soluzioni multi-tenant si basa sull'intelligenza artificiale (IA) e machine learning (ML). Una soluzione di intelligenza artificiale/Machine Learning multi-tenant è una soluzione che offre funzionalità simili basate su ML a un numero qualsiasi di tenant. I tenant in genere non possono visualizzare o condividere i dati di qualsiasi altro tenant, ma in alcune situazioni i tenant potrebbero usare gli stessi modelli di altri tenant.
Le architetture di intelligenza artificiale/Machine Learning multi-tenant devono considerare i requisiti per i dati e i modelli, nonché le risorse di calcolo necessarie per eseguire il training dei modelli e per eseguire l'inferenza dai modelli. È importante considerare come vengono distribuiti, distribuiti e orchestrati i modelli di intelligenza artificiale multi-tenant e per assicurarsi che la soluzione sia accurata, affidabile e scalabile.
Considerazioni e requisiti principali
Quando si lavora con intelligenza artificiale e Machine Learning, è importante considerare separatamente i requisiti per il training e l'inferenza. Lo scopo del training è creare un modello predittivo basato su un set di dati. L'inferenza viene eseguita quando si usa il modello per stimare un elemento nell'applicazione. Ognuno di questi processi ha requisiti diversi. In una soluzione multi-tenant è necessario considerare il modo in cui il modello di tenancy influisce su ogni processo. Prendendo in considerazione ognuno di questi requisiti, è possibile assicurarsi che la soluzione fornisca risultati accurati, prestazioni ben sotto carico, sia conveniente e possa essere ridimensionata per la crescita futura.
Isolamento dei tenant
Assicurarsi che i tenant non ottengano l'accesso non autorizzato o indesiderato ai dati o ai modelli di altri tenant. Trattare i modelli con una sensibilità simile ai dati non elaborati sottoposti a training. Assicurarsi che i tenant comprendano il modo in cui i dati vengono usati per eseguire il training dei modelli e il modo in cui i modelli sottoposti a training sui dati di altri tenant potrebbero essere usati per scopi di inferenza nei carichi di lavoro.
Esistono tre approcci comuni per l'uso dei modelli di Machine Learning nelle soluzioni multi-tenant: modelli specifici del tenant, modelli condivisi e modelli condivisi ottimizzati.
Modelli specifici del tenant
I modelli specifici del tenant vengono sottoposti a training solo sui dati per un singolo tenant e quindi vengono applicati a tale tenant singolo. I modelli specifici del tenant sono appropriati quando i dati dei tenant sono sensibili o quando l'ambito è limitato per apprendere dai dati forniti da un tenant e si applica il modello a un altro tenant. Il diagramma seguente illustra come creare una soluzione con modelli specifici del tenant per due tenant:
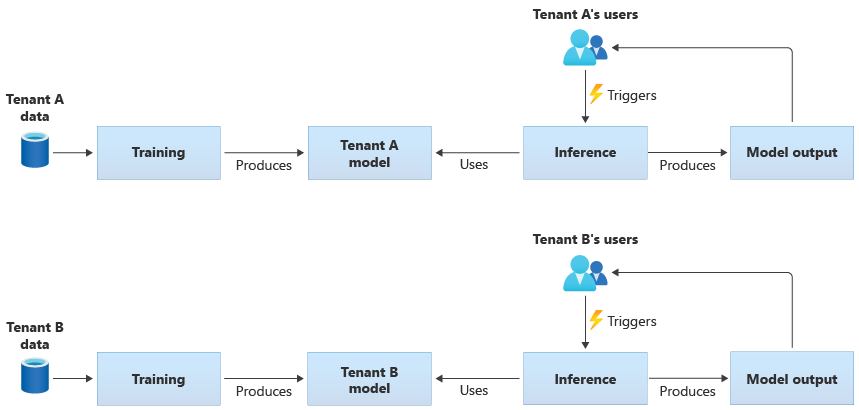
Modelli condivisi
Nelle soluzioni che usano modelli condivisi, tutti i tenant eseguono l'inferenza in base allo stesso modello condiviso. I modelli condivisi possono essere modelli con training preliminare acquisiti o ottenuti da un'origine della community. Il diagramma seguente illustra come usare un singolo modello con training preliminare per l'inferenza da tutti i tenant:
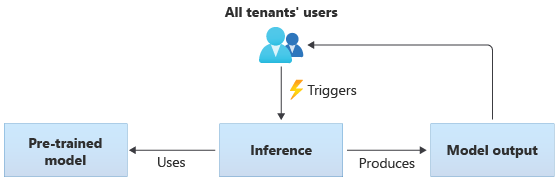
È anche possibile creare modelli condivisi eseguendo il training dai dati forniti da tutti i tenant. Il diagramma seguente illustra un singolo modello condiviso, sottoposto a training sui dati di tutti i tenant:
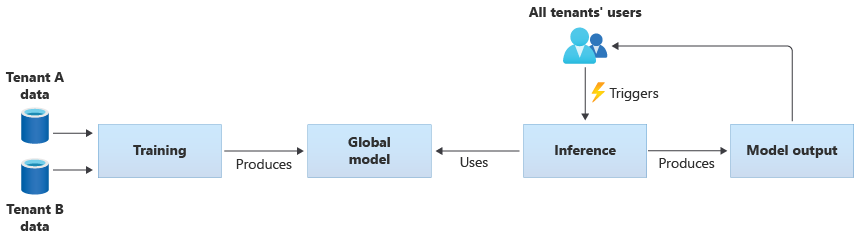
Importante
Se si esegue il training di un modello condiviso dai dati dei tenant, assicurarsi che i tenant comprendano e accettino l'uso dei dati. Assicurarsi che le informazioni di identificazione vengano rimosse dai dati dei tenant.
Valutare le operazioni da eseguire, se un oggetto tenant viene usato per eseguire il training di un modello che verrà applicato a un altro tenant. Ad esempio, è possibile escludere i dati di tenant specifici dal set di dati di training?
Modelli condivisi ottimizzati
È anche possibile scegliere di acquisire un modello di base con training preliminare e quindi eseguire un'ulteriore ottimizzazione del modello per renderlo applicabile a ognuno dei tenant, in base ai propri dati. Il diagramma seguente illustra questo approccio:
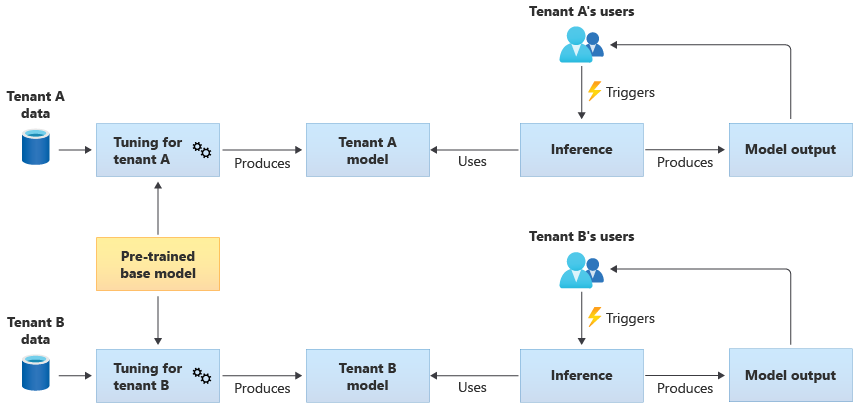
Scalabilità
Valutare il modo in cui la crescita della soluzione influisce sull'uso dei componenti di Intelligenza artificiale e Machine Learning. La crescita può fare riferimento a un aumento del numero di tenant, alla quantità di dati archiviati per ogni tenant, al numero di utenti e al volume di richieste alla soluzione.
Training: esistono diversi fattori che influenzano le risorse necessarie per eseguire il training dei modelli. Questi fattori includono il numero di modelli di cui è necessario eseguire il training, la quantità di dati con cui si esegue il training dei modelli e la frequenza con cui si esegue il training o la ripetizione del training dei modelli. Se si creano modelli specifici del tenant, man mano che aumenta il numero di tenant, sarà probabile che la quantità di risorse di calcolo e di archiviazione necessarie crescerà. Se si creano modelli condivisi ed eseguirne il training in base ai dati di tutti i tenant, è meno probabile che le risorse per il training vengano ridimensionate allo stesso tasso di crescita del numero di tenant. Tuttavia, un aumento della quantità complessiva di dati di training influirà sulle risorse utilizzate, per eseguire il training dei modelli condivisi e specifici del tenant.
Inferenza: le risorse necessarie per l'inferenza sono in genere proporzionali al numero di richieste che accedono ai modelli per l'inferenza. Con l'aumento del numero di tenant, è probabile che anche il numero di richieste aumenti.
È consigliabile usare correttamente i servizi di Azure. Poiché i carichi di lavoro di intelligenza artificiale/Machine Learning tendono a usare contenitori, servizio Azure Kubernetes (AKS) e Istanze di Azure Container (ACI) tendono a essere scelte comuni per i carichi di lavoro di intelligenza artificiale/Machine Learning. Il servizio Azure Kubernetes è in genere una scelta ottimale per abilitare la scalabilità elevata e ridimensionare dinamicamente le risorse di calcolo in base alla richiesta. Per i carichi di lavoro di piccole dimensioni, ACI può essere una semplice piattaforma di calcolo da configurare, anche se non viene ridimensionata con facilità con il servizio Azure Kubernetes.
Prestazioni
Prendere in considerazione i requisiti di prestazioni per i componenti di intelligenza artificiale/Machine Learning della soluzione, sia per il training che per l'inferenza. È importante chiarire i requisiti di latenza e prestazioni per ogni processo, in modo da poter misurare e migliorare in base alle esigenze.
Training: il training viene spesso eseguito come processo batch, il che significa che potrebbe non essere sensibile alle prestazioni come altre parti del carico di lavoro. Tuttavia, è necessario assicurarsi di effettuare il provisioning di risorse sufficienti per eseguire il training del modello in modo efficiente, incluso il ridimensionamento.
Inferenza: l'inferenza è un processo sensibile alla latenza, che spesso richiede una risposta veloce o anche in tempo reale. Anche se non è necessario eseguire l'inferenza in tempo reale, assicurarsi di monitorare le prestazioni della soluzione e usare i servizi appropriati per ottimizzare il carico di lavoro.
Prendere in considerazione l'uso delle funzionalità di elaborazione ad alte prestazioni di Azure per i carichi di lavoro di Intelligenza artificiale e Machine Learning. Azure offre molti tipi diversi di macchine virtuali e altre istanze hardware. Valutare se la soluzione può trarre vantaggio dall'uso di CPU, GPU, FPGA o altri ambienti con accelerazione hardware. Azure offre anche inferenza in tempo reale con GPU NVIDIA, inclusi i server di inferenza NVIDIA Framework. Per i requisiti di calcolo con priorità bassa, è consigliabile usare i pool di nodi spot del servizio Azure Kubernetes. Per altre informazioni sull'ottimizzazione dei servizi di calcolo in una soluzione multi-tenant, vedere Approcci architetturali per il calcolo in soluzioni multi-tenant.
Il training del modello richiede in genere molte interazioni con gli archivi dati, quindi è anche importante considerare la strategia dei dati e le prestazioni fornite dal livello dati. Per altre informazioni sulla multi-tenancy e sui servizi dati, vedere Approcci architetturali per l'archiviazione e i dati nelle soluzioni multi-tenant.
Valutare la possibilità di profilare le prestazioni della soluzione. Ad esempio, Azure Machine Learning offre funzionalità di profilatura che è possibile usare durante lo sviluppo e la strumentazione della soluzione.
Complessità dell'implementazione
Quando si compila una soluzione per usare intelligenza artificiale e Machine Learning, è possibile scegliere di usare componenti predefiniti o per compilare componenti personalizzati. Ci sono due decisioni chiave da prendere. Il primo è la piattaforma o il servizio usato per intelligenza artificiale e Machine Learning. Il secondo è se si usano modelli con training preliminare o si creano modelli personalizzati.
Piattaforme: sono disponibili molti servizi di Azure che è possibile usare per i carichi di lavoro di intelligenza artificiale e Machine Learning. Ad esempio, Servizi cognitivi di Azure e il servizio Azure OpenAI forniscono API per eseguire l'inferenza su modelli predefiniti e Microsoft gestisce le risorse sottostanti. Servizi cognitivi di Azure consente di distribuire rapidamente una nuova soluzione, ma offre meno controllo sul modo in cui vengono eseguiti il training e l'inferenza e potrebbe non adattarsi a ogni tipo di carico di lavoro. Al contrario, Azure Machine Learning è una piattaforma che consente di compilare, eseguire il training e usare modelli di Machine Learning personalizzati. Azure Machine Learning offre controllo e flessibilità, ma aumenta la complessità della progettazione e dell'implementazione. Esaminare i prodotti e le tecnologie di Machine Learning di Microsoft per prendere una decisione informata quando si seleziona un approccio.
Modelli: anche quando non si usa un modello completo fornito da un servizio come Servizi cognitivi di Azure, è comunque possibile accelerare lo sviluppo usando un modello con training preliminare. Se un modello con training preliminare non soddisfa esattamente le proprie esigenze, valutare la possibilità di estendere un modello con training preliminare applicando una tecnica denominata transfer learning o fine-tunning. L'apprendimento per il trasferimento consente di estendere un modello esistente e applicarlo a un dominio diverso. Ad esempio, se stai creando un servizio di raccomandazione musicale multi-tenant, potresti prendere in considerazione la creazione di un modello con training preliminare di raccomandazioni musicali e usare l'apprendimento per il trasferimento per eseguire il training del modello per le preferenze musicali di un utente specifico.
Usando piattaforme ml predefinite come Servizi cognitivi di Azure o il servizio OpenAI di Azure o un modello con training preliminare, è possibile ridurre significativamente i costi iniziali di ricerca e sviluppo. L'uso di piattaforme predefinite potrebbe risparmiare molti mesi di ricerca ed evitare la necessità di assumere data scientist altamente qualificati per eseguire il training, la progettazione e l'ottimizzazione dei modelli.
Ottimizzazione dei costi
In genere, i carichi di lavoro di intelligenza artificiale e Machine Learning comportano la maggior parte dei costi delle risorse di calcolo necessarie per il training e l'inferenza del modello. Vedere Approcci architetturali per il calcolo in soluzioni multi-tenant per comprendere come ottimizzare il costo del carico di lavoro di calcolo per i requisiti.
Quando si pianificano i costi di intelligenza artificiale e Machine Learning, prendere in considerazione i requisiti seguenti:
- Determinare gli SKU di calcolo per il training. Ad esempio, fare riferimento a indicazioni su come eseguire questa operazione con Azure ML.
- Determinare gli SKU di calcolo per l'inferenza. Per una stima dei costi di esempio per l'inferenza, vedere le linee guida per Azure ML.
- Monitorare l'utilizzo. Osservando l'utilizzo delle risorse di calcolo, è possibile determinare se è necessario ridurre o aumentare la capacità distribuendo SKU diversi o ridimensionando le risorse di calcolo man mano che cambiano i requisiti. Vedere Monitoraggio di Azure Machine Learning.
- Ottimizzare l'ambiente di clustering di calcolo. Quando si usano cluster di calcolo, monitorare l'utilizzo del cluster o configurare la scalabilità automatica per ridurre i nodi di calcolo.
- Condividere le risorse di calcolo. Valutare se è possibile ottimizzare il costo delle risorse di calcolo condividendoli tra più tenant.
- Prendi in considerazione il tuo budget. Comprendere se si dispone di un budget fisso e monitorare il consumo di conseguenza. È possibile configurare i budget per evitare eccedenze in sospeso e allocare quote in base alla priorità del tenant.
Approcci e modelli da prendere in considerazione
Azure offre un set di servizi per abilitare carichi di lavoro di intelligenza artificiale e Machine Learning. Esistono diversi approcci architetturali comuni usati nelle soluzioni multi-tenant: per usare soluzioni di intelligenza artificiale/Machine Learning predefinite, per creare un'architettura di intelligenza artificiale/Machine Learning personalizzata usando Azure Machine Learning e per usare una delle piattaforme di analisi di Azure.
Usare i servizi di intelligenza artificiale/Machine Learning predefiniti
È consigliabile provare a usare servizi di intelligenza artificiale/Machine Learning predefiniti, dove è possibile. Ad esempio, l'organizzazione potrebbe iniziare a esaminare l'intelligenza artificiale/MACHINE e vuole integrarsi rapidamente con un servizio utile. In alternativa, potrebbero essere presenti requisiti di base che non richiedono il training e lo sviluppo di modelli di Machine Learning personalizzati. I servizi ml predefiniti consentono di usare l'inferenza senza compilare ed eseguire il training di modelli personalizzati.
Azure offre diversi servizi che forniscono tecnologia di intelligenza artificiale e Machine Learning in un'ampia gamma di domini, tra cui comprensione del linguaggio, riconoscimento vocale, conoscenza, riconoscimento di documenti e moduli e visione artificiale. I servizi di intelligenza artificiale/Machine Learning predefiniti di Azure includono Servizi cognitivi di Azure, Servizio OpenAI di Azure, Ricerca cognitiva di Azure e Azure Riconoscimento modulo. Ogni servizio fornisce un'interfaccia semplice per l'integrazione e una raccolta di modelli con training preliminare e testato. Come servizi gestiti, forniscono contratti di servizio e richiedono una configurazione o una gestione continuativa. Non è necessario sviluppare o testare modelli personalizzati per usare questi servizi.
Molti servizi di Machine Learning gestiti non richiedono il training del modello o i dati, quindi in genere non c'è alcun problema di isolamento dei dati del tenant. Tuttavia, quando si usa Ricerca cognitiva in una soluzione multi-tenant, vedere Modelli di progettazione per applicazioni SaaS multi-tenant e Ricerca cognitiva di Azure.
Prendere in considerazione i requisiti di scalabilità per i componenti della soluzione. Ad esempio, molte delle API all'interno di Servizi cognitivi di Azure supportano un numero massimo di richieste al secondo. Se si distribuisce una singola risorsa di Servizi cognitivi da condividere tra i tenant, con l'aumentare del numero di tenant, potrebbe essere necessario ridimensionare più risorse.
Nota
Alcuni servizi gestiti consentono di eseguire il training con i propri dati, tra cui il servizio Visione personalizzata, l'API Viso, Riconoscimento modulo modelli personalizzati e alcuni modelli OpenAI che supportano la personalizzazione e l'esecuzione fine. Quando si lavora con questi servizi, è importante considerare i requisiti di isolamento per i dati dei tenant.
Architettura personalizzata di intelligenza artificiale/Machine Learning
Se la soluzione richiede modelli personalizzati o si lavora in un dominio non coperto da un servizio ml gestito, è consigliabile creare un'architettura di intelligenza artificiale/Machine Learning personalizzata. Azure Machine Learning offre una suite di funzionalità per orchestrare il training e la distribuzione di modelli di Machine Learning. Azure Machine Learning supporta molte librerie di Machine Learning open source, tra cui PyTorch, Tensorflow, Scikit e Keras. È possibile monitorare continuamente le metriche delle prestazioni dei modelli, rilevare la deriva dei dati e attivare la ripetizione del training per migliorare le prestazioni del modello. Durante tutto il ciclo di vita dei modelli di Machine Learning, Azure Machine Learning consente la controllabilità e la governance con rilevamento e derivazione predefiniti per tutti gli artefatti di Machine Learning.
Quando si lavora in una soluzione multi-tenant, è importante considerare i requisiti di isolamento dei tenant durante le fasi di training e inferenza. È anche necessario determinare il processo di training e distribuzione del modello. Azure Machine Learning offre una pipeline per eseguire il training dei modelli e di distribuirli in un ambiente da usare per l'inferenza. In un contesto multi-tenant valutare se i modelli devono essere distribuiti nelle risorse di calcolo condivise o se ogni tenant dispone di risorse dedicate. Progettare le pipeline di distribuzione del modello in base al modello di isolamento e al processo di distribuzione del tenant.
Quando si usano modelli open source, potrebbe essere necessario ripetere il training di questi modelli usando l'apprendimento di trasferimento o l'ottimizzazione. Si consideri come gestire i diversi modelli e i dati di training per ogni tenant, nonché le versioni del modello.
Il diagramma seguente illustra un'architettura di esempio che usa Azure Machine Learning. L'esempio usa l'approccio di isolamento dei modelli specifici del tenant.
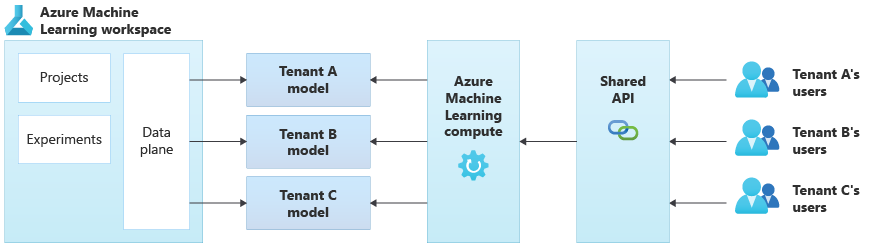
Soluzioni di intelligenza artificiale/Machine Learning integrate
Azure offre diverse piattaforme di analisi avanzate che possono essere usate per un'ampia gamma di scopi. Queste piattaforme includono Azure Synapse Analytics, Databricks e Apache Spark.
È possibile prendere in considerazione l'uso di queste piattaforme per intelligenza artificiale/MACHINE, quando è necessario ridimensionare le funzionalità di Machine Learning in un numero molto elevato di tenant e quando è necessaria un'orchestrazione e calcolo su larga scala. È anche possibile prendere in considerazione l'uso di queste piattaforme per intelligenza artificiale/Machine Learning, quando è necessaria una piattaforma di analisi generale per altre parti della soluzione, ad esempio per l'analisi dei dati e l'integrazione con la creazione di report tramite Microsoft Power BI. È possibile distribuire una singola piattaforma che copre tutte le esigenze di analisi e intelligenza artificiale/Machine Learning. Quando si implementano piattaforme dati in una soluzione multi-tenant, vedere Approcci architetturali per l'archiviazione e i dati nelle soluzioni multi-tenant.
Antipattern da evitare
- Mancata considerazione dei requisiti di isolamento. È importante considerare attentamente come isolare i dati e i modelli dei tenant, sia per il training che per l'inferenza. In caso contrario, potrebbe violare i requisiti legali o contrattuali. Può anche ridurre l'accuratezza dei modelli per eseguire il training tra più dati dei tenant, se i dati sono sostanzialmente diversi.
- Vicini rumorosi. Valutare se i processi di training o inferenza potrebbero essere soggetti al problema Noisy Neighbor. Ad esempio, se si dispone di diversi tenant di grandi dimensioni e di un singolo tenant di piccole dimensioni, assicurarsi che il training del modello per i tenant di grandi dimensioni non consumi inavvertitamente tutte le risorse di calcolo e di fame i tenant più piccoli. Usare la governance e il monitoraggio delle risorse per ridurre il rischio del carico di lavoro di calcolo di un tenant interessato dall'attività degli altri tenant.
Contributori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- Kevin Ashley | Senior Customer Engineer, FastTrack per Azure
Altri contributori:
- Paul Burpo | Principal Customer Engineer, FastTrack per Azure
- John Downs | Principal Customer Engineer, FastTrack per Azure
- Daniel Scott-Raynsford | Partner Technology Strategist
- Arsen Vladimirintune | Principal Customer Engineer, FastTrack per Azure
Passaggi successivi
Vedere Approcci architetturali per il calcolo in soluzioni multi-tenant.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per