I dati sono spesso considerati la parte più preziosa di una soluzione, perché rappresenta le informazioni aziendali preziose dei clienti. È quindi importante gestire attentamente i dati. Quando si pianificano componenti di archiviazione o dati per un sistema multi-tenant, è necessario decidere un approccio per la condivisione o l'isolamento dei dati dei tenant.
In questo articolo vengono fornite indicazioni sulle considerazioni chiave e sui requisiti essenziali per gli architetti di soluzioni quando si decide un approccio per archiviare i dati in un sistema multi-tenant. È quindi consigliabile usare alcuni modelli comuni per applicare la multi-tenancy ai servizi di archiviazione e dati e alcuni antipattern da evitare. Infine, forniamo indicazioni mirate per alcune situazioni specifiche.
Considerazioni e requisiti principali
È importante considerare gli approcci usati per i servizi di archiviazione e dati da diverse prospettive, che si allineano approssimativamente ai pilastri di Azure Well-Architected Framework.
Ridimensiona
Quando si lavora con i servizi che archiviano i dati, è consigliabile prendere in considerazione il numero di tenant presenti e il volume di dati archiviati. Se si dispone di un numero ridotto di tenant ,ad esempio cinque o meno, e si archiviano piccole quantità di dati per ogni tenant, è probabile che si tratti di uno spreco di risorse di archiviazione dei dati per pianificare un approccio di archiviazione dei dati altamente scalabile o di creare un approccio completamente automatizzato per gestire le risorse di dati. Ma man mano che si aumenta, si trae sempre più vantaggio dalla definizione di una strategia chiara per ridimensionare i dati e le risorse di archiviazione e applicare l'automazione alla gestione. Quando si hanno più di 50 tenant o se si prevede di raggiungere tale livello di scalabilità, è particolarmente importante progettare i dati e l'approccio di archiviazione, con scalabilità come considerazione chiave.
Si consideri la misura in cui si prevede di ridimensionare e pianificare chiaramente l'approccio dell'architettura di archiviazione dei dati per soddisfare tale livello di scalabilità.
Prevedibilità delle prestazioni
I servizi di archiviazione e dati multi-tenant sono particolarmente soggetti al problema Noisy Neighbor. È importante valutare se i tenant potrebbero influire sulle prestazioni dell'altro. Ad esempio, i tenant hanno picchi sovrapposti nei modelli di utilizzo nel tempo? Tutti i clienti usano la soluzione contemporaneamente ogni giorno o vengono distribuite uniformemente le richieste? Questi fattori influiranno sul livello di isolamento necessario per la progettazione, sulla quantità di risorse di cui è necessario effettuare il provisioning e sul livello di condivisione delle risorse tra i tenant.
È importante considerare la risorsa di Azure e richiedere quote come parte di questa decisione. Si supponga, ad esempio, di distribuire un singolo account di archiviazione per contenere tutti i dati dei tenant. Se si supera un numero specifico di operazioni di archiviazione al secondo, Archiviazione di Azure rifiuterà le richieste dell'applicazione e tutti i tenant saranno interessati. Questo comportamento è detto comportamento di limitazione . È importante monitorare le richieste limitate. Per altre informazioni, vedere Linee guida per i tentativi per i servizi di Azure.
Isolamento dei dati
Quando si progetta una soluzione che contiene servizi dati multi-tenant, esistono in genere opzioni e livelli di isolamento dei dati diversi, ognuno con i propri vantaggi e compromessi. Ad esempio:
- Quando si usa Azure Cosmos DB, è possibile distribuire contenitori separati per ogni tenant ed è possibile condividere database e account tra più tenant. In alternativa, è possibile valutare la possibilità di distribuire database diversi o anche account per ogni tenant, a seconda del livello di isolamento richiesto.
- Quando si usano Archiviazione di Azure per i dati BLOB, è possibile distribuire contenitori BLOB separati per ogni tenant oppure distribuire account di archiviazione separati.
- Quando si usa Azure SQL, è possibile usare tabelle separate nei database condivisi oppure distribuire database o server separati per ogni tenant.
- In tutti i servizi di Azure è possibile valutare la possibilità di distribuire le risorse all'interno di una singola sottoscrizione di Azure condivisa oppure di usare più sottoscrizioni di Azure, ad esempio anche una per tenant.
Non esiste una singola soluzione che funzioni per ogni situazione. L'opzione scelta dipende da diversi fattori e dai requisiti dei tenant. Ad esempio, se i tenant devono soddisfare standard di conformità o normativi specifici, potrebbe essere necessario applicare un livello di isolamento superiore. Analogamente, potrebbe essere necessario disporre di requisiti commerciali per isolare fisicamente i dati dei clienti oppure potrebbe essere necessario applicare l'isolamento per evitare il problema Noisy Neighbor. Inoltre, se i tenant devono usare le proprie chiavi di crittografia, hanno singoli criteri di backup e ripristino oppure devono archiviare i dati in posizioni geografiche diverse, potrebbe essere necessario isolarli da altri tenant o raggrupparli con tenant con criteri simili.
Complessità dell'implementazione
È importante considerare la complessità dell'implementazione. È consigliabile mantenere l'architettura il più semplice possibile, rispettando comunque i requisiti. Evitare di impegnarsi in un'architettura che diventerà sempre più complessa quando si ridimensiona o un'architettura che non si dispone delle risorse o delle competenze necessarie per sviluppare e gestire.
Analogamente, se la soluzione non deve essere ridimensionata in un numero elevato di tenant o se non si hanno problemi relativi alle prestazioni o all'isolamento dei dati, è preferibile mantenere la soluzione semplice ed evitare di aggiungere complessità non necessarie.
Un particolare problema per le soluzioni di dati multi-tenant è il livello di personalizzazione supportato. Ad esempio, un tenant può estendere il modello di dati o applicare regole dati personalizzate? Assicurarsi di progettare per questo requisito in anticipo. Evitare di creare fork o fornire un'infrastruttura personalizzata per singoli tenant. L'infrastruttura personalizzata impedisce la scalabilità, il test della soluzione e la distribuzione degli aggiornamenti. Prendere invece in considerazione l'uso di flag di funzionalità e altre forme di configurazione del tenant.
Complessità della gestione e delle operazioni
Valutare il modo in cui si prevede di gestire la soluzione e il modo in cui l'approccio multi-tenancy influisce sulle operazioni e sui processi. Ad esempio:
- Gestione: prendere in considerazione le operazioni di gestione tra tenant, ad esempio le normali attività di manutenzione. Se si usano più account, server o database, come si avviano e monitorano le operazioni per ogni tenant?
- Monitoraggio e misurazione: se si monitorano o si misurano i tenant, valutare il modo in cui la soluzione segnala le metriche e se possono essere facilmente collegate al tenant che ha attivato la richiesta.
- Creazione di report: i dati dei report provenienti da tenant isolati potrebbero richiedere che ogni tenant pubblica i dati in un data warehouse centralizzato, invece di eseguire query su ogni database singolarmente e quindi aggregare i risultati.
- Aggiornamenti dello schema: se si usa un database che applica uno schema, pianificare la distribuzione degli aggiornamenti dello schema nell'ambiente. Valutare il modo in cui l'applicazione conosce la versione dello schema da usare per le query di database di un tenant specifico.
- Requisiti: prendere in considerazione i requisiti di disponibilità elevata dei tenant (ad esempio, contratti di servizio o contratti di servizio di tempo di attività) e i requisiti di ripristino di emergenza (ad esempio, obiettivi del tempo di ripristino o RTO e obiettivi del punto di ripristino o RPO). Se i tenant hanno aspettative diverse, sarà possibile soddisfare i requisiti di ogni tenant?
- Migrazione: come si eseguirà la migrazione dei tenant se devono passare a un tipo di servizio diverso, a una distribuzione diversa o a un'altra area?
Costo
In genere, maggiore è la densità dei tenant per l'infrastruttura di distribuzione, minore è il costo per il provisioning di tale infrastruttura. Tuttavia, l'infrastruttura condivisa aumenta la probabilità di problemi come il problema Noisy Neighbor, quindi considerare attentamente i compromessi.
Approcci e modelli da prendere in considerazione
Diversi modelli di progettazione del Centro architetture di Azure hanno rilevanza per servizi di archiviazione e dati multi-tenant. È possibile scegliere di seguire un modello in modo coerente. In alternativa, è possibile prendere in considerazione la combinazione e la corrispondenza dei modelli. Ad esempio, è possibile usare un database multi-tenant per la maggior parte dei tenant, ma distribuire timbri a tenant singoli per i tenant che pagano più o che hanno requisiti insoliti. Analogamente, è spesso consigliabile ridimensionare usando indicatori di distribuzione, anche quando si usa un database multi-tenant o database partizionati all'interno di un timbro.
Modello degli stamp di distribuzione
Per altre informazioni sul modo in cui è possibile usare il modello Deployment Stamps per supportare una soluzione multi-tenant, vedere Panoramica.
Database e archivi file multi-tenant condivisi
È consigliabile distribuire un database multi-tenant condiviso, un account di archiviazione o una condivisione file e condividerlo tra tutti i tenant.
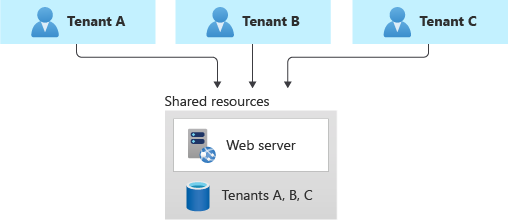
Questo approccio fornisce la massima densità dei tenant all'infrastruttura, quindi tende a raggiungere il costo più basso di qualsiasi approccio. Spesso riduce anche il sovraccarico di gestione, perché è presente un singolo database o una risorsa da gestire, eseguire il backup e proteggere.
Tuttavia, quando si lavora con l'infrastruttura condivisa, è necessario considerare diversi aspetti:
- Limiti di scalabilità: quando ci si basa su una singola risorsa, prendere in considerazione la scalabilità e i limiti supportati di tale risorsa. Ad esempio, la dimensione massima di un database o di un archivio file o i limiti massimi di velocità effettiva diventerà un blocco rigido, se l'architettura si basa su un singolo database. Considerare attentamente la scala massima che è necessario ottenere e confrontarla con i limiti correnti e futuri, prima di selezionare questo modello.
- Vicini rumorosi: il problema Del rumore vicino potrebbe diventare un fattore, soprattutto se si dispone di tenant particolarmente occupati o generare carichi di lavoro più elevati rispetto ad altri. Valutare la possibilità di applicare il modello di limitazione delle richieste o il modello di limitazione della frequenza per attenuare questi effetti.
- Monitoraggio di ogni tenant: potrebbe essere difficile monitorare l'attività e misurare il consumo per un singolo tenant. Alcuni servizi, ad esempio Azure Cosmos DB, forniscono report sull'utilizzo delle risorse per ogni richiesta, quindi queste informazioni possono essere monitorate per misurare l'utilizzo per ogni tenant. Altri servizi non forniscono lo stesso livello di dettaglio. Ad esempio, le metriche di File di Azure per la capacità dei file sono disponibili per ogni dimensione di condivisione file, solo quando si usano condivisioni Premium. Tuttavia, il livello standard fornisce le metriche solo a livello di account di archiviazione.
- Requisiti del tenant: i tenant possono avere requisiti diversi per la sicurezza, il backup, la disponibilità o la posizione di archiviazione. Se queste non corrispondono alla configurazione della singola risorsa, potrebbe non essere possibile gestirle.
- Personalizzazione dello schema: quando si usa un database relazionale o un'altra situazione in cui lo schema dei dati è importante, la personalizzazione dello schema a livello di tenant è difficile.
Modello di partizionamento orizzontale
Il modello di partizionamento orizzontale prevede la distribuzione di più database separati, denominati partizioni, che contengono ognuno uno o più dati dei tenant. A differenza dei francobolli di distribuzione, le partizioni non implicano che l'intera infrastruttura sia duplicata. È possibile partizionare i database senza duplicare o partizionare altre infrastrutture nella soluzione.

Il partizionamento orizzontale è strettamente correlato al partizionamento e i termini vengono spesso usati in modo intercambiabile. Prendere in considerazione le linee guida per il partizionamento orizzontale, verticale e funzionale dei dati.
Il modello di partizionamento orizzontale può essere ridimensionato a un numero molto elevato di tenant. Inoltre, a seconda del carico di lavoro, potrebbe essere possibile ottenere una densità elevata di tenant per le partizioni, in modo che il costo possa essere interessante. Il modello di partizionamento orizzontale può essere usato anche per gestire le quote, i limiti e i vincoli del servizio di Azure.
Alcuni archivi dati, ad esempio Azure Cosmos DB, offrono supporto nativo per il partizionamento orizzontale o il partizionamento. Quando si usano altre soluzioni, ad esempio Azure SQL, può essere più complesso creare un'infrastruttura di partizionamento orizzontale e instradare le richieste alla partizione corretta per un determinato tenant.
Il partizionamento orizzontale rende anche difficile supportare le differenze di configurazione a livello di tenant e consentire ai clienti di fornire le proprie chiavi di crittografia.
App multi-tenant con database dedicati per ogni tenant
Un altro approccio comune consiste nel distribuire una singola applicazione multi-tenant, con database dedicati per ogni tenant.
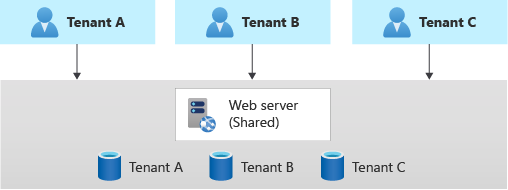
In questo modello, i dati di ogni tenant sono isolati dagli altri e potrebbe essere possibile supportare un certo grado di personalizzazione per ogni tenant.
Poiché si effettua il provisioning di risorse dati dedicate per ogni tenant, il costo per questo approccio può essere superiore a quello dei modelli di hosting condivisi. Azure offre tuttavia diverse opzioni che è possibile prendere in considerazione per condividere il costo di hosting di singole risorse di dati tra più tenant. Ad esempio, quando si usa Azure SQL, è possibile prendere in considerazione i pool elastici. Per Azure Cosmos DB, è possibile effettuare il provisioning della velocità effettiva per un database e la velocità effettiva viene condivisa tra i contenitori in tale database, anche se questo approccio non è appropriato quando sono necessarie prestazioni garantite per ogni contenitore.
In questo approccio, poiché solo i componenti dati vengono distribuiti singolarmente per ogni tenant, è probabile che sia possibile ottenere una densità elevata per gli altri componenti della soluzione e ridurre il costo di tali componenti.
È importante usare approcci di distribuzione automatizzata quando si effettua il provisioning dei database per ogni tenant.
Modello geodes
Il modello Geode è progettato appositamente per le soluzioni distribuite geograficamente, incluse le soluzioni multi-tenant. Supporta un carico elevato e livelli elevati di resilienza. Se si implementa il modello Geode, il livello dati deve essere in grado di replicare i dati tra aree geografiche e deve supportare scritture in più aree geografiche.
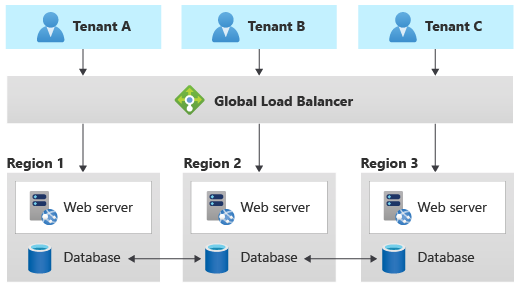
Azure Cosmos DB fornisce scritture multimaster per supportare questo modello e Cassandra supporta cluster in più aree. Altri servizi dati in genere non sono in grado di supportare questo modello, senza una personalizzazione significativa.
Antipattern da evitare
Quando si creano servizi dati multi-tenant, è importante evitare situazioni che impediscono la scalabilità.
Per i database relazionali, questi includono:
- Isolamento basato su tabella. Quando si lavora all'interno di un singolo database, evitare di creare singole tabelle per ogni tenant. Un singolo database non sarà in grado di supportare un numero molto elevato di tenant quando si usa questo approccio e diventa sempre più difficile eseguire query, gestire e aggiornare i dati. Prendere invece in considerazione l'uso di un singolo set di tabelle multi-tenant con una colonna dell'identificatore del tenant. In alternativa, è possibile usare uno dei modelli descritti in precedenza per distribuire database separati per ogni tenant.
- Personalizzazione del tenant a livello di colonna. Evitare di applicare gli aggiornamenti dello schema che si applicano solo a un singolo tenant. Si supponga, ad esempio, di avere un singolo database multi-tenant. Evitare di aggiungere una nuova colonna per soddisfare i requisiti di un tenant specifico. Potrebbe essere accettabile per un numero ridotto di personalizzazioni, ma questo diventa rapidamente ingestibile quando si dispone di un numero elevato di personalizzazioni da considerare. Prendere invece in considerazione la revisione del modello di dati per tenere traccia dei dati personalizzati per ogni tenant in una tabella dedicata.
- Modifiche manuali dello schema. Evitare di aggiornare manualmente lo schema del database, anche se si dispone solo di un singolo database condiviso. È facile perdere traccia degli aggiornamenti applicati e, se è necessario aumentare il numero di istanze in più database, è difficile identificare lo schema corretto da applicare. Creare invece una pipeline automatizzata per distribuire le modifiche dello schema e usarla in modo coerente. Tenere traccia della versione dello schema usata per ogni tenant in un database dedicato o in una tabella di ricerca.
- Dipendenze della versione. Evitare che l'applicazione assuma una dipendenza da una singola versione dello schema del database. Durante la scalabilità, potrebbe essere necessario applicare gli aggiornamenti dello schema in momenti diversi per tenant diversi. Assicurarsi invece che la versione dell'applicazione sia compatibile con le versioni precedenti con almeno una versione dello schema ed evitare aggiornamenti dello schema distruttivi.
Database
Esistono alcune funzionalità che possono essere utili per la multi-tenancy. Tuttavia, questi non sono disponibili in tutti i servizi di database. Valutare se sono necessari quando si decide di usare il servizio per lo scenario:
- La sicurezza a livello di riga può fornire l'isolamento della sicurezza per i dati di tenant specifici in un database multi-tenant condiviso. Questa funzionalità è disponibile in Azure SQL e Postgres Flex, ma non è disponibile in altri database, ad esempio MySQL o Azure Cosmos DB.
- Potrebbe essere necessaria la crittografia a livello di tenant per supportare i tenant che forniscono le proprie chiavi di crittografia per i dati. Questa funzionalità è disponibile in Sql di Azure come parte di Always Encrypted. Azure Cosmos DB fornisce chiavi gestite dal cliente a livello di account e supporta anche Always Encrypted.
- Il pool di risorse consente di condividere risorse e costi tra più database o contenitori. Questa funzionalità è disponibile nei pool elastici e nelle istanze gestite di SQL di Azure e nella velocità effettiva del database di Azure Cosmos DB, anche se ogni opzione presenta limitazioni da tenere presente.
- Il partizionamento orizzontale e il partizionamento hanno un supporto nativo più forte in alcuni servizi rispetto ad altri. Questa funzionalità è disponibile in Azure Cosmos DB, usando il partizionamento logico e fisico e in PostgreSQL Hyperscale. Anche se SQL di Azure non supporta il partizionamento orizzontale in modo nativo, fornisce strumenti di partizionamento orizzontale per supportare questo tipo di architettura.
Inoltre, quando si usano database relazionali o altri database basati su schema, considerare la posizione in cui deve essere attivato il processo di aggiornamento dello schema quando si gestisce una flotta di database. In una piccola area di database, è possibile prendere in considerazione l'uso di una pipeline di distribuzione per distribuire le modifiche dello schema. Man mano che si aumentano, potrebbe essere preferibile per il livello applicazione rilevare la versione dello schema per un database specifico e avviare il processo di aggiornamento.
Archiviazione file e BLOB
Si consideri l'approccio usato per isolare i dati all'interno di un account di archiviazione. Ad esempio, è possibile distribuire account di archiviazione separati per ogni tenant oppure condividere gli account di archiviazione e distribuire singoli contenitori. In alternativa, è possibile creare contenitori BLOB condivisi e quindi usare il percorso BLOB per separare i dati per ogni tenant. Prendere in considerazione i limiti e le quote delle sottoscrizioni di Azure e pianificare attentamente la crescita per garantire la scalabilità delle risorse di Azure per supportare le esigenze future.
Se si usano contenitori condivisi, pianificare attentamente la strategia di autenticazione e autorizzazione per assicurarsi che i tenant non possano accedere ai dati degli altri. Quando si fornisce ai client l'accesso alle risorse di Archiviazione di Azure, prendere in considerazione il modello Di passeparte.
Allocazione costi
Valutare come misurare il consumo e allocare i costi ai tenant per l'uso di servizi dati condivisi. Quando possibile, mirare a usare le metriche predefinite invece di calcolare le proprie. Tuttavia, con l'infrastruttura condivisa, diventa difficile suddividere i dati di telemetria per i singoli tenant e prendere in considerazione la misurazione personalizzata a livello di applicazione.
In generale, i servizi nativi del cloud, ad esempio Azure Cosmos DB e Archiviazione BLOB di Azure, offrono metriche più granulari per tenere traccia e modellare l'utilizzo per un tenant specifico. Ad esempio, Azure Cosmos DB fornisce la velocità effettiva utilizzata per ogni richiesta e risposta.
Contributori
Questo articolo viene gestito da Microsoft. Originariamente è stato scritto dai seguenti contributori.
Autore principale:
- John Downs | Principal Customer Engineer, FastTrack per Azure
Altri contributori:
- Paul Burpo | Principal Customer Engineer, FastTrack per Azure
- Daniel Scott-Raynsford | Partner Technology Strategist
- Arsen Vladimirintune | Principal Customer Engineer, FastTrack per Azure
Per visualizzare i profili LinkedIn non pubblici, accedere a LinkedIn.
Passaggi successivi
Per altre informazioni sulla multi-tenancy e su servizi di Azure specifici, vedere: