Convalida continua con test di carico di Azure e Azure Chaos Studio
Man mano che le applicazioni e i servizi nativi del cloud diventano più complessi, la distribuzione di modifiche e nuove versioni può risultare complessa. Le interruzioni sono spesso causate da distribuzioni o versioni difettose. Tuttavia , gli errori possono verificarsi anche dopo la distribuzione, quando un'applicazione inizia a ricevere traffico reale, soprattutto in carichi di lavoro complessi eseguiti in ambienti cloud multi-tenant altamente distribuiti e gestiti da più team di sviluppo. Questi ambienti richiedono misure di resilienza maggiori, ad esempio la logica di ripetizione dei tentativi e la scalabilità automatica, che in genere sono difficili da testare durante il processo di sviluppo.
Ecco perché la convalida continua in un ambiente simile all'ambiente di produzione è importante, in modo da poter trovare e risolvere eventuali problemi o bug il prima possibile nel ciclo di sviluppo. I team del carico di lavoro devono eseguire i test nelle prime fasi del processo di sviluppo (spostamento a sinistra) e consentire agli sviluppatori di eseguire test in un ambiente vicino all'ambiente di produzione.
I carichi di lavoro cruciali hanno requisiti di disponibilità elevata, con obiettivi di 3, 4 o 5 nove (rispettivamente 99,9%, 99,99% o 99,999%). È fondamentale implementare test automatizzati rigorosi per raggiungere questi obiettivi.
La convalida continua dipende da ogni carico di lavoro e dalle caratteristiche dell'architettura. Questo articolo fornisce una guida per la preparazione e l'integrazione di Test di carico di Azure e Azure Chaos Studio in un normale ciclo di sviluppo.
1 : definire i test in base alle soglie previste
Il test continuo è un processo complesso che richiede una preparazione corretta. Quali saranno i test e i risultati previsti devono essere chiari.
In PE:06 - Consigli per i test delle prestazioni e RE:08 - Consigli per progettare una strategia di test di affidabilità, Azure Well-Architected Framework consiglia di iniziare identificando scenari chiave, dipendenze, utilizzo previsto, disponibilità, prestazioni e obiettivi di scalabilità.
È quindi necessario definire un set di valori soglia misurabili per quantificare le prestazioni previste degli scenari chiave.
Suggerimento
Esempi di valori di soglia includono il numero previsto di accessi utente, le richieste al secondo per una determinata API e le operazioni al secondo per un processo in background.
È consigliabile usare i valori soglia per sviluppare un modello di integrità per l'applicazione, sia per il test che per il funzionamento dell'applicazione nell'ambiente di produzione.

Successivamente, usare i valori per definire un test di carico che genera traffico realistico per testare le prestazioni di base dell'applicazione, convalidare le operazioni di scalabilità previste e così via. Il traffico utente artificiale sostenuto è necessario in ambienti di pre-produzione, perché senza l'utilizzo è difficile rivelare problemi di runtime.
I test di carico assicurano che le modifiche apportate all'applicazione o all'infrastruttura non causino problemi e che il sistema soddisfi ancora i criteri di test e prestazioni previsti. Un'esecuzione di test non riuscita che non soddisfa i criteri di test indica che è necessario modificare la linea di base o che si è verificato un errore imprevisto.
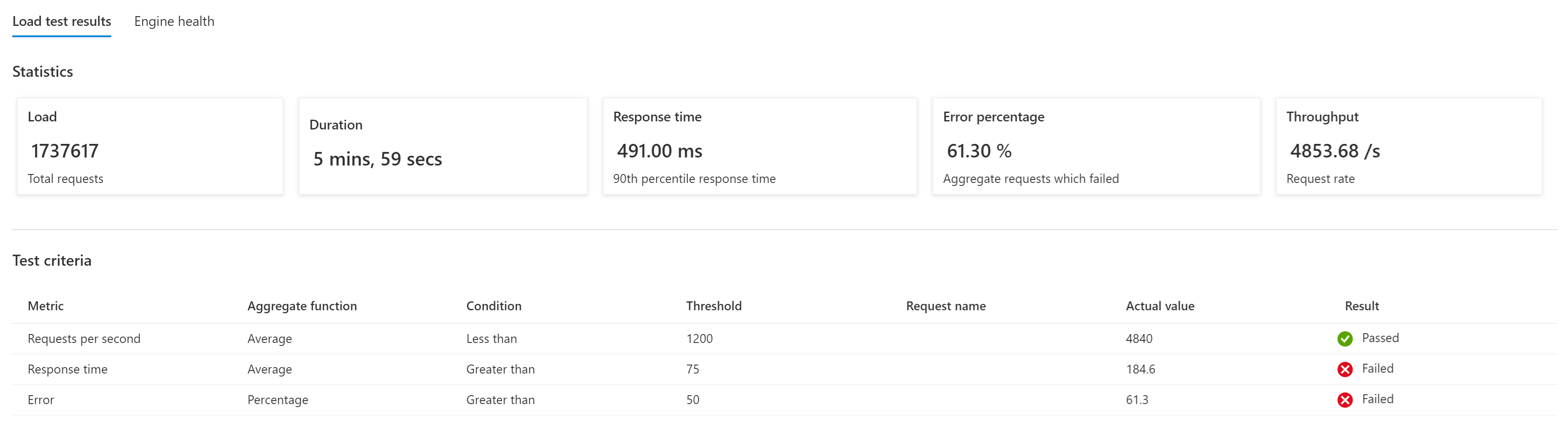
Anche se i test automatizzati rappresentano l'utilizzo quotidiano, è consigliabile eseguire regolarmente test di carico manuali per verificare la risposta del sistema a picchi imprevisti.
La seconda parte della convalida continua è l'iniezione di errori (chaos engineering). Questo passaggio verifica la resilienza di un sistema testando la modalità di risposta agli errori. Inoltre, tutte le misure di resilienza, ad esempio la logica di ripetizione dei tentativi, la scalabilità automatica e altre, funzionano come previsto.
2 - Implementare la convalida con test di carico e Chaos Studio
Microsoft Azure offre questi servizi gestiti per implementare test di carico e chaos engineering:
- Test di carico di Azure produce carico utente sintetico su applicazioni e servizi.
- Azure Chaos Studio offre la possibilità di eseguire la sperimentazione chaos, inserendo sistematicamente errori nei componenti e nell'infrastruttura dell'applicazione.
È possibile distribuire e configurare Sia Chaos Studio che Test di carico tramite il portale di Azure, ma, nel contesto della convalida continua, è più importante disporre di API per distribuire, configurare ed eseguire test in modo programmatico e automatizzato. L'uso di questi due strumenti consente di osservare in che modo il sistema reagisce ai problemi e la sua capacità di guarire automaticamente in risposta a errori dell'infrastruttura o dell'applicazione.
Il video seguente illustra un'implementazione combinata di Chaos e test di carico integrati in Azure DevOps:
Se si sviluppa un carico di lavoro mission-critical, sfruttare le architetture di riferimento, indicazioni dettagliate, implementazioni di esempio e artefatti di codice forniti come parte del progetto Mission-Critical di Azure e azure Well-Architected Framework.
L'implementazione Mission-Critical distribuisce il servizio Test di carico tramite Terraform e contiene una raccolta di script wrapper di PowerShell Core per interagire con il servizio tramite l'API. Questi script possono essere incorporati direttamente in una pipeline di distribuzione.
Un'opzione nell'implementazione di riferimento consiste nell'eseguire il test di carico direttamente dall'interno della pipeline end-to-end (e2e) usata per creare singoli ambienti di sviluppo (specifici del ramo):

La pipeline eseguirà automaticamente un test di carico, con o senza esperimenti chaos (a seconda della selezione) in parallelo:

Nota
L'esecuzione di esperimenti chaos durante un test di carico può comportare una latenza più elevata, tempi di risposta più elevati e tassi di errore temporaneamente aumentati. Si noteranno numeri più elevati fino al completamento di un'operazione di scalabilità orizzontale o al completamento di un failover, rispetto a un'esecuzione senza esperimenti chaos.

A seconda che il test chaos sia abilitato e la scelta degli esperimenti, le definizioni di base possono variare, perché la tolleranza per gli errori può essere diversa nello stato "normale" e "chaos".
3 – Regolare le soglie e stabilire una linea di base
Infine, modificare le soglie di test di carico per le esecuzioni regolari per verificare che l'applicazione (ancora) fornisca le prestazioni previste e non generi errori. Avere una baseline separata per il test chaos che tollera i picchi previsti nelle percentuali di errore e le prestazioni temporanee ridotte. Questa attività è continua e deve essere ripetuta regolarmente. Ad esempio, dopo aver introdotto nuove funzionalità, modificando gli SKU del servizio e altri.
Il servizio Test di carico di Azure offre una funzionalità predefinita denominata criteri di test che consente di specificare determinati criteri che un test deve superare. Questa funzionalità può essere usata per implementare linee di base diverse.

La funzionalità è disponibile tramite il portale di Azure e tramite l'API di test di carico e gli script wrapper sviluppati come parte di Azure Mission-critical offrono un'opzione per distribuire una definizione di baseline basata su JSON.
È consigliabile integrare questi test direttamente nelle pipeline CI/CD ed eseguirli durante le prime fasi dello sviluppo di funzionalità. Per un esempio, vedere l'implementazione di esempio nell'implementazione di riferimento mission-critical di Azure.
In sintesi, l'errore è inevitabile in qualsiasi sistema distribuito complesso e la soluzione deve quindi essere progettata (e testata) per gestire gli errori. Le linee guida e le implementazioni di riferimento per carichi di lavoro cruciali di Well-Architected Framework consentono di progettare e gestire applicazioni altamente affidabili per derivare il valore massimo dal cloud Microsoft.
Passaggio successivo
Esaminare l'area di progettazione di distribuzione e test per carichi di lavoro cruciali.