Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La modellazione dell'integrità e l'osservabilità sono concetti essenziali per ottimizzare l'affidabilità, che si concentra sulla strumentazione e il monitoraggio robusti e contestualizzati. Questi concetti forniscono informazioni critiche sull'integrità delle applicazioni, promuovendo l'identificazione e la risoluzione rapida dei problemi.
La maggior parte delle applicazioni cruciali è significativa in termini di scalabilità e complessità e quindi genera volumi elevati di dati operativi, che rende difficile valutare e determinare un'azione operativa ottimale. La modellazione dell'integrità si impegna infine a ottimizzare l'osservabilità aumentando i log di monitoraggio non elaborati e le metriche con requisiti aziendali chiave per quantificare l'integrità delle applicazioni, guidando la valutazione automatizzata degli stati di integrità per ottenere operazioni coerenti e veloci.
Questa area di progettazione si concentra sul processo per definire un modello di integrità affidabile, mappando gli stati di integrità delle applicazioni quantificati tramite costrutti osservabili e operativi per ottenere la maturità operativa.
Importante
Questo articolo fa parte della serie di carichi di lavoro cruciali di Azure Well-Architected . Se non si ha familiarità con questa serie, è consigliabile iniziare con un carico di lavoro mission-critical?
Esistono tre livelli principali di maturità operativa quando si tenta di massimizzare l'affidabilità.
- Rilevare e rispondere ai problemi quando si verificano.
- Diagnosticare i problemi che si verificano o si sono già verificati.
- Prevedere e prevenire i problemi prima che si verifichino.
Video: Definire un modello di integrità per il carico di lavoro critico
Integrità dell'applicazione a livelli
Per creare un modello di integrità, definire innanzitutto l'integrità dell'applicazione nel contesto dei requisiti aziendali chiave quantificando gli stati "integri" e "non integri" in un formato livello e misurabile. Quindi, per ogni componente dell'applicazione, perfezionare la definizione nel contesto di uno stato di esecuzione costante e aggregato in base ai flussi utente dell'applicazione. Sovraimpose con requisiti aziendali non funzionali chiave per prestazioni e disponibilità. Infine, aggregare gli stati di integrità per ogni singolo flusso utente per formare una rappresentazione accettabile dell'integrità complessiva dell'applicazione. Dopo aver stabilito, queste definizioni di integrità a livelli devono essere usate per informare le metriche di monitoraggio critiche in tutti i componenti di sistema e convalidare la composizione del sottosistema operativo.
Importante
Quando si definiscono gli stati "non integri", rappresentano per tutti i livelli dell'applicazione. È importante distinguere tra stati di errore temporanei e non temporanei per qualificare la riduzione del servizio rispetto all'indisponibilità.
Considerazioni relative alla progettazione
Il processo di integrità della modellazione è un'attività di progettazione superiore che inizia con un esercizio architettonico per definire tutti i flussi utente e mappare le dipendenze tra componenti funzionali e logici, quindi mapping implicito delle dipendenze tra le risorse di Azure.
Un modello di integrità dipende completamente dal contesto della soluzione che rappresenta e pertanto non può essere risolto "out-of-the-box" perché "una dimensione non adatta a tutti".
- Le applicazioni differiscono nella composizione e nelle dipendenze
- Le metriche e le soglie delle metriche per le risorse devono essere ottimizzate anche in termini di valori che rappresentano stati integri e non integri, che sono fortemente influenzati dalla funzionalità dell'applicazione e dai requisiti non funzionali inclusi.
Un modello di integrità a livelli consente di tracciare l'integrità dell'applicazione alle dipendenze di livello inferiore, che consente di causare rapidamente la riduzione del servizio.
Per acquisire gli stati di integrità per un singolo componente, è necessario comprendere le caratteristiche operative distinte del componente in uno stato costante che riflette il carico di produzione. Il test delle prestazioni è quindi una funzionalità chiave per definire e valutare continuamente l'integrità dell'applicazione.
Gli errori all'interno di una soluzione cloud potrebbero non verificarsi in isolamento. Un'interruzione in un singolo componente può causare diverse funzionalità o componenti aggiuntivi che non sono disponibili.
- Tali errori potrebbero non essere immediatamente osservabili.
Suggerimenti per la progettazione
Definire un modello di integrità misurabile come priorità per garantire una chiara comprensione operativa dell'intera applicazione.
- Il modello di integrità deve essere stratiato e riflettente della struttura dell'applicazione.
- Il livello di base deve considerare singoli componenti dell'applicazione, ad esempio le risorse di Azure.
- I componenti fondamentali devono essere aggregati insieme ai requisiti chiave non funzionali per creare una lente contestualizzata aziendale nell'integrità dei flussi di sistema.
- I flussi di sistema devono essere aggregati con pesi appropriati in base alla criticità aziendale per creare una definizione significativa dell'integrità complessiva dell'applicazione. I flussi utente con priorità finanziaria o relativi ai clienti devono essere classificati in ordine di priorità.
- Ogni livello del modello di integrità deve acquisire gli stati "integri" e "non integri".
- Assicurarsi che il modello di calore possa distinguere tra stati temporanei e non temporanei non integri per isolare la riduzione del servizio dalla non disponibilità.
Rappresentare gli stati di integrità usando un punteggio di integrità granulare per ogni componente applicazione distinto e ogni flusso utente aggregando i punteggi di integrità per i componenti dipendenti mappati, considerando i requisiti chiave non funzionali come coefficienti.
- Il punteggio di integrità per un flusso utente deve essere rappresentato dal punteggio più basso in tutti i componenti mappati, fattorendo in modo relativo rispetto ai requisiti non funzionali per il flusso utente.
- Il modello usato per calcolare i punteggi di integrità deve riflettere in modo coerente l'integrità operativa e, in caso contrario, il modello deve essere modificato e ridistribuito per riflettere nuovi apprendimento.
- Definire le soglie dei punteggi di integrità per riflettere lo stato di integrità.
Il punteggio di integrità deve essere calcolato automaticamente in base alle metriche sottostanti, che possono essere visualizzate tramite modelli di osservabilità e agire tramite procedure operative automatizzate.
- Il punteggio di integrità deve diventare fondamentale per la soluzione di monitoraggio, in modo che i team operativi non debbano più interpretare e mappare i dati operativi all'integrità dell'applicazione.
Usare il modello di integrità per calcolare il raggiungimento del livello di disponibilità (SLO) anziché la disponibilità non elaborata, assicurando che la demarcazione tra la riduzione del servizio e l'indisponibilità vengano riflesse come contratti di servizio separati.
Usare il modello di integrità nelle pipeline CI/CD e i cicli di test per verificare che l'integrità dell'applicazione venga mantenuta dopo gli aggiornamenti del codice e della configurazione.
- Il modello di integrità deve essere usato per osservare e convalidare l'integrità durante i test di carico e i test di caos come parte dei processi CI/CD.
La creazione e la gestione di un modello di integrità è un processo iterativo e gli investimenti di ingegneria devono essere allineati per favorire miglioramenti continui.
- Definire un processo per valutare e ottimizzare continuamente l'accuratezza del modello e valutare l'investimento in modelli di Machine Learning per eseguire ulteriormente il training del modello.
Esempio - Modello di integrità a livelli
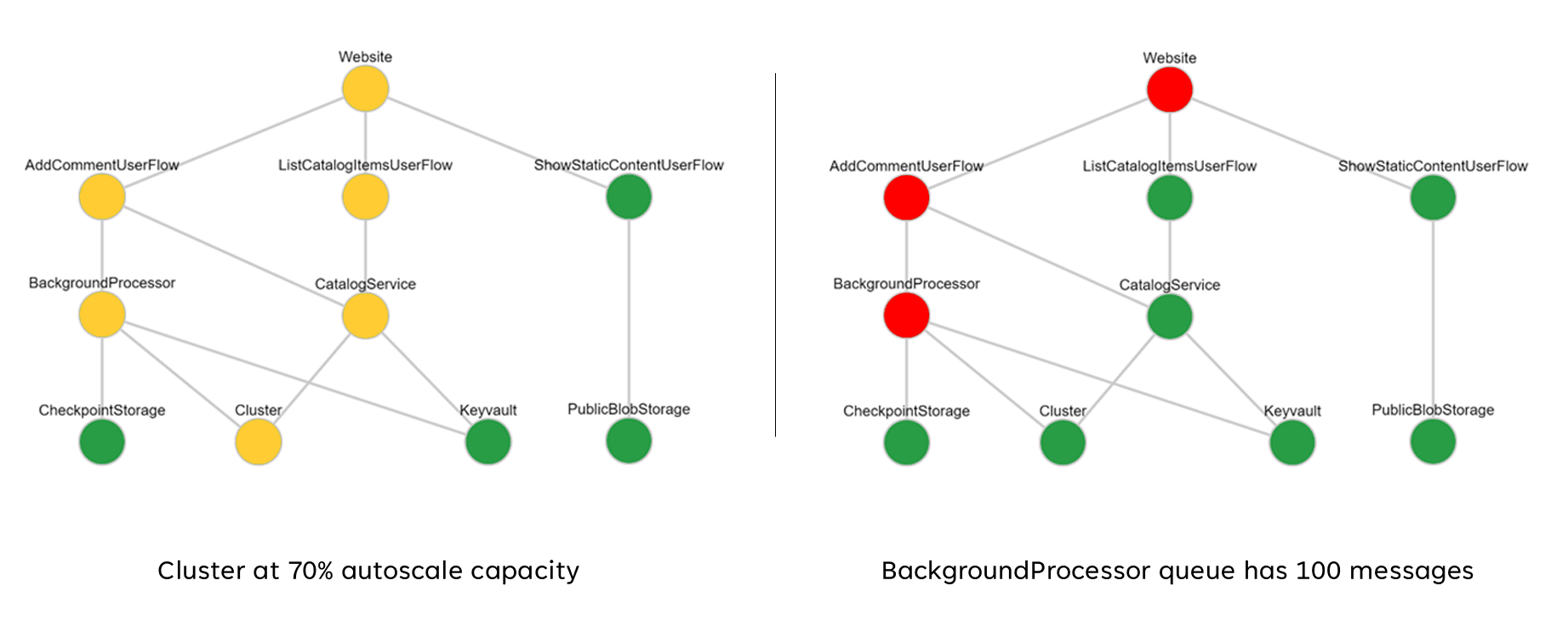
Si tratta di una rappresentazione semplificata di un modello di integrità dell'applicazione a livelli per scopi illustrativi. Un modello di integrità completo e contestualizzato viene fornito nelle implementazioni di riferimento Mission-Critical:
Quando si implementa un modello di integrità, è importante definire l'integrità dei singoli componenti tramite l'aggregazione e l'interpretazione delle metriche chiave a livello di risorsa. Un esempio di modalità di utilizzo delle metriche delle risorse è l'immagine seguente:

Questa definizione di integrità può essere successivamente rappresentata da una query KQL, come illustrato dalla query di esempio seguente che aggrega InsightsMetrics (Informazioni dettagliate sui contenitori) e AzureMetrics (impostazione di diagnostica per il cluster del servizio Azure Kubernetes) e confronta (inner join) rispetto alle soglie di integrità modellate.
// ClusterHealthStatus
let Thresholds=datatable(MetricName: string, YellowThreshold: double, RedThreshold: double) [
// Disk Usage:
"used_percent", 50, 80,
// Average node cpu usage %:
"node_cpu_usage_percentage", 60, 90,
// Average node disk usage %:
"node_disk_usage_percentage", 60, 80,
// Average node memory usage %:
"node_memory_rss_percentage", 60, 80
];
InsightsMetrics
| summarize arg_max(TimeGenerated, *) by Computer, Name
| project TimeGenerated,Computer, Namespace, MetricName = Name, Value=Val
| extend NodeName = extract("([a-z0-9-]*)(-)([a-z0-9]*)$", 3, Computer)
| union (
AzureMetrics
| extend ResourceType = extract("(PROVIDERS/MICROSOFT.)([A-Z]*/[A-Z]*)", 2, ResourceId)
| where ResourceType == "CONTAINERSERVICE/MANAGEDCLUSTERS"
| summarize arg_max(TimeGenerated, *) by MetricName
| project TimeGenerated, MetricName, Namespace = "AzureMetrics", Value=Average
)
| lookup kind=inner Thresholds on MetricName
| extend IsYellow = iff(Value > YellowThreshold and Value < RedThreshold, 1, 0)
| extend IsRed = iff(Value > RedThreshold, 1, 0)
| project NodeName, MetricName, Value, YellowThreshold, IsYellow, RedThreshold, IsRed
L'output della tabella risultante può essere trasformato successivamente in un punteggio di integrità per un'aggregazione più semplice a livelli più elevati del modello di integrità.
// ClusterHealthScore
ClusterHealthStatus
| summarize YellowScore = max(IsYellow), RedScore = max(IsRed)
| extend HealthScore = 1-(YellowScore*0.25)-(RedScore*0.5)
Questi punteggi aggregati possono essere successivamente rappresentati come grafico di dipendenza usando strumenti di visualizzazione come Grafana per illustrare il modello di integrità.
Questa immagine mostra un modello di integrità a livelli di esempio dall'implementazione di riferimento online di Azure Mission-Critical e illustra come una modifica dello stato di integrità per un componente fondamentale può avere un impatto a catena sui flussi utente e sull'integrità complessiva dell'applicazione (i valori di esempio corrispondono alla tabella nell'immagine precedente).
Demo video: Demo di monitoraggio e modellazione dell'integrità
Sink dati unificato per l'analisi correlata
Molti set di dati operativi devono essere raccolti da tutti i componenti di sistema per rappresentare in modo accurato un modello di calore definito, considerando i log e le metriche da entrambi i componenti dell'applicazione e le risorse di Azure sottostanti. Questa vasta quantità di dati deve essere archiviata in un formato che consente l'interpretazione quasi in tempo reale per facilitare un'azione operativa rapida. Inoltre, la correlazione tra tutti i set di dati inclusi è necessaria per garantire che l'analisi efficace non sia innessa, consentendo la rappresentazione a livelli dell'integrità.
È necessario un sink di dati unificato per garantire che tutti i dati operativi vengano archiviati rapidamente e resi disponibili per l'analisi correlata per creare una rappresentazione dell'integrità dell'applicazione in un unico riquadro. Azure offre diverse tecnologie operative sotto l'ambito di Monitoraggio di Azure e l'area di lavoro Log Analytics funge da sink di dati nativo di Azure principale per archiviare e analizzare i dati operativi.
 di
di
Considerazioni relative alla progettazione
Monitoraggio di Azure
Monitoraggio di Azure è abilitato per impostazione predefinita per tutte le sottoscrizioni di Azure, ma i log di Monitoraggio di Azure (area di lavoro Log Analytics) e le risorse di Application Insights devono essere distribuiti e configurati per incorporare la raccolta dati e le funzionalità di query.
Monitoraggio di Azure supporta tre tipi di dati di osservabilità: log, metriche e tracce distribuite.
- I log vengono archiviati nelle aree di lavoro Log Analytics, basate su Azure Esplora dati. Le query di log vengono archiviate in Query Pack che possono essere condivise tra sottoscrizioni e vengono usate per guidare i componenti di osservabilità, ad esempio dashboard, cartelle di lavoro o altri strumenti di creazione di report e visualizzazione.
- Le metriche vengono archiviate in un database della serie temporale interna. Per la maggior parte delle risorse di Azure, le metriche vengono raccolte automaticamente e mantenute per 93 giorni. I dati delle metriche possono anche essere inviati all'area di lavoro Log Analytics usando un'impostazione di diagnostica per la risorsa.
Tutte le risorse di Azure espongono log e metriche, ma le risorse devono essere configurate in modo appropriato per instradare i dati di diagnostica al sink di dati desiderato.
Suggerimento
Azure offre vari criteri predefiniti che possono essere applicati per garantire che le risorse distribuite siano configurate per inviare log e metriche a un'area di lavoro Log Analytics.
Non è raro che i controlli normativi richiedano che i dati operativi rimangano all'interno di aree geografiche o paesi/aree geografiche di origine. I requisiti normativi possono stabilire la conservazione dei tipi di dati critici per un periodo di tempo esteso. Ad esempio, nel settore bancario regolamentato, i dati di controllo devono essere conservati per almeno sette anni.
Diversi tipi di dati operativi possono richiedere periodi di conservazione diversi. Ad esempio, i log di sicurezza possono essere conservati per un periodo lungo, mentre i dati sulle prestazioni non richiedono la conservazione a lungo termine al di fuori del contesto di IOps.
I dati possono essere archiviati o esportati dalle aree di lavoro Log Analytics per scopi di conservazione e/o controllo a lungo termine.
I cluster dedicati offrono un'opzione di distribuzione che consente di zone di disponibilità per la protezione da errori di zona nelle aree di Azure supportate. I cluster dedicati richiedono un impegno minimo di inserimento dei dati giornalieri.
Le aree di lavoro di Log Analytics vengono distribuite in un'area di Azure specificata.
Per proteggere la perdita di dati da non disponibilità di un'area di lavoro Log Analytics, è possibile configurare le risorse con più impostazioni di diagnostica. Ogni impostazione di diagnostica può inviare metriche e log a un'area di lavoro Log Analytics separata.
- I dati inviati a ogni area di lavoro di Log Analytics aggiuntiva comportano costi aggiuntivi.
- L'area di lavoro Log Analytics ridondante può essere distribuita nella stessa area di Azure o in aree di Azure separate per una ridondanza a livello di area aggiuntiva.
- L'invio di log e metriche da una risorsa di Azure a un'area di lavoro Log Analytics in un'area diversa comporta costi di uscita dei dati tra aree.
- Alcune risorse di Azure richiedono un'area di lavoro Log Analytics all'interno della stessa area della risorsa stessa.
- Per altre opzioni di disponibilità per l'area di lavoro Log Analytics, vedere Procedure consigliate per i log di Monitoraggio di Azure .
I dati dell'area di lavoro di Log Analytics possono essere esportati in Archiviazione di Azure o Hub eventi di Azure in base a una modalità continua, pianificata o una sola volta.
- L'esportazione dei dati consente l'archiviazione dei dati a lungo termine e protegge dalla possibile perdita di dati operativi a causa della mancata disponibilità.
- Le destinazioni di esportazione disponibili sono Archiviazione di Azure o Hub eventi di Azure. Archiviazione di Azure può essere configurata per diversi livelli di ridondanza , tra cui zonale o area. L'esportazione dei dati in Archiviazione di Azure archivia i dati all'interno di file json.
- Le destinazioni di esportazione dei dati devono trovarsi nella stessa area di Azure dell'area di lavoro Log Analytics. Destinazione di esportazione dei dati dell'hub eventi nella stessa area dell'area di lavoro Log Analytics. Hub eventi di Azure ripristino di emergenza geografico non è applicabile per questo scenario.
- Esistono diverse limitazioni per l'esportazione dei dati. Per l'esportazione dei dati sono supportate solo tabelle specifiche nell'area di lavoro.
- L'archiviazione può essere usata per archiviare i dati in un'area di lavoro Log Analytics per la conservazione a lungo termine a un costo ridotto senza esportarlo.
I log di Monitoraggio di Azure hanno limiti di limitazione delle query utente, che possono essere visualizzati come disponibilità ridotta ai client, ad esempio dashboard di osservabilità.
- Cinque query simultanee per utente: se cinque query sono già in esecuzione, le query aggiuntive vengono inserite in una coda di concorrenza per utente fino al termine di una query in esecuzione.
- Tempo nella coda di concorrenza: se una query si trova nella coda di concorrenza per oltre tre minuti, verrà terminata e verrà restituito un codice di errore 429.
- Limite di profondità della coda di concorrenza: la coda di concorrenza è limitata a 200 query e le query aggiuntive verranno rifiutate con un codice di errore 429.
- Limite di frequenza delle query: è previsto un limite per utente di 200 query per 30 secondi in tutte le aree di lavoro.
I Pacchetti di query sono risorse di Azure Resource Manager, che possono essere usate per proteggere e ripristinare le query di log se l'area di lavoro Log Analytics non è disponibile.
- I Pacchetti di query contengono query come JSON e possono essere archiviati esternamente ad Azure simile ad altri asset di infrastruttura come codice.
- Distribuiscibile tramite l'API REST di Microsoft.Insights.
- Se un'area di lavoro Log Analytics deve essere ricreata, è possibile ridistribuire il pacchetto di query da una definizione archiviata esternamente.
- I Pacchetti di query contengono query come JSON e possono essere archiviati esternamente ad Azure simile ad altri asset di infrastruttura come codice.
Application Insights può essere distribuito in un modello di distribuzione basato sull'area di lavoro, supportato da un'area di lavoro Log Analytics in cui vengono archiviati tutti i dati.
Il campionamento può essere abilitato all'interno di Application Insights per ridurre la quantità di dati inviati e ottimizzare i costi di inserimento dei dati.
Tutti i dati raccolti da Monitoraggio di Azure, tra cui Application Insights, vengono addebitati in base al volume di dati inseriti e alla durata di conservazione dei dati.
- I dati inseriti in un'area di lavoro Log Analytics possono essere conservati senza costi aggiuntivi fino ai primi 31 giorni (90 giorni se Sentinel è abilitato)
- I dati inseriti in un'area di lavoro di Application Insights vengono conservati per i primi 90 giorni senza costi aggiuntivi.
Il modello tariffario del piano di impegno di Log Analytics offre un costo ridotto e un approccio prevedibile agli addebiti di inserimento dei dati.
- Qualsiasi utilizzo superiore al livello di prenotazione viene addebitato allo stesso prezzo del livello corrente.
Log Analytics, Application Insights e Azure Esplora dati usare la Linguaggio di query Kusto (KQL).
Le query di Log Analytics vengono salvate come funzioni nell'area di lavoro Log Analytics (
savedSearches).
Suggerimenti per la progettazione
Usare l'area di lavoro Log Analytics come sink di dati unificato per fornire un 'singolo riquadro' in tutti i set di dati operativi.
- Decentralizzare le aree di lavoro di Log Analytics in tutte le aree di distribuzione usate. Ogni area di Azure con una distribuzione dell'applicazione deve considerare un'area di lavoro Log Analytics per raccogliere tutti i dati operativi provenienti da tale area. Tutte le risorse globali devono usare un'area di lavoro Log Analytics dedicata separata, che deve essere distribuita all'interno di un'area di distribuzione primaria.
- L'invio di tutti i dati operativi a un'unica area di lavoro Log Analytics creerebbe un singolo punto di errore.
- I requisiti per la residenza dei dati potrebbero impedire l'uscita dei dati dall'area di origine e le aree di lavoro federate risolveranno per impostazione predefinita questo requisito.
- È previsto un costo significativo di uscita associato al trasferimento di log e metriche tra aree.
- Tutti i francobolli di distribuzione all'interno della stessa area possono usare la stessa area di lavoro Log Analytics a livello di area.
- Decentralizzare le aree di lavoro di Log Analytics in tutte le aree di distribuzione usate. Ogni area di Azure con una distribuzione dell'applicazione deve considerare un'area di lavoro Log Analytics per raccogliere tutti i dati operativi provenienti da tale area. Tutte le risorse globali devono usare un'area di lavoro Log Analytics dedicata separata, che deve essere distribuita all'interno di un'area di distribuzione primaria.
È consigliabile configurare le risorse con più impostazioni di diagnostica che puntano a diverse aree di lavoro di Log Analytics per proteggere contro l'indisponibilità di Monitoraggio di Azure per le applicazioni con un minor numero di stamp di distribuzione a livello di area.
Usare Application Insights come strumento di monitoraggio delle prestazioni delle applicazioni coerente in tutti i componenti dell'applicazione per raccogliere i log, le metriche e le tracce delle applicazioni.
- Distribuire Application Insights in una configurazione basata sull'area di lavoro per garantire che ogni area di lavoro Log Analytics a livello di area contenga log e metriche sia dai componenti dell'applicazione che dalle risorse di Azure sottostanti.
Usare query tra aree di lavoro per mantenere un 'singolo riquadro' unificato tra le diverse aree di lavoro.
Usare i query pack per proteggere le query di log in caso di indisponibilità dell'area di lavoro.
- Archiviare i query Pack all'interno del repository git dell'applicazione come asset di codice dell'infrastruttura.
Tutte le aree di lavoro Log Analytics devono essere considerate come risorse a esecuzione prolungata con un ciclo di vita diverso alle risorse dell'applicazione all'interno di un timbro di distribuzione a livello di area.
Esportare i dati operativi critici dall'area di lavoro Log Analytics per la conservazione e l'analisi a lungo termine per facilitare l'intelligenza artificiale e l'analisi avanzata per perfezionare il modello di integrità sottostante e informare l'azione predittiva.
Valutare attentamente quale archivio dati deve essere usato per la conservazione a lungo termine; non tutti i dati devono essere archiviati in un archivio dati frequente e queryabile.
- È consigliabile usare Archiviazione di Azure in una configurazione grS per l'archiviazione dei dati operativi a lungo termine.
- Usare la funzionalità di esportazione dell'area di lavoro Log Analytics per esportare tutte le origini dati disponibili in Archiviazione di Azure.
- È consigliabile usare Archiviazione di Azure in una configurazione grS per l'archiviazione dei dati operativi a lungo termine.
Selezionare i periodi di conservazione appropriati per i tipi di dati operativi all'interno di Log Analytics, configurando periodi di conservazione più lunghi all'interno dell'area di lavoro in cui esistono i requisiti di osservabilità a caldo.
Usare Criteri di Azure per garantire che tutte le risorse regionali instradano i dati operativi all'area di lavoro Log Analytics corretta.
Nota
Quando si distribuisce in un'area di destinazione di Azure, se è previsto un requisito per l'archiviazione centralizzata dei dati operativi, è possibile creare un fork dei dati in modo che venga inserito sia negli strumenti centralizzati che nelle aree di lavoro di Log Analytics dedicate all'applicazione. In alternativa, esporre l'accesso alle aree di lavoro Log Analytics dell'applicazione in modo che i team centrali possano eseguire query sui dati dell'applicazione. In definitiva, è fondamentale che i dati operativi provenienti dalla soluzione siano disponibili nelle aree di lavoro di Log Analytics dedicate all'applicazione.
Se è necessaria l'integrazione SIEM, non inviare voci di log non elaborate, ma invece inviare avvisi critici.
Configurare solo il campionamento all'interno di Application Insights se è necessario ottimizzare le prestazioni o se non il campionamento diventa proibitivo.
- Il campionamento eccessivo può causare segnali operativi mancanti o imprecisi.
Usare gli ID di correlazione per tutti gli eventi di traccia e registrare i messaggi per collegarli a una determinata richiesta.
- Restituire gli ID di correlazione al chiamante per tutte le chiamate non solo non riuscite.
Assicurarsi che il codice dell'applicazione incorpora la strumentazione e la registrazione appropriati per informare il modello di integrità e facilitare la risoluzione dei problemi successivi o l'analisi della causa radice quando necessario.
- Il codice dell'applicazione deve usare Application Insights per facilitare la traccia distribuita, fornendo al chiamante un messaggio di errore completo che include un ID di correlazione quando si verifica un errore.
Usare la registrazione strutturata per tutti i messaggi di log.
Aggiungere probe di integrità significativi a tutti i componenti dell'applicazione.
- Quando si usa il servizio Azure Kubernetes, configurare gli endpoint di integrità per ogni distribuzione (pod) in modo che Kubernetes possa determinare correttamente quando un pod è integro o non integro.
- Quando si usa Servizio app di Azure, configurare i controlli di integrità in modo che le operazioni di scalabilità orizzontale non causano errori inviando il traffico alle istanze non ancora pronte e assicurandosi che le istanze non integre vengano riciclate rapidamente.
Se l'applicazione viene sottoscritta a Microsoft Mission-Critical Supporto, valutare la possibilità di esporre i probe di integrità chiave a supporto tecnico Microsoft, in modo che l'integrità dell'applicazione possa essere modellata in modo più accurato supporto tecnico Microsoft.
Registrare le richieste di controllo integrità riuscite, a meno che non sia possibile tollerare volumi di dati elevati nel contesto delle prestazioni dell'applicazione, poiché forniscono informazioni aggiuntive per la modellazione analitica.
Non configurare aree di lavoro Log Analytics di produzione per applicare un limite giornaliero, che limita l'inserimento giornaliero dei dati operativi, poiché ciò può causare la perdita di dati operativi critici.
- In ambienti inferiori, ad esempio sviluppo e test, un limite giornaliero può essere considerato come un meccanismo facoltativo di risparmio dei costi.
I dati operativi forniti soddisfano la soglia minima di inserimento dei dati operativi, configurare le aree di lavoro Log Analytics per usare i prezzi basati sul piano di impegno per aumentare le efficienza dei costi rispetto al modello di prezzi "con pagamento in base al consumo".
È consigliabile archiviare le query di Log Analytics usando il controllo del codice sorgente e usare l'automazione CI/CD per distribuirle nelle istanze dell'area di lavoro Log Analytics pertinenti.
Visualizzazione
La rappresentazione visiva del modello di integrità con dati operativi critici è essenziale per ottenere operazioni efficaci e ottimizzare l'affidabilità. I dashboard devono essere usati in definitiva per fornire informazioni dettagliate quasi in tempo reale sull'integrità delle applicazioni per i team DevOps, semplificando la diagnosi rapida delle deviazioni dallo stato stabile.
Microsoft offre diverse tecnologie di visualizzazione dei dati, tra cui Dashboard di Azure, Power BI e Azure Managed Grafana (attualmente in anteprima). I dashboard di Azure sono posizionati per fornire una soluzione di visualizzazione predefinita integrata per i dati operativi all'interno di Monitoraggio di Azure. Ha quindi un ruolo fondamentale da svolgere nella rappresentazione visiva dei dati operativi e dell'integrità dell'applicazione per un carico di lavoro critico. Tuttavia, esistono diverse limitazioni in termini di posizionamento dei dashboard di Azure come piattaforma di osservabilità olistica e, di conseguenza, deve essere considerata l'uso supplementare di soluzioni di osservabilità leader del mercato, ad esempio Grafana, che viene anche fornita come soluzione gestita all'interno di Azure.
Questa sezione si concentra sull'uso di Dashboard di Azure e Grafana per creare un'esperienza di dashboard affidabile in grado di fornire lenti tecniche e aziendali nell'integrità dell'applicazione, abilitando i team DevOps e l'operazione efficace. Il dashboard affidabile è essenziale per diagnosticare i problemi già verificatisi e supportare i team operativi nel rilevare e rispondere ai problemi quando si verificano.
Considerazioni relative alla progettazione
Quando si visualizza il modello di integrità usando query di log, si noti che sono presenti limiti di Log Analytics sulle query simultanee e in coda, nonché sulla frequenza di query complessiva, con query successive accodate e limitate.
Le query per recuperare i dati operativi usati per calcolare e rappresentare i punteggi di integrità possono essere scritti ed eseguiti in Log Analytics o in Azure Esplora dati.
- Le query di esempio sono disponibili qui.
Log Analytics impone diversi limiti di query, che devono essere progettati per la progettazione di dashboard operativi.
La visualizzazione delle metriche delle risorse non elaborate, ad esempio l'utilizzo della CPU o la velocità effettiva di rete, richiede una valutazione manuale da parte dei team operativi per determinare gli effetti sullo stato di integrità e ciò può essere difficile durante un evento imprevisto attivo.
Se più utenti usano dashboard all'interno di uno strumento come Grafana, il numero di query inviate a Log Analytics moltiplica rapidamente.
- Raggiungere il limite di query simultaneo in Log Analytics accoderà le query successive, rendendo l'esperienza del dashboard "lenta".
Consigli sulla progettazione
- Raccogliere e presentare output query da tutte le aree di lavoro Log Analytics a livello di area di lavoro e dall'area di lavoro log analytics globale per creare una visualizzazione unificata dell'integrità dell'applicazione.
Nota
Se si distribuisce in un'area di destinazione di Azure, è consigliabile eseguire query sull'area di lavoro Log Analytics della piattaforma centrale se esistono dipendenze chiave sulle risorse della piattaforma, ad esempio ExpressRoute per la comunicazione locale.
Un modello "luce traffico" deve essere usato per rappresentare visivamente gli stati "integri" e "non integri", con verde usato per illustrare quando i requisiti chiave non funzionali sono completamente soddisfatti e le risorse vengono usate in modo ottimale. Usare "Verde", "Amber e "Rosso" per rappresentare gli stati "Integri", "Degradati" e "Non disponibili".
Usare dashboard di Azure per creare lenti operative per le risorse globali e i stamp di distribuzione a livello di area, che rappresentano metriche chiave, ad esempio il conteggio delle richieste per Frontdoor di Azure, la latenza lato server per Azure Cosmos DB, i messaggi in ingresso/in uscita per Hub eventi e lo stato di utilizzo o distribuzione della CPU per il servizio Azure Kubernetes. I dashboard devono essere personalizzati per guidare l'efficacia operativa, infusendo gli apprendimento dagli scenari di errore per garantire che i team DevOps abbiano visibilità diretta sulle metriche chiave.
Se i dashboard di Azure non possono essere usati per rappresentare in modo accurato il modello di integrità e i requisiti aziendali necessari, è consigliabile considerare Grafana come soluzione di visualizzazione alternativa, fornendo funzionalità leader del mercato e un ampio ecosistema di plug-source open source. Valutare l'offerta di anteprima gestita di Grafana per evitare le complessità operative della gestione dell'infrastruttura Grafana.
Quando si distribuisce Grafana self-hosted, usare una progettazione distribuita a disponibilità elevata e geografica per garantire che i dashboard operativi critici possano essere resilienti agli errori della piattaforma a livello di area e agli scenari di errore a catena.
Separare lo stato di configurazione in un archivio dati esterno, ad esempio Database di Azure per Postgres o MySQL, per garantire che i nodi dell'applicazione Grafana rimangano senza stato.
- Configurare la replica del database tra aree di distribuzione.
Distribuire nodi Grafana in Servizi app in una configurazione a disponibilità elevata in un'area, usando distribuzioni basate su contenitori.
- Distribuire servizio app istanze tra aree di distribuzione considerate.
Servizi app offre una piattaforma contenitore a basso attrito, ideale per scenari a bassa scala, ad esempio dashboard operativi, e isolare Grafana dal servizio Azure Kubernetes offre una chiara separazione delle preoccupazioni tra la piattaforma applicazione primaria e le rappresentazioni operative per tale piattaforma. Per altre raccomandazioni di configurazione, vedere l'area deign della piattaforma applicazione.
Usare Archiviazione di Azure in una configurazione grS per ospitare e gestire oggetti visivi e plug-in personalizzati.
Distribuire i componenti del servizio app e della replica di database Grafana in almeno due aree di distribuzione e prendere in considerazione l'uso di un modello in cui Grafana viene distribuito in tutte le aree di distribuzione considerate.
Per gli scenari destinati a un >= 99,99% SLO, Grafana deve essere distribuito entro almeno 3 aree di distribuzione per ottimizzare l'affidabilità complessiva per i dashboard operativi chiave.
Attenuare i limiti delle query di Log Analytics aggregando le query in un numero singolo o ridotto di query, ad esempio usando l'operatore "union" KQL e impostando una frequenza di aggiornamento appropriata nel dashboard.
- Una frequenza di aggiornamento massima appropriata dipenderà dal numero e dalla complessità delle query del dashboard; è necessaria l'analisi delle query implementate.
Se viene raggiunto il limite di query simultaneo di Log Analytics, è consigliabile ottimizzare il modello di recupero archiviando (temporaneamente) i dati necessari per il dashboard in un archivio dati ad alte prestazioni, ad esempio Azure SQL.
Risposta automatica degli eventi imprevisti
Sebbene le rappresentazioni visive dell'integrità dell'applicazione forniscano informazioni operative e aziendali preziose per supportare il rilevamento e la diagnosi dei problemi, si basa sulla conformità e sulle interpretazioni dei team operativi, nonché sull'efficacia delle risposte attive successive. Pertanto, per ottimizzare l'affidabilità, è necessario implementare avvisi estesi per rilevare in modo proattivo e rispondere ai problemi in tempo quasi reale.
Monitoraggio di Azure offre un framework completo di avvisi per rilevare, classificare e rispondere ai segnali operativi tramite gruppi di azioni. Questa sezione si concentra quindi sull'uso degli avvisi di Monitoraggio di Azure per eseguire azioni automatizzate in risposta alle deviazioni correnti o potenziali da uno stato dell'applicazione integro.
Importante
L'avviso e l'azione automatizzata sono fondamentali per rilevare e rispondere rapidamente ai problemi quando si verificano, prima che si verifichi un impatto negativo maggiore. L'avviso fornisce anche un meccanismo per interpretare i segnali in ingresso e rispondere per evitare problemi prima che si verifichino.
Considerazioni relative alla progettazione
Le regole di avviso vengono definite quando un criterio condizionale è soddisfatto per i segnali in ingresso, che possono includere varie origini dati, ad esempio metriche, query di log o test di disponibilità.
Gli avvisi possono essere definiti all'interno di Log Analytics o Monitoraggio di Azure nella risorsa specifica.
Alcune metriche sono interrogabili solo all'interno di Monitoraggio di Azure, poiché non tutti i punti dati di diagnostica vengono resi disponibili all'interno di Log Analytics.
L'API Avvisi di Monitoraggio di Azure può essere usata per recuperare avvisi attivi e cronologici.
Esistono limiti di sottoscrizione correlati all'avviso e ai gruppi di azioni, che devono essere progettati per:
- I limiti esistono per il numero di regole di avviso configurabili.
- L'API Avvisi ha limiti di limitazione, che devono essere considerati per scenari di utilizzo estremi.
- I gruppi di azioni hanno diversi limiti rigidi per il numero di risposte configurabili, che devono essere progettate per.
- Ogni tipo di risposta ha un limite di 10 azioni, oltre alla posta elettronica, che ha un limite di 1.000 azioni.
Gli avvisi possono essere integrati all'interno di un modello di integrità a livelli creando una regola di avviso per una query di ricerca log salvata dalla funzione di assegnazione dei punteggi "radice" del modello. Ad esempio, usando "WebsiteHealthScore" e l'avviso su un valore numerico che rappresenta uno stato "Non integro".
Suggerimenti per la progettazione
Per l'avviso incentrato sulle risorse, creare regole di avviso all'interno di Monitoraggio di Azure per garantire che tutti i dati di diagnostica siano disponibili per i criteri delle regole di avviso.
Consolidare le azioni automatizzate all'interno di un numero minimo di gruppi di azioni, allineati ai team di servizio per supportare un approccio DevOps.
Rispondere ai segnali di utilizzo eccessivo delle risorse tramite operazioni di scalabilità automatizzate, usando le funzionalità di scalabilità automatica native di Azure, se possibile. Se la funzionalità di scalabilità automatica predefinita non è applicabile, usare il punteggio di integrità del componente per modellare i segnali e determinare quando rispondere con operazioni di scalabilità automatizzate. Assicurarsi che le operazioni di scalabilità automatizzate siano definite in base a un modello di capacità, che quantifica le relazioni di scalabilità tra i componenti, in modo che le risposte di scalabilità includano componenti che devono essere ridimensionati in relazione ad altri componenti.
Azioni del modello per soddisfare un ordine con priorità, che deve essere determinato dall'impatto aziendale.
Usare l'API Avvisi di Monitoraggio di Azure per raccogliere avvisi cronologici per incorporare all'interno dell'archiviazione operativa "a freddo" per l'analisi avanzata.
Per gli scenari di errore critici, che non possono essere soddisfatti con una risposta automatizzata, assicurarsi che l'automazione del runbook operativo sia sul posto per guidare un'azione rapida e coerente dopo aver fornito l'interpretazione manuale e disconnettersi. Usare le notifiche di avviso per guidare l'identificazione rapida dei problemi che richiedono l'interpretazione manuale
Creare quote all'interno degli sprint di progettazione per migliorare i miglioramenti incrementali nell'avviso per garantire che i nuovi scenari di errore che in precedenza non siano stati considerati possono essere completamente gestiti all'interno di nuove azioni automatizzate.
Eseguire test di idoneità operativa come parte dei processi CI/CD per convalidare le regole di avviso chiave per gli aggiornamenti della distribuzione.
Azioni predittive e operazioni di intelligenza artificiale (AIOps)
I modelli di Machine Learning possono essere applicati per correlare e assegnare priorità ai dati operativi, consentendo di raccogliere informazioni critiche correlate al filtro del rumore di avviso eccessivo e di stimare i problemi prima dell'impatto, nonché di accelerare la risposta agli eventi imprevisti quando si esegue.
In particolare, una metodologia aiOps può essere applicata alle informazioni critiche sul comportamento dei processi di sistema, utenti e DevOps. Queste informazioni dettagliate possono includere l'identificazione di un problema che si verifica ora (rilevamento), quantificando il motivo per cui il problema sta accadendo (diagnosi) o segnalando ciò che accadrà in futuro (stima). Tali informazioni dettagliate possono essere usate per guidare le azioni che regolano e ottimizzano l'applicazione per mitigare problemi attivi o potenziali, usando metriche aziendali chiave, metriche di qualità del sistema e metriche di produttività DevOps, per priorità in base all'impatto aziendale. Le azioni condotte possono essere infuse nel sistema tramite un ciclo di feedback che esegue ulteriormente il training del modello sottostante per aumentare l'efficienza.
 Metodologie di artificiale
Metodologie di artificiale
Esistono più tecnologie analitiche all'interno di Azure, ad esempio Azure Synapse e Azure Databricks, che possono essere usate per compilare ed eseguire il training di modelli analitici per IOps. Questa sezione si concentra quindi sul modo in cui queste tecnologie possono essere posizionate all'interno di una progettazione dell'applicazione per supportare i servizi di intelligenza artificiale e guidare l'azione predittiva, concentrandosi su Azure Synapse che riduce l'attrito combinando il meglio dei servizi dati di Azure insieme a nuove funzionalità potenti.
AiOps viene usato per guidare l'azione predittiva, interpretare e correlare i segnali operativi complessi osservati in un periodo sostenuto per rispondere meglio e prevenire i problemi prima che si verifichino.
Considerazioni relative alla progettazione
Azure Synapse Analytics offre più funzionalità di Machine Learning (ML).
- I modelli ml possono essere sottoposti a training ed eseguiti in pool di Synapse Spark con librerie quali MLLib, SparkML e MMLSpark, nonché le librerie open source più diffuse, ad esempio Scikit Learn.
- I modelli ml possono essere sottoposti a training con strumenti di data science comuni, ad esempio PySpark/Python, Scala o .NET.
Synapse Analytics è integrato con Azure ML tramite Azure Synapse Notebook, che consente di eseguire il training dei modelli di Machine Learning in un'area di lavoro di Azure ML usando Machine Learning automatizzato.
Synapse Analytics consente anche alle funzionalità di ML di usare Servizi cognitivi di Azure per risolvere i problemi generali in vari domini, ad esempio Rilevamento anomalie. Servizi cognitivi possono essere usati in Azure Synapse, Azure Databricks e tramite SDK e API REST nelle applicazioni client.
Azure Synapse si integra in modo nativo con strumenti di Azure Data Factory per estrarre, trasformare e caricare i dati (ETL) o inserire dati all'interno di pipeline di orchestrazione.
Azure Synapse consente la registrazione esterna dei set di dati ai dati archiviati nell'archivio BLOB di Azure o Azure Data Lake Storage.
- I set di dati registrati possono essere usati nelle attività di analisi dei dati del pool di Synapse Spark.
Azure Databricks può essere integrato nelle pipeline di analisi Azure Synapse per funzionalità Spark aggiuntive.
- Synapse orchestra la lettura dei dati e l'invio a un cluster Databricks, in cui può essere trasformato e preparato per il training del modello ml.
I dati di origine devono in genere essere preparati per l'analisi e ml.
- Synapse offre vari strumenti per facilitare la preparazione dei dati, tra cui Apache Spark, Synapse Notebooks e pool SQL serverless con visualizzazioni T-SQL e predefinite.
I modelli di Machine Learning sottoposti a training, operativi e distribuiti possono essere usati per l'assegnazione dei punteggi batch in Synapse.
- Gli scenari aiOps, ad esempio l'esecuzione di stime di regressione o riduzione nella pipeline CI/CD, possono richiedere l'assegnazione di punteggi in tempo reale .
Esistono limiti di sottoscrizione per Azure Synapse, che devono essere completamente compresi nel contesto di una metodologia aiOps.
Per incorporare completamente IOps, è necessario inserire dati di osservabilità quasi in tempo reale in modelli di inferenza ml in tempo reale in modo continuativo.
- Le funzionalità come il rilevamento anomalie devono essere valutate all'interno del flusso di dati di osservabilità.
Suggerimenti per la progettazione
Assicurarsi che tutte le risorse e i componenti dell'applicazione di Azure siano completamente instrumentati in modo che sia disponibile un set di dati operativo completo per il training del modello AIOps.
Inserire i dati operativi di Log Analytics dagli account di archiviazione di Azure globali e a livello di area in Azure Synapse per l'analisi.
Usare l'API Avvisi di Monitoraggio di Azure per recuperare gli avvisi cronologici e archiviarla all'interno dell'archiviazione ad accesso sporadico per i dati operativi da usare successivamente nei modelli di Machine Learning. Se viene usata l'esportazione dei dati di Log Analytics, archiviare i dati degli avvisi cronologici negli stessi account di Archiviazione di Azure dei dati di Log Analytics esportati.
Dopo aver inserito i dati per il training di Ml, scriverlo in Archiviazione di Azure in modo che sia disponibile per il training del modello ml senza richiedere l'esecuzione delle risorse di calcolo del calcolo dei dati di Synapse.
Assicurarsi che l'operatività del modello di Machine Learning supporti l'assegnazione dei punteggi in batch e in tempo reale.
Man mano che vengono creati modelli aiOps, implementare mlOps e applicare le procedure DevOps per automatizzare il ciclo di vita del machine learning per il training, l'operativizzazione, il punteggio e il miglioramento continuo. Creare un processo CI/CD iterativo per i modelli di Machine Learning aiOps.
Valutare Servizi cognitivi di Azure per scenari predittivi specifici a causa del sovraccarico di amministrazione e integrazione ridotto. Considerare rilevamento anomalie per contrassegnare rapidamente le varianza impreviste nei flussi di dati di osservabilità.
Passaggio successivo
Esaminare le considerazioni sulla distribuzione e sui test.