Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un'architettura di microservizi richiede una progettazione efficace dell'API perché tutti gli scambi di dati tra i servizi si verificano tramite messaggi o chiamate API. Le API efficienti consentono di evitare input/output verboso (I/O). I team indipendenti progettano servizi, quindi è necessario definire chiaramente la semantica dell'API e gli schemi di controllo delle versioni per evitare l'interruzione di altri servizi quando si aggiorna un servizio.

È necessario distinguere tra i due tipi di API:
- Le applicazioni client chiamano le API pubbliche
- API back-end per la comunicazione tra servizi
Questi due tipi hanno requisiti diversi. Un'API pubblica deve essere compatibile con applicazioni client, ad esempio applicazioni browser o applicazioni per dispositivi mobili native. La maggior parte delle API pubbliche usa REST su HTTP. Ma le API back-end devono tenere conto delle prestazioni di rete. A seconda della granularità dei servizi, la comunicazione tra servizi può comportare una quantità eccessiva di traffico di rete. I servizi possono diventare rapidamente associati all'I/O, quindi considerazioni come la velocità di serializzazione e le dimensioni del payload diventano più importanti. Alcune alternative comuni a REST su HTTP includono gRPC Remote Procedure Call (gRPC), Apache Avro e Apache Thrift. Questi protocolli supportano la serializzazione binaria e migliorano l'efficienza rispetto a HTTP.
Considerazioni
Quando si decide come implementare un'API, tenere presenti i fattori seguenti:
REST rispetto a Remote Procedure Call (RPC): Considerare i compromessi tra un'interfaccia di tipo REST e un'interfaccia di tipo RPC.
Risorse dei modelli REST, che consentono di esprimere il modello di dominio in modo intuitivo. Definisce un'interfaccia uniforme basata sui verbi HTTP, che incoraggia l'elulubilità. Include semantiche ben definite per idempotenza, effetti collaterali e codici di risposta. REST applica anche la comunicazione senza stato, migliorando la scalabilità.
RPC è incentrato sulle operazioni o sui comandi. Le interfacce RPC sono simili alle chiamate al metodo locale, il che può portare a API eccessivamente verbose. Ma RPC non richiede comunicazioni di chat. Per evitare tale risultato, è necessario progettare attentamente l'interfaccia.
Per un'interfaccia RESTful, la maggior parte dei team sceglie REST su HTTP tramite JSON. Per un'interfaccia di tipo RPC, i framework più diffusi includono gRPC, Avro e Thrift.
Efficienza: Prendere in considerazione l'efficienza in termini di velocità, memoria e dimensioni del payload. In genere un'interfaccia basata su gRPC è più veloce rispetto a REST su HTTP.
Linguaggio di definizione dell'interfaccia (IDL): Usare un file IDL per definire i metodi, i parametri e i valori restituiti di un'API. Un file IDL può generare codice client, codice di serializzazione e documentazione dell'API. Gli strumenti di test delle API usano gli IDL. I framework come gRPC, Avro e Thrift definiscono le proprie specifiche IDL. REST su HTTP non ha un formato IDL standard, ma una scelta comune è OpenAPI (in precedenza Swagger). È anche possibile creare un'API REST HTTP senza usare un linguaggio di definizione formale, ma si perdono i vantaggi della generazione e del test del codice.
Serializzazione: Scegliere come serializzare gli oggetti in rete. Le opzioni includono formati basati su testo come JSON e formati binari come il buffer del protocollo. I formati binari sono più veloci rispetto ai formati basati su testo. JSON offre tuttavia un'interoperabilità più ampia perché la maggior parte dei linguaggi e dei framework supporta la serializzazione JSON. Alcuni formati di serializzazione richiedono uno schema fisso o un file di definizione dello schema compilato. In questi casi, è necessario incorporare questo passaggio nel processo di compilazione. Per altre informazioni, vedere Procedure consigliate per la codifica dei messaggi.
Supporto del framework e del linguaggio: Quasi ogni framework e linguaggio supporta HTTP. Avro, gRPC e Thrift forniscono librerie per C++, C#, Java e Python. Thrift e gRPC supportano anche Go.
Compatibilità e interoperabilità: Se si sceglie un protocollo come gRPC, potrebbe essere necessario un livello di conversione del protocollo tra l'API pubblica e il back-end. Un gateway può eseguire tale funzione. Se si usa una mesh di servizi, controllare la compatibilità del protocollo con la mesh del servizio. Ad esempio, Linkerd include il supporto predefinito per HTTP, Thrift e gRPC.
Usare REST su HTTP a meno che non siano necessari i vantaggi delle prestazioni di un protocollo binario. REST su HTTP non richiede librerie speciali e crea un accoppiamento minimo perché i chiamanti non necessitano di uno stub client per comunicare con il servizio. L'ecosistema REST include strumenti per supportare definizioni di schema, test e monitoraggio degli endpoint HTTP RESTful. HTTP funziona anche con i client browser, quindi non è necessario un livello di conversione del protocollo tra il client e il back-end.
Se si sceglie REST su HTTP, eseguire il test delle prestazioni e del carico nelle prime fasi del processo di sviluppo per verificare se viene eseguito in modo adeguato per lo scenario in uso.
Progettazione dell'API RESTful
Le risorse seguenti consentono di progettare API RESTful:
Prendere in considerazione i fattori seguenti:
Evitare API che espongono dettagli di implementazione interni o eseguire il mirroring di uno schema interno del database. L'API deve modellare il dominio e fungere da contratto tra i servizi. Idealmente, è consigliabile modificare l'API solo quando si aggiungono nuove funzionalità, non quando si esegue il refactoring del codice o si modifica lo schema del database.
Diversi tipi di client, ad esempio applicazioni per dispositivi mobili e Web browser desktop, potrebbero richiedere dimensioni di payload o modelli di interazione diversi. Prendere in considerazione l'uso del modello Backends per Frontends per creare back-end separati per ogni cliente. Ogni back-end espone un'interfaccia ottimale per il client.
Per le operazioni che causano effetti collaterali, è consigliabile renderle idempotenti e attuarle come metodi
PUT. Questo approccio consente tentativi sicuri e migliora la resilienza. Per altre informazioni, vedere Comunicazione tra servizi.I metodi HTTP possono avere una semantica asincrona, in cui il metodo restituisce immediatamente una risposta, ma il servizio esegue l'operazione in modo asincrono. In tal caso, il metodo deve restituire un codice di risposta HTTP 202 . Questo codice indica che la richiesta è stata accettata per l'elaborazione ma non ancora elaborata. Per altre informazioni, vedere Modello di Request-Reply asincrono.
API di accesso ai dati generici: considerazioni su OData e GraphQL
Le API REST offrono un approccio strutturato per esporre le risorse, ma alcuni scenari richiedono modelli di accesso ai dati più flessibili. Le API orientate alle query come OData e GraphQL offrono alternative che consentono ai client di specificare esattamente i dati necessari. Questo approccio può potenzialmente ridurre il sovraccarico e migliorare le prestazioni. Questi tipi di API assegnano priorità alle operazioni di lettura. Le operazioni di mutazione, come la creazione, l'aggiornamento e l'eliminazione, possono essere più complesse da implementare, ma vari framework possono gestire queste operazioni in modo efficace.
Quando prendere in considerazione le API di accesso ai dati generici
Usare un modello di accesso ai dati generico nelle situazioni seguenti:
I client hanno requisiti di dati diversi che comportano molti endpoint REST specializzati o un comportamento specializzato.
È necessario supportare operazioni complesse di query, filtro e ordinamento tra più entità dati.
L'over-fetching è un problema significativo per le prestazioni, in particolare per i client con limitazioni di larghezza di banda o per dispositivi mobili.
Evitare API di accesso ai dati generiche nelle situazioni seguenti:
L'architettura dei microservizi evidenzia limiti rigorosi del servizio e incapsulamento del dominio.
È necessario un controllo granulare sui modelli di accesso ai dati e sui criteri di sicurezza.
Le API supportano principalmente operazioni semplici di creazione, lettura, aggiornamento ed eliminazione (CRUD) o flussi di lavoro aziendali ben definiti.
REST soddisfa già i requisiti di prestazioni e payload di rete.
I requisiti di sicurezza richiedono definizioni esplicite di endpoint per ridurre al minimo le superfici di attacco.
Il team non ha esperienza con l'implementazione e l'ottimizzazione del linguaggio di query.
Eseguire il mapping di REST a modelli DDD
I modelli come l'entità, l'aggregazione e l'oggetto valore definiscono vincoli per gli oggetti in un modello di dominio. Molte discussioni sulla progettazione guidata dal dominio descrivono questi modelli usando concetti del linguaggio orientato agli oggetti (OO), ad esempio costruttori o getter e setter delle proprietà. Ad esempio, gli oggetti valore devono essere non modificabili. In un linguaggio di programmazione OO si applica questo vincolo assegnando i valori nel costruttore e rendendo le proprietà di sola lettura:
export class Location {
readonly latitude: number;
readonly longitude: number;
constructor(latitude: number, longitude: number) {
if (!Number.isFinite(latitude) || latitude < -90 || latitude > 90) {
throw new RangeError('latitude must be between -90 and 90');
}
if (!Number.isFinite(latitude) || longitude < -180 || longitude > 180) {
throw new RangeError('longitude must be between -180 and 180');
}
this.latitude = latitude;
this.longitude = longitude;
}
}
Queste procedure di codifica svolgono un ruolo importante nella creazione di un'applicazione monolitica tradizionale. In una codebase di grandi dimensioni, molti sottosistemi potrebbero usare l'oggetto Location , pertanto l'oggetto deve applicare il comportamento corretto.
Il modello Repository fornisce un altro esempio. Questo modello garantisce che altre parti dell'applicazione non eseseguono letture o scritture dirette nell'archivio dati.

In un'architettura di microservizi i servizi non condividono la stessa codebase o un archivio dati. Comunicano invece tramite LE API. Ad esempio, un servizio di schedulazione potrebbe richiedere informazioni su un drone da un servizio per droni. Il servizio drone definisce il modello di drone interno tramite codice. Tuttavia, il pianificatore non può accedere direttamente a questi dettagli. L'utilità di pianificazione riceve invece una rappresentazione dell'entità drone, ad esempio un oggetto JSON in una risposta HTTP.
Questo esempio si applica bene alle industrie aeree e aerospaziali.

Il servizio di pianificazione non può modificare i modelli interni del servizio drone né scrivere nel database del servizio drone. Quindi il codice che implementa il servizio di droni ha una superficie esposta più piccola rispetto al codice di un monolite tradizionale. Se il servizio drone definisce una Location classe, l'ambito di tale classe è limitato, nessun altro servizio utilizza direttamente la classe .
Per questi motivi, queste linee guida non si concentrano molto sulle procedure di codifica correlate ai modelli DDD tattici. Tuttavia, è possibile modellare molti modelli DDD tramite le API REST.
Gli esempi seguenti illustrano in che modo i concetti REST sono allineati ai costrutti DDD comuni:
Le aggregazioni si mappano naturalmente alle risorse in REST. Ad esempio, un'API di recapito potrebbe esporre un'aggregazione di recapito come risorsa.
Le aggregazioni definiscono limiti di coerenza. Le operazioni sulle aggregazioni non devono lasciare un'aggregazione in uno stato incoerente. Evitare di creare API che consentono a un client di modificare lo stato interno di un'aggregazione. Invece, favorire API con granularità grossolana che espongono aggregazioni come risorse.
Le entità hanno identità univoche. In REST le risorse hanno identificatori univoci sotto forma di URL. Creare URL di risorse che corrispondono all'identità di dominio di un'entità. Il mapping dall'URL all'identità del dominio può non essere chiaro ai clienti.
Le entità figlio di un'aggregazione possono essere raggiunte dall'entità radice. Se si seguono i principi hypermedia come motore di stato dell'applicazione (HATEOAS), è possibile raggiungere le entità figlio tramite collegamenti nella rappresentazione dell'entità padre.
Gli oggetti valore non sono modificabili. Per eseguire gli aggiornamenti, sostituire l'intero oggetto valore. In REST, implementare gli aggiornamenti tramite richieste
PUToPATCH.Un repository consente ai client di eseguire query, aggiungere o rimuovere oggetti in una raccolta. Il repository astrae i dettagli dell'archivio dati sottostante. In REST una raccolta può essere una risorsa distinta che include metodi per l'esecuzione di query sulla raccolta o l'aggiunta di nuove entità alla raccolta.
Quando si progettano API, considerare il modo in cui esprimono il modello di dominio, non solo i dati all'interno del modello. Considerare anche le operazioni aziendali e i vincoli sui dati.
| Concetto DDD | Equivalente REST | Example |
|---|---|---|
| Aggregate | Conto risorse | { "1":1234, "status":"pending"... } |
| Identità | URL | https://delivery-service/deliveries/1 |
| Entità figlie | Links | { "href": "/deliveries/1/confirmation" } |
| Aggiornare gli oggetti di valore |
PUT oppure PATCH |
PUT https://delivery-service/deliveries/1/dropoff |
| Repository | Collection | https://delivery-service/deliveries?status=pending |
Controllo delle versioni delle API
Un'API funge da contratto tra un servizio e client o consumer di tale servizio. Le modifiche all'API possono interrompere i client esterni o i microservizi che dipendono dall'API. Ridurre al minimo il numero di modifiche all'API apportate. Le modifiche nell'implementazione sottostante spesso non richiedono modifiche all'API. Tuttavia, è probabile che si voglia aggiungere nuove funzionalità o nuove funzionalità che richiedono la modifica di un'API esistente.
Rendere le modifiche api compatibili con le versioni precedenti, quando possibile. Ad esempio, evitare di rimuovere un campo da un modello. Tale modifica può interrompere i client che prevedono che il campo esista. L'aggiunta di un campo non interrompe la compatibilità perché i client devono ignorare i campi che non riconoscono in una risposta. Tuttavia, il servizio deve gestire le richieste dei client meno recenti che omettono il nuovo campo.
Supportare il controllo delle versioni nel contratto API. Se si introduce una modifica che causa un'interruzione dell'API, introdurre una nuova versione dell'API. Continuare a supportare la versione precedente e consentire ai client di selezionare la versione da chiamare. Un modo per eseguire il controllo delle versioni consiste nell'esporre entrambe le versioni nello stesso servizio. Un'altra opzione consiste nell'eseguire due versioni del servizio side-by-side e instradare le richieste a una o all'altra versione in base alle regole di routing HTTP.
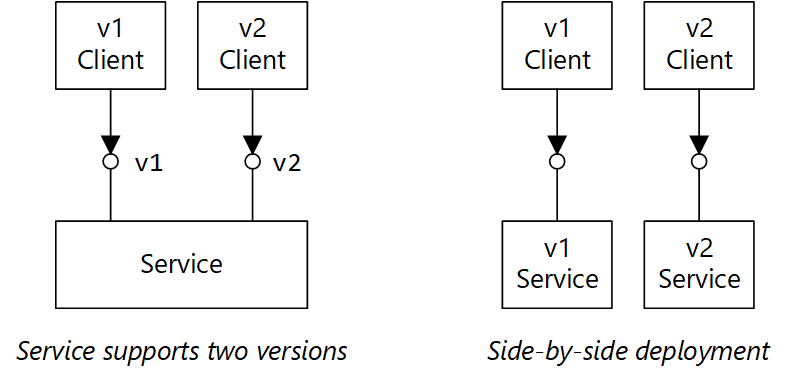
Il diagramma ha due parti. Il lato sinistro mostra un servizio che supporta due versioni. Il client v1 e il client v2 puntano entrambi a un servizio. Il lato destro mostra un'implementazione affiancata. Il client v1 punta a un servizio v1 e il client v2 punta a un servizio v2.
Più versioni aggiungono costi in termini di tempo, test e sovraccarico operativo per gli sviluppatori. Deprecare le versioni precedenti il più rapidamente possibile. Per le API interne, il team proprietario dell'API può collaborare con altri team per aiutarli a eseguire la migrazione alla nuova versione. Il processo di governance tra team è utile qui. Le API esterne (pubbliche) possono rendere più difficile ritirare una versione dell'API, soprattutto se le applicazioni client esterne o native consumano l'API.
Quando un'implementazione del servizio cambia, contrassegna la modifica con una versione. La versione fornisce informazioni importanti per la risoluzione degli errori. Questo approccio supporta l'analisi della causa radice perché si conosce la versione del servizio chiamata. È consigliabile utilizzare il versionamento semantico per le versioni del servizio. Il versionamento semantico usa un formato MAJOR.MINOR.PATCH. Tuttavia, i client devono selezionare un'API solo in base al numero di versione principale o alla versione minore se sono presenti modifiche significative ma non compromettenti tra le versioni minori. Ad esempio, i client potrebbero scegliere tra la versione 1 e la versione 2 di un'API, ma non dovrebbero scegliere la versione 2.1.3. Se si consente tale livello di granularità, si rischia di dover supportare troppe versioni.
Per altre informazioni, vedere Implementare il controllo delle versioni per un'API Web RESTful.
Operazioni Idempotenti
Un'operazione è idempotente se è possibile chiamarla più volte senza produrre più effetti collaterali dopo la prima chiamata. L'idempotenza funge da strategia di resilienza utile perché consente a un servizio upstream di richiamare in modo sicuro un'operazione più volte. Per altre informazioni, vedere Transazioni distribuite.
La specifica HTTP indica che i metodi GET, PUT e DELETE devono essere idempotenti.
POST non è garantito che i metodi siano idempotenti. Se un POST metodo crea una nuova risorsa, in genere non esiste alcuna garanzia che questa operazione sia idempotente. La specifica definisce idempotente nel modo seguente:
Un metodo di richiesta viene considerato idempotente se l'effetto previsto sul server di più richieste identiche con tale metodo è uguale all'effetto per una singola richiesta di questo tipo. (RFC 7231)
Comprendere la differenza tra PUT e POST semantica quando si crea una nuova entità. In entrambi i casi, il client invia una rappresentazione di un'entità nel corpo della richiesta. Ma il significato dell'URI (Uniform Resource Identifier) è diverso.
Per un
POSTmetodo, l'URI rappresenta una risorsa padre della nuova entità, ad esempio una raccolta. Ad esempio, per creare un nuovo recapito, l'URI potrebbe essere/api/deliveries. Il server crea l'entità e lo assegna a un nuovo URI, ad esempio/api/deliveries/39660. Questo URI viene restituito nell'intestazioneLocationdella risposta. Ogni volta che il client invia una richiesta, il server crea una nuova entità con un nuovo URI.Per un
PUTmetodo, l'URI identifica l'entità. Se un'entità esistente ha tale URI, il server sostituisce l'entità esistente con la versione nella richiesta. Se nessuna entità usa tale URI, ne crea uno. Si supponga, ad esempio, che il client invii unaPUTrichiesta aapi/deliveries/39660. Se nessuna risorsa di recapito usa tale URI, il server ne crea uno nuovo. Se il client invia nuovamente la stessa richiesta, il server sostituisce l'entità esistente.
Il servizio di distribuzione usa il codice seguente per implementare il PUT metodo :
[HttpPut("{id}")]
[ProducesResponseType<Delivery>(StatusCodes.Status201Created)]
[ProducesResponseType(StatusCodes.Status204NoContent)]
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
try
{
var internalDelivery = delivery.ToInternal();
// Create the new delivery entity.
await deliveryRepository.CreateAsync(internalDelivery);
// Create a delivery status event.
var deliveryStatusEvent = new DeliveryStatusEvent { DeliveryId = delivery.Id, Stage = DeliveryEventType.Created };
await deliveryStatusEventRepository.AddAsync(deliveryStatusEvent);
// Return HTTP 201 (Created)
return CreatedAtRoute("GetDelivery", new { id= delivery.Id }, delivery);
}
catch (DuplicateResourceException)
{
// This method mainly creates deliveries. If the delivery already exists, update it.
logger.LogInformation("Updating resource with delivery id: {DeliveryId}", id);
var internalDelivery = delivery.ToInternal();
await deliveryRepository.UpdateAsync(id, internalDelivery);
// Return HTTP 204 (No Content)
return NoContent();
}
}
La maggior parte delle richieste crea una nuova entità, quindi il metodo prevede che la creazione abbia esito positivo e chiami CreateAsync sull'oggetto repository. Il metodo gestisce quindi le eccezioni duplicate-resource aggiornando invece la risorsa.
Passo successivo
Informazioni sull'uso di un gateway API al limite tra le applicazioni client e i microservizi.