La comunicazione tra i microservizi deve essere efficiente e solida, Con un sacco di piccoli servizi che interagiscono per completare una singola attività aziendale, questa può essere una sfida. In questo articolo vengono esaminati i compromessi tra la messaggistica asincrona e le API sincrone. Verranno quindi esaminate alcune delle sfide nella progettazione di comunicazioni tra servizi resilienti.
Problematiche
Ecco alcune delle principali problematiche derivanti dalla comunicazione da servizio a servizio. Le mesh di servizi, descritte più avanti in questo articolo, sono progettate per gestire molte di queste problematiche.
Resilienza. Possono esistere decine o addirittura centinaia di istanze di un determinato microservizio. Un'istanza può avere esito negativo per diversi motivi. Può verificarsi un errore a livello di nodo, ad esempio un errore hardware o un riavvio della VM. Un'istanza potrebbe arrestarsi in modo anomalo o essere sovraccaricata da richieste e non riuscire a elaborare le nuove richieste. Uno di questi eventi può causare l'esito negativo di una chiamata di rete. Due schemi progettuali consentono di rendere più resilienti le chiamate di rete da servizio a servizio:
Nuovo tentativo. Una chiamata di rete potrebbe non riuscire a causa di un errore temporaneo che si risolve da sé. Invece di non riuscire del tutto, l'operazione in genere deve essere ripetuta dal chiamante un certo numero di volte o finché non trascorre un periodo di timeout configurato. Se tuttavia un'operazione non è idempotente, i nuovi tentativi possono causare effetti collaterali indesiderati. La chiamata originale potrebbe riuscire, ma il chiamante non riceve mai una risposta. Se il chiamante riprova, l'operazione potrebbe essere richiamata due volte. In genere non è sicuro provare a eseguire di nuovo i metodi POST o PATCH, perché non è garantito che siano idempotenti.
Interruttore. Un numero eccessivo di richieste non riuscite può causare un collo di bottiglia perché le richieste in sospeso si accumulano nella coda. Queste richieste bloccate potrebbero tenere in sospeso risorse di sistema critiche, come la memoria, i thread, le connessioni di database e così via, che possono causare errori a catena. Il modello a interruttore può impedire a un servizio di provare a eseguire ripetutamente un'operazione che probabilmente continuerà a restituire un errore.
Bilanciamento del carico. Quando il servizio "A" chiama il servizio "B", la richiesta deve raggiungere un'istanza in esecuzione del servizio "B". In Kubernetes il tipo di risorsa Service fornisce un indirizzo IP stabile per un gruppo di pod. Il traffico di rete verso l'indirizzo IP del servizio viene inoltrato a un pod per mezzo di regole di iptables. Per impostazione predefinita, viene scelto un pod casuale. Una rete mesh di servizi (vedere sotto) può fornire algoritmi di bilanciamento del carico più intelligenti in base alla latenza osservata o ad altre metriche.
Traccia distribuita. Una singola transazione può estendersi a più servizi, rendendo così difficile monitorare le prestazioni complessive e l'integrità del sistema. Anche se ogni servizio genera log e metriche, se non vengono in qualche modo collegati, hanno un uso limitato. L'articolo Registrazione e monitoraggio illustra in modo più approfondito la traccia distribuita, ma viene menzionata qui come una sfida.
Controllo delle versioni dei servizi. Quando un team distribuisce una nuova versione di un servizio, deve evitare di interrompere gli altri servizi o i client esterni che ne dipendono. Potrebbe anche essere necessario eseguire più versioni affiancate di un servizio e instradare le richieste a una determinata versione. Per altre informazioni su questo problema, vedere Controllo delle versioni delle API.
Crittografia TLS e autenticazione TLS reciproca. Per motivi di sicurezza, potrebbe essere necessario crittografare il traffico tra i servizi con TLS e usare l'autenticazione TLS reciproca per autenticare i chiamanti.
Messaggistica sincrona e asincrona
I microservizi possono usare due modelli di messaggistica di base per comunicare con gli altri microservizi.
Comunicazione sincrona. In questo modello un servizio chiama un'API esposta da un altro servizio, usando un protocollo come HTTP o gRPC. Questa opzione è un modello di messaggistica sincrona perché il chiamante attende una risposta dal ricevitore.
Passaggio di messaggi asincroni. In questo modello un servizio invia un messaggio senza attendere una risposta e uno o più servizi elaborano il messaggio in modo asincrono.
È importante distinguere tra I/O asincrono e un protocollo asincrono. L'I/O asincrono implica che il thread chiamante non viene bloccato durante il completamento dell'I/O. È importante per le prestazioni, ma dal punto di vista dell'architettura è un dettaglio dell'implementazione. Un protocollo asincrono implica che il mittente non attende una risposta. HTTP è un protocollo sincrono, anche se un client HTTP può usare l'I/O asincrono quando invia una richiesta.
Sono possibili compromessi per ogni modello. Il paradigma richiesta/risposta è ben noto, quindi progettare un'API può risultare più naturale che progettare un sistema di messaggistica. Tuttavia, la messaggistica asincrona presenta alcuni vantaggi che possono essere utili in un'architettura di microservizi:
Accoppiamento ridotto. Il mittente del messaggio non ha bisogno di informazioni sul consumer.
Più sottoscrittori. Usando un modello di pubblicazione/sottoscrizione, più consumer possono effettuare la sottoscrizione per ricevere gli eventi. Vedere Stile di architettura guidato dagli eventi.
Isolamento degli errori. Se il consumer ha esito negativo, il mittente può ugualmente inviare i messaggi. I messaggi verranno selezionati quando il consumer eseguirà il recupero. Questa possibilità è particolarmente utile in un'architettura di microservizi, perché ogni servizio ha il proprio ciclo di vita. Un servizio potrebbe non essere disponibile o essere sostituito con una versione più recente in qualsiasi momento. La messaggistica asincrona può gestire i tempi di inattività intermittenti. Per le API sincrone è invece necessario che il servizio sia disponibile o l'operazione non riuscirà.
Tempi di risposta. Un servizio upstream può rispondere più rapidamente se non attende servizi downstream. Ciò può rivelarsi particolarmente utile in un'architettura di microservizi. Se è presente una catena di dipendenze dei servizi (il servizio A chiama B, che chiama C e così via), l'attesa di chiamate sincrone può aggiungere periodi di latenza inaccettabili.
Livellamento del carico. Una coda può fungere da buffer per livellare il carico di lavoro, in modo che i ricevitori possano elaborare i messaggi alla propria velocità.
Flussi di lavoro. Le code possono essere usate per gestire un flusso di lavoro, inserendo un checkpoint nel messaggio dopo ogni passaggio del flusso di lavoro.
L'uso efficiente della messaggistica asincrona comporta tuttavia anche alcune problematiche.
Accoppiamento con l'infrastruttura di messaggistica. L'uso di una determinata infrastruttura di messaggistica può causare un accoppiamento rigido con tale infrastruttura. Sarà difficile passare a un'altra infrastruttura di messaggistica in un secondo momento.
Latenza. La latenza end-to-end per un'operazione può diventare elevata se le code di messaggi si riempiono.
Costo. A velocità effettive elevate, il costo economico dell'infrastruttura di messaggistica potrebbe essere considerevole.
Complessità. La gestione della messaggistica asincrona non è un'attività semplice. È ad esempio necessario gestire i messaggi duplicati, deduplicandoli o rendendo le operazioni idempotenti. È anche difficile implementare la semantica richiesta-risposta usando la messaggistica asincrona. Per inviare una risposta, è necessaria un'altra coda, oltre a un modo per correlare i messaggi di richiesta e di risposta.
Velocità effettiva. Se i messaggi richiedono la semantica di accodamento, la coda può diventare un collo di bottiglia nel sistema. Ogni messaggio richiede almeno un'operazione di accodamento e un'operazione di rimozione dalla coda. La semantica di accodamento inoltre richiede in genere qualche tipo di blocco all'interno dell'infrastruttura di messaggistica. Se la coda è un servizio gestito, potrebbe esserci latenza aggiuntiva, perché la coda è esterna alla rete virtuale del cluster. È possibile attenuare questi problemi con l'invio in batch dei messaggi, che però aumenta la complessità del codice. Se i messaggi non richiedono la semantica di accodamento, è possibile usare un flusso di eventi invece di una coda. Per altre informazioni, vedere Stile di architettura guidato dagli eventi.
Drone Delivery: scelta dei modelli di messaggistica
Questa soluzione usa l'esempio di recapito tramite drone. È ideale per le industrie aerospaziali e aeree.
Tenendo presenti queste considerazioni, il team di sviluppo ha effettuato le seguenti scelte di progettazione per l'applicazione di recapito tramite drone:
Il servizio di inserimento espone un'API REST pubblica che le applicazioni client usano per pianificare, aggiornare o annullare le consegne.
Il servizio di inserimento usa Hub eventi per inviare messaggi asincroni al servizio utilità di pianificazione. I messaggi asincroni sono necessari per implementare il livellamento del carico richiesto per l'inserimento.
I servizi account, consegna, pacchetto, drone e trasporto di terze parti espongono tutti API REST interne. Il servizio utilità di pianificazione chiama queste API per eseguire una richiesta di un utente. Uno dei motivi per usare le API sincrone è la necessità dell'utilità di pianificazione di ottenere una risposta da ogni servizio downstream. Un errore in uno dei servizi downstream comporta l'esito negativo dell'intera operazione. Un potenziale problema è tuttavia la quantità di latenza che viene introdotta chiamando i servizi back-end.
Se un servizio downstream presenta un errore non transazionale, l'intera transazione deve essere contrassegnata come non riuscita. Per gestire questo caso, il servizio Utilità di pianificazione invia un messaggio asincrono al supervisore, in modo che il supervisore possa pianificare le transazioni di compensazione.
Il servizio di consegna espone un'API pubblica che i client possono usare per ottenere lo stato di una consegna. Nell'articolo Gateway API viene illustrato come un gateway API può nascondere i servizi sottostanti dal client, quindi il client non deve sapere quali servizi espongono le API.
Mentre un drone è in volo, il servizio drone invia gli eventi contenenti la posizione e lo stato correnti del drone. Il servizio di consegna è in ascolto di questi eventi per tenere traccia dello stato di una consegna.
Quando lo stato di una consegna cambia, il servizio di consegna invia un evento relativo allo stato della consegna, ad esempio
DeliveryCreatedoDeliveryCompleted. Qualsiasi servizio può sottoscrivere questi eventi. Nella progettazione corrente, il servizio Cronologia recapito è l'unico sottoscrittore, ma potrebbero essere presenti altri sottoscrittori in un secondo momento. Gli eventi, ad esempio, potrebbero essere inviati a un servizio di analisi in tempo reale e poiché l'utilità di pianificazione non deve attendere una risposta, l'aggiunta di altri sottoscrittori non ha effetto sul percorso del flusso di lavoro principale.
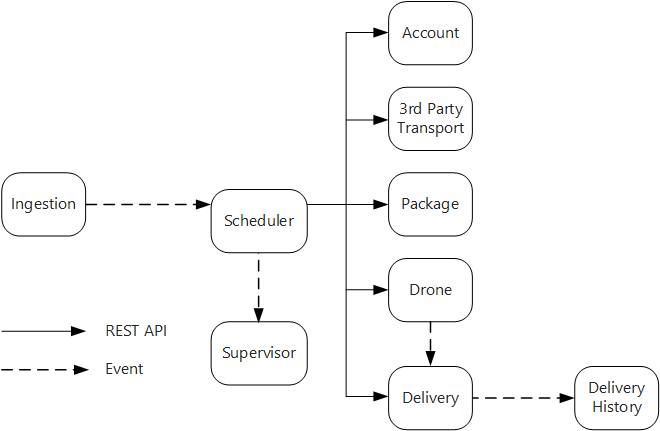
Si noti che gli eventi relativi allo stato della consegna sono derivati dagli eventi relativi alla posizione del drone. Quando ad esempio un drone raggiunge la posizione di una consegna e recapita un pacchetto, il servizio di consegna lo converte in un evento DeliveryCompleted. Questo è un esempio di come si possa pensare in termini di modelli di dominio. Come illustrato prima, la gestione dei droni rientra in un contesto delimitato distinto. Gli eventi relativi ai droni indicano la posizione fisica di un drone. Gli eventi relativi alle consegne invece rappresentano le modifiche dello stato di una consegna, che è un'entità di business diversa.
Uso di una rete mesh di servizi
Una rete mesh di servizi è un livello di software che gestisce la comunicazione da servizio a servizio. Le reti mesh di servizi sono progettate per fare fronte a molte delle problematiche elencate nella sezione precedente e per trasferire la responsabilità di queste problematiche dai microservizi a un livello condiviso. La rete mesh di servizi funge da proxy che intercetta la comunicazione di rete tra i microservizi nel cluster. Attualmente, il concetto di mesh di servizi si applica principalmente agli agenti di orchestrazione dei contenitori, anziché alle architetture serverless.
Nota
Mesh di servizi è un esempio del modello Ambassador, un servizio helper che invia richieste di rete per conto dell'applicazione.
Al momento, le opzioni principali per una mesh di servizi in Kubernetes sono Linkerd e Istio. Entrambe queste tecnologie sono in rapida evoluzione. Tuttavia, alcune funzionalità che linkerd e Istio hanno in comune includono:
Bilanciamento del carico a livello di sessione, in base alle latenze osservate o al numero di richieste arretrate, che può migliorare le prestazioni oltre quelle del bilanciamento del carico di livello 4 offerte da Kubernetes.
Routing di livello 7 basato sul percorso URL, sull'intestazione host, sulla versione API o su altre regole a livello di applicazione.
Nuovo tentativo per le richieste non riuscite. Una rete mesh di servizi conosce i codici di errore HTTP e può automaticamente riprovare a eseguire le richieste non riuscite. È possibile configurare il numero massimo di tentativi, oltre a un periodo di timeout per associare la latenza massima.
Interruzione del circuito. Se un'istanza continua a non riuscire a eseguire le richieste, la rete mesh di servizi la contrassegnerà temporaneamente come non disponibile. Dopo un periodo di backoff, proverà di nuovo l'istanza. È possibile configurare l'interruttore in base a diversi criteri, ad esempio il numero di errori consecutivi.
La rete mesh di servizi acquisisce le metriche sulle chiamate tra i servizi, ad esempio il volume della richiesta, la latenza, le percentuali di errore e riuscita e le dimensioni della risposta. La rete mesh di servizi abilita anche l'analisi distribuita aggiungendo le informazioni di correlazione per ogni hop in una richiesta.
Autenticazione TLS reciproca per le chiamate da servizio a servizio.
Se è necessaria una rete mesh di servizi, Dipende. Senza una mesh di servizi, è necessario considerare ognuna delle sfide menzionate all'inizio di questo articolo. È possibile risolvere problemi come quelli relativi ai nuovi tentativi, agli interruttori di circuito e alle analisi distribuite anche senza una rete mesh di servizi, ma con una rete mesh di servizi queste problematiche passano dai singoli servizi a un livello dedicato. D'altra parte, una mesh di servizi aggiunge complessità alla configurazione e alla configurazione del cluster. Le prestazioni potrebbero risentirne, perché le richieste ora vengono instradate tramite il proxy della rete mesh di servizi e perché in ogni nodo del cluster ora sono in esecuzione servizi aggiuntivi. È consigliabile eseguire test di carico e delle prestazioni completi prima di distribuire una rete mesh di servizi nell'ambiente di produzione.
Transazioni distribuite
Una sfida comune nei microservizi consiste nel gestire correttamente le transazioni che si estendono su più servizi. Spesso in questo scenario, l'esito positivo di una transazione è tutto o nulla, se uno dei servizi partecipanti ha esito negativo, l'intera transazione deve avere esito negativo.
Considerare i due casi seguenti:
Un servizio può riscontrare un errore temporaneo , ad esempio un timeout di rete. Questi errori spesso possono essere risolti semplicemente eseguendo nuovamente la chiamata. Se l'operazione ha ancora esito negativo dopo un determinato numero di tentativi, viene considerata un errore non transiente.
Un errore non transiente è un errore improbabile che vada via da solo. Gli errori non transienti includono condizioni di errore normali, ad esempio l'input non valido. Includono anche le eccezioni non gestite nel codice dell'applicazione o l'arresto anomalo di un processo. Se si verifica questo tipo di errore, l'intera transazione aziendale deve essere contrassegnata come errore. Potrebbe essere necessario annullare altri passaggi nella stessa transazione che hanno già avuto esito positivo.
Dopo un errore non transazionale, la transazione corrente potrebbe essere in uno stato parzialmente non riuscito , in cui uno o più passaggi sono già stati completati correttamente. Se, ad esempio, il servizio drone ha già pianificato un drone, il drone deve essere annullato. In tal caso, l'applicazione deve annullare i passaggi che hanno avuto esito positivo, usando una transazione di compensazione. In alcuni casi, questa azione deve essere eseguita da un sistema esterno o anche da un processo manuale. Nella progettazione ricordare che anche le misure di compensazione sono soggette a errori.
Se la logica per le transazioni di compensazione è complessa, prendere in considerazione la creazione di un servizio separato responsabile di questo processo. Nell'applicazione di recapito tramite drone il servizio Utilità di pianificazione inserisce le operazioni non riuscite in una coda dedicata. Un microservizio separato, detto supervisore, legge da questa coda e chiama un'API di annullamento per i servizi per cui è necessaria la compensazione. Questa è una variante del modello di supervisione agente di pianificazione. Il servizio supervisore potrebbe eseguire anche altre operazioni, ad esempio inviare all'utente una notifica tramite SMS o posta elettronica oppure inviare un avviso a un dashboard delle operazioni.
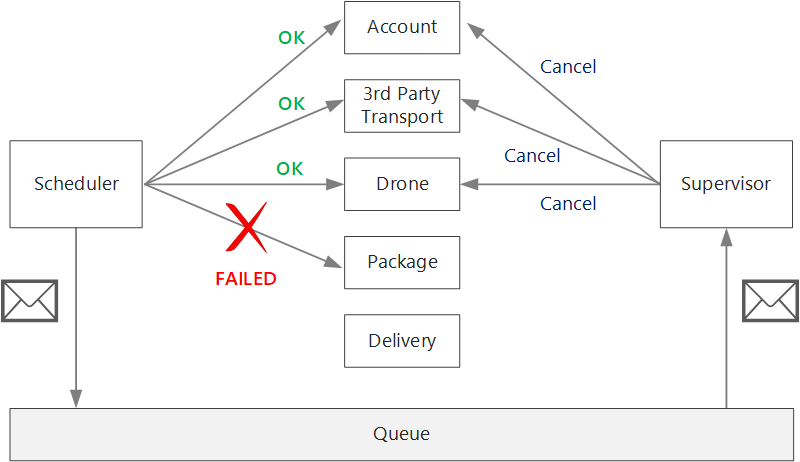
Il servizio utilità di pianificazione potrebbe non riuscire, ad esempio perché un nodo si arresta in modo anomalo. In tal caso, una nuova istanza può attivare e assumere il controllo. Sarà tuttavia necessario riprendere tutte le transazioni già in corso.
Un approccio consiste nel salvare un checkpoint in un archivio durevole dopo il completamento di ogni passaggio del flusso di lavoro. Se un'istanza del servizio Utilità di pianificazione si arresta in modo anomalo al centro di una transazione, una nuova istanza può usare il checkpoint per riprendere la posizione in cui è stata interrotta l'istanza precedente. Tuttavia, la scrittura di checkpoint può comportare un sovraccarico delle prestazioni.
Un'altra opzione consiste nel progettare tutte le operazioni in modo che siano idempotenti. Un'operazione è idempotente se può essere chiamata più volte senza produrre effetti collaterali aggiuntivi dopo la prima chiamata. Essenzialmente, il servizio downstream deve ignorare le chiamate duplicate, il che significa che il servizio deve essere in grado di rilevare chiamate duplicate. Non è sempre semplice implementare metodi idempotenti. Per altre informazioni, vedere Operazioni Idempotenti.
Passaggi successivi
Per i microservizi che comunicano direttamente tra loro, è importante creare API ben progettate.