Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Isolare gli elementi di un'applicazione in pool in modo che, se un elemento ha esito negativo, gli altri continuano a funzionare. Questo approccio, noto anche come architettura basata su celle, rende un'applicazione a tolleranza di errore e arresta un errore in una parte del sistema dalla propagazione del resto.
Tip
Questo schema prende il nome dalle paratie stagne che suddividono in sezioni lo scafo di una nave. Se lo scafo subisce un danno, si riempie d'acqua solo la sezione danneggiata, impedendo quindi che l'intera nave affondi.
Contesto e problema
Un'applicazione basata sul cloud può includere più servizi e ogni servizio ha uno o più consumer. Un carico o un errore eccessivo in un servizio influisce su tutti i consumer del servizio.
Inoltre, un consumer potrebbe inviare richieste a più servizi contemporaneamente e usare le risorse per ogni richiesta. Quando il consumer invia una richiesta a un servizio non configurato o non risponde correttamente, le risorse usate dalla richiesta del client potrebbero non essere disponibili per un periodo prolungato. Quando le richieste al servizio continuano, tali risorse potrebbero essere esaurite. Ad esempio, il pool di connessioni del client potrebbe essere esaurito. A questo punto, le richieste dell'utente ad altri servizi vengono influenzate. Alla fine, il consumer non può inviare richieste ad altri servizi, non solo il servizio originale che non risponde.
L'esaurimento delle risorse influisce sui servizi con più consumer. Molte richieste da un client potrebbero esaurire le risorse disponibili nel servizio. L'esaurimento delle risorse può significare che altri consumer non possono utilizzare il servizio, causando un effetto di errore a catena.
Soluzione
Partizionare le istanze del servizio in gruppi diversi in base ai requisiti di carico e disponibilità dei consumer. Questa progettazione consente di isolare gli errori. È possibile sostenere le funzionalità del servizio per alcuni consumatori, anche durante un guasto.
Un consumer può anche partizionare le risorse per assicurarsi che le risorse usate per chiamare un servizio non influiscano sulle risorse usate per chiamare un altro servizio. Ad esempio, a un consumer che chiama più servizi potrebbe essere assegnato un pool di connessioni per ogni servizio. Se un servizio inizia a non riuscire, influisce solo sul pool di connessioni assegnato per tale servizio. Il consumer può continuare a usare altri servizi.
Questo modello offre i vantaggi seguenti:
Isola i consumatori e i servizi dagli errori a catena. Un problema che interessa un consumer o un servizio può essere isolato all'interno della propria paratia per evitare il fallimento dell'intera soluzione.
Mantiene alcune funzionalità se si verifica un errore del servizio. Altri servizi e funzionalità dell'applicazione continuano a funzionare.
Offre livelli di servizio diversi per l'utilizzo delle applicazioni. È possibile configurare un pool di consumer ad alta priorità per l'uso di servizi ad alta priorità.
Il diagramma seguente mostra paratie strutturate intorno a pool di connessioni che chiamano singoli servizi. Se il servizio A ha esito negativo o causa un problema, il pool di connessioni è isolato, quindi sono interessati solo i carichi di lavoro che usano il pool di thread assegnato al servizio A. I carichi di lavoro che usano il servizio B e C non sono interessati e possono continuare a funzionare senza interruzioni.
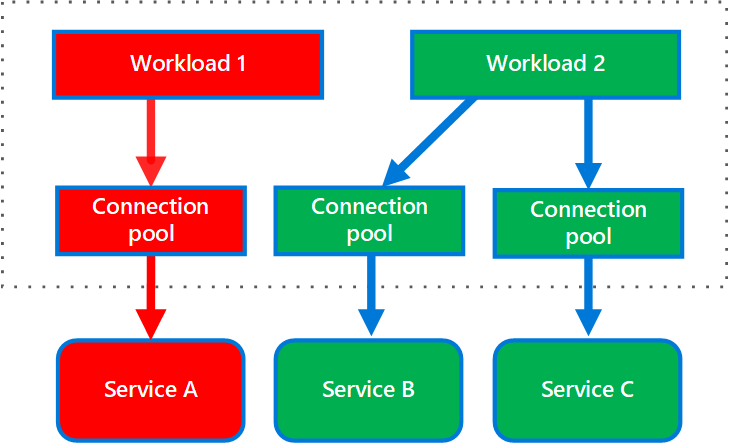
Diagramma che mostra due carichi di lavoro, Carico di lavoro 1 e Carico di lavoro 2 e tre servizi, Servizio A, Servizio B e Servizio C. Il carico di lavoro 1 usa un pool di connessioni assegnato al servizio A. Il carico di lavoro 2 usa due pool di connessioni. Un pool di connessioni viene assegnato al servizio B e l'altro viene assegnato al servizio C. Il pool di connessioni usato dal carico di lavoro 1 è isolato. I pool di connessioni usati dal carico di lavoro 2 possono continuare a chiamare il servizio B e il servizio C.
Il diagramma seguente mostra più client che chiamano un singolo servizio. Ogni client viene assegnato a un'istanza del servizio separata. Il client 1 effettua troppe richieste e ne sovraccarica l'istanza. Poiché ogni istanza del servizio è isolata dalle altre, gli altri client possono continuare a effettuare chiamate.
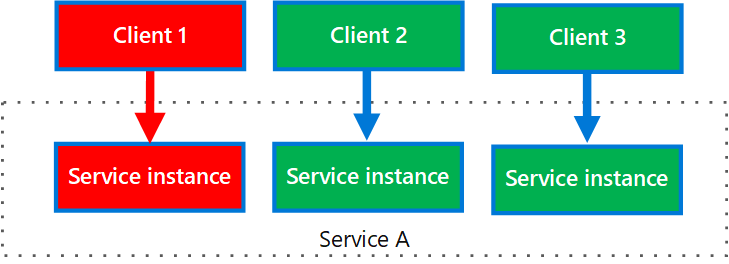
Diagramma che mostra tre client, Client 1, Client 2 e Client 3 e tre istanze del servizio che formano ognuna parte del servizio A. Ogni client si connette alla propria istanza del servizio. Le istanze del servizio sono isolate. Se client 1 sovraccarica l'istanza, i client 2 e 3 non sono interessati.
Problemi e considerazioni
Quando si decide come implementare questo modello, tenere presente quanto segue:
Definire le partizioni in funzione dei requisiti aziendali e tecnici dell'applicazione.
Se si usa la progettazione basata su dominio tattico per progettare microservizi, i limiti delle partizioni devono essere allineati ai contesti delimitati.
Quando si partizionano servizi o clienti in paratie, considerare il livello di isolamento fornito dalla tecnologia e gli oneri in termini di costi, prestazioni e manutenzione.
Per fornire una gestione degli errori più sofisticata, è consigliabile combinare il bulkhead con il pattern di retry, il circuit breaker e il pattern di throttling.
Quando si partizionare i consumatori in compartimenti, è consigliabile usare processi, pool di thread e semafori. Progetti come resilience4j e Polly offrono un framework per la creazione di paratie per i consumatori.
Quando si suddividono i servizi in paratie, è consigliabile distribuirli in macchine virtuali, contenitori o processi separati. I contenitori offrono un buon bilanciamento dell'isolamento delle risorse con un sovraccarico non significativo.
I servizi che comunicano usando messaggi asincroni possono essere isolati tramite diversi insiemi di code. Ogni coda può avere una serie dedicata di istanze che elaborano i messaggi nella coda o un singolo gruppo di istanze che utilizzano un algoritmo per estrarre e avviare l'elaborazione.
Determinare il livello di granularità delle paratie. Ad esempio, se si vogliono distribuire tenant tra partizioni, è possibile inserire ogni tenant in una partizione separata o inserire più tenant in una partizione.
Monitorare le prestazioni e il contratto di servizio di ogni partizione.
Usare i controlli della piattaforma predefiniti, come i limiti di frequenza di Gestione API di Azure, l'isolamento dell'unità richiesta (RU) di Azure Cosmos DB e i limiti delle risorse in Azure Kubernetes Service o in App contenitore di Azure. Non ricreare questi meccanismi di limitazione e isolamento nel codice dell'applicazione.
I carichi di lavoro di IA e inferenza richiedono spesso una rigida separazione delle risorse a causa di quote per distribuzione e limiti di concorrenza. Ad esempio, isolare le distribuzioni di modelli o le risorse Foundry per carico di lavoro o per tenant.
Quando usare questo modello
Usare questo modello quando:
- Si vuole isolare le risorse per dipendenze specifiche in modo che un'interruzione in un servizio non influisca sull'intera applicazione.
- Si desidera isolare i consumatori critici dai consumatori standard.
- È necessario proteggere l'applicazione da errori a catena.
Questo modello potrebbe non essere adatto quando:
- Un uso meno efficiente delle risorse potrebbe non essere accettabile nel progetto.
- La complessità aggiunta non è necessaria.
Progettazione del carico di lavoro
Valutare come usare il modello Bulkhead nella progettazione di un carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. La tabella seguente fornisce indicazioni su come questo modello supporta gli obiettivi di ogni pilastro.
| Pilastro | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resiliente a un malfunzionamento e assicurano che ripristini a uno stato completamente funzionante dopo che si verifica un guasto. | La strategia di isolamento degli errori introdotta tramite la segmentazione intenzionale e completa tra i componenti cerca di contenere i guasti alla paratia che riscontra il problema, impedendo ripercussioni su altre paratie. - Flussi critici RE:02 - RE:07 Autoconservazione |
| Le decisioni di progettazione della sicurezza consentono di garantire la riservatezza, l'integrità e la disponibilità dei dati e dei sistemi del carico di lavoro. | La segmentazione tra i componenti consente di vincolare gli eventi imprevisti di sicurezza alla punta compromessa. - Segmentazione SE:04 |
| l'efficienza delle prestazioni consente al carico di lavoro soddisfare in modo efficiente le richieste tramite ottimizzazioni di ridimensionamento, dati e codice. | Ogni paratia può essere scalata singolarmente per soddisfare in modo efficiente le esigenze dell'attività incapsulata nella paratia stessa. - PE:02 Pianificazione della capacità - PE:05 Ridimensionamento e partizionamento |
Se questo modello introduce compromessi all'interno di un pilastro, considerarli contro gli obiettivi degli altri pilastri.
Esempio
Il file di configurazione Kubernetes seguente crea un contenitore isolato per l'esecuzione di un singolo servizio, con limiti e risorse di CPU e memoria propri.
apiVersion: v1
kind: Pod
metadata:
name: drone-management
spec:
containers:
- name: drone-management-container
image: drone-service
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "1"
Passaggi successivi
- Usare le politiche di limitazione della frequenza per la gestione delle API per controllare la velocità effettiva delle richieste per client.
- Usare i controlli di concorrenza di Funzioni di Azure per limitare le esecuzioni parallele.
- Impostare i limiti delle risorse di App contenitore per controllare la CPU e la memoria per ogni carico di lavoro.
- Assegnare la velocità di throughput RU di Azure Cosmos DB per contenitore per garantire un isolamento prevedibile.