Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Bus di servizio di Azure
Archiviazione code di Azure
Hub eventi di Azure
Controllare la frequenza con cui l'applicazione invia richieste a un servizio in modo da rimanere entro i limiti di limitazione del servizio e la capacità complessiva. Questo approccio consente di evitare o ridurre al minimo gli errori di limitazione e di prevedere in modo più accurato la velocità effettiva.
La limitazione della frequenza è appropriata in molti scenari, ma è particolarmente utile per attività automatizzate ripetitive su larga scala, ad esempio l'elaborazione batch.
Contesto e problema
L'esecuzione di un numero elevato di operazioni tramite un servizio limitato può comportare un aumento del traffico e della velocità effettiva, perché sarà necessario tenere traccia delle richieste rifiutate e quindi ripetere le operazioni. Man mano che aumenta il numero di operazioni, un limite potrebbe richiedere più passaggi di reinvio dei dati, risultando in un maggiore impatto sulle prestazioni.
Si consideri, ad esempio, il seguente semplice processo di nuovo tentativo in caso di errore per l'inserimento dei dati in Azure Cosmos DB:
- L'applicazione deve inserire 10.000 record in Azure Cosmos DB. Ogni record costa 10 Unità di richiesta (RU) per l'acquisizione, per un totale di 100.000 RU necessari a completare l'operazione.
- L'istanza di Azure Cosmos DB ha una capacità di provisioning di 20.000 UR.
- Tutti i 10.000 record vengono inviati ad Azure Cosmos DB. 2.000 record vengono scritti correttamente e vengono rifiutati 8.000 record.
- I rimanenti 8.000 record vengono inviati ad Azure Cosmos DB. 2.000 record vengono scritti correttamente e vengono rifiutati 6.000 record.
- Si inviano i 6.000 record rimanenti ad Azure Cosmos DB. 2.000 record vengono scritti correttamente e vengono rifiutati 4.000 record.
- Si inviano i 4.000 record rimanenti ad Azure Cosmos DB. 2.000 record vengono scritti correttamente e vengono rifiutati 2.000 record.
- Si inviano i 2.000 record rimanenti ad Azure Cosmos DB. Tutti gli elementi sono stati scritti correttamente.
Il processo di inserimento è stato completato correttamente, ma solo dopo l'invio di 30.000 record ad Azure Cosmos DB anche se l'intero set di dati è costituito solo da 10.000 record.
Esistono altri fattori da considerare nell'esempio precedente:
- Un numero elevato di errori può comportare anche operazioni aggiuntive per registrare questi errori ed elaborare i dati di log risultanti. Questo approccio ingenuo avrà gestito 20.000 errori e la registrazione di questi errori potrebbe imporre un costo di elaborazione, memoria o risorsa di archiviazione.
- Non conoscendo i limiti di throttling del servizio di acquisizione, l'approccio semplicistico non è in grado di stimare i tempi necessari per l'elaborazione dei dati. La limitazione della frequenza consente di calcolare il tempo necessario per l'inserimento.
Solution
La limitazione della velocità può ridurre il traffico e migliorare potenzialmente la velocità effettiva riducendo il numero di record inviati a un servizio in un determinato periodo di tempo.
Un servizio può limitare in base a metriche diverse nel tempo, ad esempio:
- Numero di operazioni, ad esempio 20 richieste al secondo.
- Quantità di dati (ad esempio, 2 GiB al minuto).
- Costo relativo delle operazioni (ad esempio, 20.000 UR al secondo).
Indipendentemente dalla metrica usata per la limitazione delle richieste, l'implementazione della limitazione della velocità comporta il controllo del numero e/o delle dimensioni delle operazioni inviate al servizio in un periodo di tempo specifico, ottimizzando l'uso del servizio senza superare la capacità di limitazione.
Negli scenari in cui le API possono gestire le richieste più velocemente rispetto ai servizi di inserimento con limitazione, è necessario gestire la velocità di utilizzo del servizio. Considerare la limitazione solo come una mancata corrispondenza della velocità dei dati e mettere in coda le richieste di inserimento finché il servizio non viene ripristinato crea un rischio. Se l'applicazione si arresta in modo anomalo in questo scenario, eventuali dati memorizzati nel buffer potrebbero andarsi persi.
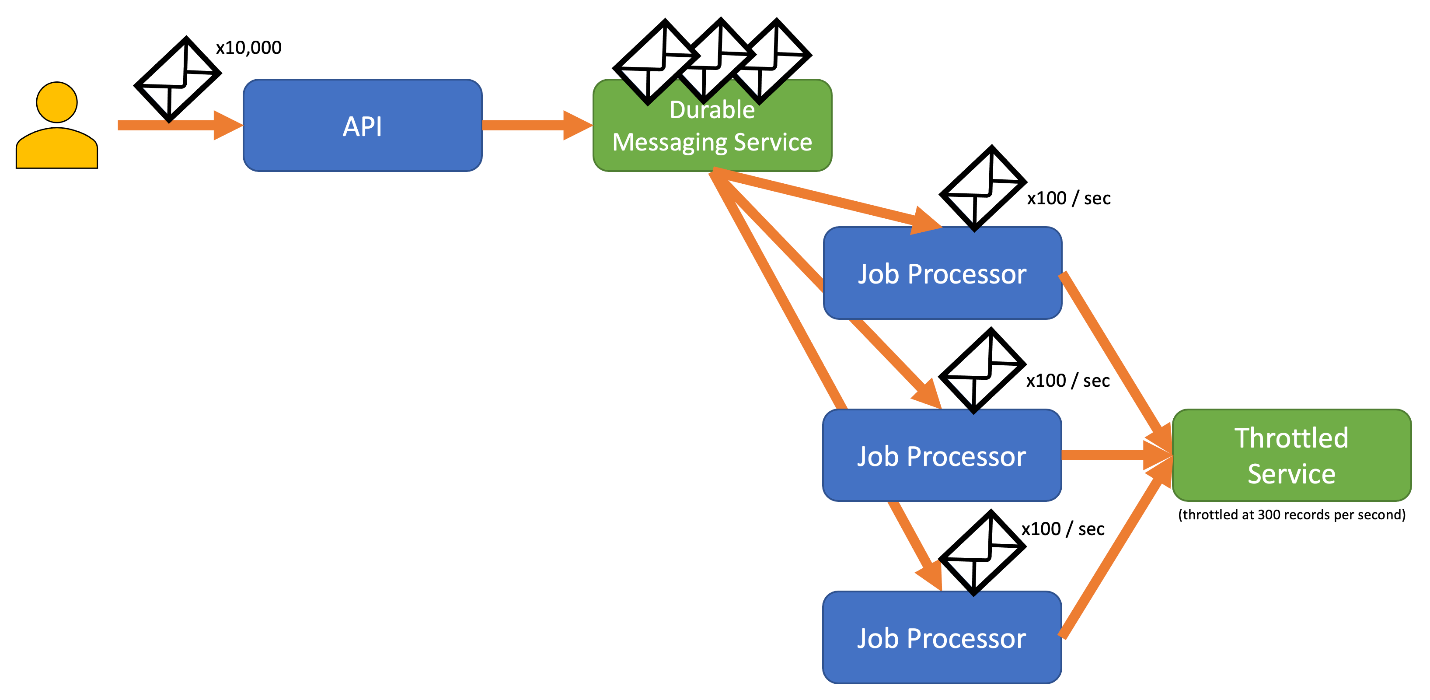
Per evitare questo rischio, valuta l'invio dei record a un sistema di messaggistica affidabile che possa gestire l'intera velocità di acquisizione. (Servizi come Hub eventi di Azure possono gestire milioni di operazioni al secondo). È quindi possibile usare uno o più processori di job per leggere i record dal sistema di messaggistica a una velocità controllata, nel rispetto dei limiti del servizio soggetto a limitazione della velocità. L'invio di record al sistema di messaggistica può far risparmiare memoria interna, permettendo di prelevare dalla coda solo i record che possono essere elaborati in un determinato intervallo di tempo.
Azure offre diversi servizi di messaggistica durevole che è possibile usare con questo modello, tra cui:
Quando si inviano record, il periodo di tempo utilizzato per il rilascio dei record potrebbe essere più dettagliato rispetto al periodo in cui il servizio applica limitazioni. I sistemi spesso impostano limitazioni in base agli intervalli di tempo con cui è possibile comprendere e lavorare facilmente. Tuttavia, per il computer che esegue un servizio, questi intervalli di tempo potrebbero essere molto lunghi rispetto alla velocità di elaborazione delle informazioni. Ad esempio, un sistema potrebbe applicare una limitazione al secondo o al minuto, ma in genere il codice viene eseguito nell'ordine dei nanosecondi o dei millisecondi.
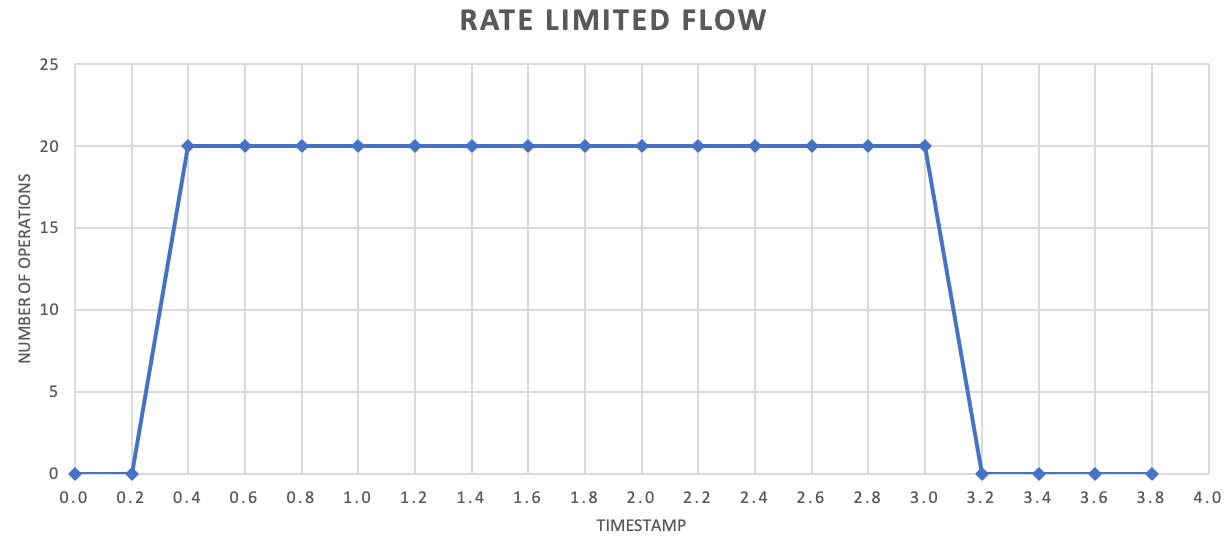
Sebbene non sia necessario, è spesso consigliabile inviare quantità di record più piccole con maggiore frequenza per migliorare la velocità effettiva. Pertanto, invece di provare a raggruppare le operazioni per un rilascio una volta al secondo o una volta al minuto, si può adottare un approccio più granulare per mantenere il consumo di risorse (memoria, CPU e rete) in modo più uniforme, impedendo potenziali colli di bottiglia a causa di esplosioni improvvise di richieste. Ad esempio, se un servizio consente 100 operazioni al secondo, l'implementazione di un limite di velocità potrebbe persino ridurre le richieste rilasciando 20 operazioni ogni 200 millisecondi, come illustrato nel grafico seguente.
Inoltre, a volte è necessario per più processi non coordinati condividere un servizio limitato. Per implementare la limitazione della frequenza in questo scenario, è possibile partizionare logicamente la capacità del servizio e quindi usare un sistema di esclusione reciproca distribuito per gestire blocchi esclusivi su tali partizioni. I processi non coordinati possono quindi competere per i blocchi su tali partizioni ogni volta che hanno bisogno di capacità. Per ogni partizione per la quale un processo detiene un lock, viene assegnata una certa quantità di capacità.
Ad esempio, se il sistema soggetto a limitazione consente 500 richieste al secondo, è possibile creare 20 partizioni da 25 richieste al secondo ciascuna. Se un processo dovesse effettuare 100 richieste, potrebbe chiedere al sistema di esclusione reciproca distribuita quattro partizioni. Il sistema potrebbe concedere due partizioni per 10 secondi. Il processo quindi limita a 50 richieste al secondo, completa l'attività in due secondi e quindi rilascia il blocco.
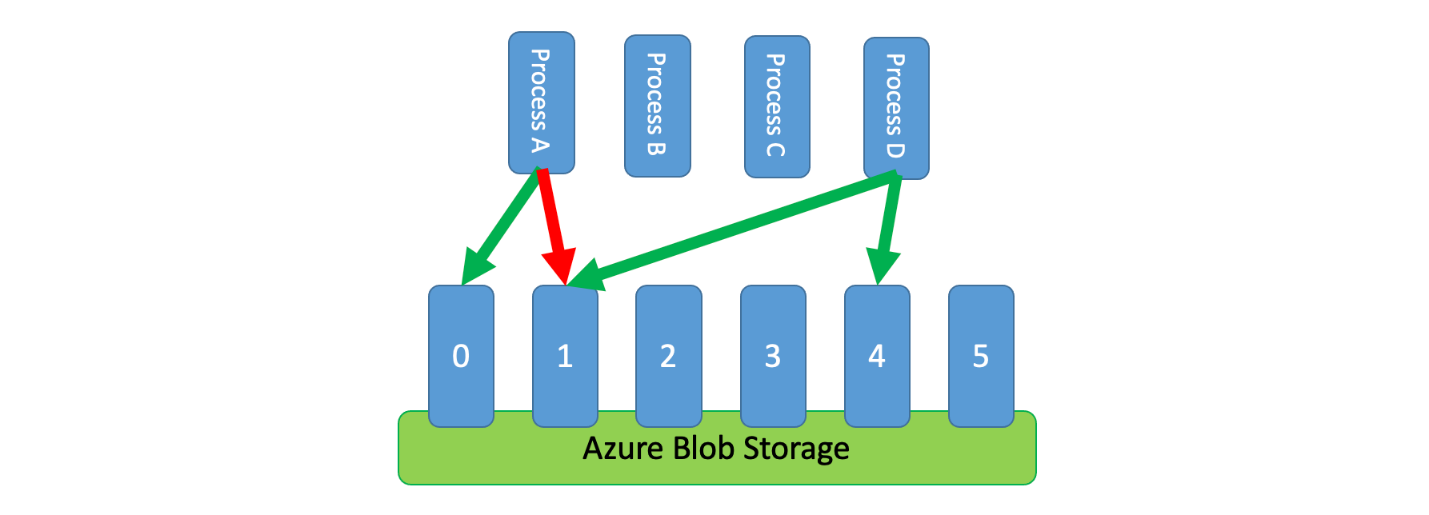
Un modo per implementare questo modello consiste nell'usare Archiviazione di Azure. In questo scenario viene creato un BLOB a 0 byte per ogni partizione logica in un contenitore. Le applicazioni possono quindi ottenere contratti di leasing esclusivi direttamente su tali BLOB per un breve periodo di tempo (ad esempio, 15 secondi). Per ogni lease concesso a un'applicazione, questa sarà in grado di utilizzare la capacità di quella partizione. L'applicazione deve quindi tenere traccia del tempo di lease in modo che, alla scadenza, possa smettere di usare la capacità concessa. Quando si implementa questo schema, spesso è opportuno che ogni processo tenti di acquisire un lease su una partizione casuale quando necessita di capacità.
Per ridurre ulteriormente la latenza, è possibile allocare una piccola quantità di capacità esclusiva per ogni processo. Un processo cercherebbe quindi di ottenere un lease per la capacità condivisa solo se avesse bisogno di superare la capacità riservata.
In alternativa a Archiviazione di Azure, è anche possibile implementare questo tipo di sistema di gestione dei lease utilizzando tecnologie come Zookeeper, Consul, etcd, Redis/Redsync e altre.
Considerazioni e problemi
Quando si decide come implementare questo modello, tenere presente quanto segue:
- Anche se il modello di limitazione della frequenza può ridurre il numero di errori di limitazione, l'applicazione dovrà comunque gestire correttamente eventuali errori di limitazione che potrebbero verificarsi.
- Se l'applicazione ha più flussi di lavoro che accedono allo stesso servizio limitato, sarà necessario integrarli tutti nella strategia di limitazione della frequenza. Ad esempio, è possibile supportare il caricamento bulk di record in un database, ma anche l'esecuzione di query per i record nello stesso database. È possibile gestire la capacità assicurando che tutti i flussi di lavoro vengano gestiti tramite lo stesso meccanismo di limitazione della velocità. In alternativa, è possibile riservare pool di capacità separati per ogni flusso di lavoro.
- Il servizio limitato potrebbe essere usato in più applicazioni. In alcuni casi, ma non tutti, è possibile coordinare tale utilizzo (come illustrato in precedenza). Se si inizia a visualizzare un numero di errori di limitazione superiore al previsto, potrebbe trattarsi di un segno di contesa tra le applicazioni che accedono a un servizio. In tal caso, potrebbe essere necessario prendere in considerazione la riduzione temporanea della velocità effettiva imposta dal meccanismo di limitazione della velocità fino a quando l'utilizzo di altre applicazioni non diminuisce.
Quando usare questo modello
Usare questo modello per:
- Ridurre gli errori generati da un servizio soggetto a limitazione della frequenza.
- Ridurre il traffico rispetto a un approccio che prevede un nuovo tentativo in caso di errore.
- Ridurre il consumo di memoria rimuovendo i record dalla coda solo quando vi è capacità sufficiente per elaborarli.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello di limitazione della frequenza può essere usato nella progettazione del carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Per esempio:
| Pillar | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| Le decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resilienti a malfunzionamenti e di assicurarsi che venga ripristinato in uno stato completamente funzionante dopo che si verifica un errore. | Questa tattica protegge il client riconoscendo e rispettando le limitazioni e i costi di comunicazione con un servizio quando il servizio desidera evitare un utilizzo eccessivo. - RE:07 Autoconservazione |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Example
L'applicazione di esempio seguente consente agli utenti di inviare record di vari tipi a un'API. È disponibile un processore di processi univoco per ogni tipo di record che esegue i passaggi seguenti:
- Validation
- Enrichment
- Inserimento del record nel database
Tutti i componenti dell'applicazione (API, processore di processi A e processore di processi B) sono processi separati che possono essere ridimensionati in modo indipendente. I processi non comunicano direttamente tra loro.
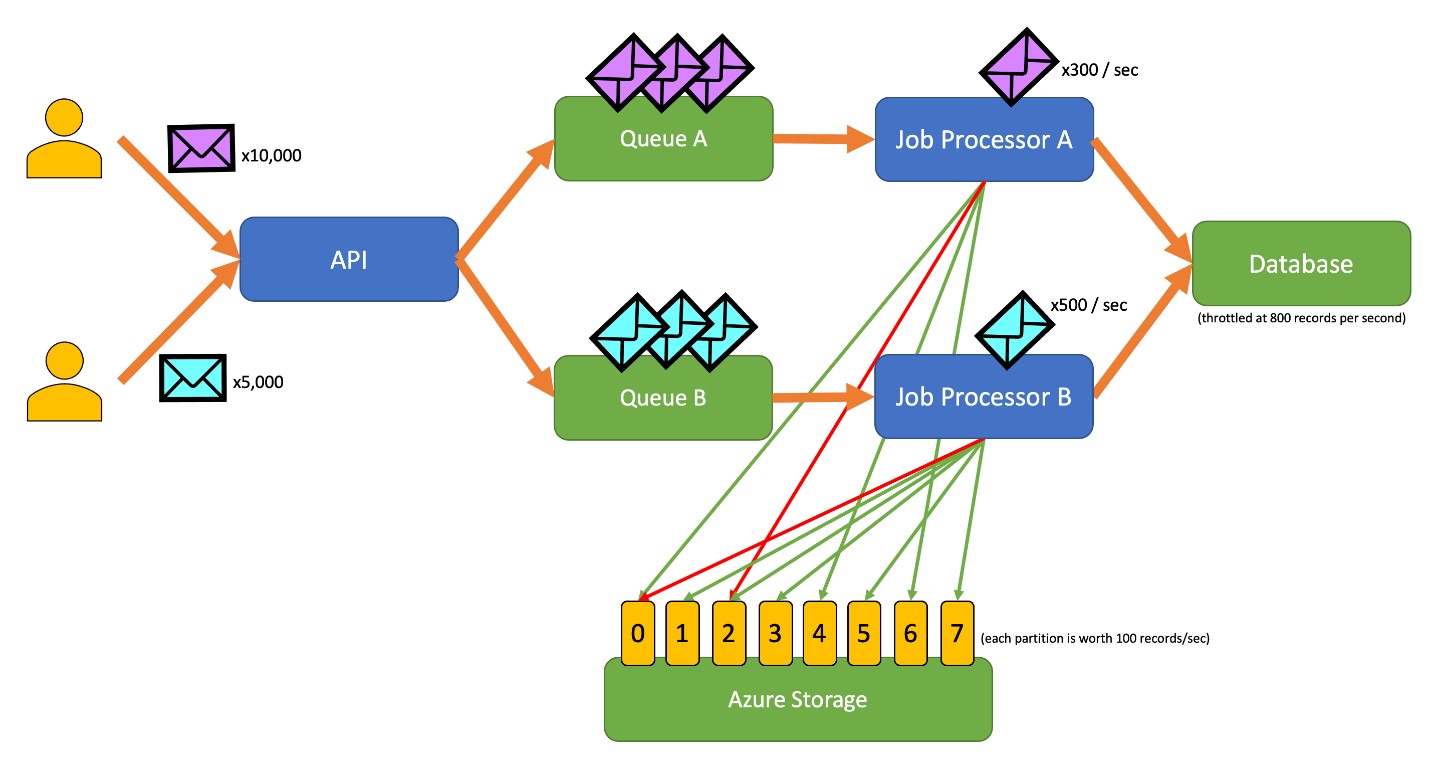
Questo diagramma incorpora il flusso di lavoro seguente:
- Un utente invia 10.000 record di tipo A all'API.
- L'API accoda tali 10.000 record nella coda A.
- Un utente invia 5.000 record di tipo B all'API.
- L'API accoda tali 5.000 record nella coda B.
- Il processore A vede che la coda A contiene record e tenta di acquisire un lease esclusivo sul blob 2.
- L'elaboratore di processi B vede che la coda B contiene record e tenta di ottenere un lease esclusivo sul blob 2.
- Processore di processi A non riesce a ottenere il lease.
- Il processore di processi B ottiene il lease sul blob 2 per 15 secondi. Ora può limitare le richieste al database a una velocità di 100 al secondo.
- Il processore di job B estrae 100 record dalla coda B e li scrive.
- Un secondo passa.
- Il processore di processi A vede che la coda A contiene più record e cerca di ottenere un lease esclusivo sul BLOB 6.
- Il processore B vede che la coda B contiene più record e tenta di acquisire un lease esclusivo sul blob 3.
- Job Processor A ottiene il lease sul blob 6 per 15 secondi. Ora può limitare le richieste al database a una velocità di 100 al secondo.
- Il processore di processi B acquisisce il lease sul blob 3 per 15 secondi. Ora può limitare le richieste al database a una velocità di 200 al secondo. Contiene anche il lease per BLOB 2.
- Il processore di job A preleva 100 record dalla coda A e li scrive.
- Job Processor B preleva 200 record dalla coda B e li scrive.
- Un secondo passa.
- Il processore di processi A vede che la coda A contiene più record e cerca di ottenere un lease esclusivo sul blob 0.
- L'elaboratore di processi B vede che nella coda B sono presenti altri record e tenta di ottenere un lease esclusivo sul blob 1.
- Il processore di processi A ottiene il lease sul blob 0 per 15 secondi. Ora può limitare le richieste al database a una velocità di 200 al secondo. Contiene anche il lease per BLOB 6.
- Il processore processi B ottiene il lease sul blob 1 per 15 secondi. Ora può limitare le richieste al database a una velocità di 300 al secondo. Detiene anche il lease per i blob 2 e 3.
- Il processore di job A preleva 200 record dalla coda A e li scrive.
- Il processore B preleva 300 record dalla coda B e li scrive.
- E così via.
Dopo 15 secondi, uno o entrambi i processi non verranno ancora completati. Man mano che i lease scadono, un processore deve anche ridurre il numero di richieste che preleva dalla coda e scrive.
 Le implementazioni di questo modello sono disponibili in linguaggi di programmazione diversi:
Le implementazioni di questo modello sono disponibili in linguaggi di programmazione diversi:
" output is necessary.)
Per l'implementazione di questo modello possono risultare utili i modelli e le informazioni aggiuntive seguenti:
- Throttling. Il modello di limitazione della velocità descritto di seguito viene in genere implementato in risposta a un servizio limitato.
- Retry. Quando le richieste a un servizio soggetto a limitazione generano errori di throttling, è in genere opportuno ripetere tali richieste dopo aver atteso un intervallo appropriato.
Il livellamento del carico basato sulle code è simile, ma differisce dal pattern di limitazione della frequenza per diversi aspetti fondamentali:
- La limitazione della frequenza non deve necessariamente usare le code per gestire il carico, ma deve usare un servizio di messaggistica durevole. Ad esempio, un modello di limitazione della frequenza può usare servizi come Apache Kafka o Hub eventi di Azure.
- Il modello di limitazione della frequenza introduce il concetto di un sistema distribuito di esclusione reciproca tra partizioni, che consente di gestire la capacità disponibile per più processi non coordinati che comunicano con lo stesso servizio soggetto a limitazione della frequenza.
- Un modello di livellamento del carico basato su coda è applicabile ogni volta che si verifica una mancata corrispondenza delle prestazioni tra i servizi o per migliorare la resilienza. In questo modo è un modello più ampio rispetto alla limitazione della frequenza, che è più specificamente interessato all'accesso efficiente a un servizio limitato.