Panoramica della continuità aziendale con Istanza gestita di SQL di Azure
Si applica a: ![]() Istanza gestita di SQL di Azure SQL
Istanza gestita di SQL di Azure SQL
Il presente articolo offre una panoramica delle funzionalità di continuità aziendale e ripristino di emergenza del database SQL di Azure, descrivendo le opzioni e le raccomandazioni per il ripristino da eventi di interruzione che potrebbero causare la perdita di dati o causare la mancata disponibilità del database e dell'applicazione. Informazioni sulle operazioni da eseguire quando si verifica un errore generato da un utente o da un'applicazione che influisce sull'integrità dei dati, se in una zona di disponibilità di Azure si verifica un'interruzione o quando l'applicazione richiede manutenzione.
Panoramica
La continuità aziendale nell’Istanza gestita di SQL di Azure si riferisce ai meccanismi, ai criteri e alle procedure che consentono all'azienda di continuare a funzionare in caso di interruzione fornendo disponibilità, disponibilità elevata e ripristino di emergenza.
Nella maggior parte dei casi, l’istanza gestita di SQL di Azure gestirà le interruzioni che potrebbero verificarsi nell'ambiente cloud e manterrà le applicazioni e i processi aziendali in esecuzione. Esistono tuttavia alcuni eventi di interruzione in cui la mitigazione potrebbe richiedere del tempo, ad esempio:
- Un utente elimina o aggiorna accidentalmente una riga in una tabella.
- Un utente malintenzionato riesce a eliminare dati o database.
- Un evento di emergenza naturale irreversibile arresta un data center o una zona o area di disponibilità.
- Rara interruzione di data center, zona di disponibilità o a livello di area causata da una modifica della configurazione, un bug software o un errore del componente hardware.
Disponibilità
Istanza gestita di SQL di Azure viene fornito con una promessa di resilienza e affidabilità di base che la protegge da errori software o hardware. I backup sono automatizzati per proteggere i tuoi dati dal danneggiamento o dall’eliminazione accidentale. Come servizio PaaS (Platform-as-a-Service), il servizio Istanza gestita di SQL di Azure offre disponibilità come funzionalità off-the-shelf con un contratto di servizio di disponibilità leader del settore del 99,99%.
Disponibilità elevata
Per ottenere disponibilità elevata nell'ambiente cloud di Azure, abilitare la ridondanza della zona in modo che l'istanza usi le zone di disponibilità per garantire la resilienza agli errori di zona. Molte aree di Azure forniscono zone di disponibilità, che sono gruppi separati di data center all'interno di un'area con un'infrastruttura di rete, raffreddamento e alimentazione indipendente. Le zone di disponibilità sono progettate per fornire servizi, capacità e disponibilità elevata nelle zone rimanenti in caso di interruzione di un'area. L'abilitazione della ridondanza della zona garantisce che l’istanza sia resiliente agli errori hardware e software di zona e che il recupero sia trasparente per le applicazioni. Quando la disponibilità elevata è abilitata, il servizio Istanza gestita di SQL di Azure è in grado di fornire un contratto di servizio di disponibilità superiore del 99,99%.
Ripristino di emergenza
Per ottenere una maggiore disponibilità e ridondanza tra aree, è possibile abilitare le funzionalità di ripristino di emergenza per ripristinare rapidamente l'istanza da un errore irreversibile a livello di area. Opzioni del ripristino di emergenza per l’Istanza gestita di SQL di Azure:
- I gruppi di failover consentono la sincronizzazione continua tra un'istanza primaria e secondaria. I gruppi di failover forniscono endpoint listener in lettura/scrittura e di sola lettura che rimangono invariati, quindi l'aggiornamento delle stringa di connessione dell'applicazione dopo il failover non è necessario.
- Il ripristino geografico consente di eseguire il ripristino da un'interruzione a livello di area ripristinando i backup con replica geografica quando non è possibile accedere al database nell'area primaria creando un nuovo database in qualsiasi istanza esistente in qualsiasi area di Azure.
Funzionalità che offrono la continuità aziendale
Per un'istanza, esistono quattro principali scenari di interruzione potenziali. La tabella seguente elenca Istanza gestita di SQL funzionalità di continuità aziendale che è possibile usare per attenuare un potenziale scenario di interruzione dell'azienda:
| Scenario di interruzione aziendale | Funzionalità per la continuità aziendale |
|---|---|
| Guasti hardware o errori software locali che interessano il nodo del database. | Per attenuare gli errori hardware e software locali, Istanza gestita di SQL include un'architettura di disponibilità, che garantisce il ripristino automatico da questi errori con un contratto di servizio di disponibilità fino al 99,99%. |
| Il danneggiamento o l'eliminazione di dati causati in genere da un bug dell'applicazione o da un errore umano. Questi errori sono specifici dell'applicazione e in genere non possono essere rilevati dal servizio. | Per proteggere l’attività dalla perdita di dati, l’istanza gestita di SQL di Azure database crea automaticamente una combinazione di backup completi del database su base settimanale, backup differenziali del database (ogni 12 ore o 24 ore) e backup dei log delle transazioni ogni 5-10 minuti. Per impostazione predefinita, i backup vengono archiviati nell'archiviazione con ridondanza geografica per sette giorni e supportano un periodo di conservazione dei backup configurabile per il ripristino temporizzato fino a 35 giorni. È possibile ripristinare il database eliminato al punto in cui è stato eliminato se l'istanza non è stata eliminata, o se è stata configurata una conservazione a lungo termine. |
| Rara interruzione del data center o della zona di disponibilità, probabilmente causata da un evento di emergenza naturale, modifiche alla configurazione, bug software o errore del componente hardware. | Per attenuare l'interruzione a livello di data center o di zona di disponibilità, abilitare la ridondanza della zona per l’Istanza gestita di SQL usare le zone di disponibilità di Azure e garantire la ridondanza in più zone fisiche all'interno di un'area di Azure. L'abilitazione della ridondanza della zona garantisce che l'istanza gestita sia resiliente agli errori di zona con un contratto di servizio con disponibilità elevata fino al 99,99%. |
| Rara interruzione dell'area che influisce su tutte le zone di disponibilità e sui data center che la comprendono, probabilmente causata da un evento di emergenza naturale irreversibile. | Per ridurre un'interruzione a livello di area, abilitare il ripristino di emergenza usando una delle opzioni seguenti: - Sincronizzazione continua dei dati con gruppi di failover nelle repliche in un'area secondaria usata per il failover. - Impostazione della ridondanza dell'archivio di backup nell'archivio di backup con ridondanza geografica per l'uso del ripristino geografico. |
RTO e RPO
Quando si sviluppa il piano di continuità aziendale, è necessario conoscere il tempo massimo accettabile prima che l'applicazione venga ripristinata completamente dopo l'evento di arresto. Il tempo necessario per un ripristino completo dell'applicazione è noto come obiettivo del tempo di ripristino (RTO). È anche necessario conoscere la perdita massima di aggiornamenti di dati recenti (intervallo di tempo) che l'applicazione è in grado di tollerare durante il ripristino dopo l'evento di arresto improvviso. La potenziale perdita di dati è conosciuta come obiettivo del punto di ripristino (RPO).
La tabella seguente confronta RPO e RTO di ciascuna opzione di continuità aziendale:
| Opzione per la continuità aziendale | RTO (tempo di inattività) | RPO (perdita di dati) |
|---|---|---|
| Disponibilità elevata (usando la ridondanza della zona) |
Generalmente meno di 30 secondi | 0 |
| Ripristino di emergenza (usando gruppi di failover con criteri di failover gestiti dal cliente) |
Generalmente meno di 60 secondi | Uguale o maggiore a 0 (dipende dalle modifiche ai dati prima dell'evento di interruzione che non è stato replicato) |
| Ripristino di emergenza (con il ripristino geografico) |
12 ore | 1 ora |
Elenchi di controllo per continuità aziendale
Per consigli prescrittivi per ottimizzare la disponibilità e ottenere una maggiore continuità aziendale, consultare:
- Elenco di controllo della disponibilità
- Elenco di controllo per la disponibilità elevata
- Elenchi di controllo per il ripristino di emergenza
Ripristinare un database all'interno della stessa area di Azure
È possibile utilizzare i backup automatici per ripristinare un database a un momento specifico nel passato. In questo modo è possibile eseguire il ripristino da danneggiamenti dei dati causati da errori umani. Il ripristino temporizzato consente di creare un nuovo database nella stessa istanza o in un'istanza diversa, che rappresenta lo stato dei dati prima dell'evento danneggiato. L'operazione di ripristino è una dimensione dell'operazione di dati che dipende anche dal carico di lavoro corrente dell'istanza di destinazione. Potrebbe essere necessario più tempo per ripristinare un database attivo o di dimensioni molto estese. Per altre informazioni sui tempi di ripristino, vedere il tempo di ripristino dei database.
Se il periodo di conservazione massimo del backup supportato del ripristino temporizzato non è sufficiente per l'applicazione, è possibile estenderlo configurando i criteri di conservazione a lungo termine per il database. Per altre informazioni, vedere Conservazione dei backup a lungo termine.
Ripristinare un database in un’istanza esistente
Anche se raramente, un data center di Azure può subire un'interruzione del servizio. Quando si verifica un'interruzione, viene generata un'interruzione delle attività che potrebbe durare solo pochi minuti oppure ore.
- Una delle opzioni è attendere che l’istanza torni online al termine dell'interruzione del data center. Questa opzione funziona per le applicazioni che possono rimanere con il database offline. Ad esempio, un progetto di sviluppo o una versione di valutazione gratuita su cui non è necessario lavorare costantemente. Quando un data center registra un'interruzione del servizio, non si sa quanto tempo essa durerà. Pertanto, questa opzione funziona solo se è possibile rinunciare al database per un periodo di tempo.
- Se si usa l'archiviazione con ridondanza geografica o con ridondanza geografica della zona (GZRS), un'altra opzione consiste nel ripristinare un database in qualsiasi istanza gestita di SQL in qualsiasi area di Azure usando backup di database con ridondanza geografica (ripristino geografico). Il ripristino geografico usa un backup con ridondanza geografica come origine e può essere usato per ripristinare un database nell’ultimo punto disponibile nel tempo, anche se il database o il data center è inaccessibile a causa di un'interruzione del servizio. Il backup disponibile si trova nell'area abbinata.
- Infine, è possibile eseguire rapidamente il ripristino da un'interruzione se è stato configurato un database secondario geografico usando un gruppo di failover per l'istanza, usando il cliente (scelta consigliata) o il failover gestito da Microsoft. Anche se il failover stesso richiede solo pochi secondi, il servizio richiede almeno 1 ora per attivare un failover geografico gestito da Microsoft, se configurato. Questo passaggio è necessario per assicurarsi che il failover sia giustificato dalla portata dell'interruzione. Inoltre, il failover potrebbe comportare la perdita di dati modificati di recente a causa della natura della replica asincrona tra le aree abbinate.
Quando si sviluppa il piano di continuità aziendale, è necessario conoscere il tempo massimo accettabile prima che l'applicazione venga ripristinata completamente dopo l'evento di arresto improvviso. Il tempo necessario per un ripristino completo dell'applicazione è noto come obiettivo del tempo di ripristino (RTO). È anche necessario conoscere la perdita massima di aggiornamenti di dati recenti (intervallo di tempo) che l'applicazione è in grado di tollerare durante il ripristino dopo l'evento di arresto improvviso e non pianificato. La potenziale perdita di dati è nota come obiettivo del punto di ripristino (RPO).
Diversi metodi di ripristino offrono livelli diversi di RPO e RTO. È possibile scegliere un metodo di recupero specifico oppure usare una combinazione di metodi per ottenere il recupero completo dell'applicazione.
Usare i gruppi di failover se l'applicazione soddisfa uno qualsiasi dei criteri seguenti:
- È considerata cruciale.
- Ha un contratto di servizio che non consente 12 ore o più di tempo inattivo.
- Il tempo di inattività può implicare responsabilità finanziaria.
- Ha un'elevata frequenza di modifica dei dati e una perdita di dati di un'ora non è accettabile.
- Il costo aggiuntivo della replica geografica attiva è inferiore rispetto alla potenziale responsabilità finanziaria e alla perdita di profitto associata.
È possibile scegliere di usare una combinazione di backup del database e gruppi di failover a seconda dei requisiti dell'applicazione.
Le sezioni seguenti forniscono una panoramica della procedura per eseguire il ripristino tramite backup del database o gruppi di failover.
Prepararsi a un'interruzione del servizio
Indipendentemente dalla funzionalità di continuità aziendale in uso, è necessario:
- Identificare e preparare il server di destinazione, tra cui le regole del firewall IP a livello rete, gli accessi e le autorizzazioni a livello di database
master. - Stabilire come verranno reindirizzati i client e le applicazioni client verso la nuova istanza
- Documentare altre dipendenze, ad esempio impostazioni di controllo e avvisi
Se non ci si prepara adeguatamente al ripristino, riportare online le applicazioni dopo un failover o un ripristino del database richiederà ulteriore tempo e probabilmente richiederà la risoluzione di problemi aggiuntivi in un momento di stress: una combinazione da evitare.
Failover a un’istanza secondaria con replica geografica
Se si usano i gruppi con failover automatico come meccanismo di ripristino, è possibile configurare un criterio di failover automatico. Una volta avviato, il failover fa sì che l’istanza secondaria venga alzata di livello come nuova istanza primaria e sia pronta per registrare nuove transazioni e rispondere a tutte le query, con una perdita di dati minima per i dati non ancora replicati.
Nota
Quando il data center ritorna in linea, l’istanza primaria precedente si ricollega automaticamente alla nuova primaria per diventare l’istanza secondaria. Se si desidera spostare di nuovo il database primario nell'area originale è possibile avviare manualmente un failover pianificato (failback).
Eseguire un ripristino geografico
Se si usano i backup automatici con l'archiviazione con ridondanza geografica (l’opzione di archiviazione predefinita quando si crea la propria istanza), è possibile ripristinare il database tramite il ripristino geografico. In genere il ripristino avviene entro 12 ore, con una perdita di dati fino a 1 ora, a seconda dell'ultima acquisizione e replica del backup del log. Fino a quando non viene completato il ripristino, il database non è in grado di registrare tutte le transazioni o rispondere a tutte le query. Si noti che il ripristino geografico consente solo di ripristinare il database al punto di ripristino più recente disponibile.
Nota
Se il data center ritorna online prima che l'applicazione venga spostata sul database ripristinato, è possibile annullare il ripristino.
Eseguire attività successive al filover/ripristino
Dopo il ripristino da un meccanismo di ripristino, è necessario eseguire le seguenti attività aggiuntive prima che utenti e applicazioni siano nuovamente attivi e in esecuzione:
- Reindirizzare i client e le applicazioni client verso la nuova istanza e il database ripristinato.
- Verificare che siano presenti le regole del firewall IP di rete appropriate per la connessione degli utenti.
- Verificare che siano presenti gli account di accesso appropriato e le autorizzazioni
mastera livello di database (o usare gli utenti contenuti). - Configurare il controllo in base alle proprie esigenze.
- Configurare gli avvisi in base alle proprie esigenze.
Nota
Se si usa un gruppo di failover e ci si connette all’istanza mediante il listener di lettura/scrittura, il reindirizzamento dopo il failover verrà eseguito automaticamente e in modo trasparente per l'applicazione.
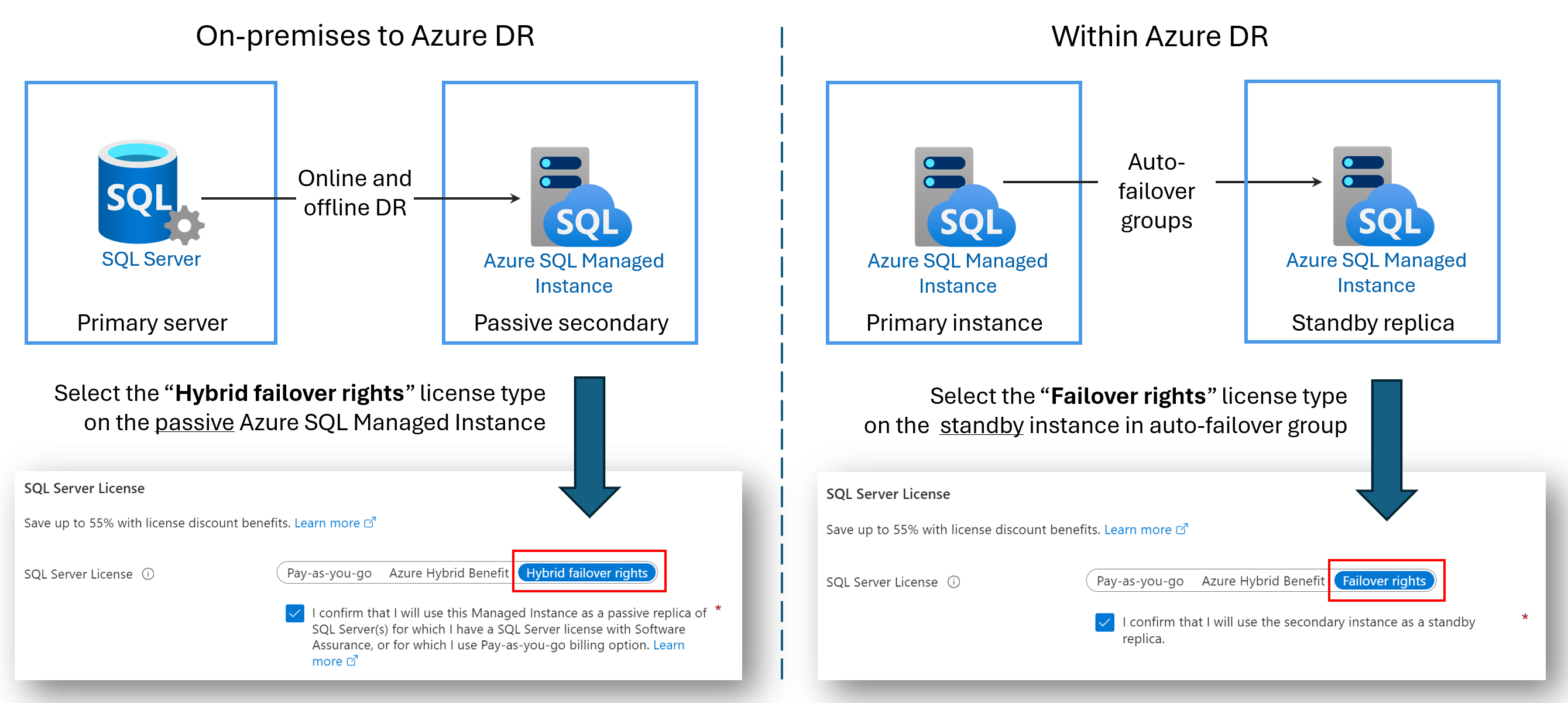
Repliche di ripristino di emergenza senza licenza
È possibile risparmiare sui costi di licenza configurando un’Istanza gestita di SQL di Azure secondario solo per il ripristino di emergenza. Questo vantaggio è disponibile se si usa un gruppo di failover tra due istanze gestite di SQL oppure è stato configurato un collegamento ibrido tra SQL Server e Istanza gestita di SQL di Azure. Purché l'istanza secondaria non disponga di carichi di lavoro di lettura o scrittura e che sia solo uno standby di ripristino di emergenza passivo, non vengono addebitati i costi di licenza vCore usati dall'istanza secondaria.
Quando si designa un'istanza secondaria solo per il ripristino di emergenza e non vengono eseguiti carichi di lavoro di lettura o scrittura nell'istanza, Microsoft fornisce all'utente il numero di vCore concessi in licenza all'istanza primaria senza costi aggiuntivi ai fini dei diritti di failover. Viene comunque addebitato il costo per la risorsa di calcolo e quella di archiviazione usate dall'istanza secondaria. Per termini e condizioni precisi del vantaggio dei diritti di failover ibrido, vedere le condizioni di licenza di SQL Server online nella sezione "SQL Server – Diritti di failover".
Il nome del vantaggio dipende dallo scenario:
- Diritti di failover ibridi per una replica passiva: quando si configura un collegamento tra SQL Server e Istanza gestita di SQL di Azure, è possibile usare il vantaggio dei diritti di failover ibridi per risparmiare sui costi di licenza vCore per la replica secondaria passiva.
- Diritti di failover per una replica standby: quando si configura un gruppo di failover tra due istanze gestite, è possibile usare il vantaggio Diritti di failover per risparmiare sui costi di licenza vCore per la replica secondaria di standby.
Il diagramma seguente illustra il vantaggio per ogni scenario:
Passaggi successivi
Per altre informazioni sulle funzionalità di continuità aziendale, vedere Backup automatizzati e gruppi di failover. Per il ripristino di emergenza, si veda Ripristinare un database e abilitare la ridondanza della zona per Istanza gestita di SQL di Azure.