Resilienza e ripristino di emergenza nel servizio Web PubSub di Azure
La resilienza e il ripristino di emergenza sono un'esigenza comune per i sistemi online. Il servizio Web PubSub di Azure garantisce già la disponibilità del 99,9%, ma è ancora un servizio a livello di area. Quando si verifica un'interruzione a livello di area, è fondamentale che il servizio continui a elaborare i messaggi in tempo reale in un'area diversa.
Per il ripristino di emergenza a livello di area, è consigliabile adottare i due approcci seguenti:
- Abilitare la replica geografica (modo semplice). Questa funzionalità gestirà automaticamente il failover a livello di area. Se abilitata, rimane solo un'istanza di Azure SignalR e non vengono introdotte modifiche al codice. Controllare la replica geografica per informazioni dettagliate.
- Usare più endpoint. Informazioni su come eseguire questa operazione in questo documento
Architettura a disponibilità elevata per il servizio Web PubSub
Esistono due modelli tipici che usano il servizio Web PubSub:
- Uno è il modello client-server che i client inviano eventi al server e il server esegue il push dei messaggi ai client.
- Un altro è il modello client-client che i client pubblicano/sub messaggi tramite il servizio Web PubSub ad altri client.
Le sezioni seguenti descrivono diversi modi per eseguire il ripristino di emergenza in questi due modelli
Architettura a disponibilità elevata per il modello client-server
Per avere resilienza tra aree per il servizio Web PubSub, è necessario configurare più istanze del servizio in aree diverse. In questo modo, quando un'area è inattiva è possibile usare le altre come backup.
Una configurazione tipica per uno scenario tra aree consiste nell'avere due o più coppie di istanze del servizio Web PubSub e server app.
All'interno di ogni server app di coppia e servizio Web PubSub si trovano nella stessa area e il servizio Web PubSub imposta il gestore eventi upstream sul server app nella stessa area.
Per illustrare meglio l'architettura, chiamiamo servizio Web PubSub il servizio primario al server app nella stessa coppia. E chiamiamo servizi Web PubSub in altre coppie come servizi secondari al server app.
Il server applicazioni può usare l'API controllo integrità dei servizi per rilevare se i servizi primari e secondari sono integri o meno. Ad esempio, per un servizio Web PubSub denominato demo, l'endpoint https://demo.webpubsub.azure.com/api/health restituisce 200 quando il servizio è integro. Il server app può chiamare periodicamente gli endpoint o chiamare gli endpoint su richiesta per verificare se gli endpoint sono integri. I client WebSocket negoziano in genere con il server applicazioni prima di ottenere l'URL che si connette al servizio Web PubSub e l'applicazione usa questo passaggio di negoziazione per eseguire il failover dei client ad altri servizi secondari integri. Procedura dettagliata come indicato di seguito:
- Quando un client negozia con il server app, il server app DEVE restituire solo gli endpoint di servizio Web PubSub primari, in modo normale che i client si connettano solo agli endpoint primari.
- Quando l'istanza primaria è inattiva, negoziare DOVREBBE restituire un endpoint secondario integro in modo che il client possa comunque stabilire connessioni e il client si connette all'endpoint secondario.
- Quando l'istanza primaria è in funzione, negoziare DOVREBBE restituire l'endpoint primario integro in modo che i client possano ora connettersi all'endpoint primario
- Quando il server dell'app trasmettei messaggi, DOVREBBE trasmettere messaggi a tutti gli endpoint integri , inclusi i messaggi primari e secondari.
- Il server app può chiudere le connessioni connesse agli endpoint secondari per forzare la riconnessione dei client all'endpoint primario integro.
Con questa topologia, è comunque possibile recapitare un messaggio da un server a tutti i client, perché tutti i server app e le istanze del servizio Web PubSub sono interconnessi.
Non è ancora stata integrata la strategia nell'SDK, quindi per il momento l'applicazione deve implementare questa strategia da sola.
In sintesi, il lato applicazione deve implementare:
- Controllo integrità. L'applicazione può verificare se il servizio è integro usando periodicamente l'API controllo integrità dei servizi in background o su richiesta per ogni chiamata negoziata .
- Logica di negoziazione. L'applicazione restituisce l'endpoint primario integro per impostazione predefinita. Quando l'endpoint primario è inattivo, l'applicazione restituisce un endpoint secondario integro.
- Logica di trasmissione. Quando i messaggi vengono inviati a più client, l'applicazione deve assicurarsi che i messaggi vengano trasmessi a tutti gli endpoint integri .
Di seguito è riportato un diagramma che illustra tale topologia:
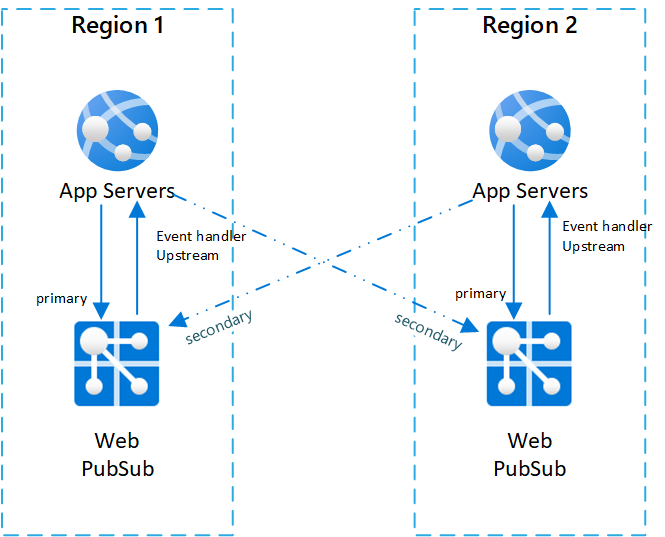
Sequenza di failover e procedure consigliate
La configurazione della topologia di sistema è ora appropriata. Ogni volta che un'istanza del servizio Web PubSub è inattiva, il traffico online verrà instradato ad altre istanze. Quando un'istanza primaria è inattiva e viene ripristinata in un secondo momento, si verifica quanto segue:
- L'istanza del servizio primario è inattiva, tutti i client connessi a questa istanza verranno eliminati.
- Nuovi client o riconnettere il client negoziano con il server app
- Il server app rileva che l'istanza del servizio primario è inattiva e negozia interrompe la restituzione di questo endpoint e inizia a restituire un endpoint secondario integro.
- I client si connettono all'istanza secondaria.
- L'istanza secondaria gestisce ora tutto il traffico online. Tutti i messaggi dal server ai client possono comunque essere recapitati perché l'istanza secondaria è connessa a tutti i server app. Tuttavia, i messaggi di evento da client a server vengono inviati solo al server app upstream nella stessa area.
- Dopo che l'istanza primaria è stata ripristinata e ripristinata online, il server app rileva che l'istanza primaria è nuovamente integra. La negoziazione restituirà di nuovo l'endpoint primario, quindi i nuovi client verranno connessi all'istanza primaria. Ma i client esistenti non verranno eliminati e continueranno a connettersi al database secondario fino a quando non si disconnettono.
I diagrammi seguenti illustrano come viene eseguito il failover:
Fig.1 Prima del failover 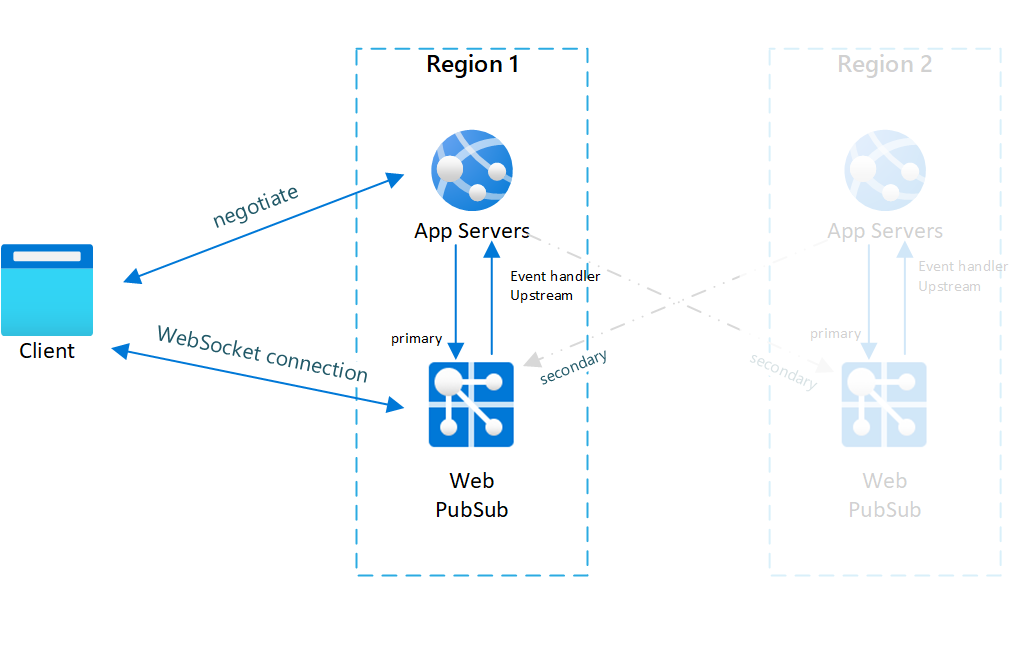
Fig.2 Dopo il failover 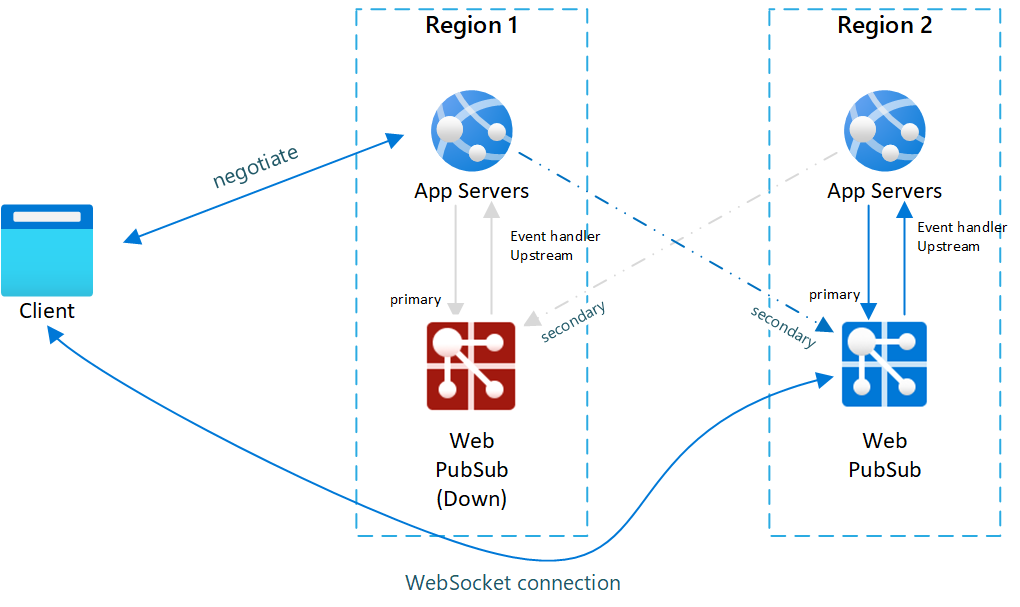
Fig.3 Tempo breve dopo il recupero primario 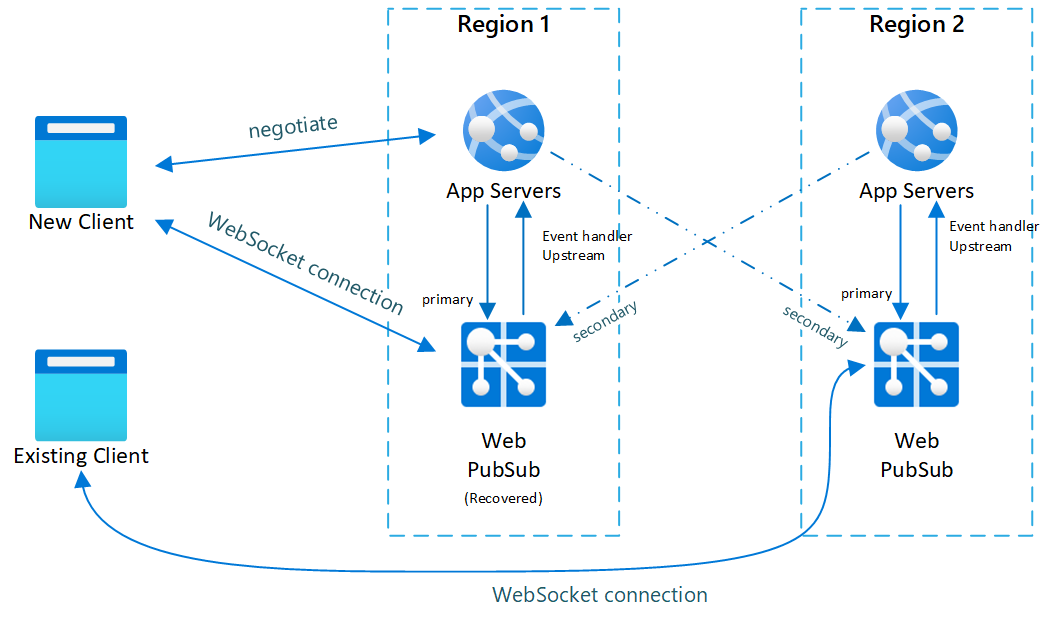
È possibile vedere nel caso normale solo il server app primario e il servizio Web PubSub hanno traffico online (in blu).
Dopo il failover, anche il server app secondario e il servizio Web PubSub diventano attivi. Dopo che il servizio Web PubSub primario è di nuovo online, i nuovi client si connetteranno al sito Web PubSub primario. I client esistenti restano invece connessi a quello secondario, quindi il traffico viene gestito da entrambe le istanze.
Dopo la disconnessione di tutti i client esistenti, il sistema tornerà alla situazione normale (figura 1).
Per implementare un'architettura a disponibilità elevata tra più aree sono disponibili due modelli principali:
- Il primo consiste nell'avere una coppia di server app e un'istanza del servizio Web PubSub che esegue tutto il traffico online e avere un'altra coppia come backup (denominata attivo/passivo, illustrato nella fig.1).
- L'altro consiste nell'avere due (o più) coppie di server app e istanze del servizio Web PubSub, ognuna che fa parte del traffico online e funge da backup per altre coppie (denominata attivo/attivo, simile alla fig.3).
Il servizio Web PubSub può supportare entrambi i modelli, la differenza principale è il modo in cui si implementano i server app. Se i server app sono attivi/passivi, anche il servizio Web PubSub sarà attivo/passivo (poiché il server app primario restituisce solo l'istanza primaria del servizio Web PubSub). Se i server app sono attivi/attivi, anche il servizio Web PubSub sarà attivo/attivo (poiché tutti i server app restituiranno le proprie istanze Web PubSub primarie, in modo che tutti possano ottenere traffico).
Tenere presente che, indipendentemente dai modelli che si sceglie di usare, è necessario connettere ogni istanza del servizio Web PubSub a un server app come ruolo primario .
Inoltre, a causa della natura della connessione WebSocket (si tratta di una connessione lunga), i client riscontrano interruzioni della connessione quando si verifica un'emergenza e si verifica un failover. Sarà necessario gestire questi casi sul lato client in modo che siano trasparenti per i clienti finali, ad esempio eseguendo la riconnessione dopo la chiusura di una connessione.
Architettura a disponibilità elevata per il modello client-client
Per il modello client-client, attualmente non è ancora possibile supportare un ripristino di emergenza senza tempi di inattività usando più istanze. Se si hanno requisiti di disponibilità elevata, prendere in considerazione l'uso della replica geografica.
Come testare un failover
Seguire la procedura per attivare il failover:
- Nella scheda Rete per la risorsa primaria nel portale disabilitare l'accesso alla rete pubblica. Se la risorsa ha la rete privata abilitata, usare le regole di controllo di accesso per negare tutto il traffico.
- Riavviare la risorsa primaria.
Passaggi successivi
In questo articolo si è appreso come configurare l'applicazione per ottenere resilienza per il servizio Web PubSub.
Usare queste risorse per iniziare a creare un'applicazione personalizzata: