Zone di destinazione dei dati
Le zone di destinazione dei dati sono connesse alla zona di destinazione di gestione dei dati tramite peering di rete virtuale .Data landing zones are connected to your data management zone by virtual network (VNet) peering. Ogni zona di destinazione dei dati è considerata una zona di destinazione correlata all'architettura della zona di destinazione di Azure.
Importante
Prima di effettuare il provisioning di una zona di destinazione dei dati, assicurarsi che il modello operativo DevOps e CI/CD sia installato e che venga distribuita una zona di destinazione per la gestione dei dati.
Ogni zona di destinazione dei dati ha diversi livelli che consentono l'agilità per le integrazioni dei dati del servizio e i prodotti dati in esso contenuti. È possibile distribuire una nuova zona di destinazione dei dati con un set standard di servizi che consentono all'area di destinazione dei dati di iniziare l'inserimento e l'analisi dei dati.
La sottoscrizione di Azure associata alla zona di destinazione dei dati ha la struttura seguente:
Nota
Un'applicazione dati produce uno o più prodotti dati.
Architettura della zona di destinazione dei dati
L'architettura della zona di destinazione dei dati illustra i livelli, i relativi gruppi di risorse e i servizi contenuti in ogni gruppo di risorse. L'architettura offre anche una panoramica di tutti i gruppi e i ruoli associati alla zona di destinazione dei dati, oltre all'estensione dell'accesso ai piani dati e di controllo.

Suggerimento
Prima di distribuire una zona di destinazione dei dati, assicurarsi di prendere in considerazione il numero di zone di destinazione dei dati iniziali da distribuire.
Usare questa architettura come punto di partenza. Scaricare il file di Visio e modificarlo in base ai requisiti aziendali e tecnici specifici durante la pianificazione dell'implementazione della zona di destinazione dei dati.
Livello servizi di base
Il livello di servizi di base include tutti i servizi necessari per abilitare la zona di destinazione dei dati nel contesto dell'analisi su scala cloud. La tabella seguente elenca i gruppi di risorse che forniscono la suite standard di servizi disponibili in ogni zona di destinazione dei dati distribuita.
| Gruppo di risorse | Obbligatorio | Descrizione |
|---|---|---|
network-rg |
Sì | Rete |
databricks-monitoring-rg |
Facoltativo | Monitoraggio per le aree di lavoro di Azure Databricks |
hive-rg |
Facoltativo | Metastore Hive per Azure Databricks |
storage-rg |
Sì | Servizi data lake |
external-data-rg |
Sì | Archiviazione di inserimento per il caricamento |
runtimes-rg |
Sì | Runtime di integrazione condivisa |
mgmt-rg |
Sì | Agenti CI/CD |
metadata-ingestion-rg |
Facoltativo | Inserimento indipendente dai dati |
databricks-monitoring-rg |
Facoltativo | Area di lavoro Log Analytics per le aree di lavoro di Databricks nella zona di destinazione |
shared-synapse-rg |
Facoltativo | Azure Synapse condiviso |
shared-databricks-rg |
Facoltativo | Area di lavoro di Azure Databricks condivisa |
Rete
Il gruppo di risorse di rete contiene i componenti principali, tra cui Azure Network Watcher, gruppi di sicurezza di rete (NSG) e una rete virtuale. Tutti questi servizi vengono distribuiti in un singolo gruppo di risorse.
La rete virtuale della zona di destinazione dei dati viene eseguito automaticamente il peering con la rete virtuale della zona di destinazione della gestione dei dati e la rete virtuale della sottoscrizione di connettività.
Monitoraggio delle aree di lavoro di Azure Databricks
Questo gruppo di risorse è facoltativo e viene distribuito solo con Azure Databricks.
Il modello di zona di destinazione di Azure consiglia di inviare tutti i log a un'area di lavoro Log Analytics centrale. Tuttavia, ogni zona di destinazione dei dati include anche un gruppo di risorse di monitoraggio per acquisire i log di Spark da Databricks. Ogni gruppo di risorse contiene un'area di lavoro Log Analytics condivisa e Azure Key Vault per archiviare le chiavi di Log Analytics.
Importante
Usare solo l'area di lavoro Log Analytics nel gruppo di risorse di monitoraggio di Databricks per acquisire i log di Azure Databricks Spark.
Per ulteriori informazioni, vedere Monitoraggio di Azure Databricks.
Metastore Hive per Azure Databricks
Questo gruppo di risorse è facoltativo e deve essere distribuito solo con Azure Databricks.
Il metastore Hive per Azure Databricks effettua il provisioning di un database Database di Azure per MySQL e di un insieme di credenziali delle chiavi. Tutte le aree di lavoro di Azure Databricks nella zona di destinazione dei dati usano questo metastore come metastore Apache Hive esterno.
Per altre informazioni, vedere Metastore Apache Hive esterno.
Servizi Data Lake
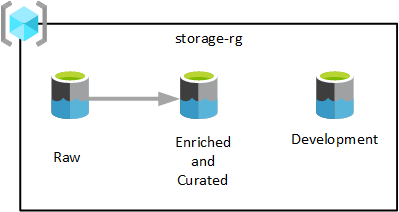
Come illustrato nel diagramma precedente, viene eseguito il provisioning di tre account Azure Data Lake Storage Gen2 in un singolo gruppo di risorse di Servizi Data Lake. I dati trasformati in fasi diverse vengono salvati in uno dei data lake della zona di destinazione dei dati. I dati sono disponibili per l'utilizzo da parte dei team di analisi, data science e visualizzazione.
I livelli data lake usano terminologia diversa a seconda della tecnologia e del fornitore. Questa tabella fornisce indicazioni su come applicare le condizioni per l'analisi su scala cloud:
| Analisi cloud | Delta Lake | Altri termini | Descrizione |
|---|---|---|---|
| Raw | Bronzo | Atterraggio e conformità | Tabelle di inserimento |
| Dati arricchiti | Argento | Zona di standardizzazione | Tabelle perfezionate. Entità completa archiviata, recordset pronti per l'utilizzo dai sistemi di record. |
| Curato | Oro | Area prodotto | Funzionalità o tabelle aggregate. Zona primaria per applicazioni, team e utenti per l'utilizzo di prodotti dati. |
| Sviluppo | -- | Area di sviluppo | Posizione per data engineer e scienziati, che comprendono sia una sandbox di analisi che una zona di sviluppo di prodotti. |
Nota
Nel diagramma precedente ogni zona di destinazione dei dati ha tre data lake. Tuttavia, a seconda dei requisiti, è possibile consolidare i livelli non elaborati, arricchiti e curati in un account di archiviazione e gestire un altro account di archiviazione denominato "sviluppo" per consentire agli utenti di dati di introdurre altri prodotti dati utili.
Per altre informazioni, vedi:
- Panoramica di Azure Data Lake Storage per l'analisi su scala cloud
- Standardizzazione dei dati
- Effettuare il provisioning degli account di Azure Data Lake Storage Gen2 per ogni zona di destinazione dei dati
- Considerazioni chiave per Azure Data Lake Storage
- Controllo di accesso e configurazioni data lake in Azure Data Lake Storage
Archiviazione di inserimento per il caricamento
Gli editori di dati di terze parti devono trasferire i dati nella piattaforma in modo che i team dell'applicazione dati possano eseguirne il pull nei data lake. Come illustrato nel diagramma seguente, il gruppo di risorse di archiviazione di inserimento di caricamento consente di effettuare il provisioning degli archivi BLOB per terze parti.
I team dell'applicazione dati richiedono questi BLOB di archiviazione. Le richieste vengono quindi approvate dal team operativo della zona di destinazione dei dati. I dati devono essere rimossi dal BLOB di archiviazione di origine dopo il pull dal BLOB di archiviazione in raw.
Importante
Poiché Archiviazione di Azure viene effettuato il provisioning dei BLOB in base alle esigenze, è necessario inizialmente distribuire un gruppo di risorse di servizi di archiviazione vuoto in ogni zona di destinazione dei dati.
Runtime di integrazione condivisa
Distribuire una macchina virtuale con runtime di integrazione self-hosted nella zona di destinazione dei dati. Ospitarlo nel gruppo di risorse di integrazione condivisa. Questa distribuzione consente di eseguire rapidamente l'onboarding dei prodotti dati nella zona di destinazione dei dati.
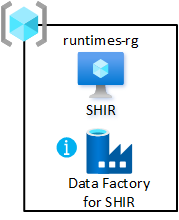
Per abilitare il gruppo di risorse:
- Creare almeno una data factory di Azure nel gruppo di risorse di integrazione condivisa della zona di destinazione dei dati. Usarlo solo per collegare il runtime di integrazione self-hosted condiviso, non per le pipeline di dati.
- Creare e configurare un runtime di integrazione self-hosted nella macchina virtuale.
- Associare il runtime di integrazione self-hosted alle data factory di Azure nelle zone di destinazione dei dati.
- Configurare Automazione di Azure per aggiornare periodicamente il runtime di integrazione self-hosted.
Nota
La distribuzione precedente fornisce una singola distribuzione di macchine virtuali con runtime di integrazione self-hosted. È possibile associare un runtime di integrazione self-hosted a più macchine virtuali o macchine virtuali locali in Azure. Questi computer sono chiamati nodi. È possibile avere fino a quattro nodi associati a un runtime di integrazione self-hosted. I vantaggi della presenza di più nodi in computer locali in cui è installato un gateway per un gateway logico sono:
- Maggiore disponibilità del runtime di integrazione self-hosted in modo che non sia più il singolo punto di errore nella soluzione Big Data o nell'integrazione dei dati cloud. Questa disponibilità consente di garantire la continuità quando si usano fino a quattro nodi.
- Miglioramento delle prestazioni e della velocità effettiva durante lo spostamento dati tra archivi dati locali e cloud. Ottenere altre informazioni sui confronti delle prestazioni.
È possibile associare più nodi installando il software di runtime di integrazione self-hosted dall'Area download. Registrarlo quindi usando una delle chiavi di autenticazione ottenute dal cmdlet New-AzDataFactoryV2IntegrationRuntimeKey, come descritto nell'esercitazione.
Le informazioni più dettagliate sono disponibili in Disponibilità elevata e scalabilità di Azure Datafactory.
Importante
Distribuire i runtime di integrazione condivisa il più vicino possibile all'origine dati. La distribuzione non limita la distribuzione dei runtime di integrazione in una zona di destinazione dei dati o in cloud di terze parti. Offre invece un fallback per le origini dati native del cloud e in area.
Agenti CI/CD
Gli agenti CI/CD consentono di distribuire applicazioni dati e modifiche alla zona di destinazione dei dati.
Per altre informazioni, vedere Agenti di Azure Pipeline.
Inserimento indipendente dai dati
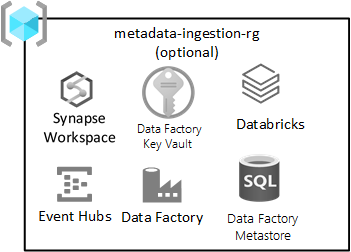
Questo gruppo di risorse è facoltativo e non impedisce la distribuzione della zona di destinazione.
Questo gruppo di risorse si applica se si ha (o si sta sviluppando) un motore di inserimento dati indipendente per l'inserimento automatico dei dati in base alla registrazione dei metadati (inclusi i stringa di connessione, il percorso per copiare i dati da e verso e verso e la pianificazione dell'inserimento. Il gruppo di risorse di inserimento ed elaborazione dispone di servizi chiave per questo tipo di framework.
Distribuire un'istanza di database SQL di Azure per contenere i metadati usati da Azure Data Factory. Effettuare il provisioning di Azure Key Vault per archiviare i segreti relativi ai servizi di inserimento automatizzati. Questi segreti possono includere:
- Credenziali del metastore di Azure Data Factory
- Credenziali dell'entità servizio per il processo di inserimento automatico
Per altre informazioni, vedere Come i framework di inserimento automatizzato supportano l'analisi su scala cloud in Azure.
I servizi inclusi in questo gruppo di risorse includono:
| Service | Richiesto | Linee guida |
|---|---|---|
| Azure Data Factory | Sì | Azure Data Factory è il motore di orchestrazione per l'inserimento indipendente dai dati. |
| DB di Azure SQL | Sì | Il database SQL di Azure è il metastore per Azure Data Factory. |
| Hub eventi o hub IoT | Facoltativo | Hub eventi o hub IoT possono fornire flussi in tempo reale a Hub eventi, oltre all'elaborazione batch e streaming tramite un'area di lavoro di progettazione di Databricks. |
| Azure Databricks | Facoltativo | È possibile distribuire Azure Databricks o Azure Synapse Spark per l'uso con il motore di inserimento indipendente dai dati. |
| Azure Synapse | Facoltativo | È possibile distribuire Azure Databricks o Azure Synapse Spark da usare con il motore di inserimento indipendente dai dati. |
Databricks condiviso
Questo gruppo di risorse è facoltativo e viene distribuito solo con Azure Databricks. Tutti gli utenti nella zona di destinazione dei dati possono usare un'area di lavoro di Databricks.
Azure Databricks è un consumer chiave del servizio Azure Data Lake Storage. Le operazioni di file atomiche sono ottimizzate per i motori di analisi Spark. Questa ottimizzazione velocizza il completamento dei processi Spark con problemi del servizio Azure Databricks.
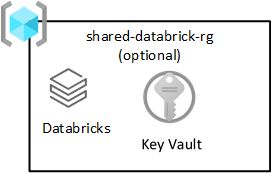
Importante
Viene effettuato il provisioning di un'area di lavoro di Azure Databricks denominata area di lavoro di Azure Databricks (analisi) per tutti i data scientist e DataOps, come illustrato nel gruppo di risorse prodotti condivisi.
È possibile configurare questa area di lavoro per connettersi ad Azure Data Lake usando il pass-through di Microsoft Entra o il controllo di accesso alle tabelle. A seconda del caso d'uso, è possibile configurare l'accesso condizionale come un'altra misura di sicurezza.
Seguire le procedure consigliate per l'analisi su scala cloud per integrare Azure Databricks:
- Proteggere l'accesso ad Azure Data Lake Gen2 da Azure Databricks
- Procedure consigliate per Azure Databricks
Il modello di zona di destinazione di Azure consiglia di inviare tutti i log a un'area di lavoro Log Analytics centrale. Tuttavia, ogni zona di destinazione dei dati contiene anche un gruppo di risorse di monitoraggio per acquisire i log di Spark da Databricks.
Azure Synapse Analytics condiviso
Questo gruppo di risorse è facoltativo.
Durante la configurazione iniziale di una zona di destinazione dei dati, viene distribuita una singola area di lavoro di Azure Synapse Analytics per l'uso da parte di tutti gli analisti e gli scienziati dei dati nel gruppo di risorse di prodotti condivisi.
È possibile configurare più aree di lavoro synapse per i prodotti dati se sono necessarie la gestione dei costi e la ricarica. I team dell'applicazione dati possono usare aree di lavoro di Azure Synapse Analytics dedicate per creare pool di database SQL di Azure dedicati come archivio dati di lettura usato dal livello di visualizzazione.
Importante
Impedire l'uso dell'area di lavoro condivisa di Azure Synapse per la creazione di prodotti dati bloccando l'area di lavoro per consentire solo query SQL su richiesta. È lì solo per scopi sfruttativi.
Applicazione dati
Ogni zona di destinazione dei dati può avere più prodotti dati. È possibile creare questi prodotti dati inserendo i dati dall'origine. È anche possibile creare prodotti dati da altri prodotti dati all'interno della stessa zona di destinazione dei dati o da altre zone di destinazione dei dati. La creazione di prodotti dati dei prodotti dati è soggetta all'approvazione dell'amministratore dei dati.
Gruppo di risorse del prodotto di dati
Il prodotto del gruppo di risorse prodotto dati include tutti i servizi necessari per rendere tale prodotto dati. Ad esempio, per MySQL è necessario un database di Azure, usato da uno strumento di visualizzazione. I dati devono essere inseriti e trasformati prima che vengano inseriti nel database MySQL. In questo caso, è possibile distribuire Database di Azure per MySQL e un'istanza di Azure Data Factory nel gruppo di risorse del prodotto dati.
Suggerimento
Se si sceglie di non implementare un motore indipendente dai dati per l'inserimento una sola volta dalle origini operative o se le connessioni complesse non sono facilitate nel motore di agnostici dei dati, creare un'applicazione dati allineata all'origine. Per altre informazioni, vedere Applicazioni dati (allineate all'origine)
Per altre informazioni su come eseguire l'onboarding dei prodotti dati, vedere Prodotti dati di analisi su scala cloud in Azure.
Visualizzazione
Viene creato un gruppo di risorse di visualizzazione vuoto per ogni zona di destinazione dei dati. Compilare questo gruppo di risorse con i servizi necessari per implementare la soluzione di visualizzazione. L'uso della rete virtuale esistente consente alla soluzione di connettersi ai prodotti dati.
Questo gruppo di risorse può ospitare macchine virtuali per i servizi di visualizzazione di terze parti.
Suggerimento
A causa dei costi di licenza, potrebbe essere più economico distribuire prodotti di visualizzazione di terze parti nella zona di destinazione di gestione dei dati e per consentire a tali prodotti di connettersi tra zone di destinazione dei dati per eseguire il pull dei dati.