Azure Machine Learning come prodotto dati per l'analisi su scala cloud
Azure Machine Learning è una piattaforma integrata per la gestione completa del ciclo di vita dell’apprendimento automatico, che include assistenza per la creazione, il funzionamento e l'utilizzo di flussi di lavoro e modelli di apprendimento automatico. Ecco alcuni vantaggi del servizio:
Le funzionalità supportano le attività degli autori volte ad aumentare la produttività, consentendo loro di gestire esperimenti, accedere ai dati, tenere traccia dei processi, ottimizzare gli iperparametri e automatizzare i flussi di lavoro.
La possibilità di spiegare, riprodurre, controllare e integrare il modello con DevOps, oltre a un modello di controllo della sicurezza completo, può aiutare gli operatori a soddisfare i requisiti di governance e conformità.
Le funzionalità di inferenza gestita e una solida integrazione con i servizi di calcolo e dati di Azure possono semplificare l'utilizzo del servizio.
Azure Machine Learning copre tutti gli aspetti del ciclo di vita di data science. Copre la registrazione dell'archivio dati e del set di dati per la distribuzione del modello. Può essere usato per qualsiasi tipo di apprendimento automatico, dalla forma classica al Deep Learning. Include l'apprendimento supervisionato e non supervisionato. Che si preferisca scrivere codice Python o R oppure usare opzioni senza codice o con uso limitato di codice, come la finestra di progettazione, si possono creare, sottoporre a training e monitorare modelli di apprendimento automatico e deep learning accurati in un'area di lavoro di Azure Machine Learning.
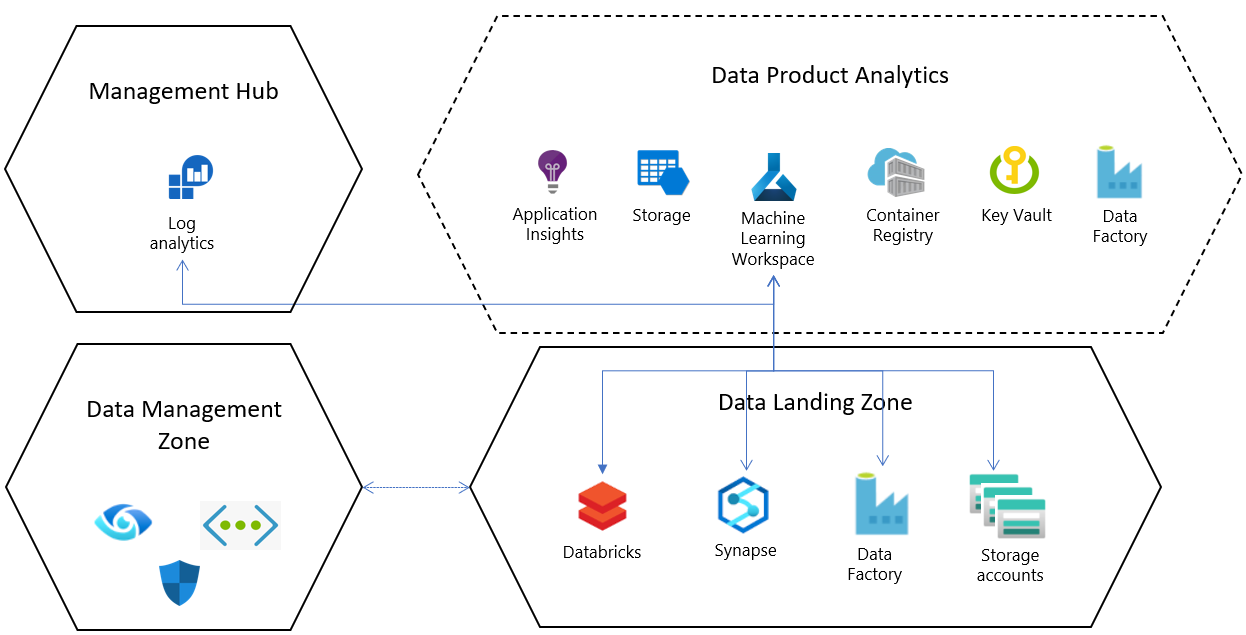
Azure Machine Learning, la piattaforma Azure e i servizi Azure per intelligenza artificiale possono collaborare per gestire il ciclo di vita dell’apprendimento automatico. Un professionista di apprendimento automatico può usare Azure Synapse Analytics, database SQL di Azure o Microsoft Power BI per iniziare ad analizzare i dati e passare ad Azure Machine Learning per la prototipazione, la gestione della sperimentazione e l'operazionalizzazione. Nelle zone di destinazione di Azure, Azure Machine Learning può essere considerato un prodotto dati.
Azure Machine Learning nell'analisi su scala cloud
Una base della zona di destinazione di Cloud Adoption Framework (CAF), le zone di destinazione dei dati di analisi su scala cloud e la configurazione di Azure Machine Learning configura i professionisti di Machine Learning con un ambiente preconfigurato in cui possono distribuire ripetutamente nuovi carichi di lavoro di Machine Learning o eseguire la migrazione di carichi di lavoro esistenti. Queste funzionalità possono aiutare i professionisti di apprendimento automatico a far fruttare di più il loro tempo in termini di agilità e valore.
I principi di progettazione seguenti possono guidare l'implementazione di zone di destinazione di Azure per Azure Machine Learning:
Accesso ai dati accelerato: preconfiguare i componenti di archiviazione della zona di destinazione come archivi dati nell'area di lavoro di Azure Machine Learning.
Collaborazione abilitata: organizzare le aree di lavoro per progetto e centralizzare la gestione degli accessi per le risorse delle zone di destinazione per supportare la collaborazione tra professionisti di ingegneria dei dati, data science e apprendimento automatico.
Implementazione sicura: come impostazione predefinita per ogni distribuzione, seguire le procedure consigliate e usare la gestione dell'isolamento della rete, delle identità e degli accessi per proteggere gli asset di dati.
Self-service: i professionisti di apprendimento automatico possono incrementare l'agilità e l'organizzazione esplorando le opzioni per distribuire nuove risorse di progetto.
Separazione delle criticità tra gestione dei dati e utilizzo dei dati: il pass-through delle identità è il tipo di autenticazione predefinito per Azure Machine Learning e l'archiviazione.
Applicazione dati più veloce (allineata all'origine): è possibile preconfigurare Azure Data Factory, Azure Synapse Analytics e Databricks per il collegamento ad Azure Machine Learning.
Osservabilità: la registrazione centrale e le configurazioni di riferimento consentono di monitorare l'ambiente.
Panoramica dell'implementazione
Nota
Questa sezione consiglia configurazioni specifiche per l'analisi su scala cloud. Integra la documentazione di Azure Machine Learning e le procedure consigliate di Cloud Adoption Framework.
Organizzazione e configurazione dell'area di lavoro
È possibile distribuire il numero di aree di lavoro di apprendimento automatico necessarie per i carichi di lavoro e per ogni zona di destinazione distribuita. Le raccomandazioni seguenti possono essere utili per la configurazione:
Distribuire almeno un'area di lavoro di apprendimento automatico per ogni progetto.
A seconda del ciclo di vita del progetto di apprendimento automatico, distribuire un'area di lavoro di sviluppo per creare prototipi dei casi d'uso ed esplorare i dati nelle prime fasi. Per attività che richiedono sperimentazione, test e distribuzione continui, distribuire un'area di lavoro di staging e produzione.
Quando sono necessari più ambienti per le aree di lavoro di sviluppo, gestione temporanea e produzione in una zona di destinazione dei dati, è consigliabile evitare la duplicazione dei dati facendo in modo che ogni ambiente si trovi nella stessa zona di destinazione dei dati di produzione.
Per altre informazioni su come organizzare e configurare le risorse di Azure Machine Learning, vedere Organizzare e configurare gli ambienti di Azure Machine Learning.
Per ogni configurazione di risorsa predefinita in una zona di destinazione dei dati viene distribuito un servizio Azure Machine Learning in un gruppo di risorse dedicato con queste configurazioni e risorse dipendenti:
- Insieme di credenziali chiave di Azure
- Application Insights
- Registro Azure Container
- Usare Azure Machine Learning per connettersi a un account Archiviazione di Azure e all'autenticazione basata sull'identità di Microsoft Entra per consentire agli utenti di connettersi all'account.
- La registrazione diagnostica viene configurata per ogni area di lavoro e per una risorsa centrale di Log Analytics su scala aziendale. Ciò consente di analizzare l'integrità dei processi e lo stato delle risorse di Azure Machine Learning in modo centralizzato all'interno di una o più zone di destinazione.
- Per altre informazioni su Azure Machine Learning e sulle dipendenze, vedere Definizione di area di lavoro di Azure Machine Learning.
Integrazione con i servizi di base della zona di destinazione dei dati
La zona di destinazione dei dati include un set predefinito di servizi distribuiti nel livello servizi di base. Questi servizi di base possono essere configurati durante la distribuzione di Azure Machine Learning nella zona di destinazione dei dati.
Connettere Azure Synapse Analytics o le area di lavoro di Databricks come servizi collegati per integrare i dati ed elaborare Big Data.
Per impostazione predefinita, il provisioning dei servizi di data lake viene effettuato nella zona di destinazione dei dati e le distribuzioni dei prodotti Azure Machine Learning includono connessioni (archivi dati) preconfigurate per questi account di archiviazione.
Connettività di rete
La rete per l'implementazione di Azure Machine Learning nelle zone di destinazione di Azure viene configurata con le procedure consigliate per la sicurezza di Azure Machine Learning e le procedure consigliate per le reti di CAF. Queste procedure consigliate includono le configurazioni seguenti:
- Azure Machine Learning e le risorse dipendenti sono configurati per l'uso di endpoint di collegamento privato.
- Le risorse di calcolo gestite vengono distribuite solo con indirizzi IP privati.
- La connettività di rete al repository di immagini di base pubblico di Azure Machine Learning e servizi partner come Azure Artifacts possono essere configurati a livello di rete.
Gestione delle identità e dell'accesso
Prendere in considerazione le raccomandazioni seguenti per la gestione delle identità utente e dell'accesso con Azure Machine Learning:
Gli archivi dati in Azure Machine Learning possono essere configurati per l'uso dell'autenticazione basata su credenziali o identità. Quando si usano le configurazioni di controllo di accesso e data lake in Azure Data Lake Storage Gen2, configurare gli archivi dati per l'uso dell'autenticazione basata sull'identità. In questo modo, Azure Machine Learning può ottimizzare le autorizzazioni di accesso utente per l'archiviazione.
Usare i gruppi di Microsoft Entra per gestire le autorizzazioni utente per le risorse di archiviazione e Machine Learning.
Azure Machine Learning può usare le identità gestite assegnate dall'utente per il controllo di accesso e limitare l'intervallo di accesso a Registro Azure Container, Key Vault, Archiviazione di Azure e Application Insights.
Creare identità gestite assegnate dall'utente in cluster di calcolo creati in Azure Machine Learning.
Effettuare il provisioning dell'infrastruttura tramite self-service
La funzionalità self-service può essere abilitata e regolata con i criteri per Azure Machine Learning. La tabella seguente elenca un set di criteri predefiniti quando si distribuisce Azure Machine Learning. Per altre informazioni, vedere Definizioni dei criteri predefiniti di Criteri di Azure per Azure Machine Learning.
| Criteri | Tipo | Riferimento |
|---|---|---|
| Le aree di lavoro di Azure Machine Learning devono usare collegamenti privati di Azure. | Predefinito | Visualizza nel portale di Azure |
| Le aree di lavoro di Azure Machine Learning devono usare identità gestite assegnate dall'utente. | Predefinito | Visualizza nel portale di Azure |
| [Anteprima]: Configura i registri consentiti per i calcoli di Azure Machine Learning specificati. | Predefinito | Visualizza nel portale di Azure |
| Configura aree di lavoro di Azure Machine Learning con endpoint privati. | Predefinito | Visualizza nel portale di Azure |
| Configurare i calcoli di Machine Learning per disabilitare i metodi di autenticazione locale. | Predefinito | Visualizza nel portale di Azure |
| Append-machinelearningcompute-setupscriptscreationscript | Personalizzato (zone di destinazione CAF) | Visualizzare su GitHub |
| Deny-machinelearning-hbiworkspace | Personalizzato (zone di destinazione CAF) | Visualizzare su GitHub |
| Deny-machinelearning-publicaccesswhenbehindvnet | Personalizzato (zone di destinazione CAF) | Visualizzare su GitHub |
| Deny-machinelearning-AKS | Personalizzato (zone di destinazione CAF) | Visualizzare su GitHub |
| Deny-machinelearningcompute-subnetid | Personalizzato (zone di destinazione CAF) | Visualizzare su GitHub |
| Deny-machinelearningcompute-vmsize | Personalizzato (zone di destinazione CAF) | Visualizzare su GitHub |
| Deny-machinelearningcomputecluster-remoteloginportpublicaccess | Personalizzato (zone di destinazione CAF) | Visualizzare su GitHub |
| Deny-machinelearningcomputecluster-scale | Personalizzato (zone di destinazione CAF) | Visualizzare su GitHub |
Raccomandazioni per la gestione dell'ambiente
Le zone di destinazione dei dati di analisi su scala cloud delineano l'implementazione di riferimento per le distribuzioni ripetibili, che consentono di configurare ambienti gestibili e gestibili. Prendere in considerazione le raccomandazioni seguenti per l'uso di Azure Machine Learning per gestire l'ambiente:
Usare i gruppi di Microsoft Entra per gestire l'accesso alle risorse di Machine Learning.
Pubblicare una dashboard di monitoraggio centrale per monitorare l'integrità della pipeline, l'utilizzo del calcolo e la gestione delle quote per Machine Learning.
Se in genere si usano criteri di Azure predefiniti ed è necessario soddisfare requisiti di conformità aggiuntivi, creare criteri di Azure personalizzati per migliorare la governance e la modalità self-service.
Per tenere traccia dei costi di ricerca e sviluppo, distribuire un'area di lavoro di apprendimento automatico nella zona di destinazione come risorsa condivisa durante le prime fasi di esplorazione del caso d'uso.
Importante
Usare cluster di Azure Machine Learning per il training dei modelli a livello di produzione e il servizio Azure Kubernetes (AKS) per le distribuzioni a livello di produzione.
Suggerimento
Usare Azure Machine Learning per progetti di data science. Copre il flusso di lavoro end-to-end con sottoservizi e funzionalità e consente di automatizzare completamente il processo.
Passaggi successivi
Usare le linee guida e il modello Data Product Analytics per distribuire Azure Machine Learning e fare riferimento alla documentazione e alle esercitazioni di Azure Machine Learning per iniziare a creare le soluzioni.
Passare ai seguenti quattro articoli di Cloud Adoption Framework per altre informazioni sulle procedure consigliate per la distribuzione e la gestione di Azure Machine Learning per le aziende:
Organizzare e configurare gli ambienti di Azure Machine Learning: quando si pianifica una distribuzione di Azure Machine Learning, quale effetto hanno le strutture del team, gli ambienti o la collocazione geografica delle risorse sulla configurazione delle aree di lavoro?
Procedure consigliate di Azure Machine Learning per la sicurezza aziendale: informazioni su come proteggere l'ambiente e le risorse con Azure Machine Learning.
Gestire budget, costi e quote per Azure Machine Learning su scala aziendale: le organizzazioni devono affrontare molte problematiche di gestione e ottimizzazione quando gestiscono i costi di calcolo per carichi di lavoro, team e utenti sostenuti da Azure Machine Learning.
Guida di Machine Learning DevOps: Machine Learning DevOps è un cambiamento organizzativo che si basa su una combinazione di persone, processi e tecnologie per offrire soluzioni di apprendimento automatico in modo solido, scalabile, affidabile e automatizzato. Questa guida riepiloga le procedure consigliate e le informazioni che consentono alle aziende di usare Azure Machine Learning per l'adozione di Machine Learning DevOps.