Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo fa parte della serie di articoli "SAP extend and innovate data: Best practices".
- Identificare le origini dati SAP
- Scegliere il connettore SAP migliore
- Prestazioni e risoluzione dei problemi per l'estrazione dei dati SAP
- Sicurezza dell'integrazione dei dati per SAP in Azure
- Architettura generica di integrazione dei dati SAP
Esistono molti modi per connettersi al sistema SAP per l'integrazione dei dati. Le sezioni seguenti descrivono considerazioni e raccomandazioni generali e specifiche del connettore.
Prestazioni
È importante configurare impostazioni ottimali per l'origine e la destinazione in modo da ottenere prestazioni ottimali durante l'estrazione e l'elaborazione dei dati.
Considerazioni generali
- Verificare che i parametri SAP corretti siano impostati per una connessione massima simultanea.
- È consigliabile usare il tipo di accesso del gruppo SAP per migliorare le prestazioni e la distribuzione del carico.
- Assicurarsi che la macchina virtuale del runtime di integrazione self-hosted (SHIR) sia ridimensionata in modo adeguato e sia a disponibilità elevata.
- Quando si usano set di dati di grandi dimensioni, verificare se il connettore in uso offre una funzionalità di partizionamento. Molti dei connettori SAP supportano il partizionamento e la parallelizzazione delle funzionalità per velocizzare i caricamenti dei dati. Quando si usa questo metodo, i dati vengono inseriti in blocchi più piccoli che possono essere caricati usando diversi processi paralleli. Per altre informazioni, vedere la documentazione specifica del connettore.
Indicazioni generali
Usare la transazione SAP RZ12 per modificare i valori per il numero massimo di connessioni simultanee.
Parametri SAP per RFC - RZ12: il parametro seguente può limitare il numero di chiamate RFC consentite per un utente o un'applicazione, quindi assicurarsi che questa restrizione non causi un collo di bottiglia.
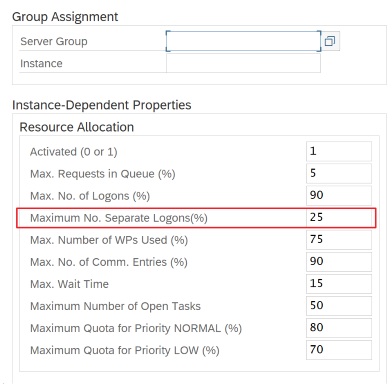
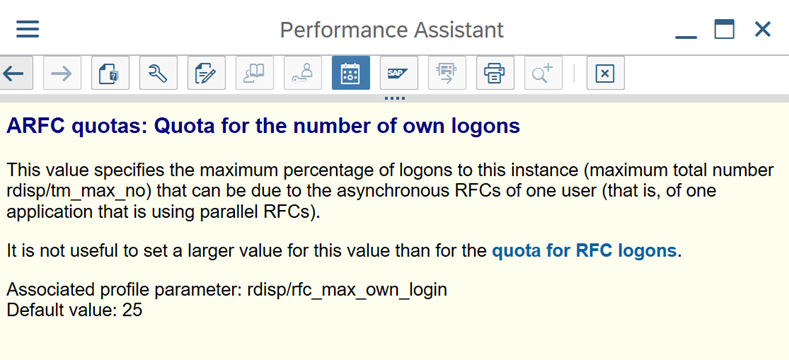
Connessione a SAP tramite il gruppo di accesso: SHIR (runtime di integrazione self-hosted) deve connettersi a SAP usando un gruppo di accesso SAP (tramite server messaggi) e non a un server applicazioni specifico per garantire una distribuzione del carico di lavoro in tutti i server applicazioni disponibili.
Nota
Il cluster Spark del flusso di dati e shir sono potenti. Molte attività di copia SAP interne, ad esempio 16, possono essere attivate ed eseguite. Tuttavia, se il numero di connessione simultaneo del server SAP è ridotto, ad esempio 8, il valore perf legge i dati dal lato SAP.
Iniziare con 4 vCPU e vm da 16 GB per SHIR. I passaggi seguenti illustrano la connessione del processo di lavoro del dialogo in SAP con SHIR.
- Controllare se il cliente usa un computer fisico di scarsa qualità per configurare e installare SHIR per eseguire una copia SAP interna.
- Passare al portale di Azure Data Factory e trovare il servizio collegato SAP CDC correlato usato nel flusso di dati. Controllare il nome SHIR a cui si fa riferimento.
- Controllare le impostazioni cpu, memoria, rete e disco del computer fisico in cui è installato SHIR.
- Controllare il numero
diawp.exedi in esecuzione nel computer SHIR. Èdiawp.exepossibile eseguire un'attività di copia. Il numero didiawp.exeè basato sulle impostazioni cpu, memoria, rete e disco del computer.
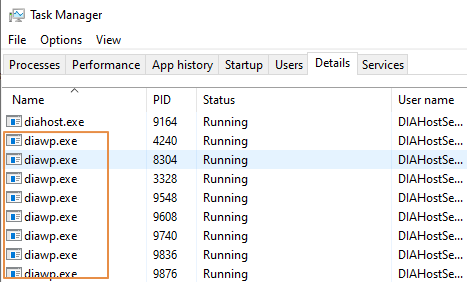
Se si vogliono eseguire più partizioni in parallelo in SHIR contemporaneamente, usare una macchina virtuale potente per configurare SHIR. In alternativa, usare la scalabilità orizzontale usando funzionalità di disponibilità elevata e scalabilità SHIR per avere più nodi. Per altre informazioni, vedere Disponibilità elevata e scalabilità.
Partizioni
La sezione seguente descrive il processo di partizionamento per un connettore SAP CDC. Il processo è lo stesso per un connettore SAP Table e SAP BW Open Hub.

Il ridimensionamento può essere eseguito nel runtime di integrazione self-hosted o nel runtime di integrazione di Azure a seconda dei requisiti di prestazioni. Esaminare l'utilizzo della CPU di SHIR per visualizzare le metriche per decidere l'approccio di ridimensionamento. Il shir può essere ridimensionato verticalmente o orizzontalmente in base alle proprie esigenze. È consigliabile distribuire il runtime di integrazione di Azure in uno SKU inferiore. Aumentare le prestazioni per soddisfare i requisiti di prestazioni in base a quanto determinato tramite test di carico, anziché iniziare inutilmente alla fine superiore.
Nota
Se si raggiunge il 70% della capacità, aumentare o aumentare le prestazioni per shir.

Il partizionamento è utile per carichi completi iniziali o di grandi dimensioni e in genere non è necessario per i caricamenti differenziali. Se non si specifica la partizione, per impostazione predefinita, 1 "producer" nel sistema SAP (in genere un processo batch) recupera i dati di origine nella coda dei dati operativi (ODQ) e SHIR recupera i dati da ODQ. Per impostazione predefinita, SHIR usa quattro thread per recuperare i dati da ODQ, quindi potenzialmente quattro processi di dialogo vengono occupati in SAP in quel momento.
L'idea del partizionamento consiste nel suddividere un set di dati iniziale di grandi dimensioni in più subset disgiunti di dimensioni inferiori che sono idealmente uguali e che possono essere elaborati in parallelo. Questo metodo riduce il tempo necessario per produrre i dati dalla tabella di origine in ODQ in modo lineare. Questo metodo presuppone che sul lato SAP siano presenti risorse sufficienti per gestire il carico.
Nota
- Il numero di partizioni eseguite in parallelo è limitato dal numero di core del driver nel runtime di integrazione di Azure. Attualmente è in corso una risoluzione per questa limitazione.
- Ogni unità o pacchetto nella transazione SAP ODQMON è un singolo file nella cartella di staging.
Considerazioni sulla progettazione durante l'esecuzione delle pipeline con CDC
Controllare la durata della fase da SAP a fasi.
Controllare le prestazioni di runtime nel sink.
È consigliabile usare la funzionalità di partizionamento per migliorare le prestazioni per migliorare la velocità effettiva.
Se la durata da SAP a fase è lenta, valutare la possibilità di ridimensionare SHIR a specifiche più elevate.
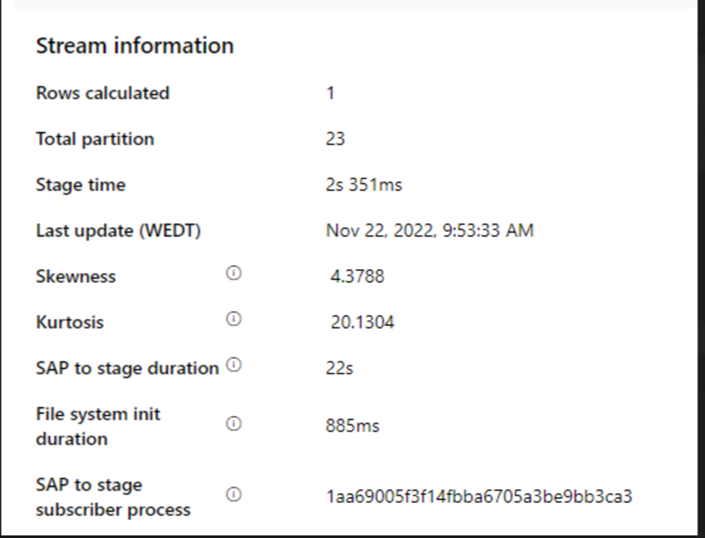
Controllare se il tempo di elaborazione del sink è troppo lento.
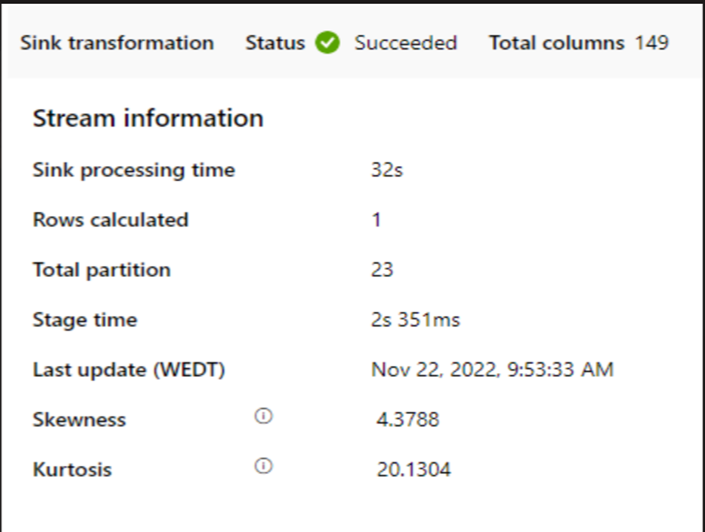
Se un cluster di piccole dimensioni viene usato per eseguire il flusso di dati di mapping, può influire sulle prestazioni nel sink. Usare un cluster di grandi dimensioni, ad esempio 16 + 256 core, in modo che il livello di prestazioni legga i dati dalla fase e scriva nel sink.
Per volumi di dati di grandi dimensioni, è consigliabile partizionare il carico per eseguire processi paralleli, ma mantenere il numero di partizioni minore o uguale al core del runtime di integrazione di Azure, detto anche core del cluster Spark.
Usare la scheda Ottimizza per definire le partizioni. È possibile usare il partizionamento di origine nel connettore CDC.
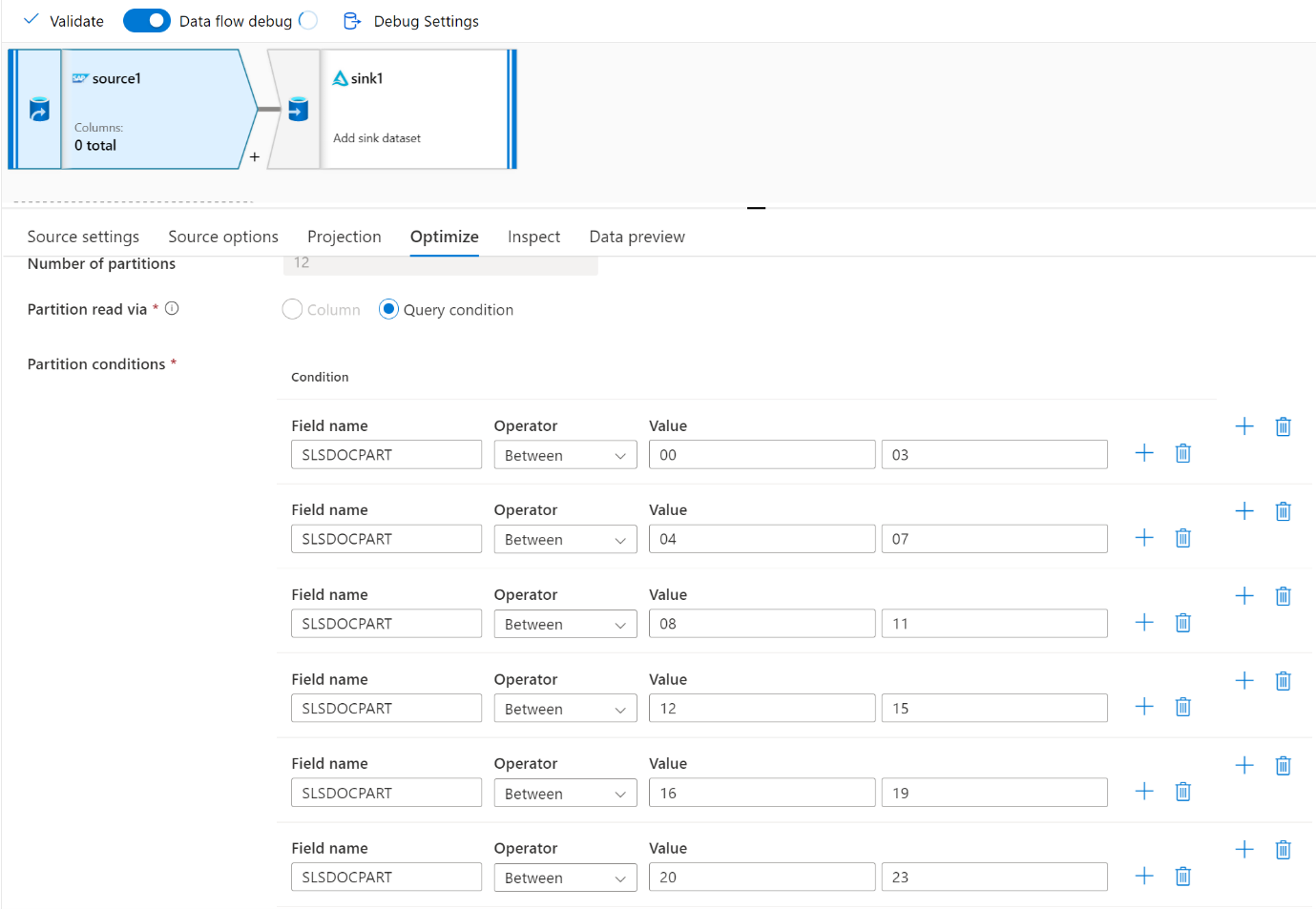
Nota
- Esiste una correlazione diretta tra il numero di partizioni con i core SHIR e i nodi del runtime di integrazione di Azure.
- Il connettore SAP CDC è elencato come tipo di sottoscrittore Odata "Accesso Odata per il provisioning dei dati operativi" in ODQMON nel sistema SAP.
Considerazioni sulla progettazione quando si usa un connettore tabella
- Ottimizzare il partizionamento per ottenere prestazioni migliori.
- Si consideri il grado di parallelismo di SAP Table.
- Si consideri una singola progettazione di file per il sink di destinazione.
- Eseguire il benchmark della velocità effettiva quando si usano volumi di dati di grandi dimensioni.
Suggerimenti per la progettazione quando si usa un connettore Tabella
Partizione: Quando si esegue la partizione nel connettore tabella SAP, un'istruzione select sottostante viene suddivisa in più usando le clausole where in un campo appropriato, ad esempio un campo con cardinalità elevata. Se la tabella SAP ha un volume elevato di dati, abilitare il partizionamento per suddividere i dati in partizioni più piccole. Provare a ottimizzare il numero di partizioni (parametro
maxPartitionsNumber) in modo che le partizioni siano sufficientemente piccole per evitare dump di memoria in SAP, ma sufficientemente grandi da velocizzare l'estrazione.Parallelismo: Il grado di parallelismo di copia (parametro
parallelCopies) funziona in combinazione con il partizionamento e indica al SHIR di effettuare chiamate RFC parallele al sistema SAP. Ad esempio, se si imposta questo parametro su 4, il servizio genera simultaneamente ed esegue quattro query in base all'opzione e alle impostazioni di partizione specificate. Ogni query recupera una parte di dati dalla tabella SAP.Per ottenere risultati ottimali, il numero di partizioni deve essere un multiplo del numero del grado di parallelismo di copia.
Quando si copiano dati da TABELLA SAP a sink binari, il conteggio parallelo effettivo viene modificato automaticamente in base alla quantità di memoria disponibile in SHIR. Registrare le dimensioni della macchina virtuale SHIR per ogni ciclo di test, il grado di parallelismo di copia e il numero di partizioni. Osservare le prestazioni della macchina virtuale SHIR, le prestazioni del sistema SAP di origine e il grado di parallelismo desiderato. Usare un processo iterativo per identificare le impostazioni ottimali e le dimensioni ideali per la macchina virtuale SHIR. Prendere in considerazione tutte le pipeline di inserimento che caricano simultaneamente i dati da uno o più sistemi SAP.
Si noti il numero osservato di chiamate RFC a SAP rispetto al grado di parallelismo configurato. Se il numero di chiamate RFC a SAP è minore del grado di parallelismo, verificare che la macchina virtuale SHIR disponga di risorse di memoria e CPU sufficienti. Se necessario, scegliere una macchina virtuale più grande. Il sistema SAP di origine è configurato per limitare il numero di connessioni parallele. Per altre informazioni, vedere la sezione Raccomandazioni generali in questo articolo.
Numero di file: Quando si copiano dati in un archivio dati basato su file e il sink di destinazione è configurato per essere una cartella, per impostazione predefinita vengono generati più file. Se si imposta la
fileNameproprietà nel sink, i dati sono scritti in un singolo file. È consigliabile scrivere in una cartella come più file perché ottiene una velocità effettiva di scrittura superiore rispetto alla scrittura in un singolo file.Benchmark delle prestazioni: È consigliabile usare l'esercizio di benchmarking delle prestazioni per inserire grandi quantità di dati. Questo metodo varia parametri, ad esempio partizionamento, grado di parallelismo e numero di file per determinare l'impostazione ottimale per l'architettura, il volume e il tipo di dati specificati. Raccogliere i dati dai test nel formato seguente.


Risoluzione dei problemi
Per l'estrazione lenta o non riuscita dal sistema SAP, usare i log SAP da SM37 e li corrispondono alle letture in Data Factory.
Se viene attivato un solo processo batch, impostare le partizioni di origine SAP per migliorare le prestazioni nel flusso di dati di mapping in Data Factory. Per altre informazioni, vedere passaggio 6 nelle proprietà del flusso di dati mappa.
Se più processi batch vengono attivati nel sistema SAP e si verifica una differenza significativa tra l'ora di inizio di ogni processo batch, modificare le dimensioni di Azure IR. Quando si aumenta il numero di nodi driver in Azure IR, il parallelismo dei processi batch nel lato SAP aumenta.
Nota
Il numero massimo di nodi driver per Azure IR è 16. Ogni nodo driver può attivare un solo processo batch.
Controllare i log in SHIR. Per visualizzare i log, passare alla macchina virtuale SHIR. Aprire Applicazioni visualizzatore > eventi e log dei servizi > Connectors > Integration runtime.
Per inviare i log al supporto, passare alla macchina virtuale SHIR. Aprire i log di invio di > diagnostica di Configuration Manager > Integration Runtime. Questa azione invia i log degli ultimi sette giorni e fornisce un ID report. È necessario questo ID report e RunId dell'esecuzione. Documentare l'ID report per informazioni di riferimento future.
Quando si usa il connettore SAP CDC in uno scenario SLT:
Assicurarsi che siano soddisfatti i prerequisiti. I ruoli sono necessari per l'utente SLT (SAP Landscape Transformation), ad esempio ADFSLTUSER nei sistemi OLTP o ECC per il funzionamento della replica SLT. Per altre informazioni, vedere Informazioni sulle autorizzazioni e i ruoli necessari.
Se si verificano errori in uno scenario SLT, vedere i consigli per l'analisi. Isolare e testare prima lo scenario all'interno della soluzione SAP. Ad esempio, testarlo all'esterno di Data Factory eseguendo il programma di test fornito da SAP
RODPS_REPL_TESTin SE38. Se il problema si trova sul lato SAP, viene visualizzato lo stesso errore quando si usa il report. È possibile analizzare l'estrazione dei dati in SAP usando il codiceODQMONdi transazione .Se la replica funziona quando si usa questo report di test, ma non con Data Factory, contattare il supporto di Azure o Data Factory.
Nell'esempio seguente viene illustrato un report per
RODPS_REPL_TESTin SE38: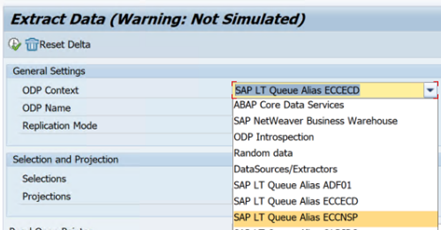
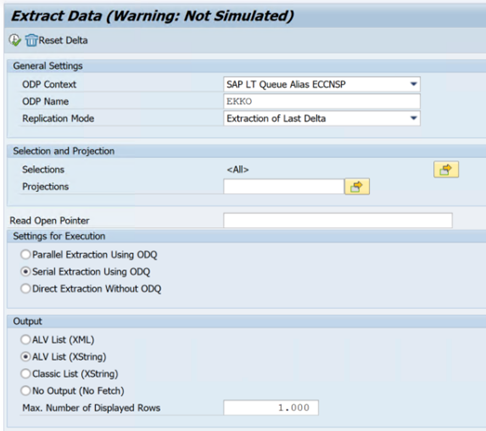

Nell'esempio seguente viene illustrato il codice
ODQMONdella transazione: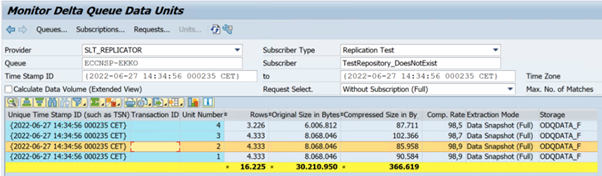
Quando il servizio collegato data factory si connette al sistema SLT, non mostra gli ID trasferimento di massa SLT quando si aggiorna il campo Contesto .
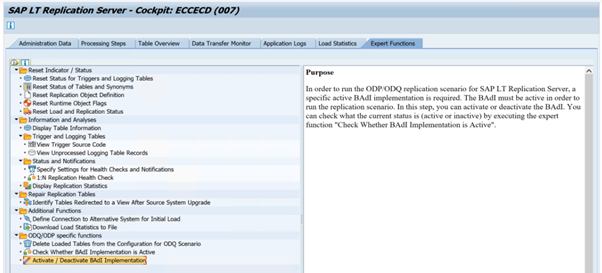
Per eseguire lo scenario di replica ODP/ODQ per il server di replica SAP LT, attivare l'implementazione del componente aggiuntivo aziendale (BAdI) seguente.
Badi:
BADI_ODQ_QUEUE_MODELImplementazione del miglioramento:
ODQ_ENH_SLT_REPLICATIONNella transazione LTRC passare alla scheda Funzione esperto e selezionare Attiva/Disattiva implementazione BAdI per attivare l'implementazione.
Selezionare Sì.
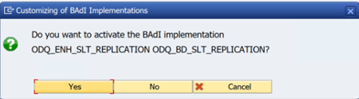
Nella cartella funzioni specifiche ODQ/ODP selezionare Verifica se l'implementazione BAdI è attiva.

La finestra di dialogo mostra l'attività del programma.
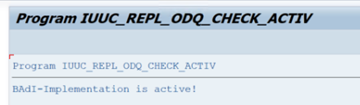
Reimpostare le sottoscrizioni. Per iniziare con un'estrazione nuova o arrestare i dati di replica, rimuovere la sottoscrizione in ODQMON. Questa azione rimuove anche le voci da LTRC. Dopo aver reimpostato la sottoscrizione, potrebbe richiedere alcuni minuti prima di visualizzare l'effetto in LTRC. Pianificare i processi di pulizia del provisioning dei dati operativi (ODP) per mantenere pulite le code delta, ad esempio
ODQ_CLEANUP_CLIENT_004CDS_VIEW (transazione DHCDCMON). A partire da S/4HANA 1909, SAP replica i dati dalle visualizzazioni CDS che usano trigger basati su dati anziché colonne date. Il concetto è simile a SLT, ma invece di usare la transazione LTRC per monitorarla, si usa la transazione DHCDCMON.
Risoluzione dei problemi di SLT
Il server di replica SLT offre la replica dei dati in tempo reale da origini SAP e/o non SAP alle destinazioni SAP e/o non SAP. Esistono tre tipi di set di strumenti per monitorare l'estrazione da SLT ad Azure.
- ODQMON è lo strumento di monitoraggio complessivo per l'estrazione dei dati. Avviare l'analisi con ODQMON per tenere traccia delle incoerenze dei dati, dell'analisi iniziale delle prestazioni e aprire le richieste di sottoscrizione ed estrazione.
- LTRC è la transazione da usare per controllare l'analisi delle prestazioni. È utile se si verificano problemi di replica dei dati dal sistema di origine a ODP perché è possibile monitorare il flusso di dati e trovare inconsistenze.
- SM37 fornisce il monitoraggio dettagliato di ogni passaggio di estrazione SLT.
La normale pulizia deve essere eseguita usando ODQMON in cui è possibile gestire direttamente la sottoscrizione e non è consigliabile usare LTRC per la stessa.
È possibile che si verifichino problemi durante l'estrazione di dati da SLT, ad esempio:
L'estrazione non viene eseguita. Verificare se la connessione SAP CDC ha creato una connessione in ODQMON e verificare se esiste la sottoscrizione.
Incoerenze dei dati. Controllare ODQMON per visualizzare la singola richiesta di dati e verificare che sia possibile visualizzare i dati. Se è possibile visualizzare i dati in ODQMON ma non in Azure Synapse o Data Factory, l'indagine dovrebbe verificarsi sul lato Azure. Se non è possibile visualizzare i dati in ODQMON, eseguire un'analisi del framework SLT usando LTRC.
Problemi di prestazioni. L'estrazione dei dati è un approccio a due passaggi. Prima di tutto, SLT legge i dati dal sistema di origine e lo trasferisce a ODP. In secondo luogo, il connettore SAP CDC raccoglie i dati da ODP e lo trasferisce all'archivio dati scelto. La transazione LTRC consente di analizzare la prima parte del processo di estrazione. Per analizzare l'estrazione dei dati da ODP ad Azure, usare ODQMON e Data Factory o Strumenti di monitoraggio di Synapse.
Nota
Per ulteriori informazioni, vedere le risorse:
Prestazioni SLT
Nella modalità di caricamento iniziale (ODPSLT) sono necessari tre passaggi per estrarre i dati da SLT in ODP:
- Creare oggetti di migrazione. Questo processo richiede solo un paio di secondi.
- Accedere al calcolo del piano che suddivide la tabella di origine in blocchi più piccoli. Questo passaggio dipende dalla modalità di carico iniziale selezionata durante la configurazione SLT e le dimensioni della tabella. L'opzione ottimizzata per le risorse è consigliata.
- Il caricamento dei dati trasferisce i dati dal sistema di origine a ODP.
Ogni passaggio è controllato dai processi in background. È possibile utilizzare le transazioni SM37 e LTRC per monitorare la durata. Se il sistema viene sovrautilato, i processi in background potrebbero essere avviati in un secondo momento perché non sono presenti processi di lavoro batch gratuiti sufficienti. Quando le attività sono inattive, le prestazioni risentono.
Se il calcolo del piano di accesso richiede molto tempo e la modalità di caricamento iniziale è impostata su "ottimizzato per le prestazioni", modificarla in "ottimizzata per le risorse" ed eseguire di nuovo l'estrazione. Se il caricamento dei dati richiede molto tempo, aumentare il numero di thread paralleli nella configurazione.
Se si usa un'architettura autonoma per la replica SLT (server di replica SLT dedicato), la velocità effettiva di rete tra il sistema di origine e il server di replica potrebbe influire sulle prestazioni di estrazione.
Per la replica:
- Assicurarsi di disporre di processi di trasferimento dati sufficienti che non sono riservati per il caricamento iniziale.
- Verificare di non avere un record di tabella di registrazione non elaborato nelle statistiche di caricamento.
- Assicurarsi che l'opzione di replica sia impostata su in tempo reale.
Le impostazioni di replica avanzate sono disponibili in LTRS. Per altre informazioni, vedere la guida alla risoluzione dei problemi SLT.
Diverse versioni sap hanno interfacce utente LTRC diverse. Gli screenshot seguenti mostrano la stessa pagina per due versioni diverse.
SAP S/4HANA:

SAP ECC:



Monitoraggio
Per informazioni sul monitoraggio dell'estrazione dei dati SAP, vedere queste risorse: