Punteggio di attendibilità di una risposta
Quando una query dell'utente viene confrontata con una knowledge base, QnA Maker restituisce le risposte pertinenti insieme a un punteggio di attendibilità. Questo punteggio indica la probabilità che la risposta corrisponda perfettamente alla query dell'utente specificata.
Il punteggio di attendibilità è un numero compreso tra 0 e 100. Un punteggio pari a 100 indica probabilmente una corrispondenza esatta, mentre un punteggio pari a 0 indica che non è stata trovata alcuna risposta corrispondente. Maggiore sarà il punteggio, maggiore sarà l'attendibilità della risposta. Per una determinata query potrebbero essere restituite più risposte. In questo caso le risposte sono restituite in ordine decrescente in base al punteggio di attendibilità.
Nell'esempio seguente è possibile vedere una sola entità domanda/risposta con 2 domande.

Per l'esempio precedente è possibile aspettarsi punteggi come quelli dell'intervallo di esempio riportato di seguito, per diversi tipi di query utente:
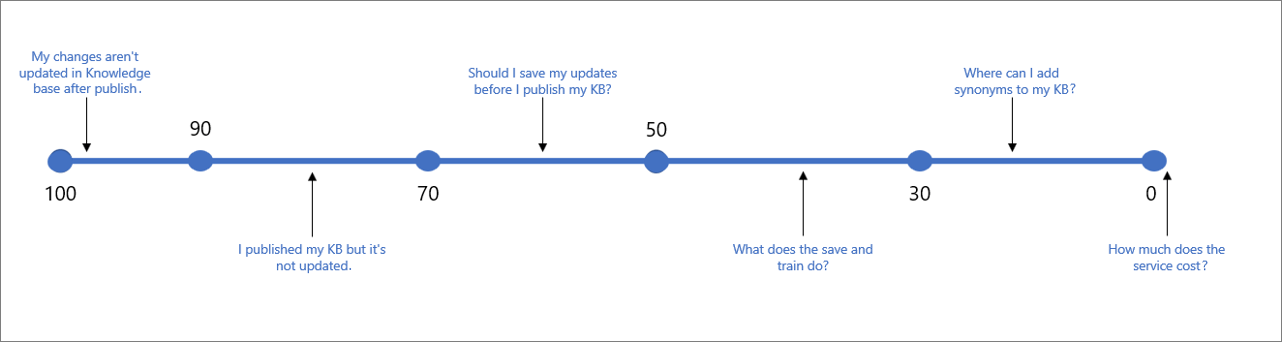
La tabella seguente indica l'attendibilità tipica associata a un determinato punteggio.
| Valore del punteggio | Significato del punteggio | Query di esempio |
|---|---|---|
| 90-100 | Corrispondenza quasi esatta tra query dell'utente e domanda della knowledge base | "Le modifiche non vengono aggiornate nella knowledge base dopo la pubblicazione" |
| > 70 | Attendibilità elevata: in genere una risposta appropriata che risponde completamente alla query dell'utente | "Ho pubblicato la mia knowledge base ma non è aggiornata" |
| 50-70 | Attendibilità media: in genere una risposta piuttosto appropriata che dovrebbe rispondere alla finalità principale della query dell'utente | "Devo salvare gli aggiornamenti personali prima di pubblicare la mia knowledge base?" |
| 30-50 | Attendibilità bassa: in genere una risposta correlata che risponde parzialmente alla finalità dell'utente | "Cosa fa la funzione Save and train (Salva ed esegui training)?" |
| < 30 | Attendibilità molto bassa: in genere non risponde alla query dell'utente, ma include alcune parole o frasi corrispondenti | "Dove posso aggiungere sinonimi alla mia knowledge base?" |
| 0 | Nessuna corrispondenza, perciò non viene restituita alcuna risposta. | "Quanto costa il servizio?" |
Scegliere un punteggio soglia
La tabella precedente illustra i punteggi previsti nella maggior parte delle knowledge base. Tuttavia, poiché ogni KB è diverso e presenta diversi tipi di parole, finalità e obiettivi, è consigliabile testare e scegliere la soglia più adatta. Per impostazione predefinita, la soglia è impostata su 0, in modo che vengano restituite tutte le risposte possibili. La soglia consigliata che dovrebbe funzionare per la maggior parte dei KB è 50.
Quando si sceglie la soglia, tenere presente il bilanciamento tra Accuracy (Precisione) e Coverage (Attinenza) e modificare la soglia in base alle esigenze.
Quando Accuracy (Precisione) è più importante, aumentare la soglia. In questo modo, ogni volta che una risposta viene restituita, essa sarà molto più ATTENDIBILE e avrà una probabilità molto maggiore di essere quella che l'utente sta cercando. In questo modo molte domande potrebbero rimanere senza risposta. Ad esempio: se si imposta la soglia su 70, si potrebbe escludere alcuni esempi ambigui come "Cosa fa la funzione Save and train (Salva ed esegui training)?".
Se Coverage (Attinenza) è più importante e si desidera rispondere al massimo numero di domande possibile, anche se la risposta ha una relazione solo parziale con la domanda dell'utente, ABBASSARE la soglia. In questo modo potrebbero esserci più casi in cui la risposta non risponde all'effettiva query dell'utente ma offre informazioni attinenti alla domanda. Ad esempio: se si imposta la soglia 30, è possibile fornire risposte per le query come "Dove è possibile modificare la knowledge base?"
Nota
Le versioni più recenti di QnA Maker includono miglioramenti della logica di assegnazione dei punteggi e potrebbero influire sulla soglia. Ogni volta che si aggiorna il servizio, assicurarsi di testare e modificare la soglia, se necessario. È possibile controllare la versione del servizio QnA qui e scoprire come ottenere gli aggiornamenti più recenti qui.
Imposta soglia
Impostare il punteggio di soglia come proprietà del corpo JSON dell'API GenerateAnswer. Ciò significa che è stato impostato per ogni chiamata a GenerateAnswer.
Dal framework bot impostare il punteggio come parte dell'oggetto opzioni con C# o Node.js.
Migliorare i punteggi di attendibilità
Per ottimizzare il punteggio di attendibilità di una particolare risposta a una query dell'utente, è possibile aggiungere la query alla Knowledge Base come domanda alternativa per tale risposta. È anche possibile usare variazioni delle parole senza distinzione tra maiuscole e minuscole per aggiungere i sinonimi alle parole chiave nella Knowledge Base.
Punteggi di attendibilità simili
Quando più risposte hanno un punteggio di attendibilità simile, è probabile che la query fosse troppo generica e quindi associata con pari probabilità a più risposte. Provare a strutturare meglio le domande e le risposte in modo che ogni entità di domanda/risposta abbia una finalità distinta.
Differenze di punteggio di attendibilità tra test e produzione
Il punteggio di attendibilità di una risposta può variare in modo trascurabile tra la versione di test e la versione pubblicata della Knowledge Base, anche se il contenuto è lo stesso. Ciò è dovuto al fatto che il contenuto del test e della Knowledge Base pubblicata si trova in diversi indici di Ricerca intelligenza artificiale di Azure.
L'indice di test contiene tutte le coppie QnA delle knowledge base. Quando si esegue una query sull'indice di test, la query si applica all'intero indice, i risultati vengono limitati alla partizione per tale knowledge base specifica. Se i risultati della query di test influiscono negativamente sulla possibilità di convalidare la knowledge base, è possibile:
- organizzare la knowledge base usando uno dei seguenti elementi:
- 1 risorsa limitata a 1 KB: limitare la singola risorsa QnA (e l'indice di test di Ricerca intelligenza artificiale di Azure risultante) a una singola knowledge base.
- 2 risorse - 1 per il test, 1 per la produzione: hanno due risorse QnA Maker, usando una per i test (con i propri indici di test e produzione) e una per il prodotto (con i propri indici di test e produzione) e una per il prodotto (con i propri indici di test e produzione)
- e, usare sempre gli stessi parametri, ad esempio top durante l'esecuzione di query sia sulla knowledge base di test che di produzione
Quando si pubblica una knowledge base, il contenuto di domande e risposte della knowledge base passa dall'indice di test a un indice di produzione in Ricerca di Azure. Vedere come funziona l'operazione di pubblicazione.
Se si ha una knowledge base in aree diverse, ogni area usa il proprio indice di Ricerca intelligenza artificiale di Azure. Poiché vengono usati indici diversi, i punteggi non saranno esattamente gli stessi.
Nessuna corrispondenza trovata
Se lo strumento di classificazione non trova corrispondenze soddisfacenti, viene restituito il punteggio di attendibilità di 0.0 oppure "None" (Nessuno) e la risposta predefinita è "No good match found in the KB" (Nessuna buona corrispondenza trovata nella Knowledge Base). È possibile eseguire l'override di questa risposta predefinita nel codice del bot o dell'applicazione che chiama l'endpoint. In alternativa è anche possibile impostare la risposta sostitutiva in Azure, modificando così la risposta predefinita per tutte le Knowledge Base distribuite in un particolare servizio QnA Maker.