Guida introduttiva: Analisi del testo personalizzati per l'integrità
Usare questo articolo per iniziare a creare un Analisi del testo personalizzato per il progetto di integrità, in cui è possibile eseguire il training di modelli personalizzati oltre a Analisi del testo per l'integrità per il riconoscimento di entità personalizzate. Un modello è un software di intelligenza artificiale sottoposto a training per eseguire una determinata attività. Per questo sistema, i modelli estraggono le entità denominate correlate al settore sanitario e vengono sottoposti a training tramite l'apprendimento dai dati etichettati.
In questo articolo si usa Language Studio per illustrare i concetti chiave delle Analisi del testo personalizzate per l'integrità. Ad esempio, si creerà un Analisi del testo personalizzato per il modello sanitario per estrarre la posizione della struttura o del trattamento da brevi note di scaricamento.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
Creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure e un account di archiviazione di Azure
Prima di poter usare Analisi del testo personalizzate per l'integrità, è necessario creare una risorsa del linguaggio di intelligenza artificiale di Azure, che consentirà di fornire le credenziali necessarie per creare un progetto e avviare il training di un modello. È anche necessario un account di archiviazione di Azure, in cui è possibile caricare il set di dati usato per compilare il modello.
Importante
Per iniziare rapidamente, è consigliabile creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure seguendo la procedura descritta in questo articolo. La procedura descritta in questo articolo consentirà di creare contemporaneamente la risorsa di linguaggio e l'account di archiviazione, che è più semplice rispetto a farlo in un secondo momento.
Se si dispone di una risorsa preesistente che si vuole usare, sarà necessario connetterla all'account di archiviazione. Per altre informazioni, vedere indicazioni sull'uso di una risorsa preesistente.
Creare una nuova risorsa dal portale di Azure
Accedere al portale di Azure per creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure.
Nella finestra visualizzata selezionare Classificazione testo personalizzata e riconoscimento di entità denominate personalizzate dalle funzionalità personalizzate. Selezionare Continua per creare la risorsa nella parte inferiore della schermata .
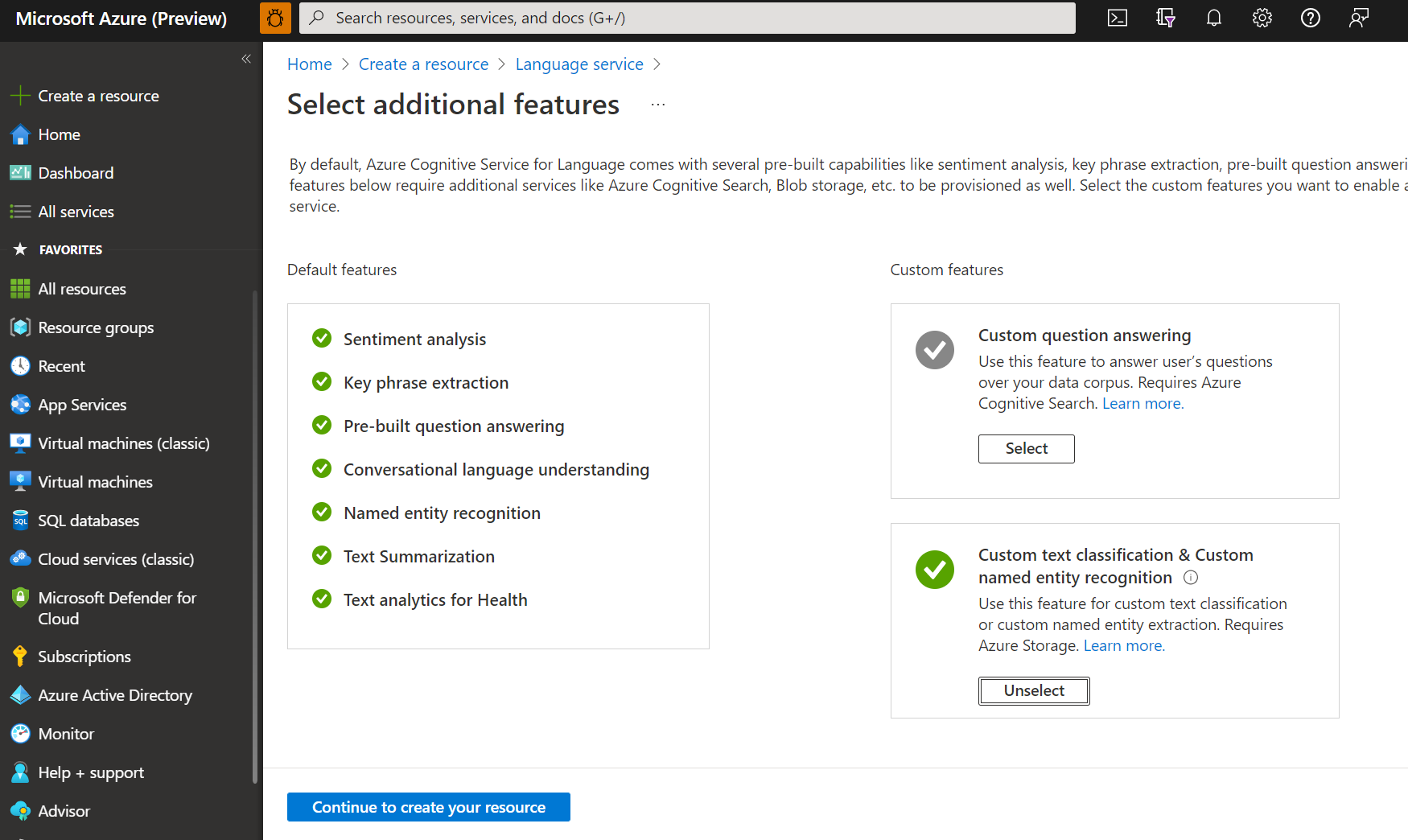
Creare una risorsa lingua con i dettagli seguenti.
Nome Descrizione Abbonamento La sottoscrizione di Azure. Gruppo di risorse Gruppo di risorse che conterrà la risorsa. È possibile usare uno esistente o crearne uno nuovo. Area Area per la risorsa lingua. Ad esempio, "Stati Uniti occidentali 2". Nome Nome della risorsa. Piano tariffario Piano tariffario per la risorsa Lingua. È possibile usare il livello Gratuito (F0) per provare il servizio. Nota
Se viene visualizzato un messaggio che indica che l'account di accesso non è un proprietario del gruppo di risorse dell'account di archiviazione selezionato, l'account deve avere un ruolo di proprietario assegnato nel gruppo di risorse prima di poter creare una risorsa lingua. Per assistenza, contattare il proprietario della sottoscrizione di Azure.
Nella sezione Classificazione testo personalizzata e riconoscimento di entità denominate personalizzate selezionare un account di archiviazione esistente o selezionare Nuovo account di archiviazione. Questi valori consentono di iniziare e non necessariamente i valori dell'account di archiviazione da usare negli ambienti di produzione. Per evitare la latenza durante la compilazione del progetto, connettersi agli account di archiviazione nella stessa area della risorsa lingua.
Archiviazione valore dell'account Valore consigliato Nome account di archiviazione Qualsiasi nome Storage account type LRS Standard Assicurarsi che sia selezionata l'informativa sull'intelligenza artificiale responsabile. Selezionare Rivedi e crea nella parte inferiore della pagina e quindi selezionare Crea.

Caricare dati di esempio nel contenitore BLOB
Dopo aver creato un account di archiviazione di Azure e averla connessa alla risorsa Lingua, sarà necessario caricare i documenti dal set di dati di esempio nella directory radice del contenitore. Questi documenti verranno usati successivamente per eseguire il training del modello.
Scaricare il set di dati di esempio da GitHub.
Aprire il file ZIP ed estrarre la cartella contenente i documenti.
Nel portale di Azure passare all'account di archiviazione creato e selezionarlo.
Nell'account di archiviazione selezionare Contenitori nel menu a sinistra, sotto Archiviazione dati. Nella schermata visualizzata selezionare + Contenitore. Assegnare al contenitore il nome example-data e lasciare il livello di accesso pubblico predefinito.
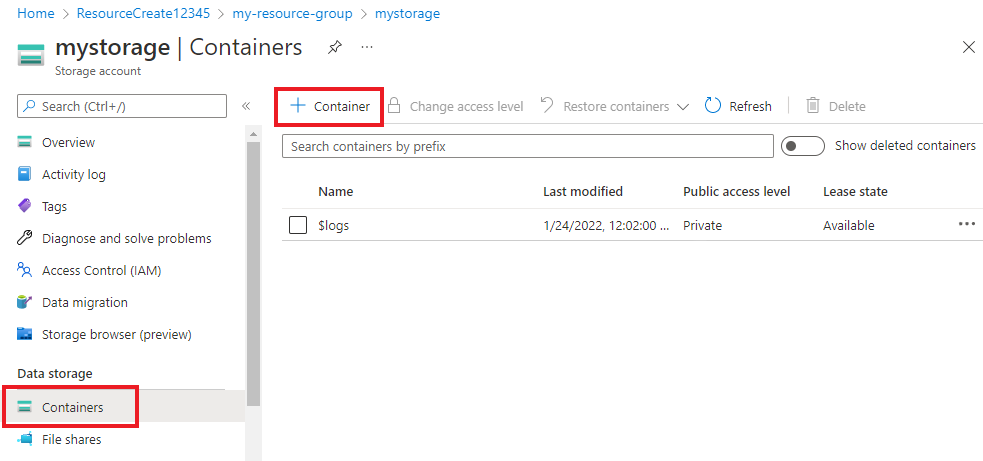
Dopo aver creato il contenitore, selezionarlo. Selezionare quindi il pulsante Carica per selezionare i
.txt.jsonfile e scaricati in precedenza.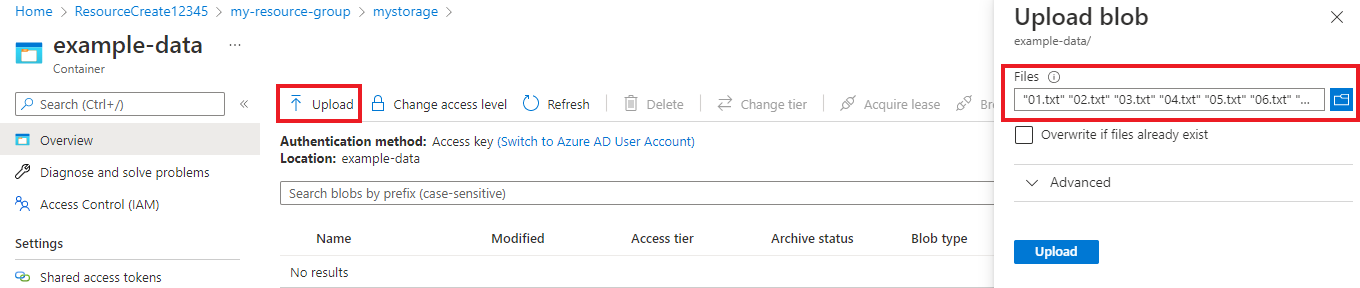


Il set di dati di esempio fornito contiene 12 note cliniche. Ogni nota clinica include diverse entità mediche e la posizione di trattamento. Verranno usate le entità predefinite per estrarre le entità mediche ed eseguire il training del modello personalizzato per estrarre la posizione di trattamento usando i componenti appresi e elencati dell'entità.
Creare un Analisi del testo personalizzato per il progetto di integrità
Dopo aver configurato la risorsa e l'account di archiviazione, creare un nuovo Analisi del testo personalizzato per il progetto di integrità. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa Lingua usata.
Accedere a Language Studio. Verrà visualizzata una finestra che consente di selezionare la sottoscrizione e la risorsa lingua. Selezionare la risorsa Lingua creata nel passaggio precedente.
Nella sezione Estrarre informazioni di Language Studio selezionare Analisi del testo personalizzato per l'integrità.
Selezionare Crea nuovo progetto dal menu in alto nella pagina dei progetti. La creazione di un progetto consente di etichettare i dati, eseguire il training, valutare, migliorare e distribuire i modelli.

Immettere le informazioni sul progetto, inclusi un nome, una descrizione e la lingua dei file nel progetto. Se si usa il set di dati di esempio, selezionare Inglese. Non è possibile modificare il nome del progetto in un secondo momento. Selezionare Avanti.
Suggerimento
Il set di dati non deve essere interamente nello stesso linguaggio. È possibile avere più documenti, ognuno con lingue supportate diverse. Se il set di dati contiene documenti di lingue diverse o se si prevede testo da lingue diverse durante il runtime, selezionare l'opzione Abilita set di dati multilingue quando si immettono le informazioni di base per il progetto. Questa opzione può essere abilitata in un secondo momento dalla pagina Impostazioni progetto.
Dopo aver selezionato Crea nuovo progetto, verrà visualizzata una finestra per consentire la connessione dell'account di archiviazione. Se è già stato connesso un account di archiviazione, verrà visualizzato l'account di archiviazione connesso. In caso contrario, scegliere l'account di archiviazione dall'elenco a discesa visualizzato e selezionare Connessione account di archiviazione. Verranno impostati i ruoli necessari per l'account di archiviazione. Questo passaggio restituirà un errore se non si è assegnati come proprietario nell'account di archiviazione.
Nota
- È necessario eseguire questo passaggio una sola volta per ogni nuova risorsa usata.
- Questo processo è irreversibile, se si connette un account di archiviazione alla risorsa lingua, non è possibile disconnetterlo in un secondo momento.
- È possibile connettere la risorsa lingua solo a un account di archiviazione.
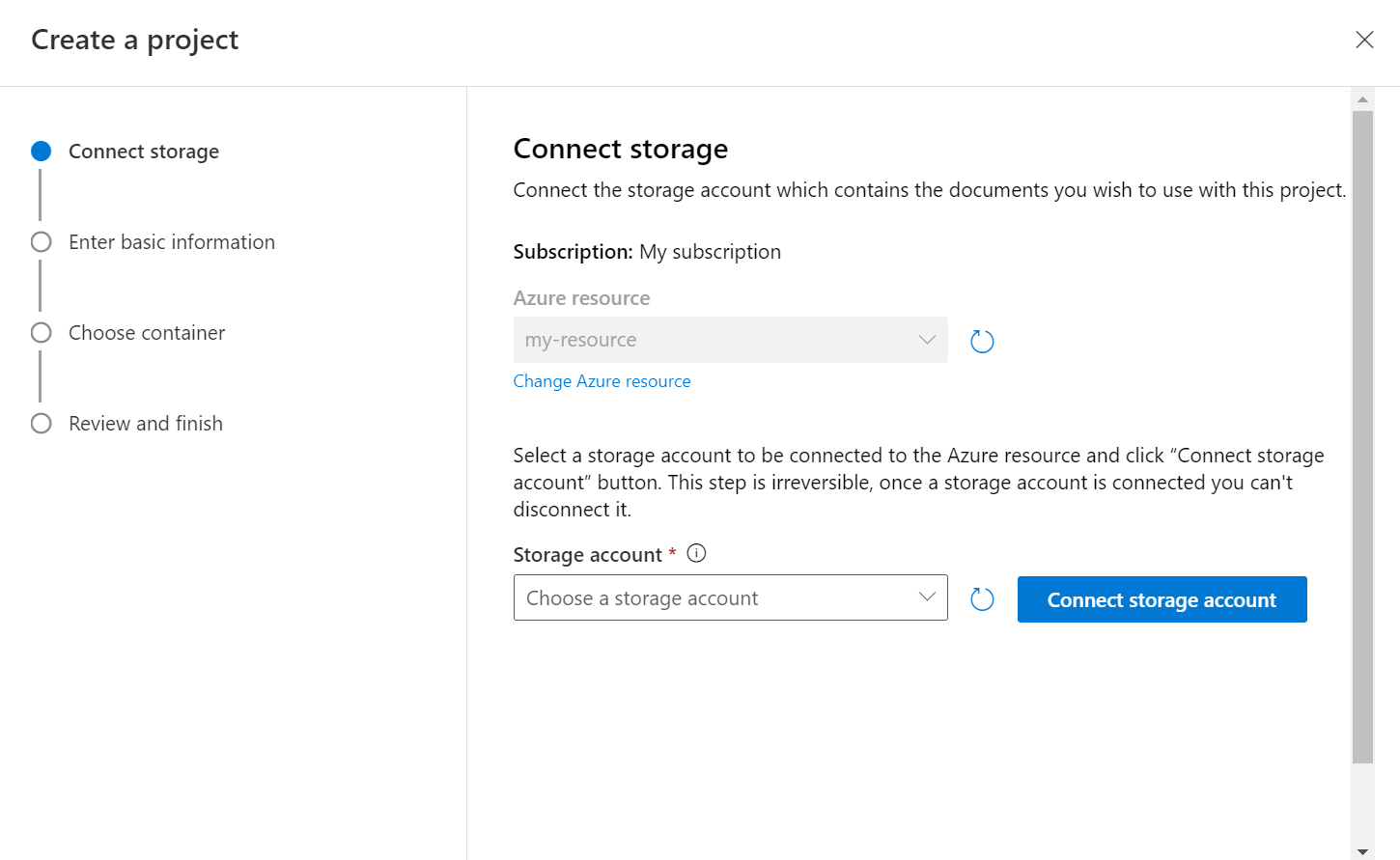
Selezionare il contenitore in cui è stato caricato il set di dati.
Se i dati sono già stati etichettati, assicurarsi che seguano il formato supportato e selezionare Sì, i miei file sono già etichettati e ho formattato il file di etichette JSON e selezionare il file delle etichette dal menu a discesa. Seleziona Avanti. Se si usa il set di dati della guida introduttiva, non è necessario esaminare la formattazione del file di etichette JSON.
Esaminare i dati immessi e selezionare Crea progetto.


Eseguire il training del modello
In genere, dopo aver creato un progetto, è possibile iniziare a etichettare i documenti presenti nel contenitore connesso al progetto. Per questa guida introduttiva è stato importato un set di dati con tag di esempio e il progetto è stato inizializzato con il file di etichette JSON di esempio, quindi non è necessario aggiungere etichette aggiuntive.
Per avviare il training del modello da Language Studio:
Selezionare Processi di training dal menu a sinistra.
Selezionare Avvia un processo di training dal menu in alto.
Selezionare Esegui training di un nuovo modello e digitare il nome del modello nella casella di testo. È anche possibile sovrascrivere un modello esistente selezionando questa opzione e scegliendo il modello da sovrascrivere dal menu a discesa. La sovrascrittura di un modello sottoposto a training è irreversibile, ma non influisce sui modelli distribuiti fino a quando non si distribuisce il nuovo modello.
Selezionare il metodo di suddivisione dei dati. È possibile scegliere Suddivisione automatica del set di test dai dati di training in cui il sistema suddividerà i dati etichettati tra i set di training e di test, in base alle percentuali specificate. In alternativa, è possibile usare una suddivisione manuale dei dati di training e test, questa opzione è abilitata solo se sono stati aggiunti documenti al set di test. Per informazioni sulla suddivisione dei dati, vedere Etichettatura dei dati e come eseguire il training di un modello .
Selezionare il pulsante Train (Esegui training ).
Se si seleziona l'ID processo di training nell'elenco, verrà visualizzato un riquadro laterale in cui è possibile controllare lo stato del training, lo stato del processo e altri dettagli per questo processo.
Nota
- Solo i processi di training completati correttamente genereranno modelli.
- Il training può richiedere tempo tra un paio di minuti e diverse ore in base alle dimensioni dei dati etichettati.
- È possibile eseguire un solo processo di training alla volta. Non è possibile avviare altri processi di training nello stesso progetto fino al completamento del processo in esecuzione.

Distribuire il modello
In genere dopo il training di un modello, esaminare i relativi dettagli di valutazione e apportare miglioramenti, se necessario. In questa guida introduttiva si distribuirà semplicemente il modello e lo si renderà disponibile per provare in Language Studio oppure è possibile chiamare l'API di stima.
Per distribuire il modello da Language Studio:
Selezionare Deploying a model (Distribuzione di un modello ) dal menu a sinistra.
Selezionare Aggiungi distribuzione per avviare un nuovo processo di distribuzione.
Selezionare Crea nuova distribuzione per creare una nuova distribuzione e assegnare un modello sottoposto a training nell'elenco a discesa seguente. È anche possibile sovrascrivere una distribuzione esistente selezionando questa opzione e selezionando il modello sottoposto a training che si vuole assegnare al modello dall'elenco a discesa seguente.
Nota
La sovrascrittura di una distribuzione esistente non richiede modifiche alla chiamata api di stima, ma i risultati ottenuti saranno basati sul modello appena assegnato.
Selezionare Distribuisci per avviare il processo di distribuzione.
Al termine della distribuzione, accanto verrà visualizzata una data di scadenza. La scadenza della distribuzione è quando il modello distribuito non sarà disponibile per la stima, che in genere si verifica dodici mesi dopo la scadenza di una configurazione di training.


Testare il modello
Dopo aver distribuito il modello, è possibile iniziare a usarlo per estrarre le entità dal testo tramite l'API Prediction. Per questa guida introduttiva si userà Language Studio per inviare il Analisi del testo personalizzato per l'attività di stima dell'integrità e visualizzare i risultati. Nel set di dati di esempio scaricato in precedenza è possibile trovare alcuni documenti di test che è possibile usare in questo passaggio.
Per testare i modelli distribuiti da Language Studio:
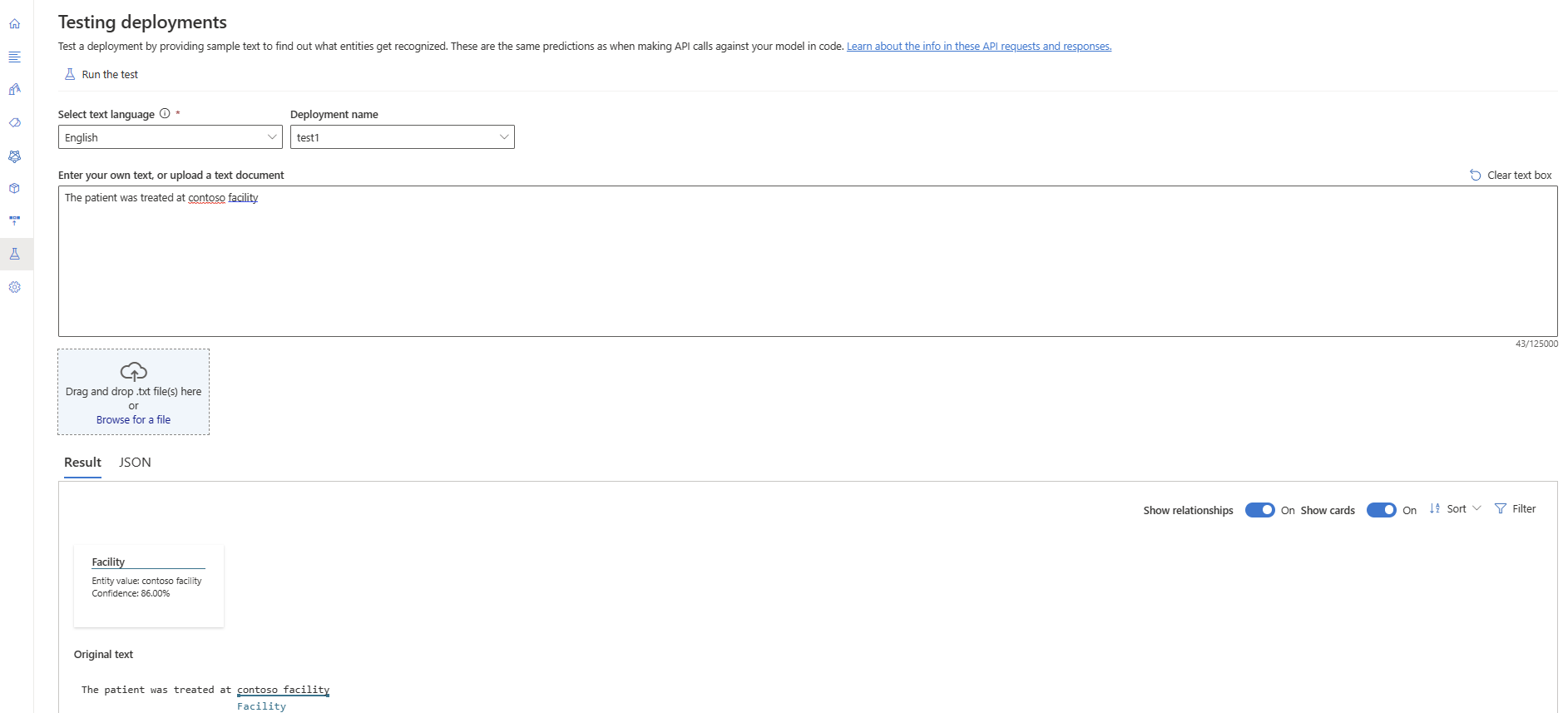
Selezionare Test delle distribuzioni dal menu a sinistra.
Selezionare la distribuzione da testare. È possibile testare solo i modelli assegnati alle distribuzioni.
Selezionare la distribuzione da eseguire query/test dall'elenco a discesa.
È possibile immettere il testo da inviare alla richiesta o caricare un
.txtfile da usare.Selezionare Esegui il test dal menu in alto.
Nella scheda Risultato è possibile visualizzare le entità estratte dal testo e i relativi tipi. È anche possibile visualizzare la risposta JSON nella scheda JSON .

Pulire le risorse
Quando il progetto non è più necessario, è possibile eliminare il progetto usando Language Studio.
- Selezionare la funzionalità del servizio di linguaggio in uso nella parte superiore della pagina,
- Selezionare il progetto da eliminare
- Selezionare Elimina nel menu in alto.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
Creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure e un account di archiviazione di Azure
Prima di poter usare Analisi del testo personalizzate per l'integrità, è necessario creare una risorsa del linguaggio di intelligenza artificiale di Azure, che fornirà le credenziali necessarie per creare un progetto e avviare il training di un modello. È anche necessario un account di archiviazione di Azure, in cui è possibile caricare il set di dati che verrà usato per compilare il modello.
Importante
Per iniziare rapidamente, è consigliabile creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure seguendo la procedura descritta in questo articolo, che consente di creare la risorsa Lingua e creare e/o connettere un account di archiviazione contemporaneamente, che è più semplice rispetto a farlo in un secondo momento.
Se si dispone di una risorsa preesistente che si vuole usare, sarà necessario connetterla all'account di archiviazione. Per altre informazioni, vedere Creare un progetto .
Creare una nuova risorsa dal portale di Azure
Accedere al portale di Azure per creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure.
Nella finestra visualizzata selezionare Classificazione testo personalizzata e riconoscimento di entità denominate personalizzate dalle funzionalità personalizzate. Selezionare Continua per creare la risorsa nella parte inferiore della schermata .
Creare una risorsa lingua con i dettagli seguenti.
Nome Descrizione Abbonamento La sottoscrizione di Azure. Gruppo di risorse Gruppo di risorse che conterrà la risorsa. È possibile usare uno esistente o crearne uno nuovo. Area Area per la risorsa lingua. Ad esempio, "Stati Uniti occidentali 2". Nome Nome della risorsa. Piano tariffario Piano tariffario per la risorsa Lingua. È possibile usare il livello Gratuito (F0) per provare il servizio. Nota
Se viene visualizzato un messaggio che indica che l'account di accesso non è un proprietario del gruppo di risorse dell'account di archiviazione selezionato, l'account deve avere un ruolo di proprietario assegnato nel gruppo di risorse prima di poter creare una risorsa lingua. Per assistenza, contattare il proprietario della sottoscrizione di Azure.
Nella sezione Classificazione testo personalizzata e riconoscimento di entità denominate personalizzate selezionare un account di archiviazione esistente o selezionare Nuovo account di archiviazione. Questi valori consentono di iniziare e non necessariamente i valori dell'account di archiviazione da usare negli ambienti di produzione. Per evitare la latenza durante la compilazione del progetto, connettersi agli account di archiviazione nella stessa area della risorsa lingua.
Archiviazione valore dell'account Valore consigliato Nome account di archiviazione Qualsiasi nome Storage account type LRS Standard Assicurarsi che sia selezionata l'informativa sull'intelligenza artificiale responsabile. Selezionare Rivedi e crea nella parte inferiore della pagina e quindi selezionare Crea.
Caricare dati di esempio nel contenitore BLOB
Dopo aver creato un account di archiviazione di Azure e averla connessa alla risorsa Lingua, sarà necessario caricare i documenti dal set di dati di esempio nella directory radice del contenitore. Questi documenti verranno usati successivamente per eseguire il training del modello.
Scaricare il set di dati di esempio da GitHub.
Aprire il file ZIP ed estrarre la cartella contenente i documenti.
Nel portale di Azure passare all'account di archiviazione creato e selezionarlo.
Nell'account di archiviazione selezionare Contenitori nel menu a sinistra, sotto Archiviazione dati. Nella schermata visualizzata selezionare + Contenitore. Assegnare al contenitore il nome example-data e lasciare il livello di accesso pubblico predefinito.
Dopo aver creato il contenitore, selezionarlo. Selezionare quindi il pulsante Carica per selezionare i
.txt.jsonfile e scaricati in precedenza.
Il set di dati di esempio fornito contiene 12 note cliniche. Ogni nota clinica include diverse entità mediche e la posizione di trattamento. Verranno usate le entità predefinite per estrarre le entità mediche ed eseguire il training del modello personalizzato per estrarre la posizione di trattamento usando i componenti appresi e elencati dell'entità.
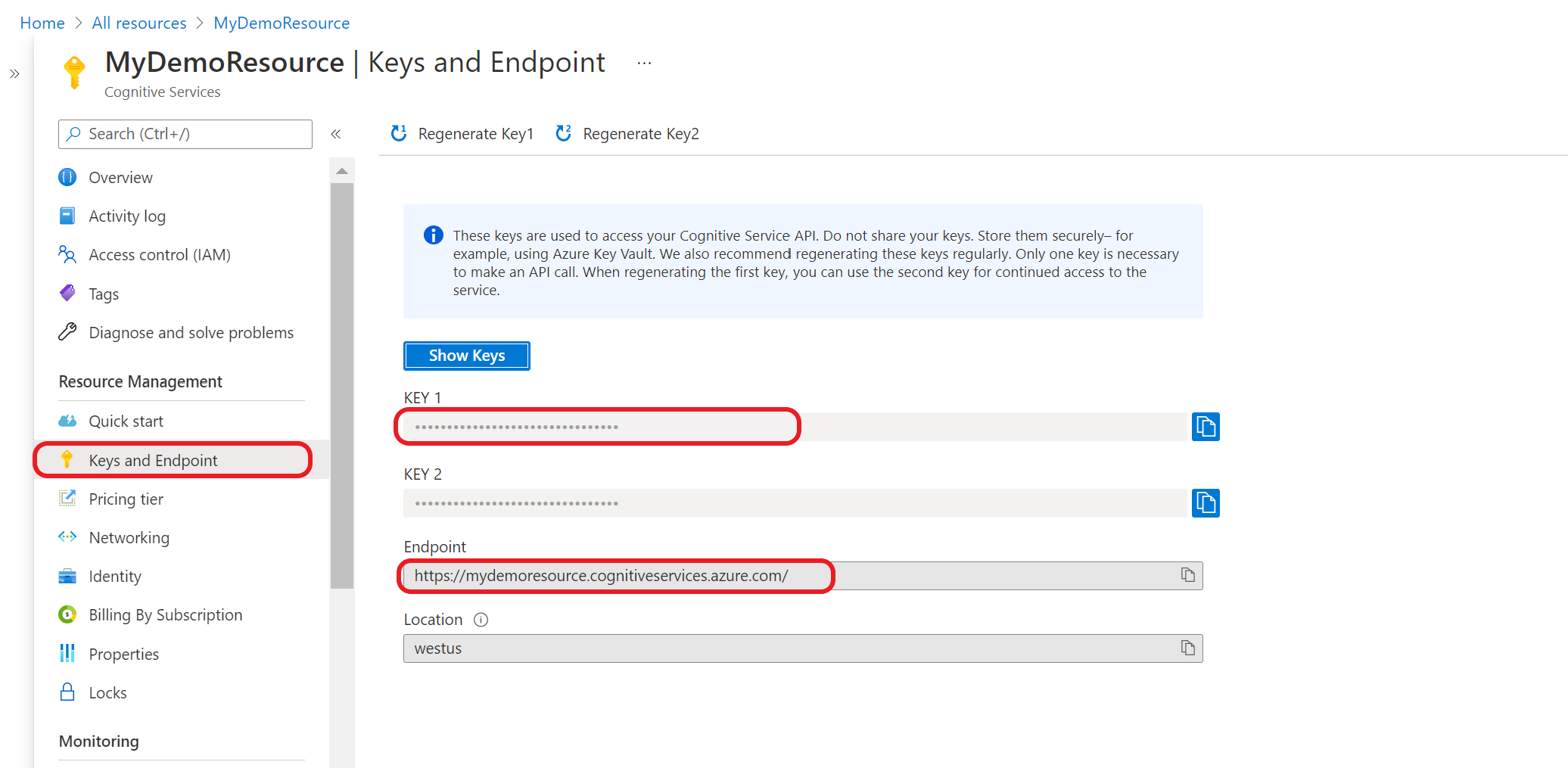
Ottenere le chiavi di risorsa e l'endpoint
Passare alla pagina di panoramica delle risorse nel portale di Azure
Dal menu a sinistra selezionare Chiavi ed Endpoint. Si useranno l'endpoint e la chiave per le richieste API

Creare un Analisi del testo personalizzato per il progetto di integrità
Dopo aver configurato la risorsa e l'account di archiviazione, creare un nuovo Analisi del testo personalizzato per il progetto di integrità. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa Lingua usata.
Usare il file di etichette scaricato dai dati di esempio nel passaggio precedente e aggiungerlo al corpo della richiesta seguente.
Attivare il processo di importazione del progetto
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per importare il file di etichette. Assicurarsi che il file delle etichette segua il formato accettato.
Se esiste già un progetto con lo stesso nome, i dati del progetto vengono sostituiti.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/:import?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per l'autenticazione delle richieste API. |
Corpo
Usare il codice JSON seguente nella richiesta. Sostituire i valori segnaposto seguenti con i propri valori.
{
"projectFileVersion": "{API-VERSION}",
"stringIndexType": "Utf16CodeUnit",
"metadata": {
"projectName": "{PROJECT-NAME}",
"projectKind": "CustomHealthcare",
"description": "Trying out custom Text Analytics for health",
"language": "{LANGUAGE-CODE}",
"multilingual": true,
"storageInputContainerName": "{CONTAINER-NAME}",
"settings": {}
},
"assets": {
"projectKind": "CustomHealthcare",
"entities": [
{
"category": "Entity1",
"compositionSetting": "{COMPOSITION-SETTING}",
"list": {
"sublists": [
{
"listKey": "One",
"synonyms": [
{
"language": "en",
"values": [
"EntityNumberOne",
"FirstEntity"
]
}
]
}
]
}
},
{
"category": "Entity2"
},
{
"category": "MedicationName",
"list": {
"sublists": [
{
"listKey": "research drugs",
"synonyms": [
{
"language": "en",
"values": [
"rdrug a",
"rdrug b"
]
}
]
}
]
}
"prebuilts": "MedicationName"
}
],
"documents": [
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 500,
"labels": [
{
"category": "Entity1",
"offset": 25,
"length": 10
},
{
"category": "Entity2",
"offset": 120,
"length": 8
}
]
}
]
},
{
"location": "{DOCUMENT-NAME}",
"language": "{LANGUAGE-CODE}",
"dataset": "{DATASET}",
"entities": [
{
"regionOffset": 0,
"regionLength": 100,
"labels": [
{
"category": "Entity2",
"offset": 20,
"length": 5
}
]
}
]
}
]
}
}
| Key | Segnaposto | Valore | Esempio |
|---|---|---|---|
multilingual |
true |
Valore booleano che consente di avere documenti in più lingue nel set di dati e quando il modello viene distribuito, è possibile eseguire query sul modello in qualsiasi linguaggio supportato (non necessariamente incluso nei documenti di training). Per altre informazioni sul supporto multilingue, vedere Supporto linguistico. | true |
projectName |
{PROJECT-NAME} |
Nome progetto | myproject |
storageInputContainerName |
{CONTAINER-NAME} |
Nome contenitore | mycontainer |
entities |
Matrice contenente tutti i tipi di entità presenti nel progetto. Questi sono i tipi di entità che verranno estratti dai documenti in. | ||
category |
Nome del tipo di entità, che può essere definito dall'utente per le nuove definizioni di entità o predefinito per le entità predefinite. | ||
compositionSetting |
{COMPOSITION-SETTING} |
Regola che definisce come gestire più componenti nell'entità. Le opzioni sono combineComponents o separateComponents. |
combineComponents |
list |
Matrice contenente tutti gli elenchi secondari presenti nel progetto per un'entità specifica. Gli elenchi possono essere aggiunti alle entità predefinite o alle nuove entità con componenti appresi. | ||
sublists |
[] |
Matrice contenente sottoliste. Ogni sottolista è una chiave e i relativi valori associati. | [] |
listKey |
One |
Valore normalizzato per l'elenco di sinonimi a cui eseguire il mapping nella stima. | One |
synonyms |
[] |
Matrice contenente tutti i sinonimi | sinonimo |
language |
{LANGUAGE-CODE} |
Stringa che specifica il codice della lingua per il sinonimo nell'elenco secondario. Se il progetto è un progetto multilingue e si vuole supportare l'elenco di sinonimi per tutte le lingue del progetto, è necessario aggiungere in modo esplicito i sinonimi a ogni lingua. Per altre informazioni sui codici linguistici supportati, vedere Supporto della lingua. | en |
values |
"EntityNumberone", "FirstEntity" |
Elenco di stringhe separate da virgole corrispondenti esattamente per l'estrazione e il mapping alla chiave di elenco. | "EntityNumberone", "FirstEntity" |
prebuilts |
MedicationName |
Nome del componente predefinito che popola l'entità predefinita. Le entità predefinite vengono caricate automaticamente nel progetto per impostazione predefinita, ma è possibile estenderle con i componenti elenco nel file delle etichette. | MedicationName |
documents |
Matrice contenente tutti i documenti nel progetto e l'elenco delle entità etichettate all'interno di ogni documento. | [] | |
location |
{DOCUMENT-NAME} |
Posizione dei documenti nel contenitore di archiviazione. Poiché tutti i documenti si trovano nella radice del contenitore, questo deve essere il nome del documento. | doc1.txt |
dataset |
{DATASET} |
Set di test su cui verrà eseguito il file quando verrà suddiviso prima del training. I valori possibili per questo campo sono Train e Test. |
Train |
regionOffset |
Posizione del carattere inclusivo dell'inizio del testo. | 0 |
|
regionLength |
Lunghezza del rettangolo di selezione in termini di caratteri UTF16. Il training considera solo i dati in questa area. | 500 |
|
category |
Tipo di entità associata all'intervallo di testo specificato. | Entity1 |
|
offset |
Posizione iniziale per il testo dell'entità. | 25 |
|
length |
Lunghezza dell'entità in termini di caratteri UTF16. | 20 |
|
language |
{LANGUAGE-CODE} |
Stringa che specifica il codice della lingua per il documento usato nel progetto. Se il progetto è un progetto multilingue, scegliere il codice linguistico della maggior parte dei documenti. Per altre informazioni sui codici linguistici supportati, vedere Supporto della lingua. | en |
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica che il processo è stato inviato correttamente. Nelle intestazioni della risposta estrarre il operation-location valore. Il formato sarà simile al seguente:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. Questo URL verrà usato per ottenere lo stato del processo di importazione.
Possibili scenari di errore per questa richiesta:
- La risorsa selezionata non dispone delle autorizzazioni appropriate per l'account di archiviazione.
- L'oggetto
storageInputContainerNamespecificato non esiste. - Viene usato codice linguistico non valido o se il tipo di codice della lingua non è stringa.
multilingualvalue è una stringa e non un valore booleano.
Ottenere lo stato del processo di importazione
Usare la richiesta GET seguente per ottenere lo stato dell'importazione del progetto. Sostituire i valori segnaposto seguenti con i propri valori.
Richiesta URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/import/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{JOB-ID} |
ID per individuare lo stato di training del modello. Questo valore si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per l'autenticazione delle richieste API. |
Eseguire il training del modello
In genere, dopo aver creato un progetto, è possibile iniziare a etichettare i documenti presenti nel contenitore connesso al progetto. Per questa guida introduttiva è stato importato un set di dati con tag di esempio e il progetto è stato inizializzato con il file di tag JSON di esempio.
Avviare il processo di training
Dopo aver importato il progetto, è possibile avviare il training del modello.
Inviare una richiesta POST usando l'URL, le intestazioni e il corpo JSON seguenti per inviare un processo di training. Sostituire i valori segnaposto con i propri valori.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/:train?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per l'autenticazione delle richieste API. |
Corpo della richiesta
Usare il codice JSON seguente nel corpo della richiesta. Al termine del training viene assegnato il {MODEL-NAME} modello. Solo i processi di training con esito positivo producono modelli.
{
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"evaluationOptions": {
"kind": "percentage",
"trainingSplitPercentage": 80,
"testingSplitPercentage": 20
}
}
| Key | Segnaposto | Valore | Esempio |
|---|---|---|---|
| modelLabel | {MODEL-NAME} |
Nome del modello assegnato al modello dopo il training. | myModel |
| trainingConfigVersion | {CONFIG-VERSION} |
Si tratta della versione del modello usata per eseguire il training del modello. | 2022-05-01 |
| evaluationOptions | Opzione per suddividere i dati tra set di training e test. | {} |
|
| kind | percentage |
Metodi di divisione. I possibili valori sono percentage o manual. Per altre informazioni, vedere Come eseguire il training di un modello . |
percentage |
| trainingSplitPercentage | 80 |
Percentuale dei dati con tag da includere nel set di training. Il valore consigliato è 80. |
80 |
| testingSplitPercentage | 20 |
Percentuale dei dati contrassegnati da includere nel set di test. Il valore consigliato è 20. |
20 |
Nota
E trainingSplitPercentagetestingSplitPercentage sono obbligatori solo se Kind è impostato su percentage e la somma di entrambe le percentuali deve essere uguale a 100.
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica che il processo è stato inviato correttamente. Nelle intestazioni della risposta estrarre il location valore. È formattato come segue:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. È possibile usare questo URL per ottenere lo stato del training.
Ottenere lo stato del processo di training
Il training potrebbe richiedere alcuni minuti tra 10 e 30 minuti per questo set di dati di esempio. È possibile usare la richiesta seguente per mantenere il polling dello stato del processo di training fino a quando non viene completato correttamente.
Usare la richiesta GET seguente per ottenere lo stato dello stato di avanzamento del training del modello. Sostituire i valori segnaposto seguenti con i propri valori.
Richiesta URL
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/train/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{JOB-ID} |
ID per individuare lo stato di training del modello. Questo valore si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per l'autenticazione delle richieste API. |
Testo della risposta
Dopo l'invio della richiesta, si otterrà la risposta seguente.
{
"result": {
"modelLabel": "{MODEL-NAME}",
"trainingConfigVersion": "{CONFIG-VERSION}",
"estimatedEndDateTime": "2022-04-18T15:47:58.8190649Z",
"trainingStatus": {
"percentComplete": 3,
"startDateTime": "2022-04-18T15:45:06.8190649Z",
"status": "running"
},
"evaluationStatus": {
"percentComplete": 0,
"status": "notStarted"
}
},
"jobId": "{JOB-ID}",
"createdDateTime": "2022-04-18T15:44:44Z",
"lastUpdatedDateTime": "2022-04-18T15:45:48Z",
"expirationDateTime": "2022-04-25T15:44:44Z",
"status": "running"
}
Distribuire il modello
In genere dopo il training di un modello, esaminare i relativi dettagli di valutazione e apportare miglioramenti, se necessario. In questa guida introduttiva si distribuirà semplicemente il modello e lo si renderà disponibile per provare in Language Studio oppure è possibile chiamare l'API di stima.
Avviare il processo di distribuzione
Inviare una richiesta PUT usando l'URL, le intestazioni e il corpo JSON seguenti per inviare un processo di distribuzione. Sostituire i valori segnaposto seguenti con i propri valori.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}/deployments/{deploymentName}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per l'autenticazione delle richieste API. |
Corpo della richiesta
Usare il codice JSON seguente nel corpo della richiesta. Usare il nome del modello da assegnare alla distribuzione.
{
"trainedModelLabel": "{MODEL-NAME}"
}
| Key | Segnaposto | Valore | Esempio |
|---|---|---|---|
| trainedModelLabel | {MODEL-NAME} |
Nome del modello che verrà assegnato alla distribuzione. È possibile assegnare solo modelli sottoposti a training correttamente. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myModel |
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica che il processo è stato inviato correttamente. Nelle intestazioni della risposta estrarre il operation-location valore. Il formato sarà simile al seguente:
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
{JOB-ID} viene usato per identificare la richiesta, poiché questa operazione è asincrona. È possibile usare questo URL per ottenere lo stato della distribuzione.
Ottenere lo stato del processo di distribuzione
Usare la richiesta GET seguente per eseguire una query sullo stato del processo di distribuzione. È possibile usare l'URL ricevuto dal passaggio precedente oppure sostituire i valori segnaposto seguenti con i propri valori.
{ENDPOINT}/language/authoring/analyze-text/projects/{PROJECT-NAME}/deployments/{DEPLOYMENT-NAME}/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{DEPLOYMENT-NAME} |
Nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | staging |
{JOB-ID} |
ID per individuare lo stato di training del modello. Si trova nel valore dell'intestazione location ricevuto nel passaggio precedente. |
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxx |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
Ocp-Apim-Subscription-Key |
Chiave della risorsa. Usato per l'autenticazione delle richieste API. |
Testo della risposta
Quando si invia la richiesta, si riceverà la richiesta seguente. Continuare a eseguire il polling di questo endpoint fino a quando il parametro di stato non viene modificato in "succeeded". Si dovrebbe ottenere un 200 codice per indicare l'esito positivo della richiesta.
{
"jobId":"{JOB-ID}",
"createdDateTime":"{CREATED-TIME}",
"lastUpdatedDateTime":"{UPDATED-TIME}",
"expirationDateTime":"{EXPIRATION-TIME}",
"status":"running"
}
Eseguire stime con il modello sottoposto a training
Dopo aver distribuito il modello, è possibile iniziare a usarlo per estrarre le entità dal testo usando l'API di stima. Nel set di dati di esempio scaricato in precedenza è possibile trovare alcuni documenti di test che è possibile usare in questo passaggio.
Inviare un Analisi del testo personalizzato per l'attività di integrità
Usare questa richiesta POST per avviare un Analisi del testo personalizzato per l'attività di estrazione dell'integrità.
{ENDPOINT}/language/analyze-text/jobs?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | Chiave che fornisce l'accesso a questa API. |
Corpo
{
"displayName": "Extracting entities",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "{LANGUAGE-CODE}",
"text": "Text1"
},
{
"id": "2",
"language": "{LANGUAGE-CODE}",
"text": "Text2"
}
]
},
"tasks": [
{
"kind": "CustomHealthcare",
"taskName": "Custom TextAnalytics for Health Test",
"parameters": {
"projectName": "{PROJECT-NAME}",
"deploymentName": "{DEPLOYMENT-NAME}"
}
}
]
}
| Key | Segnaposto | Valore | Esempio |
|---|---|---|---|
displayName |
{JOB-NAME} |
Nome del processo. | MyJobName |
documents |
[{},{}] | Elenco di documenti in cui eseguire attività. | [{},{}] |
id |
{DOC-ID} |
Nome o ID del documento. | doc1 |
language |
{LANGUAGE-CODE} |
Stringa che specifica il codice della lingua per il documento. Se questa chiave non è specificata, il servizio presuppone la lingua predefinita del progetto selezionato durante la creazione del progetto. Per un elenco dei codici linguistici supportati, vedere supporto per la lingua. | en-us |
text |
{DOC-TEXT} |
Attività documento in cui eseguire le attività. | Lorem ipsum dolor sit amet |
tasks |
Elenco di attività da eseguire. | [] |
|
taskName |
Custom Text Analytics for Health Test |
Nome dell'attività | Custom Text Analytics for Health Test |
kind |
CustomHealthcare |
Il tipo di progetto o attività che si sta tentando di eseguire | CustomHealthcare |
parameters |
Elenco di parametri da passare all'attività. | ||
project-name |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
deployment-name |
{DEPLOYMENT-NAME} |
Nome della distribuzione. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | prod |
Response
Si riceverà una risposta 202 che indica che l'attività è stata inviata correttamente. Nelle intestazioni della risposta estrarre operation-location.
operation-location è formattato come segue:
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
È possibile usare questo URL per eseguire una query sullo stato di completamento dell'attività e ottenere i risultati al termine dell'attività.
Ottenere i risultati dell'attività
Usare la richiesta GET seguente per eseguire una query sullo stato/risultati dell'attività di riconoscimento dell'entità personalizzata.
{ENDPOINT}/language/analyze-text/jobs/{JOB-ID}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | Chiave che fornisce l'accesso a questa API. |
Testo della risposta
La risposta è un documento JSON con i parametri seguenti
{
"createdDateTime": "2021-05-19T14:32:25.578Z",
"displayName": "MyJobName",
"expirationDateTime": "2021-05-19T14:32:25.578Z",
"jobId": "xxxx-xxxx-xxxxx-xxxxx",
"lastUpdateDateTime": "2021-05-19T14:32:25.578Z",
"status": "succeeded",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "CustomHealthcareLROResults",
"taskName": "Custom Text Analytics for Health Test",
"lastUpdateDateTime": "2020-10-01T15:01:03Z",
"status": "succeeded",
"results": {
"documents": [
{
"entities": [
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1",
"confidenceScore": 0.98
},
{
"entityComponentInformation": [
{
"entityComponentKind": "listComponent"
}
],
"offset": 0,
"length": 11,
"text": "first entity",
"category": "Entity1.Dictionary",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "learnedComponent"
}
],
"offset": 16,
"length": 9,
"text": "entity two",
"category": "Entity2",
"confidenceScore": 1.0
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 37,
"length": 9,
"text": "ibuprofen",
"category": "MedicationName",
"confidenceScore": 1,
"assertion": {
"certainty": "negative"
},
"name": "ibuprofen",
"links": [
{
"dataSource": "UMLS",
"id": "C0020740"
},
{
"dataSource": "AOD",
"id": "0000019879"
},
{
"dataSource": "ATC",
"id": "M01AE01"
},
{
"dataSource": "CCPSS",
"id": "0046165"
},
{
"dataSource": "CHV",
"id": "0000006519"
},
{
"dataSource": "CSP",
"id": "2270-2077"
},
{
"dataSource": "DRUGBANK",
"id": "DB01050"
},
{
"dataSource": "GS",
"id": "1611"
},
{
"dataSource": "LCH_NW",
"id": "sh97005926"
},
{
"dataSource": "LNC",
"id": "LP16165-0"
},
{
"dataSource": "MEDCIN",
"id": "40458"
},
{
"dataSource": "MMSL",
"id": "d00015"
},
{
"dataSource": "MSH",
"id": "D007052"
},
{
"dataSource": "MTHSPL",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI",
"id": "C561"
},
{
"dataSource": "NCI_CTRP",
"id": "C561"
},
{
"dataSource": "NCI_DCP",
"id": "00803"
},
{
"dataSource": "NCI_DTP",
"id": "NSC0256857"
},
{
"dataSource": "NCI_FDA",
"id": "WK2XYI10QM"
},
{
"dataSource": "NCI_NCI-GLOSS",
"id": "CDR0000613511"
},
{
"dataSource": "NDDF",
"id": "002377"
},
{
"dataSource": "PDQ",
"id": "CDR0000040475"
},
{
"dataSource": "RCD",
"id": "x02MO"
},
{
"dataSource": "RXNORM",
"id": "5640"
},
{
"dataSource": "SNM",
"id": "E-7772"
},
{
"dataSource": "SNMI",
"id": "C-603C0"
},
{
"dataSource": "SNOMEDCT_US",
"id": "387207008"
},
{
"dataSource": "USP",
"id": "m39860"
},
{
"dataSource": "USPMG",
"id": "MTHU000060"
},
{
"dataSource": "VANDF",
"id": "4017840"
}
]
},
{
"entityComponentInformation": [
{
"entityComponentKind": "prebuiltComponent"
}
],
"offset": 30,
"length": 6,
"text": "100 mg",
"category": "Dosage",
"confidenceScore": 0.98
}
],
"relations": [
{
"confidenceScore": 1,
"relationType": "DosageOfMedication",
"entities": [
{
"ref": "#/documents/0/entities/1",
"role": "Dosage"
},
{
"ref": "#/documents/0/entities/0",
"role": "Medication"
}
]
}
],
"id": "1",
"warnings": []
}
],
"errors": [],
"modelVersion": "2020-04-01"
}
}
]
}
}
| Key | Valore di esempio | Descrizione |
|---|---|---|
| entities | [] | Matrice contenente tutte le entità estratte. |
| entityComponentKind | prebuiltComponent |
Variabile che indica quale componente ha restituito l'entità specifica. Valori possibili: prebuiltComponent, learnedComponent, listComponent |
| offset | 0 |
Numero che indica il punto iniziale dell'entità estratta tramite l'indicizzazione dei caratteri |
| length | 10 |
Numero che indica la lunghezza dell'entità estratta in numero di caratteri. |
| Testo | first entity |
Testo estratto per un'entità specifica. |
| category | MedicationName |
Nome del tipo di entità o della categoria corrispondente al testo estratto. |
| confidenceScore | 0.9 |
Numero che indica il livello di certezza del modello dell'entità estratta che va da 0 a 1 con un numero maggiore che indica una maggiore certezza. |
| assertion | certainty |
Asserzioni associate all'entità estratta. Le asserzioni sono supportate solo per le Analisi del testo predefinite per le entità di integrità. |
| name | Ibuprofen |
Nome normalizzato per il collegamento di entità associato all'entità estratta. Il collegamento di entità è supportato solo per le Analisi del testo predefinite per le entità di integrità. |
| collegamenti | [] | Matrice contenente tutti i risultati del collegamento dell'entità associata all'entità estratta. Il collegamento di entità è supportato solo per le Analisi del testo predefinite per le entità di integrità. |
| dataSource | UMLS |
Standard di riferimento risultante dal collegamento di entità associato all'entità estratta. Il collegamento di entità è supportato solo per le Analisi del testo predefinite per le entità di integrità. |
| ID | C0020740 |
Codice di riferimento risultante dal collegamento dell'entità associata all'entità estratta appartenente all'origine dati estratta. Il collegamento di entità è supportato solo per le Analisi del testo predefinite per le entità di integrità. |
| Relazioni | [] | Matrice contenente tutte le relazioni estratte. L'estrazione delle relazioni è supportata solo per le Analisi del testo predefinite per le entità di integrità. |
| relationType | DosageOfMedication |
Categoria della relazione estratta. L'estrazione delle relazioni è supportata solo per le Analisi del testo predefinite per le entità di integrità. |
| entities | "Dosage", "Medication" |
Entità associate alla relazione estratta. L'estrazione delle relazioni è supportata solo per le Analisi del testo predefinite per le entità di integrità. |
Pulire le risorse
Quando il progetto non è più necessario, è possibile eliminarlo con la richiesta DELETE seguente. Sostituire i valori segnaposto con i propri valori.
{Endpoint}/language/authoring/analyze-text/projects/{projectName}?api-version={API-VERSION}
| Segnaposto | Valore | Esempio |
|---|---|---|
{ENDPOINT} |
Endpoint per l'autenticazione della richiesta API. | https://<your-custom-subdomain>.cognitiveservices.azure.com |
{PROJECT-NAME} |
Nome del progetto. Per questo valore viene applicata la distinzione tra maiuscole e minuscole. | myProject |
{API-VERSION} |
Versione dell'API che si sta chiamando. Il valore a cui viene fatto riferimento è relativo alla versione più recente rilasciata. Per altre informazioni sulle altre versioni dell'API disponibili, vedere Ciclo di vita del modello. | 2022-05-01 |
Intestazioni
Usare l'intestazione seguente per autenticare la richiesta.
| Chiave | valore |
|---|---|
| Ocp-Apim-Subscription-Key | Chiave della risorsa. Usato per l'autenticazione delle richieste API. |
Dopo aver inviato la richiesta API, si riceverà una 202 risposta che indica l'esito positivo, il che significa che il progetto è stato eliminato. Risultati di una chiamata con esito positivo con un'intestazione Operation-Location usata per controllare lo stato del processo.
Passaggi successivi
Dopo aver creato il modello di estrazione di entità, è possibile:
Quando si inizia a creare Analisi del testo personalizzati per i progetti di integrità, usare gli articoli sulle procedure per altre informazioni sull'etichettatura dei dati, il training e l'utilizzo del modello in modo più dettagliato: