Guida introduttiva: riepilogo personalizzato (anteprima)
Usare questo articolo per iniziare a creare un progetto di riepilogo personalizzato in cui è possibile eseguire il training di modelli personalizzati in Riepilogo. Un modello è un software di intelligenza artificiale sottoposto a training per eseguire una determinata attività. Per questo sistema, i modelli riepilogano il testo e vengono sottoposti a training imparando dai dati importati.
In questo articolo si usa Language Studio per illustrare i concetti chiave del riepilogo personalizzato. Ad esempio, verrà creato un modello di riepilogo personalizzato per estrarre la posizione della struttura o del trattamento da brevi note di scaricamento.
Prerequisiti
- Sottoscrizione di Azure: creare un account gratuito
Creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure e un account di archiviazione di Azure
Prima di poter usare riepiloghi personalizzati, è necessario creare una risorsa del linguaggio di intelligenza artificiale di Azure, che fornirà le credenziali necessarie per creare un progetto e avviare il training di un modello. È anche necessario un account di archiviazione di Azure, in cui è possibile caricare il set di dati che verrà usato per compilare il modello.
Importante
Per iniziare rapidamente, è consigliabile creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure seguendo la procedura descritta in questo articolo. La procedura descritta in questo articolo consentirà di creare contemporaneamente la risorsa di linguaggio e l'account di archiviazione, che è più semplice rispetto a farlo in un secondo momento.
Creare una nuova risorsa dal portale di Azure
Passare alla portale di Azure per creare una nuova risorsa del linguaggio di intelligenza artificiale di Azure.
Nella finestra visualizzata selezionare questo servizio dalle funzionalità personalizzate. Selezionare Continua per creare la risorsa nella parte inferiore della schermata .
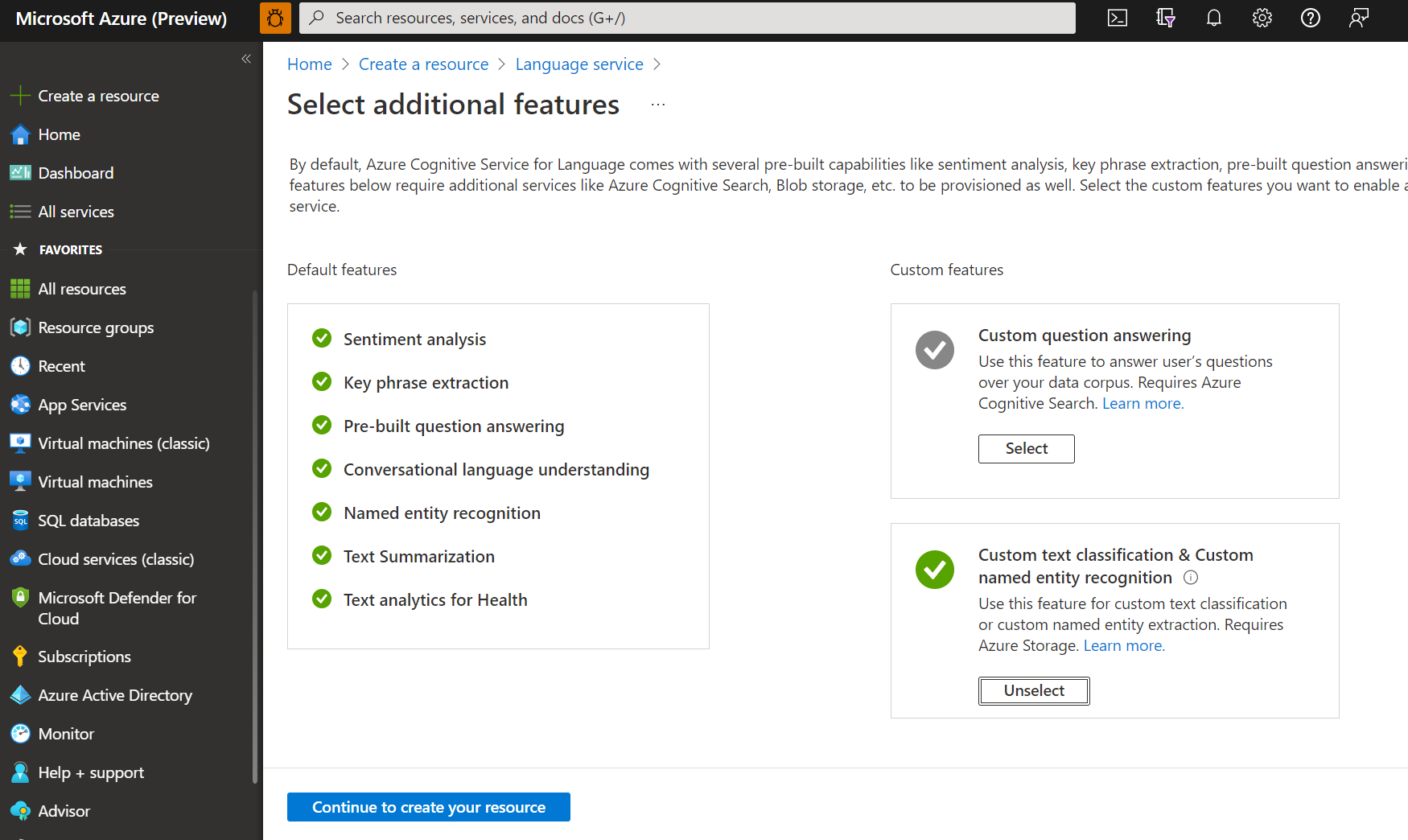
Creare una risorsa lingua con i dettagli seguenti.
Nome Descrizione Abbonamento La sottoscrizione di Azure. Gruppo di risorse Gruppo di risorse che conterrà la risorsa. È possibile usare uno esistente o crearne uno nuovo. Area Area per la risorsa lingua. Ad esempio, "Stati Uniti occidentali 2". Nome Nome della risorsa. Piano tariffario Piano tariffario per la risorsa Lingua. È possibile usare il livello Gratuito (F0) per provare il servizio. Nota
Se viene visualizzato un messaggio che indica che l'account di accesso non è un proprietario del gruppo di risorse dell'account di archiviazione selezionato, l'account deve avere un ruolo di proprietario assegnato nel gruppo di risorse prima di poter creare una risorsa lingua. Per assistenza, contattare il proprietario della sottoscrizione di Azure.
Nella sezione del servizio selezionare un account di archiviazione esistente o selezionare Nuovo account di archiviazione. Questi valori consentono di iniziare e non necessariamente i valori dell'account di archiviazione da usare negli ambienti di produzione. Per evitare la latenza durante la compilazione del progetto, connettersi agli account di archiviazione nella stessa area della risorsa lingua.
Archiviazione valore dell'account Valore consigliato Nome account di archiviazione Qualsiasi nome Storage account type LRS Standard Assicurarsi che sia selezionata l'informativa sull'intelligenza artificiale responsabile. Selezionare Rivedi e crea nella parte inferiore della pagina e quindi selezionare Crea.

Scaricare i dati di esempio
Se sono necessari dati di esempio, sono stati forniti alcuni scenari di riepilogo dei documenti e riepiloghi delle conversazioni ai fini di questa guida introduttiva.
Caricare dati di esempio nel contenitore BLOB
Individuare i file da caricare nell'account di archiviazione
Nel portale di Azure passare all'account di archiviazione creato e selezionarlo.
Nell'account di archiviazione selezionare Contenitori nel menu a sinistra, sotto Archiviazione dati. Nella schermata visualizzata selezionare + Contenitore. Assegnare al contenitore il nome example-data e lasciare il livello di accesso pubblico predefinito.

Dopo aver creato il contenitore, selezionarlo. Selezionare quindi il pulsante Carica per selezionare i
.txt.jsonfile e scaricati in precedenza.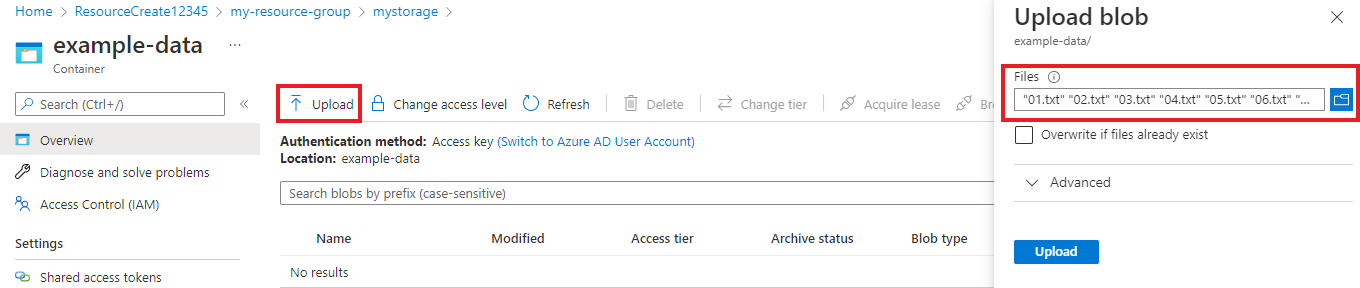


Creare un progetto di riepilogo personalizzato
Dopo aver configurato la risorsa e l'account di archiviazione, creare un nuovo progetto di riepilogo personalizzato. Un progetto è un'area di lavoro per la creazione di modelli di Machine Learning personalizzati in base ai dati. L'accesso al progetto può essere eseguito solo dall'utente e da altri utenti che hanno accesso alla risorsa Lingua usata.
Accedere a Language Studio. Verrà visualizzata una finestra che consente di selezionare la sottoscrizione e la risorsa lingua. Selezionare la risorsa Lingua creata nel passaggio precedente.
Selezionare la funzionalità da usare in Language Studio.
Selezionare Crea nuovo progetto dal menu in alto nella pagina dei progetti. La creazione di un progetto consente di etichettare i dati, eseguire il training, valutare, migliorare e distribuire i modelli.

Immettere le informazioni sul progetto, inclusi un nome, una descrizione e la lingua dei file nel progetto. Se si usa il set di dati di esempio, selezionare Inglese. Non è possibile modificare il nome del progetto in un secondo momento. Selezionare Avanti.
Suggerimento
Il set di dati non deve essere interamente nello stesso linguaggio. È possibile avere più documenti, ognuno con lingue supportate diverse. Se il set di dati contiene documenti di lingue diverse o se si prevede testo da lingue diverse durante il runtime, selezionare l'opzione Abilita set di dati multilingue quando si immettono le informazioni di base per il progetto. Questa opzione può essere abilitata in un secondo momento dalla pagina Impostazioni progetto.
Dopo aver selezionato Crea nuovo progetto, verrà visualizzata una finestra per consentire la connessione dell'account di archiviazione. Se è già stato connesso un account di archiviazione, verrà visualizzato l'account di archiviazione connesso. In caso contrario, scegliere l'account di archiviazione dall'elenco a discesa visualizzato e selezionare Connessione account di archiviazione. Verranno impostati i ruoli necessari per l'account di archiviazione. Questo passaggio restituirà un errore se non si è assegnati come proprietario nell'account di archiviazione.
Nota
- È necessario eseguire questo passaggio una sola volta per ogni nuova risorsa usata.
- Questo processo è irreversibile, se si connette un account di archiviazione alla risorsa lingua, non è possibile disconnetterlo in un secondo momento.
- È possibile connettere la risorsa lingua solo a un account di archiviazione.
Selezionare il contenitore in cui è stato caricato il set di dati.
Se i dati sono già stati etichettati, assicurarsi che seguano il formato supportato e selezionare Sì, i miei file sono già etichettati e ho formattato il file di etichette JSON e selezionare il file delle etichette dal menu a discesa. Seleziona Avanti. Se si usa il set di dati della guida introduttiva, non è necessario esaminare la formattazione del file di etichette JSON.
Esaminare i dati immessi e selezionare Crea progetto.

Eseguire il training del modello
Dopo aver creato un progetto, procedere e avviare il training del modello.
Per avviare il training del modello da Language Studio:
Selezionare Processi di training dal menu a sinistra.
Selezionare Avvia un processo di training dal menu in alto.
Selezionare Esegui training di un nuovo modello e digitare il nome del modello nella casella di testo. È anche possibile sovrascrivere un modello esistente selezionando questa opzione e scegliendo il modello da sovrascrivere dal menu a discesa. La sovrascrittura di un modello sottoposto a training è irreversibile, ma non influisce sui modelli distribuiti fino a quando non si distribuisce il nuovo modello.
Per impostazione predefinita, il sistema suddividerà i dati etichettati tra i set di training e di test, in base alle percentuali specificate. Se sono presenti documenti nel set di test, è possibile suddividere manualmente i dati di training e test.
Selezionare il pulsante Train (Esegui training ).
Se si seleziona l'ID processo di training nell'elenco, verrà visualizzato un riquadro laterale in cui è possibile controllare lo stato del training, lo stato del processo e altri dettagli per questo processo.
Nota
- Solo i processi di training completati correttamente genereranno modelli.
- Il training può richiedere tempo tra un paio di minuti e diverse ore in base alle dimensioni dei dati etichettati.
- È possibile eseguire un solo processo di training alla volta. Non è possibile avviare altri processi di training nello stesso progetto fino al completamento del processo in esecuzione.

Distribuire il modello
In genere dopo il training di un modello, esaminare i relativi dettagli di valutazione e apportare miglioramenti, se necessario. In questa guida introduttiva si distribuirà semplicemente il modello e lo si renderà disponibile per provare in Language Studio.
Per distribuire il modello da Language Studio:
Selezionare Deploying a model (Distribuzione di un modello ) dal menu a sinistra.
Selezionare Aggiungi distribuzione per avviare un nuovo processo di distribuzione.
Selezionare Crea nuova distribuzione per creare una nuova distribuzione e assegnare un modello sottoposto a training nell'elenco a discesa seguente. È anche possibile sovrascrivere una distribuzione esistente selezionando questa opzione e selezionando il modello sottoposto a training che si vuole assegnare al modello dall'elenco a discesa seguente.
Nota
La sovrascrittura di una distribuzione esistente non richiede modifiche alla chiamata api di stima, ma i risultati ottenuti saranno basati sul modello appena assegnato.
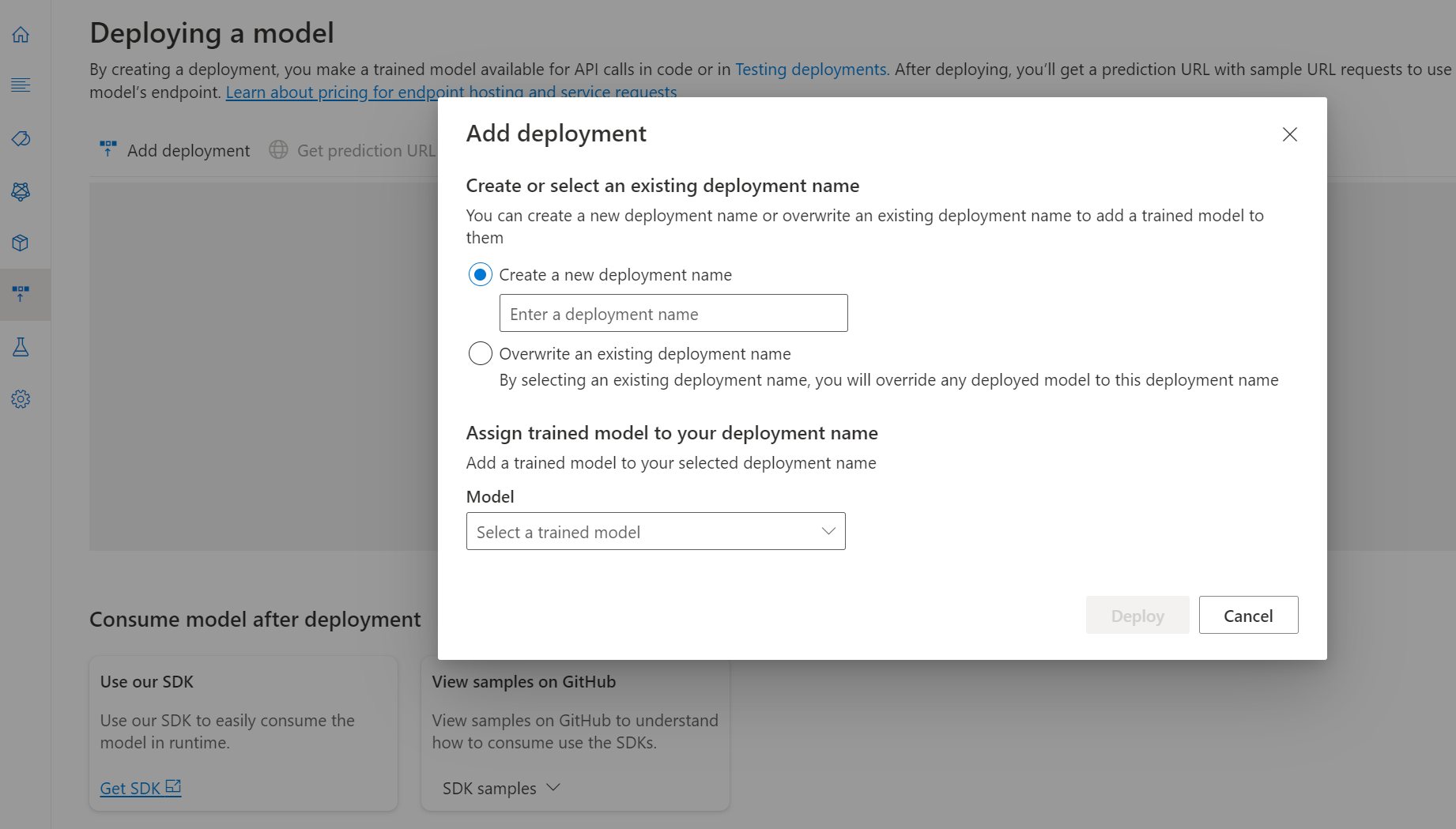
Selezionare Distribuisci per avviare il processo di distribuzione.
Al termine della distribuzione, accanto verrà visualizzata una data di scadenza. La scadenza della distribuzione è quando il modello distribuito non sarà disponibile per la stima, che in genere si verifica dodici mesi dopo la scadenza di una configurazione di training.


Testare il modello
Per questa guida introduttiva si userà Language Studio per inviare l'attività di riepilogo personalizzato e visualizzare i risultati. Nel set di dati di esempio scaricato in precedenza è possibile trovare alcuni documenti di test che è possibile usare in questo passaggio.
Per testare i modelli distribuiti da Language Studio:
Selezionare Test delle distribuzioni dal menu a sinistra.
Selezionare la distribuzione da testare. È possibile testare solo i modelli assegnati alle distribuzioni.
Per i progetti multilingue, nell'elenco a discesa lingua selezionare la lingua del testo che si esegue il test.
Selezionare la distribuzione da eseguire query/test dall'elenco a discesa.
È possibile immettere il testo da inviare alla richiesta o caricare un
.txtfile da usare.Selezionare Esegui il test dal menu in alto.
Nella scheda Risultato è possibile visualizzare le entità estratte dal testo e i relativi tipi. È anche possibile visualizzare la risposta JSON nella scheda JSON .

Pulire le risorse
Quando il progetto non è più necessario, è possibile eliminare il progetto usando Language Studio. Selezionare la funzionalità in uso nella parte superiore e quindi selezionare il progetto da eliminare. Selezionare Elimina dal menu in alto per eliminare il progetto.