Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Gli indici secondari globali di Azure Cosmos DB per NoSQL sono attualmente in anteprima. Questa anteprima viene fornita senza un contratto di servizio. Al momento, non è consigliabile usare indici secondari globali per i carichi di lavoro di produzione. Alcune funzionalità di questa anteprima potrebbero non essere supportate o potrebbero essere limitate. Per altre informazioni, vedere le condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure.
Gli indici secondari globali migliorano l'efficienza delle query archiviando i dati con una chiave di partizione diversa. Gli indici secondari globali sono contenitori di sola lettura sincronizzati automaticamente con il contenitore di origine, mantenendo una copia permanente dei dati. Ogni contenitore di indici ha impostazioni specifiche, distinte dal contenitore di origine, tra cui chiave di partizione, criteri di indicizzazione, limite di unità richiesta (UR) e modello di dati, che può essere personalizzato selezionando proprietà specifiche degli elementi.
Casi d'uso
Le applicazioni spesso devono eseguire query sui dati usando proprietà diverse dalla chiave di partizione. Queste query devono essere eseguite in tutte le partizioni, anche se alcune partizioni non contengono dati che soddisfano i criteri di filtro. Di conseguenza, le query che non includono la chiave di partizione utilizzano più UR e hanno una latenza più elevata.
Con un indice secondario globale, è possibile:
- Archiviare i dati con una chiave di partizione diversa per convertire le query tra partizioni nel contenitore di origine in ricerche a partizione singola.
- Aggiungere indici secondari globali ai contenitori esistenti per mantenere le query efficienti man mano che le esigenze dell'applicazione cambiano.
- Isolare un subset del carico di lavoro, ad esempio la creazione di indici di ricerca vettoriale o full-text nell'indice secondario globale senza influire sulle operazioni transazionali nel contenitore di origine.
Vantaggi dell'indice secondario globale
Gli indici secondari globali di Azure Cosmos DB offrono i vantaggi seguenti:
- Sincronizzazione automatica: i contenitori di indici vengono sincronizzati automaticamente con il contenitore di origine, eliminando la necessità di logica personalizzata nelle applicazioni client.
- Coerenza finale: i contenitori di indici sono infine coerenti con il contenitore di origine senza influire sulla latenza di scrittura nell'origine.
- Isolamento delle prestazioni: i contenitori di indici hanno limiti di archiviazione e UR personalizzati, fornendo l'isolamento delle prestazioni.
- Prestazioni di lettura ottimizzate: modello di dati ottimizzato, chiave di partizione e criteri di indicizzazione per ottimizzare le prestazioni di lettura con supporto per le query tramite la sintassi di query NoSQL avanzata.
- Miglioramento delle prestazioni di scrittura: i client devono scrivere solo nel contenitore di origine, migliorando le prestazioni di scrittura rispetto a una strategia di scrittura multi-contenitore.
- Contenitori di sola lettura: le scritture nel contenitore degli indici sono asincrone e vengono gestite automaticamente. Le applicazioni client non devono scrivere direttamente nel contenitore dell'indice.
- Più indici: è possibile creare più contenitori di indici per lo stesso contenitore di origine senza sovraccarico aggiuntivo.
Definizione di indici secondari globali
La creazione di un indice secondario globale è simile alla creazione di un nuovo contenitore, con proprietà aggiunte per specificare il contenitore di origine e una query che definisce il modello di dati dell'indice secondario globale. Molte personalizzazioni per i contenitori si applicano anche al contenitore di indici secondari globale, tra cui indicizzazione personalizzata, vettore e criteri di ricerca full-text. I contenitori degli indici secondari globali devono utilizzare la scalabilità automatica della velocità effettiva, che consente di rispondere ai picchi di traffico senza subire limitazioni o ritardare rispetto agli aggiornamenti nel contenitore di origine.
Ogni elemento dell'indice secondario globale corrisponde uno a uno a un elemento nel contenitore di origine. Per mantenere questa mappatura, il campo negli elementi dell'indice secondario globale id viene popolato automaticamente. Il valore di id dal contenitore di origine è rappresentato come _id nel contenitore di indice.
La query usata per definire un indice secondario globale deve rispettare i vincoli seguenti:
- L'istruzione SELECT consente la proiezione di un solo livello di proprietà nell'albero JSON oppure può essere SELECT * per includere tutte le proprietà.
- L'aliasing dei nomi delle proprietà tramite AS non è supportato.
- Le query non possono includere una clausola WHERE o altre clausole, ad esempio JOIN, DISTINCT, GROUP BY, ORDER BY, TOP, OFFSET LIMIT e EXISTS.
- Le funzioni di sistema e le funzioni definite dall'utente non sono supportate.
Ad esempio, una query valida è : SELECT c.userName, c.emailAddress FROM c, che seleziona le userName proprietà e emailAddress dal contenitore cdi origine . Questa query definisce il modello di dati dell'indice secondario globale, determinando quali proprietà sono incluse nel contenitore di indici per ogni elemento. Non è possibile modificare il contenitore di origine e la query di definizione dopo la creazione.
Informazioni su come creare indici secondari globali.
Suggerimento
Se si vuole eliminare un contenitore di origine, è prima necessario eliminare tutti gli indici secondari globali creati per tale contenitore.
Sincronizzazione di indici secondari globali
I contenitori di indici secondari globali vengono mantenuti automaticamente sincronizzati con le modifiche apportate ai dati nei contenitori di origine usando il feed di modifiche. Quando viene definito un indice secondario globale per un contenitore di origine, un processo di feed di modifiche viene creato e gestito automaticamente per te. Le modifiche vengono riflesse in modo asincrono ai dati nei contenitori di indici e non influiscono sulle scritture nel contenitore di origine. I contenitori di indici sono infine coerenti con il contenitore di origine indipendentemente dal livello di coerenza impostato per l'account.
Le letture dei feed di modifiche consumano le UR del contenitore di origine mentre le scritture nell'indice secondario globale consumano le UR del contenitore dell'indice. Le UR di cui è stato effettuato il provisioning in entrambi i contenitori determinano la velocità con cui gli indici vengono idratati e sincronizzati.
Indici secondari globali in account di più aree
Per gli account di Azure Cosmos DB con una singola area, il feed di modifiche legge dal contenitore di origine e scrive nel contenitore dell'indice secondario globale nella stessa area. In un account in più aree con una singola area di scrittura, le letture dei feed di modifiche e le scritture degli indici secondari globali si verificano nell'area di scrittura. In un account con più aree di scrittura, le letture dei feed di modifiche e le scritture degli indici secondari globali vengono eseguite in una delle aree di scrittura. Se si verifica un failover per l'account, le letture del feed di modifiche e le scritture degli indici secondari globali vengono eseguite nella nuova area di scrittura.
Esecuzione di query su indici secondari globali
L'esecuzione di query sui dati da indici secondari globali è simile all'esecuzione di query sui dati da qualsiasi altro contenitore. È possibile usare la sintassi di query completa e completa di Azure Cosmos DB per NoSQL per eseguire query su contenitori di indici secondari globali. Sono inclusi query di ricerca vettoriale, ricerca a testo completo e ricerca ibrida. Analogamente ad altri contenitori, è consigliabile ottimizzare i criteri di indicizzazione nei contenitori di indici secondari globali in base ai modelli di query.
Poiché gli indici secondari globali possono avere una chiave di partizione diversa rispetto ai contenitori di origine, l'esecuzione di query tra partizioni su indici secondari globali è più efficiente, risparmiando sia la latenza che le UR.
Monitoraggio
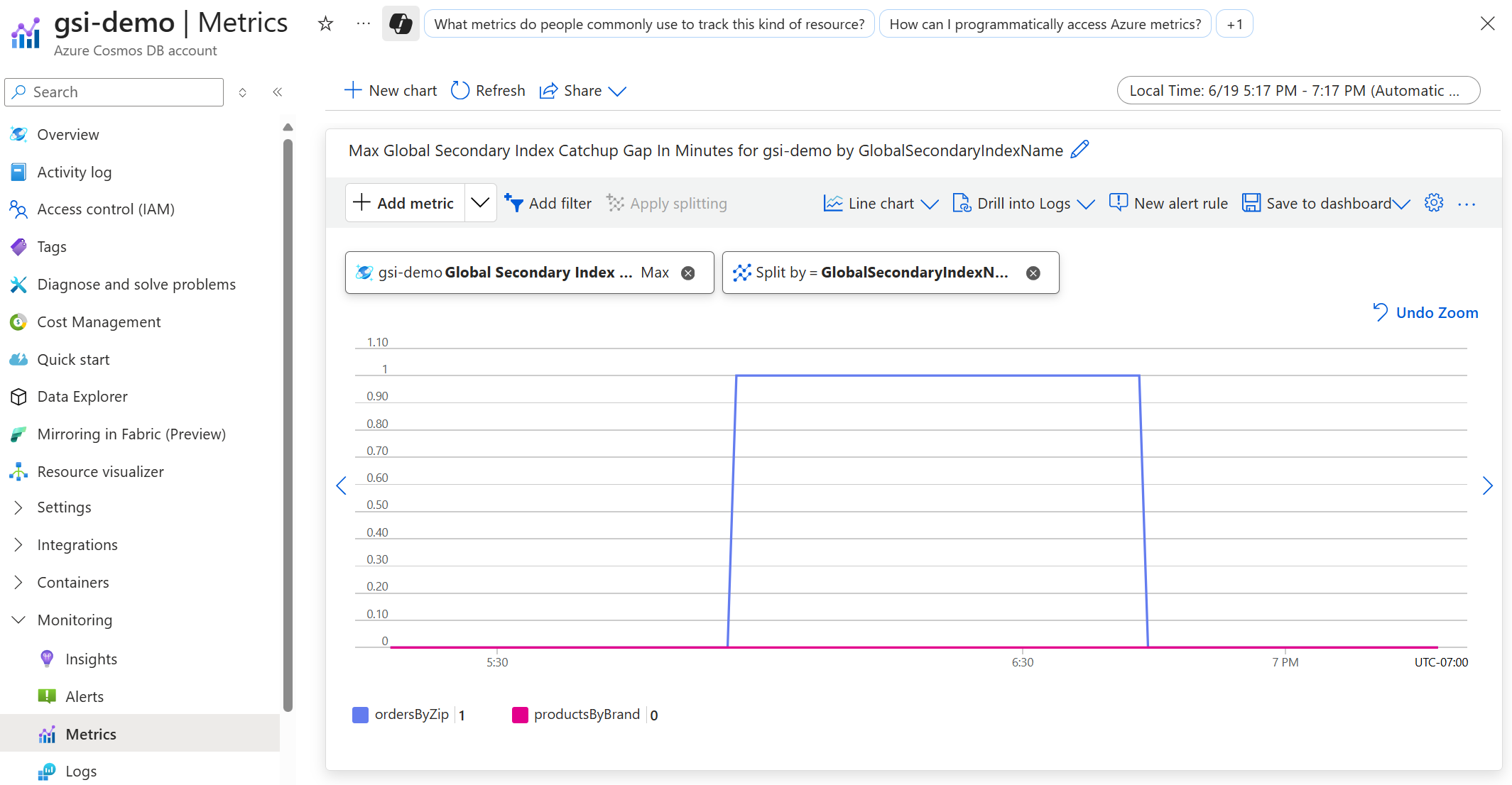
È possibile monitorare il ritardo nella costruzione di indici secondari globali tramite la metrica Global Secondary Index Catchup Gap In MinutesMetriche nel portale di Azure. Per informazioni su queste metriche, vedere Metriche supportate per Microsoft.DocumentDB/DatabaseAccounts.
Risoluzione dei problemi comuni
Voglio comprendere il ritardo tra il contenitore di origine e i contenitori di indice
La metrica Global Secondary Index Catchup Gap In Minutes mostra la differenza massima in minuti tra i dati nei contenitori di origine e i contenitori di indici secondari globali. Per visualizzare il ritardo per un singolo contenitore di indici, selezionare Applica suddivisione, Divisione per e selezionare GlobalSecondaryIndexName.
Voglio capire se i miei contenitori di indici secondari globali hanno RUs sufficienti
Le UR di cui è stato effettuato il provisioning nei contenitori di origine e indice influiscono sulla frequenza delle modifiche propagate al contenitore degli indici secondari globale. Controllare la metrica Normalized UR Consumption (Consumo di UR normalizzate ), se è troppo elevata, il contenitore può trarre vantaggio dall'aumento delle UR massime.
Limitazioni
Esistono alcune limitazioni nella funzionalità dell'indice secondario globale dell'API NoSQL di Azure Cosmos DB.
- È necessario abilitare i backup continui nell'account prima che sia possibile abilitare gli indici secondari globali.
- I contenitori di indici secondari globali non vengono ripristinati automaticamente durante il processo di ripristino dell'account. È necessario abilitare la funzionalità di indice secondario globale nell'account ripristinato al termine del processo di ripristino. È quindi possibile creare di nuovo gli indici secondari globali.