Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Azure Cosmos DB per PostgreSQL non è più supportato per i nuovi progetti. Non usare questo servizio per i nuovi progetti. Usare invece uno dei due servizi seguenti:
Usare Azure Cosmos DB per NoSQL per una soluzione di database distribuita progettata per scenari su alta scala con un accordo sul livello di servizio (SLA) di disponibilità del 99.999%, scalabilità automatica istantanea e failover automatico in più regioni.
Usare la funzionalità Cluster elastici di Database di Azure per PostgreSQL per PostgreSQL partizionato usando l'estensione Citus open source.
Coubicazione significa archiviare insieme le informazioni correlate sugli stessi nodi. Le query possono essere veloci quando tutti i dati necessari sono disponibili senza traffico di rete. La coubicazione dei dati correlati in nodi diversi consente l'esecuzione efficiente delle query in parallelo in ogni nodo.
Coubicazione dei dati per le tabelle con distribuzione hash
In Azure Cosmos DB for PostgreSQL una riga viene archiviata in una partizione se l'hash del valore nella colonna di distribuzione rientra nell'intervallo hash della partizione. Le partizioni con lo stesso intervallo hash vengono sempre posizionate nello stesso nodo. Le righe con valori di colonna di distribuzione uguali si trovano sempre nello stesso nodo tra le tabelle. Il concetto di tabelle con distribuzione hash è noto anche come partizionamento orizzontale basato su righe. Nel partizionamento orizzontale basato su schema, le tabelle all'interno di uno schema distribuito vengono sempre co-ubicate.
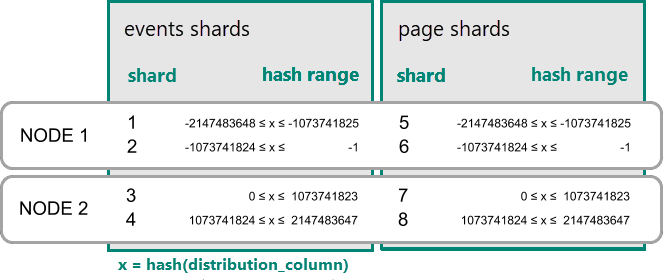
Un esempio pratico di coubicazione
Si considerino le tabelle seguenti che potrebbero far parte di un'analisi Web multi-tenant SaaS:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Ora si vuole rispondere alle query che potrebbero essere state rilasciate da un dashboard rivolto ai clienti. Una query di esempio è "Restituire il numero di visite nella settimana precedente per tutte le pagine che iniziano con '/blog' nel tenant sei."
Se i dati si trovavano in un singolo server PostgreSQL, è possibile esprimere facilmente la query usando il set completo di operazioni relazionali offerte da SQL:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
A condizione che il working set per questa query si adatti alla memoria, una tabella con server singolo è una soluzione appropriata. Si considerino ora le opportunità di ridimensionamento del modello di dati con Azure Cosmos DB for PostgreSQL.
Distribuire le tabelle in base all'ID
Le query su server singolo iniziano a rallentare man mano che aumenta il numero di tenant e i dati archiviati per ogni tenant. Il working set smette di adattarsi alla memoria e la CPU diventa un collo di bottiglia.
In questo caso, è possibile partizionare i dati in molti nodi usando Azure Cosmos DB for PostgreSQL. La prima e più importante scelta da effettuare quando si decide di partizionare è la colonna di distribuzione. Si inizierà con la semplice scelta di usare event_id per la tabella eventi e page_id per la tabella page:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Quando i dati vengono distribuiti tra ruoli di lavoro diversi, non è possibile eseguire un join come si farebbe in un singolo nodo PostgreSQL. È invece necessario eseguire due query:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Successivamente, i risultati dei due passaggi devono essere combinati dall'applicazione.
L'esecuzione delle query deve consultare i dati nelle partizioni sparse tra i nodi.
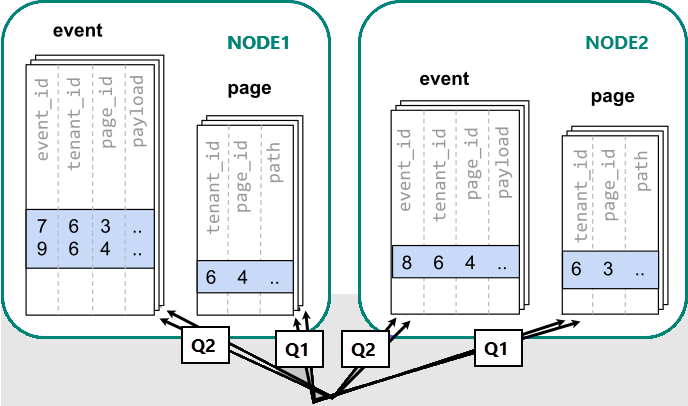
In questo caso, la distribuzione dei dati crea notevoli svantaggi:
- Sovraccarico dall'esecuzione di query su ogni partizione e dall'esecuzione di più query.
- Sovraccarico di Q1 che restituisce molte righe al client.
- Q2 diventa grande.
- La necessità di scrivere query in più passaggi richiede modifiche nell'applicazione.
I dati sono distribuiti, in modo che le query possano essere parallelizzate. È utile solo se la quantità di lavoro eseguita dalla query è notevolmente maggiore del sovraccarico di esecuzione delle query su molte partizioni.
Distribuire tabelle in base al tenant
In Azure Cosmos DB for PostgreSQL è garantito che le righe con lo stesso valore della colonna di distribuzione sono nello stesso nodo. A partire da questo punto di partenza, è possibile creare le tabelle con tenant_id come colonna di distribuzione.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Azure Cosmos DB for PostgreSQL può ora rispondere alla query originale con server singolo senza modifiche (Q1):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
A causa del filtro e del join nel tenant_id, Azure Cosmos DB for PostgreSQL sa che l'intera query può essere risolta usando il set di partizioni coubicate che contengono i dati per quel particolare tenant. Un singolo nodo PostgreSQL può rispondere alla query in un singolo passaggio.
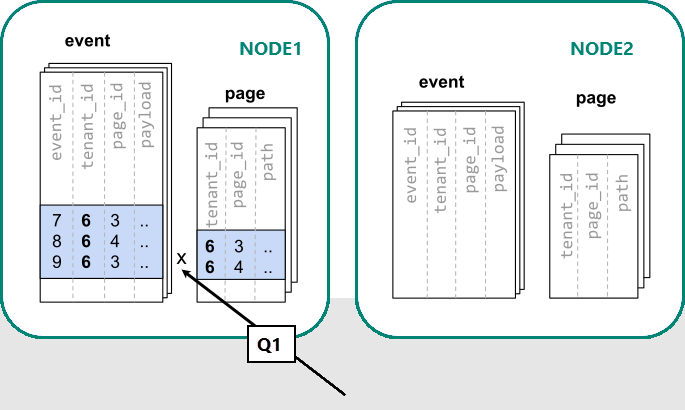
In alcuni casi, è necessario modificare query e schemi di tabella per includere l'ID tenant in vincoli univoci e condizioni di join. Questa modifica è in genere semplice.
Passaggi successivi
- Vedere in che modo i dati del tenant sono co-ubicati nell'esercitazione multi-tenant.