Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Esplora dati di Azure è un servizio di analisi dei dati rapido e completamente gestito. Offre un'analisi in tempo reale su grandi volumi di dati trasmessi da molte origini, ad esempio applicazioni, siti Web e dispositivi IoT.
Per copiare dati da un database in Oracle Server, Netezza, Teradata o SQL Server in Esplora dati di Azure, è necessario caricare grandi quantità di dati da più tabelle. In genere, i dati devono essere partizionati in ogni tabella in modo che sia possibile caricare righe con più thread in parallelo da una singola tabella. Questo articolo descrive un modello da usare in questi scenari.
I modelli di Azure Data Factory sono pipeline predefinite di Data Factory. Questi modelli consentono di iniziare rapidamente a usare Data Factory e ridurre i tempi di sviluppo nei progetti di integrazione dei dati.
Per creare un modello di Copia in blocco da database a Esplora dati di Azure, utilizzare le attività Lookup e ForEach. Per una copia più rapida dei dati, è possibile usare il modello per creare molte pipeline per database o per tabella.
Importante
Assicurarsi di usare lo strumento appropriato per la quantità di dati che si desidera copiare.
- Usare il modello Copia bulk da database a Esplora dati di Azure per copiare grandi quantità di dati da database come SQL Server e Google BigQuery in Esplora dati di Azure.
- Usare lo strumento Copia dati di Data Factory per copiare alcune tabelle con piccole o moderate quantità di dati in Esplora dati di Azure.
Prerequisiti
- Una sottoscrizione di Azure. Creare un account Azure gratuito.
- Un cluster e un database di Azure Data Explorer. Creare un cluster e un database.
- Una fabbrica di dati. Creare una fabbrica di dati.
- Origine dei dati.
Creazione ControlTableDataset
ControlTableDataset indica quali dati verranno copiati dall'origine alla destinazione nella pipeline. Il numero di righe indica il numero totale di pipeline necessarie per copiare i dati. È necessario definire ControlTableDataset come parte del database di origine.
Un esempio del formato di tabella di origine di SQL Server è illustrato nel codice seguente:
CREATE TABLE control_table (
PartitionId int,
SourceQuery varchar(255),
ADXTableName varchar(255)
);
Gli elementi di codice sono descritti nella tabella seguente:
| Proprietà | Descrizione | Esempio |
|---|---|---|
| ID di Partizione | Ordine di copia | 1 |
| SourceQuery | Query che indica quali dati verranno copiati durante il runtime della pipeline | select * from table where lastmodifiedtime LastModifytime >= ''2015-01-01 00:00:00''>
|
| ADXTableName | Nome della tabella di destinazione | MyAdxTable |
Se il tuo oggetto ControlTableDataset è in un formato diverso, crea un oggetto ControlTableDataset comparabile nel tuo formato.
Usare il modello Copia in blocco da database a Azure Data Explorer
Nel riquadro Attività iniziali selezionare Crea pipeline dal modello per aprire il riquadro Raccolta modelli .
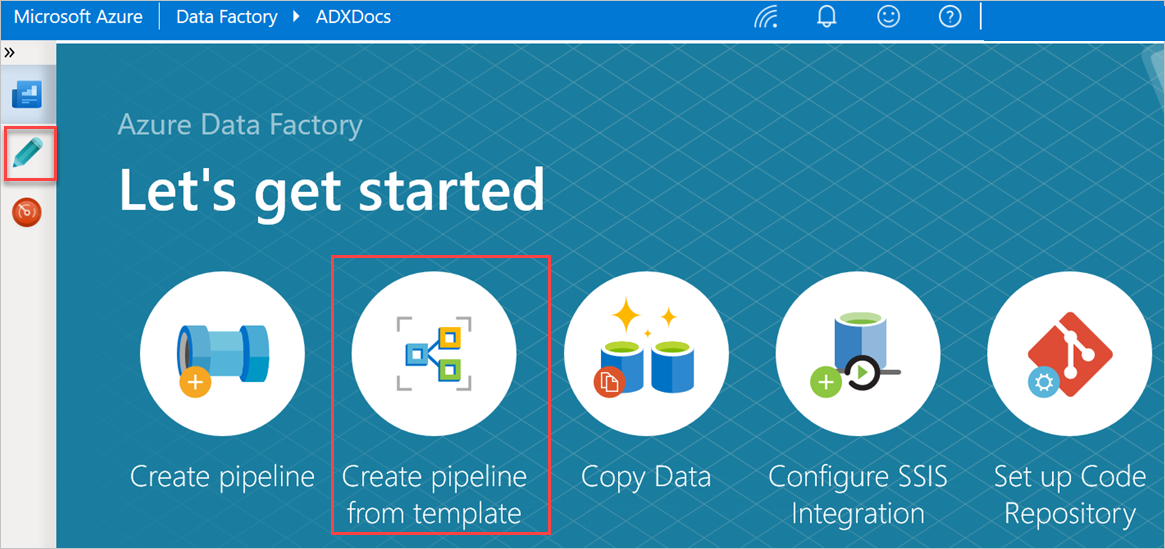
Selezionare il modello Copia in blocco da database a Esplora dati di Azure.
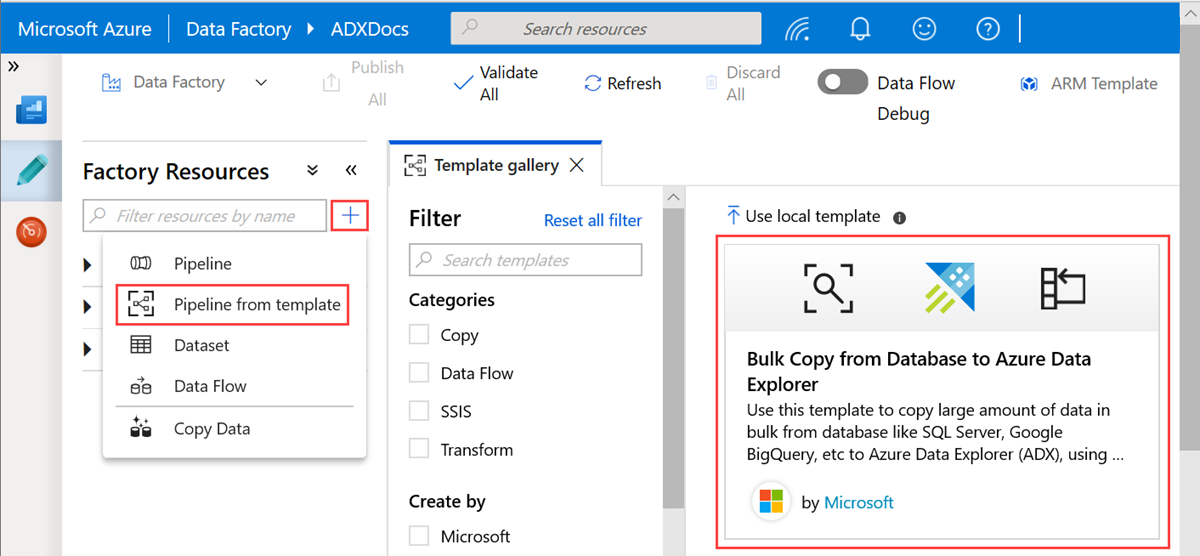
Nel riquadro Copia in massa da database ad Azure Data Explorer, negli Input utente specificare i set di dati eseguendo le seguenti operazioni:
a) Nell'elenco a discesa ControlTableDataset selezionare il servizio collegato nella tabella di controllo che indica quali dati vengono copiati dall'origine alla destinazione e dove verranno inseriti nella destinazione.
b. Nell'elenco a discesa SourceDataset selezionare il servizio collegato nel database di origine.
c. Nell'elenco a discesa AzureDataExplorerTable, selezionare la tabella di Azure Data Explorer. Se il set di dati non esiste, creare il servizio collegato Esplora dati di Azure per aggiungere il set di dati.
d. Selezionare Usa questo modello.
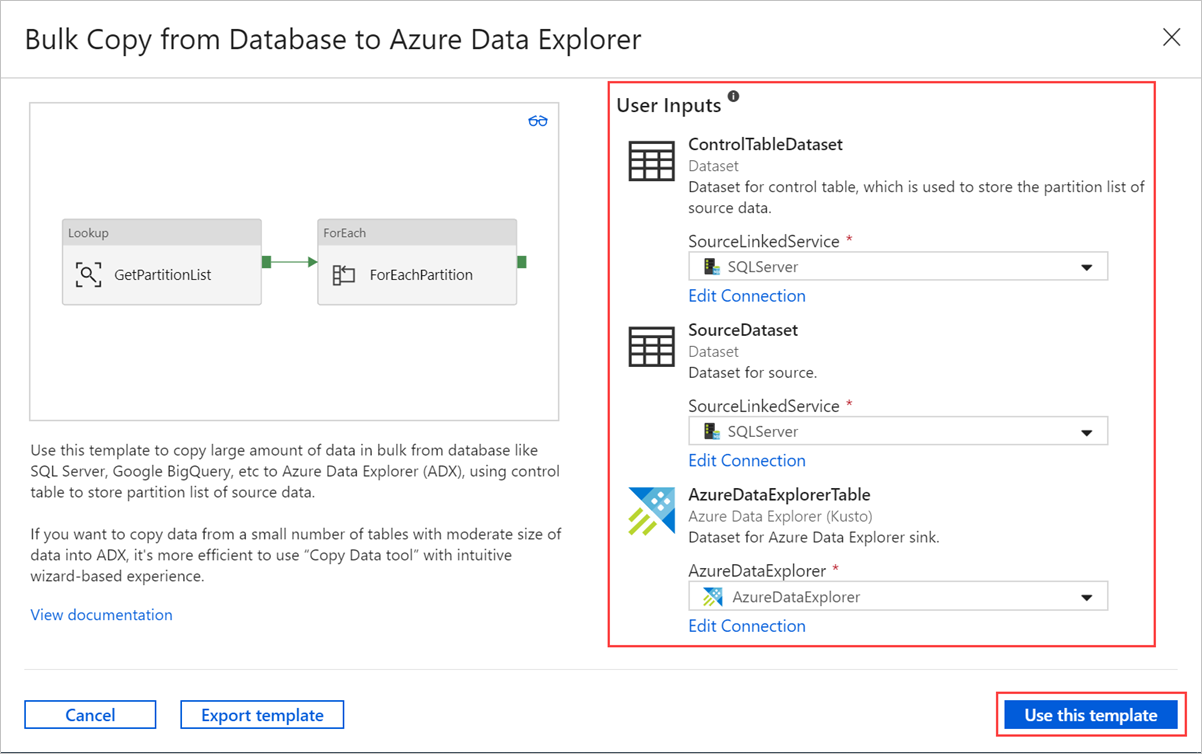
Selezionare un'area sul canvas, fuori dalle attività, per accedere alla pipeline del template. Selezionare la scheda Parametri per immettere i parametri per la tabella, inclusi Nome (nome tabella di controllo) e Valore predefinito (nomi di colonna).
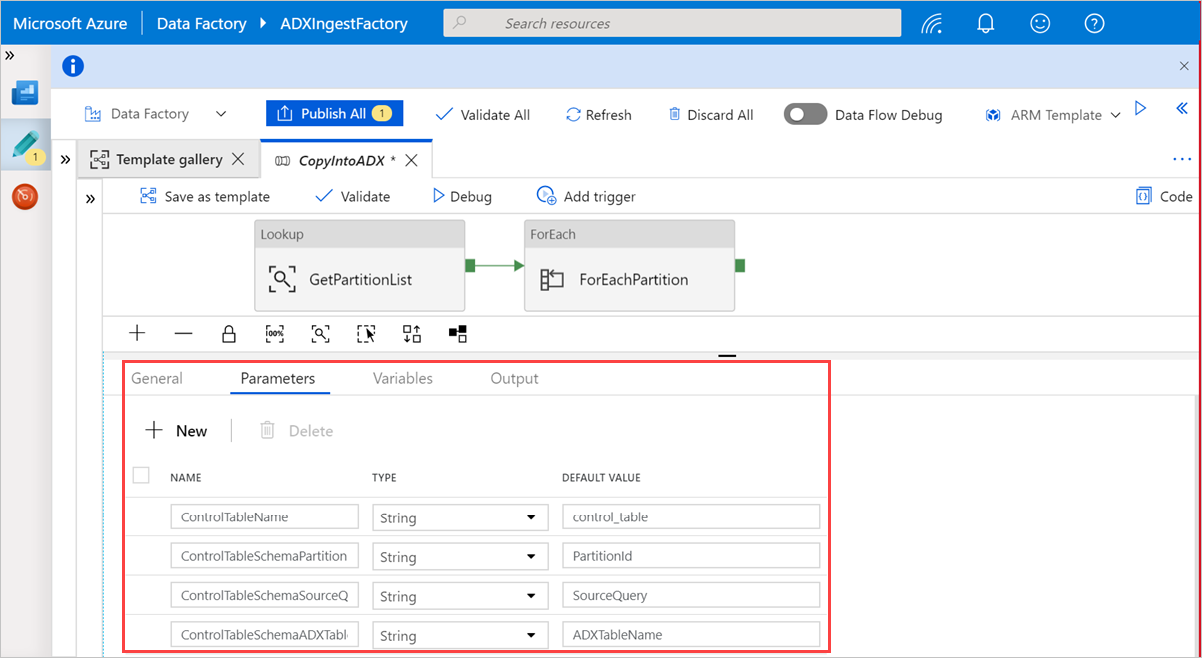
In Ricerca selezionare GetPartitionList per visualizzare le impostazioni predefinite. La query viene creata automaticamente.
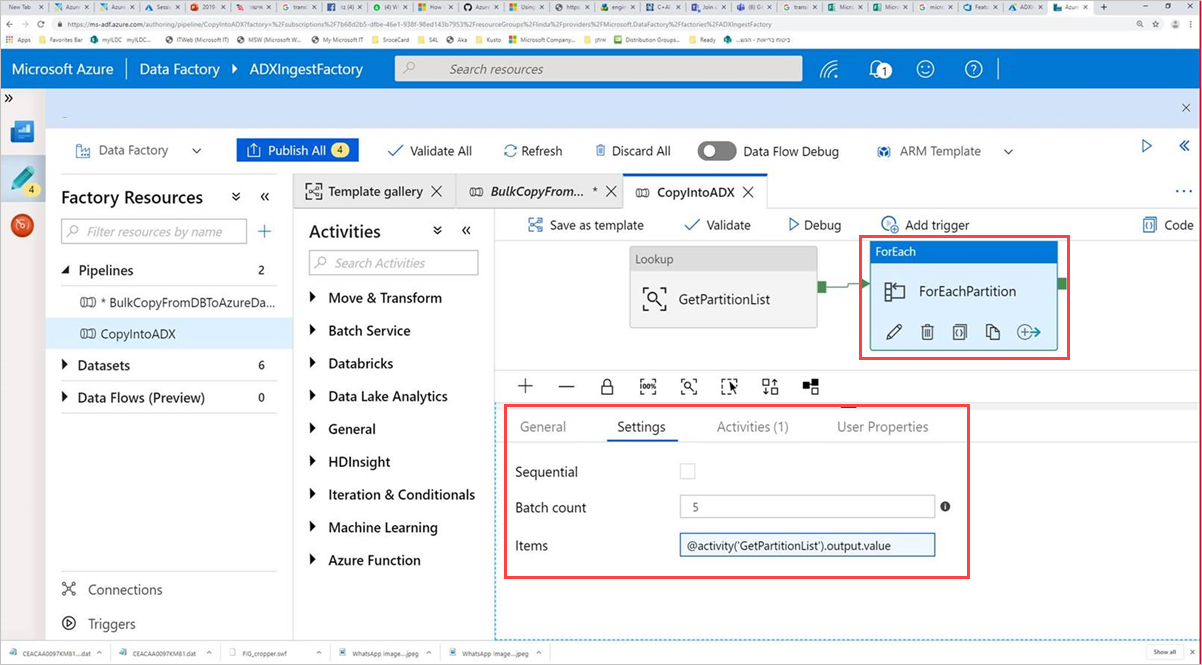
Selezionare l'attività Comando ForEachPartition, selezionare la scheda Impostazioni e quindi eseguire le operazioni seguenti:
a) Nella casella Conteggio batch immettere un numero compreso tra 1 e 50. Questa selezione determina il numero di pipeline eseguite in parallelo finché non viene raggiunto il numero di righe ControlTableDataset .
b. Per assicurarsi che i batch della pipeline siano eseguiti in parallelo, non selezionare la casella di controllo Sequenziale.
Suggerimento
La procedura consigliata consiste nell'eseguire molte pipeline in parallelo in modo che i dati possano essere copiati più rapidamente. Per aumentare l'efficienza, partizionare i dati nella tabella di origine e allocare una partizione per ogni pipeline, in base alla data e alla tabella.
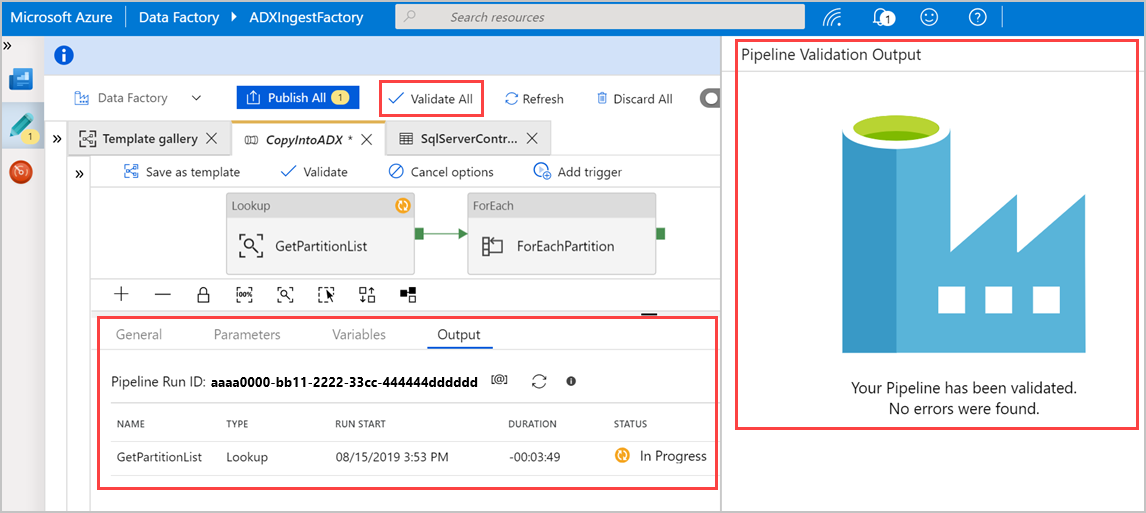
Selezionare Convalida tutto per convalidare la pipeline di Azure Data Factory e quindi visualizzare il risultato nel riquadro Output Convalida Pipeline.
Se necessario, selezionare Debug e quindi selezionare Aggiungi trigger per eseguire la pipeline.
È ora possibile usare il modello per copiare in modo efficiente grandi quantità di dati dai database e dalle tabelle.
Contenuti correlati
- Informazioni sul connettore Esplora dati di Azure per Azure Data Factory.
- Modificare servizi collegati, set di dati e pipeline nell'interfaccia utente di Data Factory.
- Eseguire query sui dati nell'interfaccia utente Web di Esplora dati di Azure.